

MyBatis启动流程
加载配置文件build()
String resource = "mybatis.xml";
//将XML配置文件构建为Configuration配置类
//读取配置文件,生成读取流
InputStream inputStream = Resources.getResourceAsStream(resource);
//返回的DefaultSqlSessionFactory是SqlSessionFactory接口的实现类,
//这个类只有一个属性,就是Configuration对象,Configuration对象用来存放读取xml配置的信息
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
通过上面代码发现,创建SqlSessionFactory的代码在SqlSessionFactoryBuilder中,进去一探究竟:
//整个过程就是将配置文件解析成Configration对象,然后创建SqlSessionFactory的过程
//就是这个方法,注意后面两个参数均为空
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
//XMLConfigBuilder看这个名字就是对mybatis的配置文件进行解析的类,现在他还是一个初始化对象,没有开始解析.用的是java的dom解析
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
//这个就是读取方法,parser.parse()返回一个Configuration对象,该对象将存放读取配置文件的信息
//build(parser.parse())传入一个Configuration对象,并使用多态返回SqlSessionFactory接口的实体类DefaultSqlSessionFactory
//DefaultSqlSessionFactory只有一个属性,就是Configuration对象
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
//这里关闭了读取流inputStream,我们不用再手动关闭了
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
下面我们看下解析配置文件过程中的一些细节。
先给出一个配置文件的列子:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--SqlSessionFactoryBuilder中配置的配置文件的优先级最高;config.properties配置文件的优先级次之;properties标签中的配置优先级最低 -->
<properties resource="org/mybatis/example/config.properties">
<property name="username" value="dev_user"/>
<property name="password" value="F2Fa3!33TYyg"/>
</properties>
<!--一些重要的全局配置-->
<settings>
<setting name="cacheEnabled" value="true"/>
<!--<setting name="lazyLoadingEnabled" value="true"/>-->
<!--<setting name="multipleResultSetsEnabled" value="true"/>-->
<!--<setting name="useColumnLabel" value="true"/>-->
<!--<setting name="useGeneratedKeys" value="false"/>-->
<!--<setting name="autoMappingBehavior" value="PARTIAL"/>-->
<!--<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>-->
<!--<setting name="defaultExecutorType" value="SIMPLE"/>-->
<!--<setting name="defaultStatementTimeout" value="25"/>-->
<!--<setting name="defaultFetchSize" value="100"/>-->
<!--<setting name="safeRowBoundsEnabled" value="false"/>-->
<!--<setting name="mapUnderscoreToCamelCase" value="false"/>-->
<!--<setting name="localCacheScope" value="STATEMENT"/>-->
<!--<setting name="jdbcTypeForNull" value="OTHER"/>-->
<!--<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>-->
<!--<setting name="logImpl" value="STDOUT_LOGGING" />-->
</settings>
<!--别名-->
<typeAliases>
<typeAlias type="com.lusaisai.po.Springbootjdbc" alias="springbootjdbc"></typeAlias>
</typeAliases>
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!--默认值为 false,当该参数设置为 true 时,如果 pageSize=0 或者 RowBounds.limit = 0 就会查询出全部的结果-->
<!--如果某些查询数据量非常大,不应该允许查出所有数据-->
<property name="pageSizeZero" value="true"/>
</plugin>
</plugins>
<!-- 和spring整合后mybatis的 environments配置将废除 -->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://10.59.97.10:3308/windty"/>
<property name="username" value="windty_opr"/>
<property name="password" value="windty!234"/>
</dataSource>
</environment>
</environments>
<databaseIdProvider type="DB_VENDOR">
<property name="MySQL" value="mysql" />
<property name="Oracle" value="oracle" />
</databaseIdProvider>
<!-- 加载mapper.xml -->
<mappers>
<!--这边可以使用package和resource两种方式加载mapper-->
<!--<package name="包名"/>-->
<!--<mapper resource="./mappers/SysUserMapper.xml"/>-->
<mapper resource="./mappers/CbondissuerMapper.xml"/>
</mappers>
parse():
下面是解析配置文件的核心方法parse:
//调用此方法对mybatis配置文件进行解析
public Configuration parse() {
//注意:parsed默认为false,配置文件读取非常消耗资源,因此这里只读取一次,如果读取过则将parsed的值改为true,再次读取的时候就抛一个异常
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
//在这里将parsed的值改为true
parsed = true;
//从配置文件configuration标签开始解析,具体解析过程在下面
parseConfiguration(parser.evalNode("/configuration"));
//返回Configuration对象用于存储mybatis配置文件信息
return configuration;
}
parseConfiguration
下面的方法就是解析configuration节点下的子节点
private void parseConfiguration(XNode root) {
try {
//issue #117 read properties first
/**
* 解析 properties节点
* <properties resource="mybatis/db.properties" />
* 解析到org.apache.ibatis.parsing.XPathParser#variables
* org.apache.ibatis.session.Configuration#variables
*/
propertiesElement(root.evalNode("properties"));
/**
* 解析我们的mybatis-config.xml中的settings节点
* 具体可以配置哪些属性:http://www.mybatis.org/mybatis-3/zh/configuration.html#settings
* <settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
..............
</settings>
*
*/
Properties settings = settingsAsProperties(root.evalNode("settings"));
/**
* 基本没有用过该属性
* VFS含义是虚拟文件系统;主要是通过程序能够方便读取本地文件系统、FTP文件系统等系统中的文件资源。
Mybatis中提供了VFS这个配置,主要是通过该配置可以加载自定义的虚拟文件系统应用程序
解析到:org.apache.ibatis.session.Configuration#vfsImpl
*/
loadCustomVfs(settings);
/**
* 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。
* SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING
* 解析到org.apache.ibatis.session.Configuration#logImpl
*/
loadCustomLogImpl(settings);
/**
* 解析我们的别名
* <typeAliases>
<typeAlias alias="Author" type="cn.tulingxueyuan.pojo.Author"/>
</typeAliases>
<typeAliases>
<package name="cn.tulingxueyuan.pojo"/>
</typeAliases>
解析到oorg.apache.ibatis.session.Configuration#typeAliasRegistry.typeAliases
除了自定义的,还有内置的
*/
typeAliasesElement(root.evalNode("typeAliases"));
/**
* 解析我们的插件(比如分页插件)
* mybatis自带的
* Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
ParameterHandler (getParameterObject, setParameters)
ResultSetHandler (handleResultSets, handleOutputParameters)
StatementHandler (prepare, parameterize, batch, update, query)
解析到:org.apache.ibatis.session.Configuration#interceptorChain.interceptors
*/
pluginElement(root.evalNode("plugins"));
/**
* 可以配置 一般不会去设置
* 对象工厂 用于反射实例化对象、对象包装工厂、
* 反射工厂 用于属性和setter/getter 获取
*/
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
// 设置settings 和默认值到configuration
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
/**
* 解析我们的mybatis环境
<environments default="dev">
