基于VectorNet的车辆行驶轨迹预测
目录
根据车辆行驶途中周围物体的变化,预测车辆行驶轨迹。数据集是"Argoverse" ,数据集包含高分辨率地图、传感器数据和车辆状态信息等多种数据类型。 "argoverse-api" 是一个由 Argo AI 公司开发的开源项目,它提供了一个 Python API,用于处理和分析 Argo AI 公司的自动驾驶车辆数据集 "Argoverse"。
流程图如下:
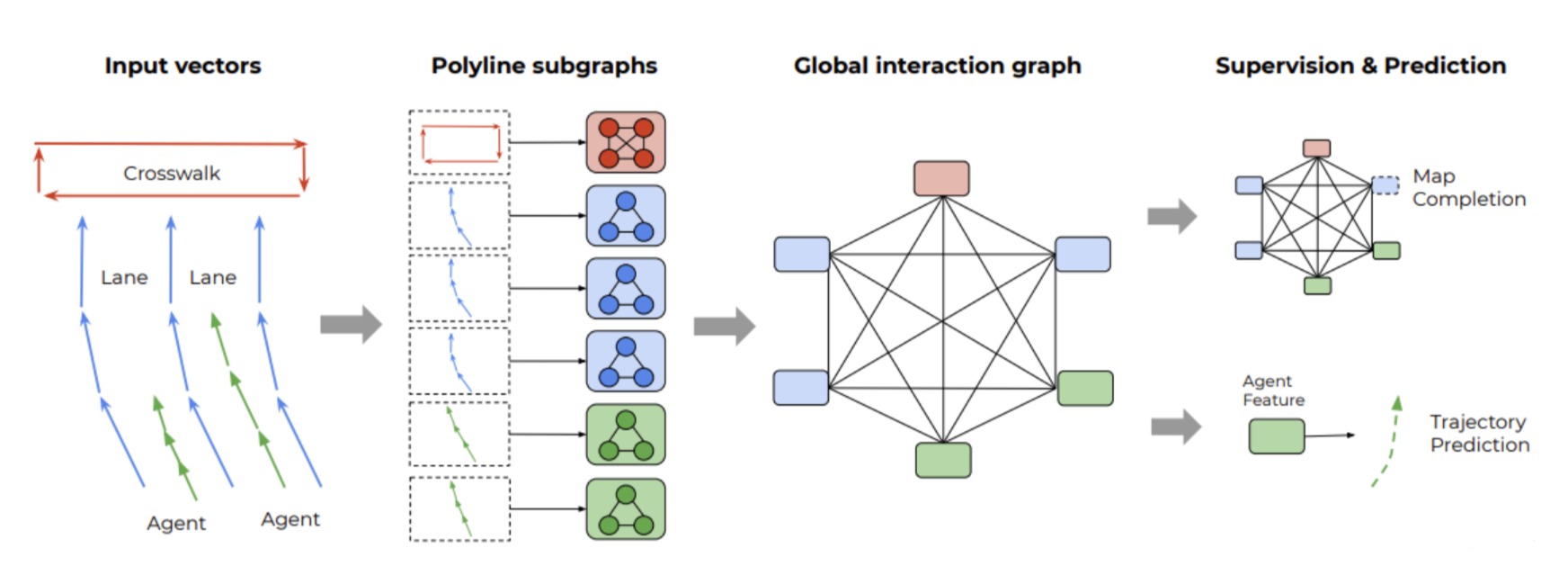
VectorNet将所有信息转化为向量表示,在向量上进行操作。物体都提取成点,带入图神经网络,由5秒的数据,用前2秒的点做训练预测后3秒的位置信息。首先构建子图(比如:车,路线条,人行道,人等分别构建自己的图),然后用transformer的self-attention把子图连接起来.最后,连接全连接层预测60个点(预测后30个点的xy坐标,共60个值)
1.向量化表示地图和移动agent(轨迹,车道线采样,每个点用特征向量表示)
- 指定好API和导入相关的库
from utils.feature_utils import compute_feature_for_one_seq, encoding_features, save_features
from argoverse.data_loading.argoverse_forecasting_loader import ArgoverseForecastingLoader
from argoverse.map_representation.map_api import ArgoverseMap
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from typing import List, Dict, Any
import os
from utils.config import DATA_DIR, LANE_RADIUS, OBJ_RADIUS, OBS_LEN, INTERMEDIATE_DATA_DIR
from tqdm import tqdm
import re
import pickle
- 读入数据文件
if __name__ == "__main__":
am = ArgoverseMap()# 导入api
for folder in os.listdir(DATA_DIR):#遍历三个文件夹(训练集,测试集,验证集)
if not re.search(r'val', folder):
# FIXME: modify the target folder by hand ('val|train|sample|test')
# if not re.search(r'test', folder):
continue
print(f"folder: {folder}")
afl = ArgoverseForecastingLoader(os.path.join(DATA_DIR, folder))#利用api读入CSV文件
norm_center_dict = {}
for name in tqdm(afl.seq_list):
afl_ = afl.get(name)
path, name = os.path.split(name)
name, ext = os.path.splitext(name)
agent_feature, obj_feature_ls, lane_feature_ls, norm_center = compute_feature_for_one_seq(
afl_.seq_df, am, OBS_LEN, LANE_RADIUS, OBJ_RADIUS, viz=False, mode='nearby')#afl_.seq_df拿到的.csv数据,am工具包,OBS_LEN:20(用前20个点做训练预测后30个点)
df = encoding_features(
agent_feature, obj_feature_ls, lane_feature_ls)
save_features(df, name, os.path.join(
INTERMEDIATE_DATA_DIR, f"{folder}_intermediate"))
norm_center_dict[name] = norm_center
with open(os.path.join(INTERMEDIATE_DATA_DIR, f"{folder}-norm_center_dict.pkl"), 'wb') as f:
pickle.dump(norm_center_dict, f, pickle.HIGHEST_PROTOCOL)
# print(pd.DataFrame(df['POLYLINE_FEATURES'].values[0]).describe())
(1)拿到车的起始点终止点信息,设定分割点
# normalize timestamps数据标准化,后续处理均为相对位置
traj_df['TIMESTAMP'] -= np.min(traj_df['TIMESTAMP'].values)
seq_ts = np.unique(traj_df['TIMESTAMP'].values)
seq_len = seq_ts.shape[0]#关注的每个对象长度为50
city_name = traj_df['CITY_NAME'].iloc[0]
agent_df = None
agent_x_end, agent_y_end, start_x, start_y, query_x, query_y, norm_center = [
None] * 7#起始位置,终止位置,query_x, query_y:预测点和训练点分割点坐标
# agent traj & its start/end point
for obj_type, remain_df in traj_df.groupby('OBJECT_TYPE'):
if obj_type == 'AGENT':
agent_df = remain_df
start_x, start_y = agent_df[['X', 'Y']].values[0] #起始位置
agent_x_end, agent_y_end = agent_df[['X', 'Y']].values[-1]# 终止位置
query_x, query_y = agent_df[['X', 'Y']].values[obs_len-1]# 预测点和训练点分割点坐标
norm_center = np.array([query_x, query_y])
break
else:
raise ValueError(f"cannot find 'agent' object type")
