知识图谱的图嵌入模型
本文梳理了面向知识图谱的图嵌入学习算法的不同设计思想,并对相应方法进行了总结。然后按照设计思路,信息利用程度的不同将图嵌入学习方法分成如下5种类别:基于转移思想的图嵌入算法,基于矩阵/张量分解的图嵌入算法,基于传统深度学习的图嵌入算法,基于图神经网络的图嵌入算法以及融入额外信息的图嵌入算法。其中前3种算法从距离度量,语义相似度和特征抽取3个角度分别考察三元组的评估策略。前3类方法的学习对象都是单个三元组,而基于GNN的模型建立再前3类方法的基础之上,首先利用GNN模型对图谱的全局结构进行编码,然后采用前3类方法作为解码器做链接预测任务。因此,基于GNN的图嵌入学习方法学习到的图结构信息理论上更加全面有效,这是从图结构信息的挖掘深度角度进行分类。最后,前4类算法都只是涉及到知识图谱的结构信息,而知识图谱作为一种特别的异质图,其实体于关系都可能关联了名称,描述,类别等信息,如何再学习图嵌入的同时考虑这些信息时第5类算法的关键思想。
评价指标
给定一个知识图谱KG=(E,R,T),其中E表示KG包含的实体集合,R表示KG涉及的关系集合,T表示KG中包含的三元组集合,面向知识图谱的图嵌入学习,简称为图嵌入学习任务,旨在为每个实体e属于E学习相应的低维表示向量ve属于Rde,其中de表示实体嵌入的维度,以及为每个关系r属于R学习相应的低维表示向量vr属于Rdr或者表示矩阵Mr属于Rdr*dr,
其中dr表示关系表示的维度,通常来说,de=dr=d。
图嵌入只是学习结果,而为了学习图嵌入,通常需要经过特定的学习任务,如链接预测任务(即知识补全任务),实体对齐任务等。以链接预测任务为例,该任务要求给定三元组中的两个元素,去预测 第3个元素,形式化定义就是给定查询(h,r,?)或者(?,r,t),分别预测正确的尾实体和头实体集合,其中h,r,t分别代表头实体,关系和尾实体。通常通过学习图嵌入来计算三元组的得分函数,通过梯度反向传播算法在最大化正确三元组的得分函数的同时也学习了图嵌入表示。相对于其他任务,链接预测任务需要的条件较少且研究意义深远,因此研究人员通常是同链接预测任务来判断图嵌入学习算法的有效性。
链接预测的评估指标通常采用MRR,MR和Hits@k这3种排序指标,之所以采用排序指标,是因为链接预测任务通常将学习任务视为排序任务,在预测前,需要为每个候选实体进行打分,并按照打分情况对候选实体进行排序。对于评估样本(h,r,t),假设其正确的标签集合为S={e|(h,r,e)}成立。为了计算上述指标,需要统计当前评估样本(h,r,t)的正确标签t在候选实体中的排序值rank.在统计排序值时,有原始排序值和过滤排序值两种统计方式。原始排序值即直接统计t在候选实体中的排序值作为最终rank,但是考虑到正确的标签集合S不仅包含标签t,还包括其他实体,如果模型只统计t在候选实体中的排序值,而忽略了排在t之前的正确标签,则计算出的排序值偏大,因此过滤排序值将所有排在t的正确标签过滤掉,再计算t的排序值作为最终的rank。通常来说给出的指标默认是指过滤后的实验指标。基于以上统计量,MR的计算方式为:
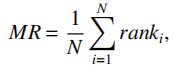
其中,N是评估样本的个数,ranki表示第i个样本中正确标签的排序值,相应的MRR的计算方式为:
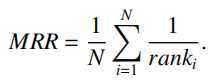
Hits@k指标统计了所有评估样本中正确标签排序在前k个的比例,计算方式为:
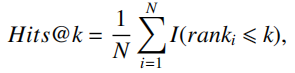
其中,I(x)为示性函数,当参数x为真时该函数取值为1,否则为0.