<environment id="dev">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="root"/>
<property name="password" value="Zw726515"/>
</dataSource>
</environment>
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
* 解析到:org.apache.ibatis.session.Configuration#environment
* 在集成spring情况下由 spring-mybatis提供数据源 和事务工厂
*/
environmentsElement(root.evalNode("environments"));
/**
* 解析数据库厂商
* <databaseIdProvider type="DB_VENDOR">
<property name="SQL Server" value="sqlserver"/>
<property name="DB2" value="db2"/>
<property name="Oracle" value="oracle" />
<property name="MySql" value="mysql" />
</databaseIdProvider>
* 解析到:org.apache.ibatis.session.Configuration#databaseId
*/
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
/**
* 解析我们的类型处理器节点
* <typeHandlers>
<typeHandler handler="org.mybatis.example.ExampleTypeHandler"/>
</typeHandlers>
解析到:org.apache.ibatis.session.Configuration#typeHandlerRegistry.typeHandlerMap
*/
typeHandlerElement(root.evalNode("typeHandlers"));
/**
* 最最最最最重要的就是解析我们的mapper
*
resource:来注册我们的class类路径下的
url:来指定我们磁盘下的或者网络资源的
class:
若注册Mapper不带xml文件的,这里可以直接注册
若注册的Mapper带xml文件的,需要把xml文件和mapper文件同名 同路径
-->
<mappers>
<mapper resource="mybatis/mapper/EmployeeMapper.xml"/>
<mapper class="com.tuling.mapper.DeptMapper"></mapper>
<package name="com.tuling.mapper"></package>
-->
</mappers>
* package
* ·解析mapper接口代理工厂(传入需要代理的接口) 解析到:org.apache.ibatis.session.Configuration#mapperRegistry.knownMappers
·解析mapper.xml 最终解析成MappedStatement 到:org.apache.ibatis.session.Configuration#mappedStatements
*/
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
具体如何解析各xml的代码就不看了,可以使用各种工具类解析xml,看下几个重要的
typeAliasesElement
//如果没有settings标签,给一个默认值
private void typeAliasesElement(XNode parent) {
//如果没有settings标签,给一个默认值
if (parent != null) {
for (XNode child : parent.getChildren()) {
//批量解析
if ("package".equals(child.getName())) {
String typeAliasPackage = child.getStringAttribute("name");
configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage);
} else {
//一个一个解析
String alias = child.getStringAttribute("alias");
String type = child.getStringAttribute("type");
try {
//根据type表示的全限定名拿到它的class对象
Class<?> clazz = Resources.classForName(type);
if (alias == null) {
//注册别名,分两种情况,一种别名alias为空,一种不为空
typeAliasRegistry.registerAlias(clazz);
} else {
typeAliasRegistry.registerAlias(alias, clazz);
}
} catch (ClassNotFoundException e) {
throw new BuilderException("Error registering typeAlias for '" + alias + "'. Cause: " + e, e);
}
}
}
}
}
typeAliasRegistry.registerAlias(clazz);
//Alias为空的注册别名方法
public void registerAlias(Class<?> type) {
String alias = type.getSimpleName();
//看下注解上面有没有
Alias aliasAnnotation = type.getAnnotation(Alias.class);
//如果有注解,解析注解
if (aliasAnnotation != null) {
alias = aliasAnnotation.value();
}
//否则,解析xml
registerAlias(alias, type);
}
registerAlias
//这就是注册别名的本质方法, 其实就是向保存别名的hashMap新增值而已
public void registerAlias(String alias, Class<?> value) {
if (alias == null) {
throw new TypeException("The parameter alias cannot be null");
}
// issue #748
//别名统一处理,都转化为小写,所以别名不区分大小写
String key = alias.toLowerCase(Locale.ENGLISH);
if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
}
//将别名存进map
typeAliases.put(key, value);
}
typeAliases
typeAliases就是一个map
//原来别名就通过一个HashMap来实现, key为别名, value就是别名对应的类型(class对象)
private final Map<String, Class<?>> typeAliases = new HashMap<>();
//别名在这这个构造方法做默认的处理,以下就是mybatis默认为我们注册的预制别名
public TypeAliasRegistry() {
registerAlias("string", String.class);
registerAlias("byte", Byte.class);
registerAlias("long", Long.class);
registerAlias("short", Short.class);
registerAlias("int", Integer.class);
registerAlias("integer", Integer.class);
registerAlias("double", Double.class);
registerAlias("float", Float.class);
registerAlias("boolean", Boolean.class);
registerAlias("byte[]", Byte[].class);
registerAlias("long[]", Long[].class);
registerAlias("short[]", Short[].class);
registerAlias("int[]", Integer[].class);
registerAlias("integer[]", Integer[].class);
registerAlias("double[]", Double[].class);
registerAlias("float[]", Float[].class);
registerAlias("boolean[]", Boolean[].class);
registerAlias("_byte", byte.class);
registerAlias("_long", long.class);
registerAlias("_short", short.class);
registerAlias("_int", int.class);
registerAlias("_integer", int.class);
registerAlias("_double", double.class);
registerAlias("_float", float.class);
registerAlias("_boolean", boolean.class);
registerAlias("_byte[]", byte[].class);
registerAlias("_long[]", long[].class);
registerAlias("_short[]", short[].class);
registerAlias("_int[]", int[].class);
registerAlias("_integer[]", int[].class);
registerAlias("_double[]", double[].class);
registerAlias("_float[]", float[].class);
registerAlias("_boolean[]", boolean[].class);
registerAlias("date", Date.class);
registerAlias("decimal", BigDecimal.class);
registerAlias("bigdecimal", BigDecimal.class);
registerAlias("biginteger", BigInteger.class);
registerAlias("object", Object.class);
registerAlias("date[]", Date[].class);
registerAlias("decimal[]", BigDecimal[].class);
registerAlias("bigdecimal[]", BigDecimal[].class);
registerAlias("biginteger[]", BigInteger[].class);
registerAlias("object[]", Object[].class);
registerAlias("map", Map.class);
registerAlias("hashmap", HashMap.class);
registerAlias("list", List.class);
registerAlias("arraylist", ArrayList.class);
registerAlias("collection", Collection.class);
registerAlias("iterator", Iterator.class);
registerAlias("ResultSet", ResultSet.class);
}
mapperElement
解析mapper.xml 最终解析成MappedStatement
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
/**
* 获取我们mappers节点下的一个一个的mapper节点
*/
for (XNode child : parent.getChildren()) {
/**
* 判断我们mapper是不是通过批量注册的
* <package name="com.tuling.mapper"></package>
*/
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