# prune points after "obs_len" timestamp
# [FIXED] test set length is only `obs_len`
traj_df = traj_df[traj_df['TIMESTAMP'] <=#筛选时间轴上满足要求的
agent_df['TIMESTAMP'].values[obs_len-1]]
assert (np.unique(traj_df["TIMESTAMP"].values).shape[0]
== obs_len), "Obs len mismatch"
(2)特征提取
lane_feature_ls = []
if mode == 'nearby':
query_x, query_y = agent_df[['X', 'Y']].values[obs_len-1]#拿到query_x, query_y
nearby_lane_ids = am.get_lane_ids_in_xy_bbox(#拿到旁边车道线信息
query_x, query_y, city_name, lane_radius)
for lane_id in nearby_lane_ids:
traffic_control = am.lane_has_traffic_control_measure(
lane_id, city_name)
is_intersection = am.lane_is_in_intersection(lane_id, city_name)
centerlane = am.get_lane_segment_centerline(lane_id, city_name)#中间线
# normalize to last observed timestamp point of agent
centerlane[:, :2] -= norm_center#标准化
halluc_lane_1, halluc_lane_2 = get_halluc_lane(
centerlane, city_name)
2.训练数据
(1)构建好GraphDataset数据结构
def process(self):
def get_data_path_ls(dir_):
return [os.path.join(dir_, data_path) for data_path in os.listdir(dir_)]
# make sure deterministic results
data_path_ls = sorted(get_data_path_ls(self.root))
valid_len_ls = []
valid_len_ls = []
data_ls = []
for data_p in tqdm(data_path_ls):
if not data_p.endswith('pkl'):
continue
x_ls = []
y = None
cluster = None
edge_index_ls = []
data = pd.read_pickle(data_p)
all_in_features = data['POLYLINE_FEATURES'].values[0]
add_len = data['TARJ_LEN'].values[0]
cluster = all_in_features[:, -1].reshape(-1).astype(np.int32)# 哪些点要做selfGraf
valid_len_ls.append(cluster.max())
y = data['GT'].values[0].reshape(-1).astype(np.float32)#y的shape为60=30*2,预测未来30个点,每个点有x,y坐标
traj_mask, lane_mask = data["TRAJ_ID_TO_MASK"].values[0], data['LANE_ID_TO_MASK'].values[0]
agent_id = 0
edge_index_start = 0
assert all_in_features[agent_id][
-1] == 0, f"agent id is wrong. id {agent_id}: type {all_in_features[agent_id][4]}"
for id_, mask_ in traj_mask.items():#构建图
data_ = all_in_features[mask_[0]:mask_[1]]
edge_index_, edge_index_start = get_fc_edge_index(
data_.shape[0], start=edge_index_start)
x_ls.append(data_)
edge_index_ls.append(edge_index_)
for id_, mask_ in lane_mask.items():
data_ = all_in_features[mask_[0]+add_len: mask_[1]+add_len]#点的个数*点的特征
edge_index_, edge_index_start = get_fc_edge_index(#得到边的索引
data_.shape[0], edge_index_start)
x_ls.append(data_)
edge_index_ls.append(edge_index_)
edge_index = np.hstack(edge_index_ls)
x = np.vstack(x_ls)
data_ls.append([x, y, cluster, edge_index])
# [x, y, cluster, edge_index, valid_len]
g_ls = []
padd_to_index = np.max(valid_len_ls)
feature_len = data_ls[0][0].shape[1]
for ind, tup in enumerate(data_ls):#构建所有子图
tup[0] = np.vstack(
[tup[0], np.zeros((padd_to_index - tup[-2].max(), feature_len), dtype=tup[0].dtype)])
tup[-2] = np.hstack(
[tup[2], np.arange(tup[-2].max()+1, padd_to_index+1)])
g_data = GraphData(#最后构建的结果
x=torch.from_numpy(tup[0]),
y=torch.from_numpy(tup[1]),
cluster=torch.from_numpy(tup[2]),
edge_index=torch.from_numpy(tup[3]),
valid_len=torch.tensor([valid_len_ls[ind]]),
time_step_len=torch.tensor([padd_to_index + 1])