基于转移思想的图嵌入学习
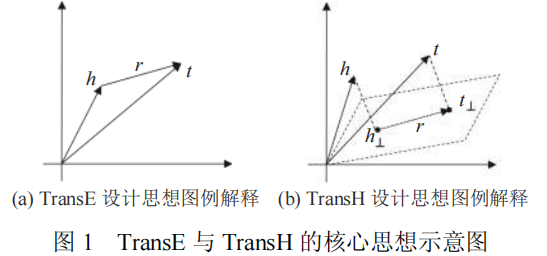
基于转移思想的图嵌入算法最早由Bordes等人提出,该工作提出了第一个基于转移的表示学习模型TransE.TransE算法认为如果三元组(头实体,关系,尾实体)正确,则头实体h,关系r与尾实体t的表示向量vh,vr和vt需满足关系vh+vr≈vt,即头实体在经过关系的转移后需要接近尾实体。TransE的核心思想如图1(a)所示,头,尾实体均被建模成表示空间中的一个点,而关系建模成表示空间中的向量位移,vh+vr≈vt,表示头实体h经过关系r的位移后在表示空间中接近尾实体t,例如v哈尔滨+v方言≈v东北话,v广东+v方言≈v粤语。因此,对于三元组(h,r,t),TransE设计的优化目标函数为f(h,r,t)=||vh+vr-vt||p,当三元组正确时最小化该目标函数,反之则最大化该函数。
TransE建模简单但效果颇佳,而且相较于传统的知识推理方法,学习效率高,能够很快部署在大型知识图谱上,因此很快引发了Trans系列模型的研究热潮。尽管TransE算法表现不错,学习效率高,但依然存在一些不足有待优化。
首先,在处理多对一,一对多以及多对多关系(统称为多映射关系)时,由于简单约束vh+vr≈vt的作用,会使得不同实体的分布式表示在表示空间中聚集在一起,即使这些实体具有不同的语义,进而造成实体语义的混乱。例如通过简单约束v哈尔滨+v位于≈v中国与v北京+v位于≈v中国,使得哈尔滨与北京的语义发生混淆。为了解决该问题,TransH引入了关系超平面的概念,在转移头实体之前,先将头尾实体分别投影到关系所在的超平面上:
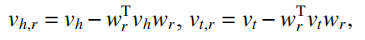
其中,wr表示关系r相关的超平面的法向量。在超平面上计算头实体经过关系转移后与尾实体的距离:||vh,r+vr-vt,r||p。
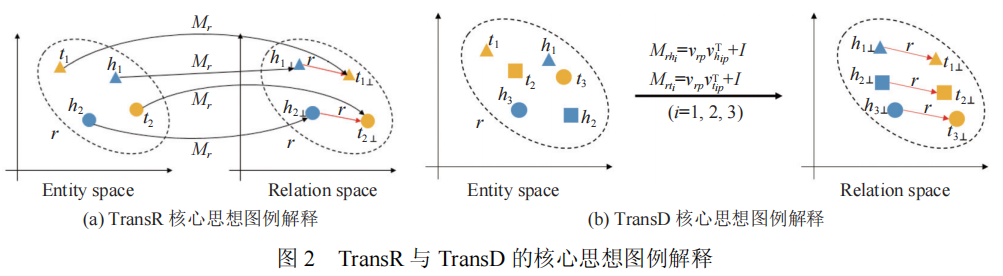
这使得相同的实体在不同的关系下具有不同的表示,在一定程度上缓解了TransE在多映射关系上的弱表现问题,该算法的设计思想参考图1(b)所示。不同于TransH的超平面假设,TransR假设每个关系都关联了一个表示空间,在转移操作前,TransR通过线性变换将实体表示映射到相应的关系空间中,然后执行转移操作,具体来说,TransR定义了关系关联的映射矩阵Mr,在执行转移操作之前,分别通过vh,r=Mrvh和vt,r=Mrvt获得关系空间内头实体与尾实体表示,最后通过计算||vh,r+vr+vt,r||p得到优化目标。TransD继承了TransR的思路,但该算法观察到TransR为不同的关系类别r关联不同的映射矩阵Mr,容易造成参数量过大的问题,因此对Mr进行了分解表示。TransD认为实体空间到关系空间的映射矩阵不应只受限与关系,还与实体相关。为了便于构造同时由实体与关系决定的映射矩阵,TransD为每个实体(关系)引入了两个向量,其中一个时实体(关系)的真实语义表示ve(vr),另一个向量vep(vrp)用于构建映射矩阵,对于三元组(h,r,t),通过Mrh=vrp(vhp)T+I与Mrt=vrp(vtp)T+I分别构建头实体与尾实体的映射矩阵。