/**
* 判断从classpath下读取我们的mapper
* <mapper resource="mybatis/mapper/EmployeeMapper.xml"/>
*/
String resource = child.getStringAttribute("resource");
/**
* 判断是不是从我们的网络资源读取(或者本地磁盘得)
* <mapper url="D:/mapper/EmployeeMapper.xml"/>
*/
String url = child.getStringAttribute("url");
/**
* 解析这种类型(要求接口和xml在同一个包下)
* <mapper class="com.tuling.mapper.DeptMapper"></mapper>
*
*/
String mapperClass = child.getStringAttribute("class");
/**
* 前面三种方式只能选一种配置,不然会报错,我们的mappers节点只配置了
* <mapper resource="mybatis/mapper/EmployeeMapper.xml"/>
*/
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
/**
* 把我们的文件读取出一个流
*/
InputStream inputStream = Resources.getResourceAsStream(resource);
/**
* 创建读取XmlMapper构建器对象,用于来解析我们的mapper.xml文件
*/
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
/**
* 真正的解析我们的mapper.xml配置文件(说白了就是来解析我们的sql)
*/
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
mapperParser.parse();
public void parse() {
/**
* 判断当前的Mapper是否被加载过
*/
if (!configuration.isResourceLoaded(resource)) {
//真正的解析我们的 <mapper namespace="com.tuling.mapper.EmployeeMapper">
configurationElement(parser.evalNode("/mapper"));
//把资源保存到我们Configuration中
configuration.addLoadedResource(resource);
bindMapperForNamespace();
}
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
configurationElement
private void configurationElement(XNode context) {
try {
/**
* 解析我们的namespace属性
* <mapper namespace="com.tuling.mapper.EmployeeMapper">
*/
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
/**
* 保存我们当前的namespace 并且判断接口完全类名==namespace
*/
builderAssistant.setCurrentNamespace(namespace);
/**
* 解析我们的缓存引用
* 说明我当前的缓存引用和DeptMapper的缓存引用一致
* <cache-ref namespace="com.tuling.mapper.DeptMapper"></cache-ref>
解析到org.apache.ibatis.session.Configuration#cacheRefMap<当前namespace,ref-namespace>
异常下(引用缓存未使用缓存):org.apache.ibatis.session.Configuration#incompleteCacheRefs
*/
cacheRefElement(context.evalNode("cache-ref"));
/**
* 解析我们的cache节点
* <cache ></cache>
解析到:org.apache.ibatis.session.Configuration#caches
org.apache.ibatis.builder.MapperBuilderAssistant#currentCache
*/
cacheElement(context.evalNode("cache"));
/**
* 解析paramterMap节点(该节点mybaits3.5貌似不推荐使用了)
*/
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
/**
* 解析我们的resultMap节点
* 解析到:org.apache.ibatis.session.Configuration#resultMaps
* 异常 org.apache.ibatis.session.Configuration#incompleteResultMaps
*
*/
resultMapElements(context.evalNodes("/mapper/resultMap"));
/**
* 解析我们通过sql片段
* 解析到org.apache.ibatis.builder.xml.XMLMapperBuilder#sqlFragments
* 其实等于 org.apache.ibatis.session.Configuration#sqlFragments
* 因为他们是同一引用,在构建XMLMapperBuilder 时把Configuration.getSqlFragments传进去了
*/
sqlElement(context.evalNodes("/mapper/sql"));
/**
* 解析我们的select | insert |update |delete节点,这里四种标签一起解析,所以效果一样
* 解析到org.apache.ibatis.session.Configuration#mappedStatements
*/
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
//解析我们的select | insert |update |delete节点
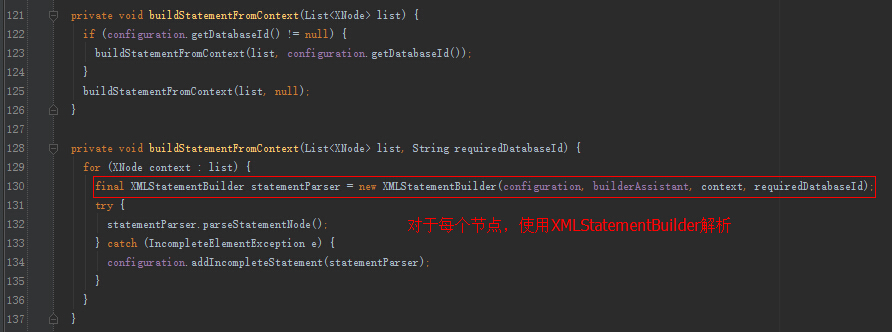
private void buildStatementFromContext(List<XNode> list) {
/**
* 判断有没有配置数据库厂商ID
*/
if (configuration.getDatabaseId() != null) {
buildStatementFromContext(list, configuration.getDatabaseId());
}
buildStatementFromContext(list, null);
}
/**
* 方法实现说明:解析我们得得select|update|delte|insert节点然后
* 创建我们得mapperStatment对象
* @author:xsls
* @param list:所有的select|update|delte|insert节点
* @param requiredDatabaseId:判断有没有数据库厂商Id
* @return:
* @exception:
* @date:2019/9/5 21:35
*/
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
/**
* 循环我们的select|delte|insert|update节点
*/
for (XNode context : list) {
/**
* 创建一个xmlStatement的构建器对象
*/
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
//解析
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
statementParser.parseStatementNode();
public void parseStatementNode() {
/**
* 我们的insert|delte|update|select 语句的sqlId
*/
String id = context.getStringAttribute("id");
/**
* 判断我们的insert|delte|update|select 节点是否配置了
* 数据库厂商标注
*/
String databaseId = context.getStringAttribute("databaseId");
/**
* 匹配当前的数据库厂商id是否匹配当前数据源的厂商id
*/
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
/**
* 获得节点名称:select|insert|update|delete
*/
String nodeName = context.getNode().getNodeName();
/**
* 根据nodeName 获得 SqlCommandType枚举
*/
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
/**
* 判断是不是select语句节点
*/
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
/**
* 获取flushCache属性
* 默认值为isSelect的反值:查询:flushCache=false 增删改:flushCache=true
*/
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
/**
* 获取useCache属性
* 默认值为isSelect:查询:useCache=true 增删改:useCache=false
*/
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
/**
* resultOrdered: 是否需要分组:
* select * from user-->User{id=1, name='User1', groups=[1, 2], roles=[1, 2, 3]}
*/
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
/**
* 解析我们的sql公用片段
* <select id="qryEmployeeById" resultType="Employee" parameterType="int">
<include refid="selectInfo"></include>
employee where id=#{id}
</select>
将 <include refid="selectInfo"></include> 解析成sql语句 放在<select>Node的子节点中
*/
// Include Fragments before parsing
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
/**
* 解析我们sql节点的参数类型
*/
String parameterType = context.getStringAttribute("parameterType");
// 把参数类型字符串转化为class
Class<?> parameterTypeClass = resolveClass(parameterType);
/**
* 查看sql是否支撑自定义语言
* <delete id="delEmployeeById" parameterType="int" lang="tulingLang">
<settings>
<setting name="defaultScriptingLanguage" value="tulingLang"/>
</settings>
*/
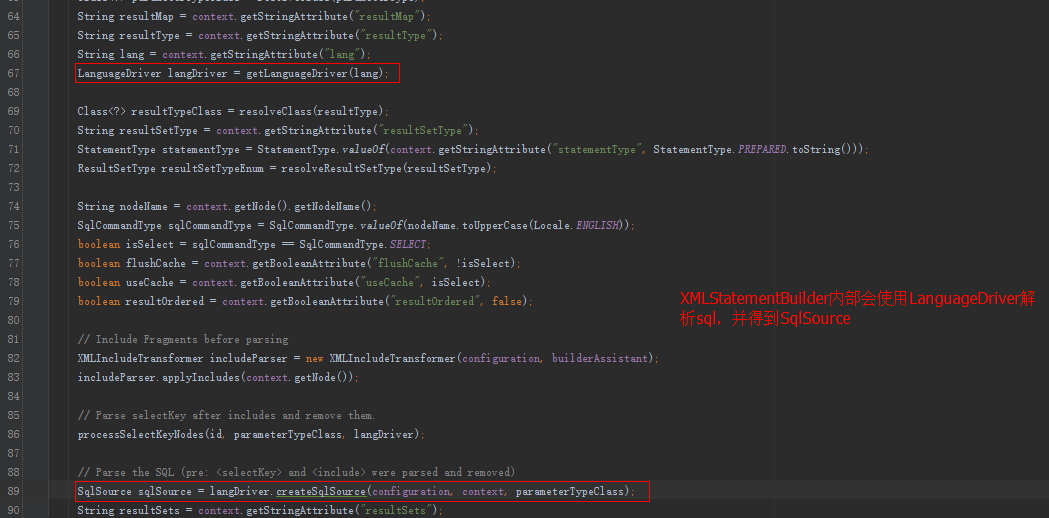
String lang = context.getStringAttribute("lang");
/**
* 获取自定义sql脚本语言驱动 默认:class org.apache.ibatis.scripting.xmltags.XMLLanguageDriver
*/
LanguageDriver langDriver = getLanguageDriver(lang);
/**
* 解析我们<insert 语句的的selectKey节点, 一般在oracle里面设置自增id
*/
// Parse selectKey after includes and remove them.
