
OpenCV实现文档扫描识别
本文实现了对读入图片进行变换,最后调用pytesseract工具实现图片内容的提取。包含高斯滤波操作去除噪音点、边缘检测、轮廓检测、透视变换、pytesseract文本识别。
步骤:
- 需要提取读入的图片中要识别的文档部分,于是,首先需要检测到该文档的边缘,其次根据边缘检测轮廓并保留合适部分,最后对检测到的轮廓进行透视变换(变换成只剩需扫描的文档部分,并且工整)
1.处理读入图像
(1)读入模板图像
img = cv2.imread(args["template"])

(2)预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)#灰度转换
gray = cv2.GaussianBlur(gray, (5, 5), 0)#高斯滤波操作去除噪音点
edged = cv2.Canny(gray, 75, 200)#边缘检测
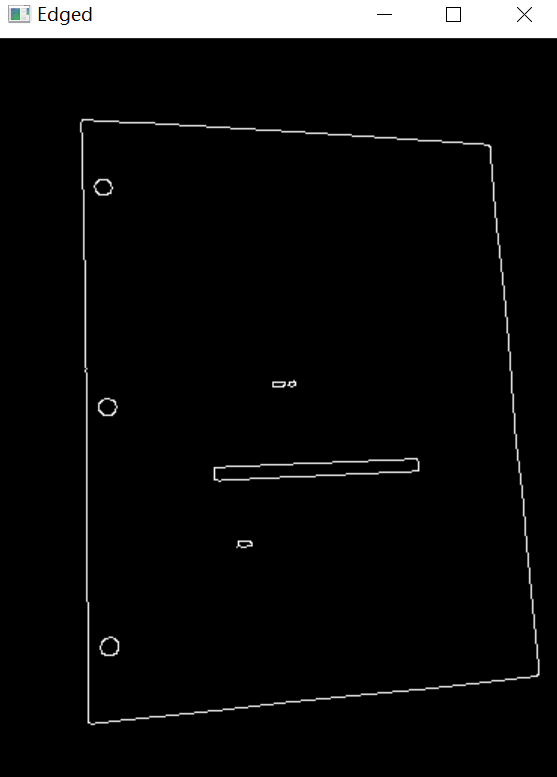
(3)轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]#在cv2.findContour()里只返回两个值: contours, hierachy,而我们要的是contours,所以后面应该是0而不是1。
cnts = sorted(cnts, key = cv2.contourArea, reverse = True)[:5] #通过对轮廓面积排序,只要前5个最大的轮廓
# 遍历轮廓
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, True) #轮廓长度
# C表示输入的点集
# epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
# True表示封闭的
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 4个点的时候就拿出来,矩形
if len(approx) == 4:
screenCnt = approx
break

(4)透视变换
- 用一个图片看一下透视变换做的事情

def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect #tl指toplift左上, tr指右上, br指右下, bl指左下
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵3*3(歪歪扭扭的原图通过变换矩阵(平移旋转翻转)可变工整)二维坐标点--->三维空间进行变换(z坐标取1)--->二维(工整)
M = cv2.getPerspectiveTransform(rect, dst)#rect表示输入的4个点,dst表示输出的4个点(至少需8个方程求解变换矩阵中的8个未知数,最后一个为1,8个方程需要4组坐标求解)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
# 透视变换
warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)#orig表示原始输入图像,screenCnt表示轮廓的四个点的坐标,* ratio表示把坐标点还原成没resize之前
# 二值处理
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('scan.jpg', ref)

2.调用pytesseract工具实现图片内容的提取
- 由于cv2.imwrite('scan.jpg', ref),后文在scan.jpg处理过的图片上进行扫描提取。
from PIL import Image
import pytesseract #开源OCR识别工具
import cv2
import os
preprocess = 'blur' #thresh
image = cv2.imread('scan.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if preprocess == "thresh":
gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if preprocess == "blur":
gray = cv2.medianBlur(gray, 3)
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
text = pytesseract.image_to_string(Image.open(filename))
print(text)
os.remove(filename)
cv2.imshow("Output", gray)
cv2.waitKey(0)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人