TransR与TransD算法的设计思想可以参见图2所示。TranSparse同样继承了TransR的思想,为了缓解TransR参数量过大的问题,TranSpare算法考虑使用稀疏矩阵建模Mr。同时该算法注意到语义越复杂的关系,往往需要用更多的参数量来学习,因此该算法为每个关系类别自适应地学习稀疏度:
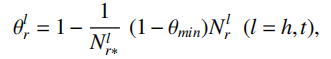
其中,Nlr表示关系r连接的实体对数目,Nlr*表示所有关系中连接实体对数目的最大值。这里TranSparse算法假设连接的实体对数目越多则该关系的语义越复杂。计算完每个关系的稀疏度Θlr后,基于该稀疏度生成稀疏矩阵Mlr(Θlr),对于头实体和尾实体分别生成映射矩阵Mhr(Θhr)和Mtr(Θtr),最后仿照TransR模型计算距离函数:
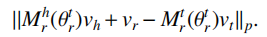
STransE为每个关系r关联了两个独立的矩阵Whr,Wtr,在转移操作前,使用Whr将头实体映射到关系空间,同时用Wtr将尾实体映射到关系空间。除此之外,CrossE采用类似TransE的思想,首先计算头实体与关系的合并,之后希望合并后的向量与尾实体尽可能相似,为了交互头实体与关系的信息,引入了交互矩阵Cr,使得实体以及关系的表示能够根据不同的三元组自主选择有用的信息,进而实现图嵌入的动态变化,以上工作都是从表示空间角度来考虑解决多映射关系的问题,TransM从三元组的重要性角度提出新的思路,该算法考虑了不同属性关系映射对三元组的贡献程度不同,认为包含一对以映射属性关系的三元组更重要,因而赋予相应三元组的损失函数以更高的权重。TransF则将方向作为度量三元组正确性的标准,具体来说,该算法不要求vh+vr≈vt,而是只要求vt与vh+vr在方向上保持一致,同理,也要求vh与vt+vr保持方向一致,为此该算法最终的得分函数为:
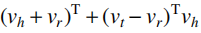
ManifoldE算法观察到对于1-N和N-N类型的关系,之所以会造成语义混乱的现象,主要由于将尾实体集合建模成空间中的一个点,使得所有正确尾实体在表示空间都簇拥在一起。因此该算法从流行角度触发,认为在学习链接预测任务(h,r,?)的过程中,正确的尾实体集合不应该由单个点表示,而是用流行来建模。
基于传统深度学习模型的图嵌入学习
基于卷积神经网络(CNN)的图嵌入模型利用卷积神经网络对三元组或三元组部分元素进行编码,从而实现对三元组进行打分的目的。ConvE对三元组(h,r,t)中的头实体h与关系r进行拼接,得到矩阵[vh,vr]属于Rd*2后对该矩阵的形状重新编辑;然后使用卷积神经网络对其进行编码,得到的编码结果经过全连接层输出最终的编码表示vhr,计算vhr与尾实体表示vt的相似度,实现对三元组进行打分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号