processSelectKeyNodes(id, parameterTypeClass, langDriver);
/**
* 我们insert语句 用于主键生成组件
*/
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
KeyGenerator keyGenerator;
/**
* selectById!selectKey
* id+!selectKey
*/
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
/**
* 把我们的命名空间拼接到keyStatementId中
* com.tuling.mapper.Employee.saveEmployee!selectKey
*/
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
/**
*<insert id="saveEmployee" parameterType="com.tuling.entity.Employee" useGeneratedKeys="true" keyProperty="id">
*判断我们全局的配置类configuration中是否包含以及解析过的主键生成器对象
*/
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
/**
* 若我们<insert 配置了useGeneratedKeys 那么就取useGeneratedKeys的配置值,
* 否者就看我们的mybatis-config.xml配置文件中是配置了
* <setting name="useGeneratedKeys" value="true"></setting> 默认是false
* 并且判断sql操作类型是否为insert
* 若是的话,那么使用的生成策略就是Jdbc3KeyGenerator.INSTANCE
* 否则就是NoKeyGenerator.INSTANCE
*/
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
/**
* 通过class org.apache.ibatis.scripting.xmltags.XMLLanguageDriver来解析我们的
* sql脚本对象 . 解析SqlNode. 注意, 只是解析成一个个的SqlNode, 并不会完全解析sql,因为这个时候参数都没确定,动态sql无法解析
*/
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
/**
* STATEMENT,PREPARED 或 CALLABLE 中的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED
*/
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
/**
* 这是一个给驱动的提示,尝试让驱动程序每次批量返回的结果行数和这个设置值相等。 默认值为未设置(unset)(依赖驱动)
*/
Integer fetchSize = context.getIntAttribute("fetchSize");
/**
* 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖驱动)。
*/
Integer timeout = context.getIntAttribute("timeout");
/**
* 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler) 推断出具体传入语句的参数,默认值为未设置
*/
String parameterMap = context.getStringAttribute("parameterMap");
/**
* 从这条语句中返回的期望类型的类的完全限定名或别名。 注意如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身。
* 可以使用 resultType 或 resultMap,但不能同时使用
*/
String resultType = context.getStringAttribute("resultType");
//解析我们查询结果集返回的类型
Class<?> resultTypeClass = resolveClass(resultType);
/**
* 外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂映射的情形都能迎刃而解。
* 可以使用 resultMap 或 resultType,但不能同时使用。
*/
String resultMap = context.getStringAttribute("resultMap");
String resultSetType = context.getStringAttribute("resultSetType");
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
if (resultSetTypeEnum == null) {
resultSetTypeEnum = configuration.getDefaultResultSetType();
}
/**
* 解析 keyProperty keyColumn 仅适用于 insert 和 update
*/
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
String resultSets = context.getStringAttribute("resultSets");
/**
* 为我们的insert|delete|update|select节点构建成我们的mappedStatment对象
*/
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
返回SqlSessionFactory
返回Configuration对象后的build方法,返回SqlSessionFactory
//这里就是返回SqlSessionFactory方法
public SqlSessionFactory build(Configuration config) {
//DefaultSqlSessionFactory就是SqlSessionFactory接口的实现类,
//这个类只有一个属性,就是Configuration对象,Configuration对象就是刚刚获取的用来存放读取xml配置的信息
return new DefaultSqlSessionFactory(config);
}
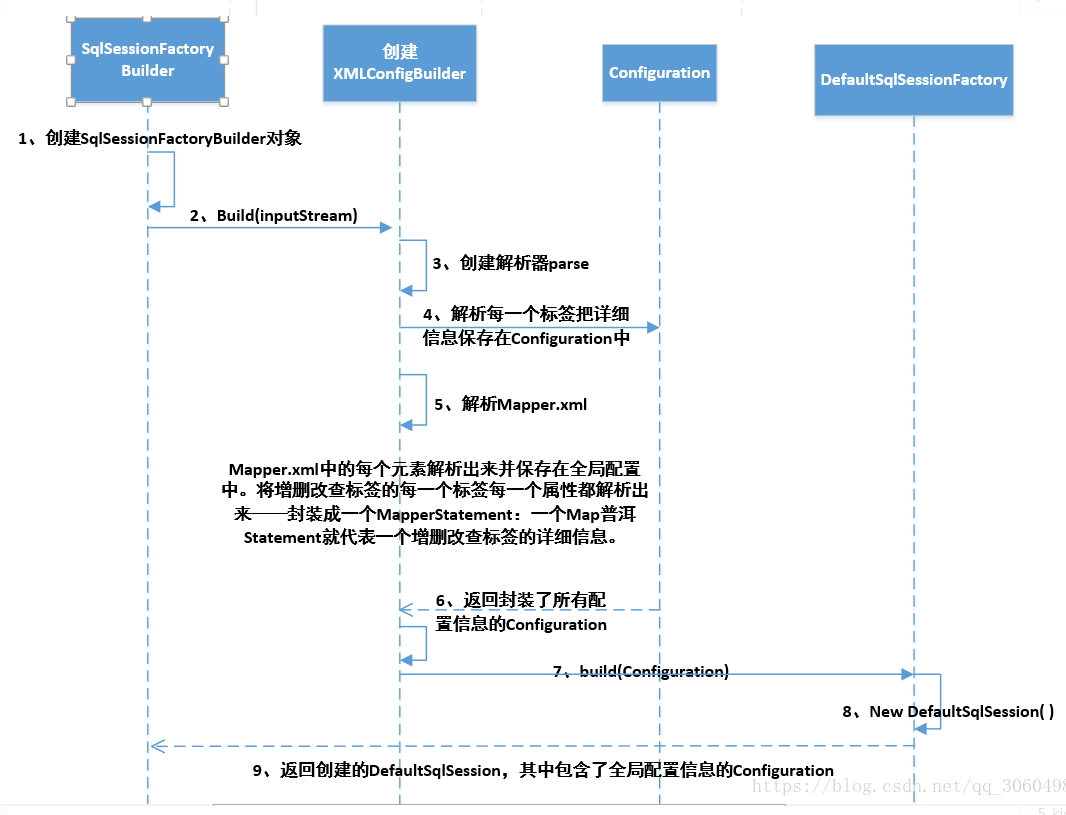
上面解析流程结束后会生成一个Configration对象,包含所有配置信息,然后会创建一个SqlSessionFactory对象,这个对象包含了Configration对象。
简单总结
MyBatis启动的流程(获取SqlSession的过程)这边简单总结下:
-
1.SqlSessionFactoryBuilder解析配置文件,包括属性配置、别名配置、拦截器配置、环境(数据源和事务管理器)、Mapper配置等;
-
2.解析完这些配置后会生成一个Configration对象,这个对象中包含了MyBatis需要的所有配置,
-
3.然后会用这个Configration对象创建一个SqlSessionFactory对象,这个对象中包含了Configration对象;
这里解析的东西比较多,大致会把所有的信息都解析到Configration对象中,比较简单不多介绍。
openSession的过程
@Override
public SqlSession openSession() {
//将Configuration对象传入,configuration.getDefaultExecutorType()=ExecutorType.SIMPLE
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
openSessionFromDataSource()
/**
* 方法实现说明:从session中开启一个数据源
* @author:xsls