)
g_ls.append(g_data)
data, slices = self.collate(g_ls)
torch.save((data, slices), self.processed_paths[0])
(2)训练数据
if __name__ == "__main__":
# training envs
np.random.seed(SEED)
torch.manual_seed(SEED)
device = torch.device(f'cuda:{gpus[0]}' if torch.cuda.is_available() else 'cpu')
# prepare dara
train_data = GraphDataset(TRAIN_DIR).shuffle()#定义好GraphDataset
val_data = GraphDataset(VAL_DIR)
if small_dataset:
train_loader = DataListLoader(train_data[:1000], batch_size=batch_size, shuffle=True)
val_loader = DataListLoader(val_data[:200], batch_size=batch_size)
else:
train_loader = DataListLoader(train_data, batch_size=batch_size, shuffle=True)
val_loader = DataListLoader(val_data, batch_size=batch_size)
model = HGNN(in_channels, out_channels)
model = nn.DataParallel(model, device_ids=gpus, output_device=gpus[0])
model = model.to(device=device)
optimizer = optim.Adam(model.parameters(), lr=lr)
scheduler = optim.lr_scheduler.StepLR(
optimizer, step_size=decay_lr_every, gamma=decay_lr_factor)
3.模型构建
(1)GCN层
x, edge_index = sub_data.x, sub_data.edge_index
for name, layer in self.layer_seq.named_modules():#嵌套多层GCN
if isinstance(layer, GraphLayerProp):
x = layer(x, edge_index)#GCN的层
sub_data.x = x
out_data = max_pool(sub_data.cluster, sub_data)#传入cluster,把很多子图放在一个大图中,不同的cluster之间点不相连,共用1个邻接矩阵,不同cluster单独做max_pool
# try:
assert out_data.x.shape[0] % int(sub_data.time_step_len[0]) == 0
# except:
# from pdb import set_trace; set_trace()
out_data.x = out_data.x / out_data.x.norm(dim=0)
return out_data
(2)根据transformer的self-attention把子图连接起来
def forward(self, x, valid_len):
# print(x.shape)
# print(self.q_lin)
query = self.q_lin(x)#有多少个x构建多少个q
key = self.k_lin(x)#构建k
value = self.v_lin(x) #构建v
scores = torch.bmm(query, key.transpose(1, 2))#根据内积求得分
attention_weights = masked_softmax(scores, valid_len)# softmax
return torch.bmm(attention_weights, value)
(3)模型
class HGNN(nn.Module):
"""
hierarchical GNN with trajectory prediction MLP
"""
def __init__(self, in_channels, out_channels, num_subgraph_layers=3, num_global_graph_layer=1, subgraph_width=64, global_graph_width=64, traj_pred_mlp_width=64):
super(HGNN, self).__init__()
self.polyline_vec_shape = in_channels * (2 ** num_subgraph_layers)
self.subgraph = SubGraph(
in_channels, num_subgraph_layers, subgraph_width)
self.self_atten_layer = SelfAttentionLayer(
self.polyline_vec_shape, global_graph_width, need_scale=False)
self.traj_pred_mlp = TrajPredMLP(
global_graph_width, out_channels, traj_pred_mlp_width)
def forward(self, data):
"""
args:
data (Data): [x, y, cluster, edge_index, valid_len]
"""
time_step_len = int(data.time_step_len[0])
valid_lens = data.valid_len
sub_graph_out = self.subgraph(data)#传入点,边,邻阶矩阵,跳入1
x = sub_graph_out.x.view(-1, time_step_len, self.polyline_vec_shape)
out = self.self_atten_layer(x, valid_lens)# 跳入2
# from pdb import set_trace
# set_trace()
pred = self.traj_pred_mlp(out[:, [0]].squeeze(1))#输出层预测,最终得到60个值与标签的60个值对应,能计算损失进行权重更新
return pred

 浙公网安备 33010602011771号
浙公网安备 33010602011771号