* @param execType:执行器类型
* @param level:隔离级别
* @return:SqlSession
* @exception:
* @date:2019/9/9 13:38
*/
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//获取环境变量
final Environment environment = configuration.getEnvironment();
//获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
/**
* 创建一个sql执行器对象
* 一般情况下 若我们的mybaits的全局配置文件的cacheEnabled默认为ture就返回
* 一个cacheExecutor,若关闭的话返回的就是一个SimpleExecutor
*/
final Executor executor = configuration.newExecutor(tx, execType);
//创建返回一个DefaultSqlSession对象返回
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
configuration.newExecutor()
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
/**
* 判断执行器的类型
* 批量的执行器
*/
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
//可重复使用的执行器
executor = new ReuseExecutor(this, transaction);
} else {
//简单的sql执行器对象
executor = new SimpleExecutor(this, transaction);
}
//判断mybatis的全局配置文件是否开启缓存
if (cacheEnabled) {
//把当前的执行器包装成一个CachingExecutor
executor = new CachingExecutor(executor);
}
/**
* TODO:调用所有的拦截器对象plugin方法
* 插件: 责任链+ 装饰器模式(动态代理)
*/
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
Executor分成两大类,一类是CacheExecutor,另一类是普通Executor。
普通Executor又分为三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
- SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
- ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
- BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
CacheExecutor其实是封装了普通的Executor,和普通的区别是在查询前先会查询缓存中是否存在结果,如果存在就使用缓存中的结果,如果不存在还是使用普通的Executor进行查询,再将查询出来的结果存入缓存。
interceptorChain.pluginAll
执行拦截器链路
public class InterceptorChain {
private final List<Interceptor> interceptors = new ArrayList<>();
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
public void addInterceptor(Interceptor interceptor) {
interceptors.add(interceptor);
}
public List<Interceptor> getInterceptors() {
return Collections.unmodifiableList(interceptors);
}
}
总结
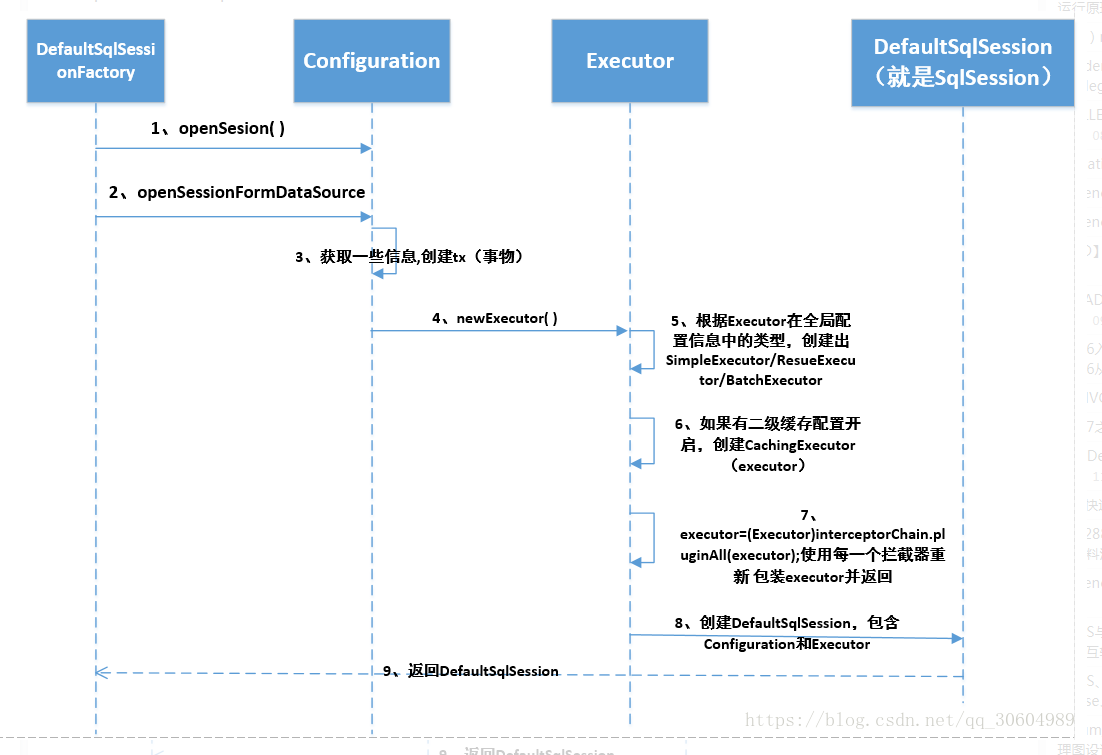
到此为止,我们已经获得了SqlSession,包含Configration和Executor就可以执行各种CRUD方法了。
简单总结
- 拿到SqlSessionFactory对象后,会调用SqlSessionFactory的openSesison方法,这个方法会创建一个Sql执行器(Executor),这个Sql执行器会代理你配置的拦截器方法。
- 获得上面的Sql执行器后,会创建一个SqlSession(默认使用DefaultSqlSession),这个SqlSession中也包含了Configration对象,所以通过SqlSession也能拿到全局配置;
- 获得SqlSession对象后就能执行各种CRUD方法了。
getMapper
进入sqlSession.getMapper方法,会发现调的是Configration对象的getMapper方法:
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
//mapperRegistry本质上是一个Map,里面注册了启动过程中解析的各种Mapper.xml
//mapperRegistry的key是接口的Class类型
//mapperRegistry的Value是MapperProxyFactory,用于生成对应的MapperProxy(动态代理类)
return mapperRegistry.getMapper(type, sqlSession);
}
MapperRegistry
public class MapperRegistry {
private final Configuration config;
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<>();
public MapperRegistry(Configuration config) {
this.config = config;
}
/**
* 方法实现说明:通过class类型和sqlSessionTemplate获取我们的Mapper(代理对象)
* @author:xsls
* @param type:Mapper的接口类型
* @param sqlSession:接口类型实际上是我们的sqlSessionTemplate类型
* @return:
* @exception:
* @date:2019/8/22 20:41
*/
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
/**
* 直接去缓存knownMappers中通过Mapper的class类型去找我们的mapperProxyFactory
*/
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
/**
* 缓存中没有获取到 直接抛出异常
*/
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
/**
* 通过MapperProxyFactory来创建我们的实例
*/
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
public <T> boolean hasMapper(Class<T> type) {
return knownMappers.containsKey(type);
}
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
knownMappers.put(type, new MapperProxyFactory<>(type));
// It's important that the type is added before the parser is run
// otherwise the binding may automatically be attempted by the
// mapper parser. If the type is already known, it won't try.
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
public Collection<Class<?>> getMappers() {
return Collections.unmodifiableCollection(knownMappers.keySet());
}
public void addMappers(String packageName, Class<?> superType) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<>();
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> mapperSet = resolverUtil.getClasses();
for (Class<?> mapperClass : mapperSet) {
addMapper(mapperClass);
}
}
public void addMappers(String packageName) {
addMappers(packageName, Object.class);
}
}
MapperRegistry.getMapper()
/**
* 方法实现说明:通过class类型和sqlSessionTemplate获取我们的Mapper(代理对象)
* @author:xsls
* @param type:Mapper的接口类型
* @param sqlSession:接口类型实际上是我们的sqlSessionTemplate类型
* @return:
* @exception:
* @date:2019/8/22 20:41
*/
@SuppressWarnings("unchecked")
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
/**
* 直接去缓存knownMappers中通过Mapper的class类型去找我们的mapperProxyFactory
*/
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
/**
* 缓存中没有获取到 直接抛出异常
*/
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
/**
* 通过MapperProxyFactory来创建我们的实例
*/
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
mapperProxyFactory.newInstance
protected T newInstance(MapperProxy<T> mapperProxy) {
//jdk动态代理
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
/**
* 创建我们的代理对象
*/
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
/**
* 创建我们的Mapper代理对象返回,jdk动态代理
*/
return newInstance(mapperProxy);
}
获取Mapper的流程总结如下:
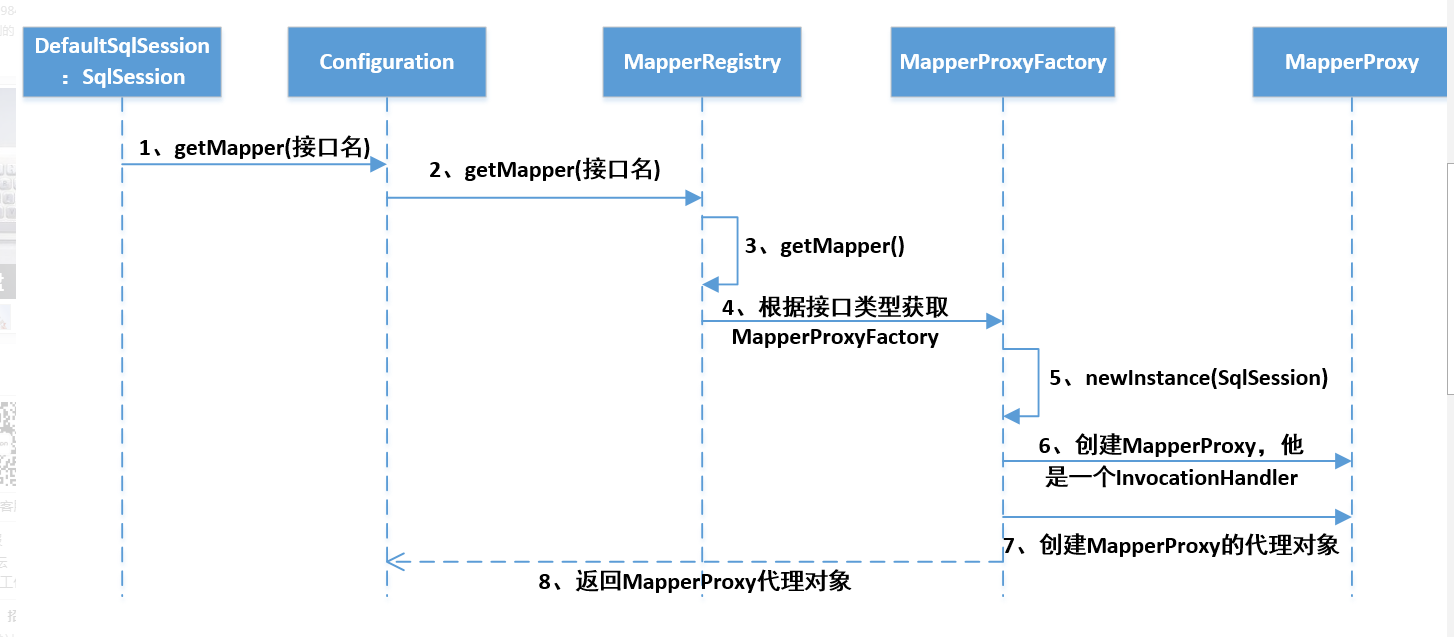
动态代理对象的执行流程
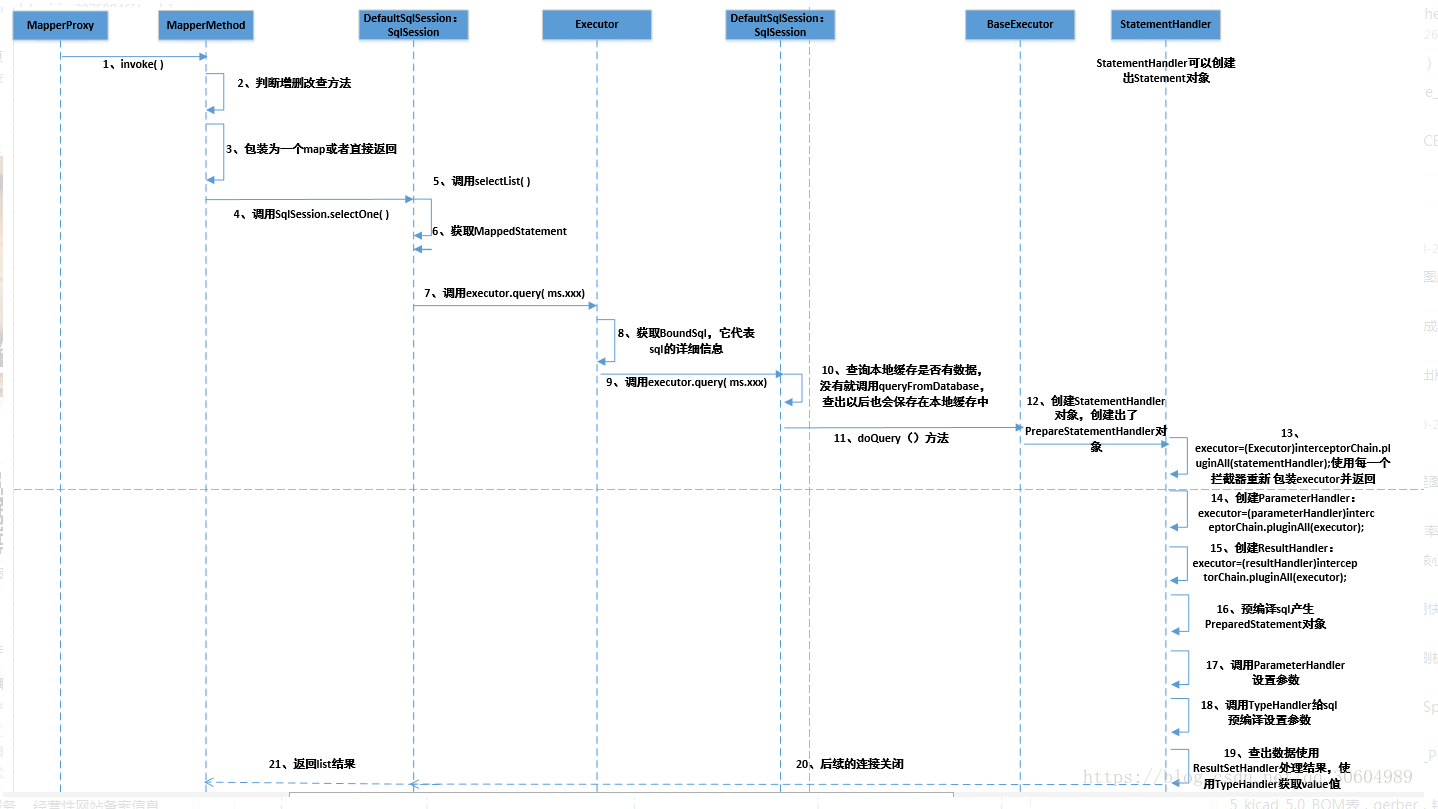
下面是动态代理类MapperProxy,调用Mapper接口的所有方法都会先调用到这个代理类的invoke方法(注意由于Mybatis中的Mapper接口没有实现类,所以MapperProxy这个代理对象中没有委托类,也就是说MapperProxy干了代理类和委托类的事情)。好了下面重点看下invoke方法。
invoke方法
/**
* 方法实现说明:我们的Mapper接口调用我们的目标对象
* 调用Mapper接口的所有方法都会先调用到这个代理类的invoke方法(注意由于Mybatis中的Mapper接口没有实现类,
* 所以MapperProxy这个代理对象中没有委托类,也就是说MapperProxy干了代理类和委托类的事情)
* @author:xsls
* @param proxy 代理对象
* @param method:目标方法
* @param args :目标对象参数
* @return:Object
* @exception:
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
/**
* 判断我们的方法是不是我们的Object类定义的方法,若是直接通过反射调用
*/
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
//是否接口的默认方法
} else if (method.isDefault()) {
/**
* 调用我们的接口中的默认方法
*/
if (privateLookupInMethod == null) {
return invokeDefaultMethodJava8(proxy, method, args);
} else {
return invokeDefaultMethodJava9(proxy, method, args);
}
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
/**
* 真正的进行调用,做了二个事情
* 第一步:把我们的方法对象封装成一个MapperMethod对象(带有缓存作用的)
*/
final MapperMethod mapperMethod = cachedMapperMethod(method);
/**
*MapperMethod的execute方法
*/
return mapperMethod.execute(sqlSession, args);
}
MapperProxy的invoke方法非常简单,主要干的工作就是创建MapperMethod对象或者是从缓存中获取MapperMethod对象。获取到这个对象后执行execute方法。
mapperMethod.execute
所以这边需要进入MapperMethod的execute方法:这个方法判断你当前执行的方式是增删改查哪一种,并通过SqlSession执行相应的操作。(这边以sqlSession.selectOne这种方式进行分析~)
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
//判断是CRUD那种方法
//command.getType()此时是select
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
//进入这个分支
case SELECT:
//这里结果为false,不进这里
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
//这里结果为false,不进这里
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
//这里结果为false,不进这里
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
//这里结果为false,不进这里
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
//进这个方法,处理一下参数
Object param = method.convertArgsToSqlCommandParam(args);
//处理参数完成后后param是hashmap类型,key有两种,一种是#{}里面的参数名,
// 另一种是(param1, param2, ...),value只有一种,就是我们的实际参数
//这里执行sql得到查询结果result,跟进去看下
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
详细流程图
https://www.processon.com/view/link/5efc23966376891e81f2a37e
DefaultSqlSession.selectOne
/**
* 方法实现说明:查询我们当个对象
* @author:xsls
* @param statement:我们的statementId(com.tuling.mapper.EmployeeMapper.findOne)
* @param parameter:调用时候的参数
* @return: T 返回结果
* @exception:
* @date:2019/9/9 20:26
*/
@Override
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
//这里selectOne调用也是调用selectList方法
List<T> list = this.selectList(statement, parameter);
//若查询出来有且有一个一个对象,直接返回要给
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
/**
* 查询的有多个,那么久抛出我们熟悉的异常
* Expected one result (or null) to be returned by selectOne(), but found: " + list.size()
*/
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
DefaultSqlSession.selectList
会调到DefaultSqlSession的selectList方法。这个方法获取了获取了MappedStatement对象,并最终调用了Executor的query方法。
//又是封装方法,别着急,继续点进去看
@Override
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
//这个是真正的sql执行方法了,statement是具体的方法名com.lusaisai.dao.DemoMapper.selectOne
//parameter是参数名和真是的参数
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//configuration对象根据statement,得到关于sql语句的相关信息
//这里得到的ms包含sql语句
MappedStatement ms = configuration.getMappedStatement(statement);
//这里就是执行sql语句
/**
* 通过执行器去执行我们的sql对象
* 第一步:包装我们的集合类参数
* 第二步:一般情况下是executor为cacheExetory对象
*/
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
然后,通过一层一层的调用(这边省略了缓存操作的环节,会在后面的文章中介绍),最终会来到doQuery方法, 这儿咱们就随便找个Excutor看看doQuery方法的实现吧,我这儿选择了SimpleExecutor:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//获取sql
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
query
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
//已经关闭,则抛出 ExecutorException 异常
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// <2> 清空本地缓存,如果 queryStack 为零,并且要求清空本地缓存。
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
// <4.1> 从一级缓存中,获取查询结果
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
// <4.2> 获取到,则进行处理
if (list != null) {
//处理存过的
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 获得不到,则从数据库中查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
queryFromDatabase
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//真正查询数据库的方法
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
doQuery
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//内部封装了ParameterHandler和ResultSetHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
//StatementHandler封装了Statement, 让 StatementHandler 去处理
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
接下来,咱们看看StatementHandler 的一个实现类 PreparedStatementHandler(这也是我们最常用的,封装的是PreparedStatement), 看看它使怎么去处理的:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
//这里强转成预编译对象PreparedStatement
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
//结果交给了ResultSetHandler 去处理,处理完之后返回给客户端
return resultSetHandler.handleResultSets(ps);
}
到此,整个调用流程结束。
解析动态sql原理(了解)
我们在使用mybatis的时候,会在xml中编写sql语句。
比如这段动态sql代码:
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>
mybatis底层是如何构造这段sql的?
下面带着这个疑问,我们一步一步分析。
介绍MyBatis中一些关于动态SQL的接口和类
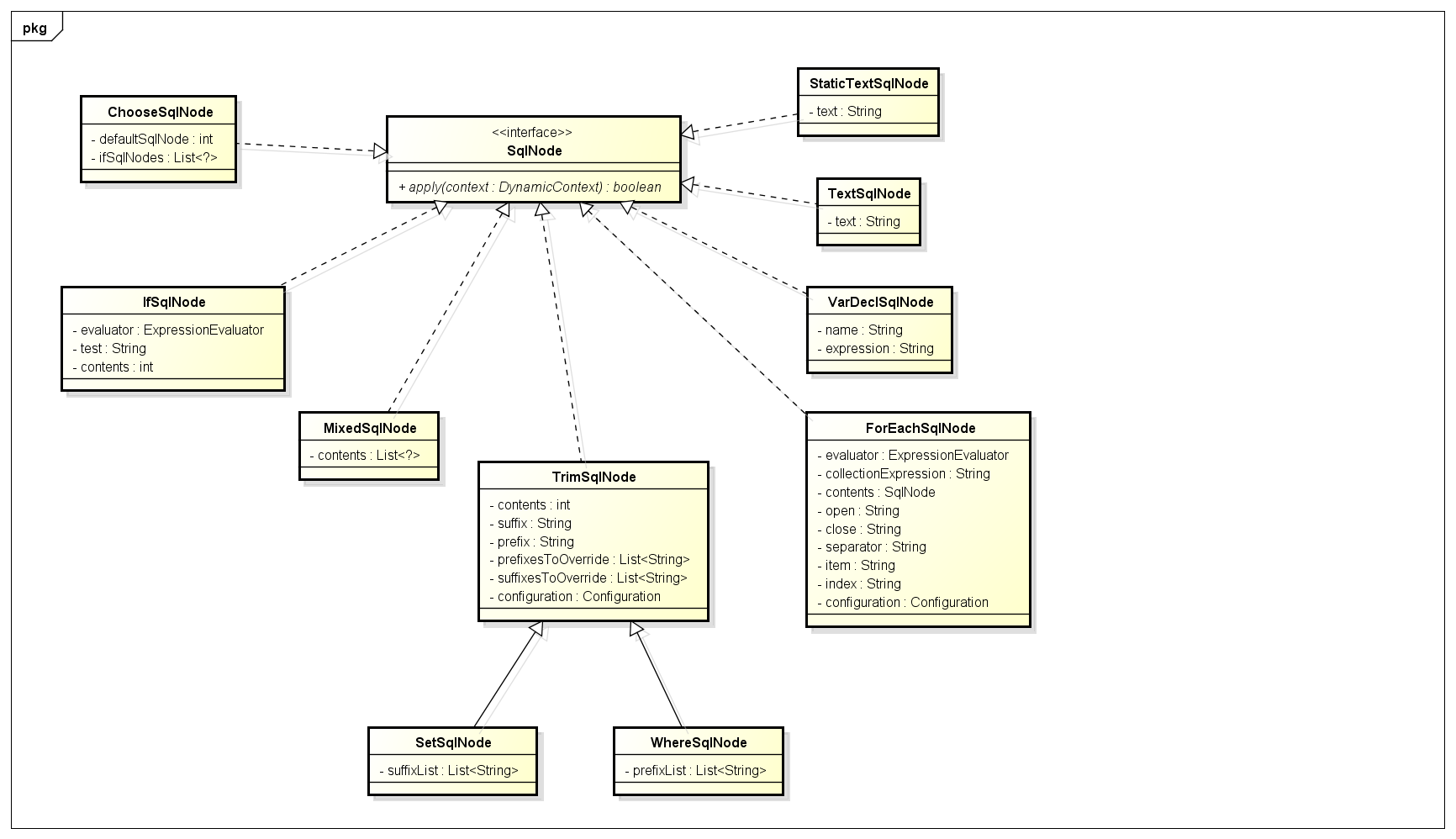
SqlNode接口,简单理解就是xml中的每个标签,比如上述sql的update,trim,if标签:
public interface SqlNode {
boolean apply(DynamicContext context);
}
SqlSource Sql源接口,代表从xml文件或注解映射的sql内容,主要就是用于创建BoundSql,有实现类DynamicSqlSource(动态Sql源),StaticSqlSource(静态Sql源)等:
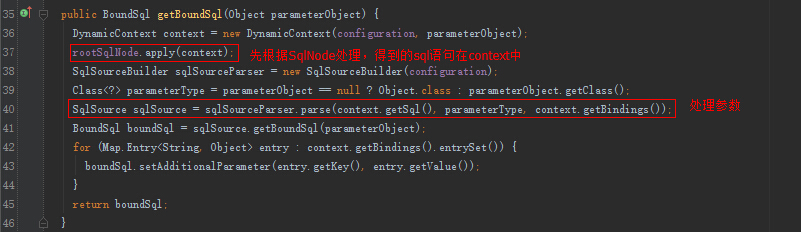
public interface SqlSource {
BoundSql getBoundSql(Object parameterObject);
}
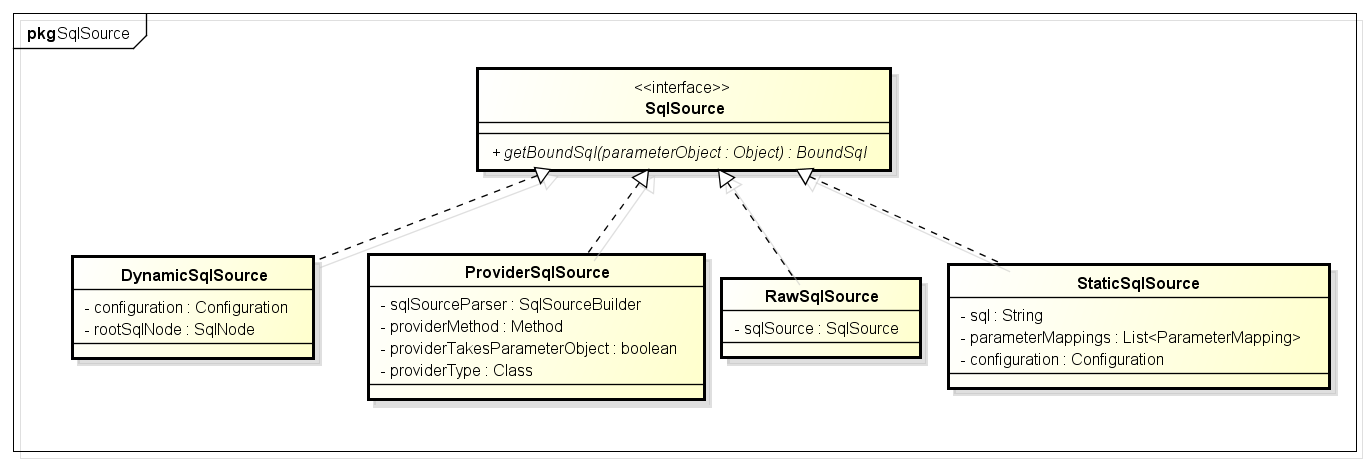
BoundSql类,封装mybatis最终产生sql的类,包括sql语句,参数,参数源数据等参数:
public class BoundSql {
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Object parameterObject;
private final Map<String, Object> additionalParameters;
private final MetaObject metaParameters;
...
}
XNode,一个Dom API中的Node接口的扩展类。
public class XNode {
private final Node node;
private final String name;
private final String body;
private final Properties attributes;
private final Properties variables;
private final XPathParser xpathParser;
...
}
BaseBuilder接口及其实现类,这些Builder的作用就是用于构造sql:
public abstract class BaseBuilder {
protected final Configuration configuration;
protected final TypeAliasRegistry typeAliasRegistry;
protected final TypeHandlerRegistry typeHandlerRegistry;
...
}
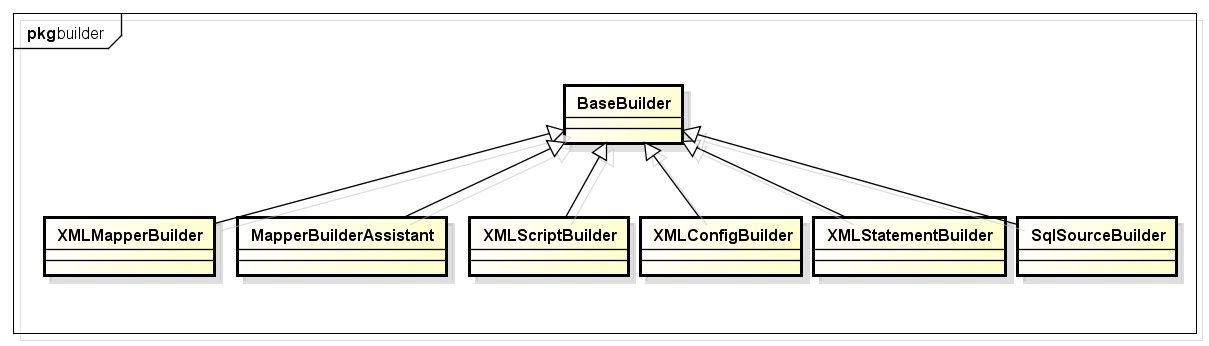
下面我们简单分析下其中4个Builder:
1 XMLConfigBuilder
解析mybatis中configLocation属性中的全局xml文件,内部会使用XMLMapperBuilder解析各个xml文件。
2 XMLMapperBuilder
遍历mybatis中mapperLocations属性中的xml文件中每个节点的Builder,比如user.xml,内部会使用XMLStatementBuilder处理xml中的每个节点。
3 XMLStatementBuilder
解析xml文件中各个节点,比如select,insert,update,delete节点,内部会使用XMLScriptBuilder处理节点的sql部分,遍历产生的数据会丢到Configuration的mappedStatements中。
4 XMLScriptBuilder
解析xml中各个节点sql部分的Builder。
LanguageDriver接口及其实现类,该接口主要的作用就是构造sql:
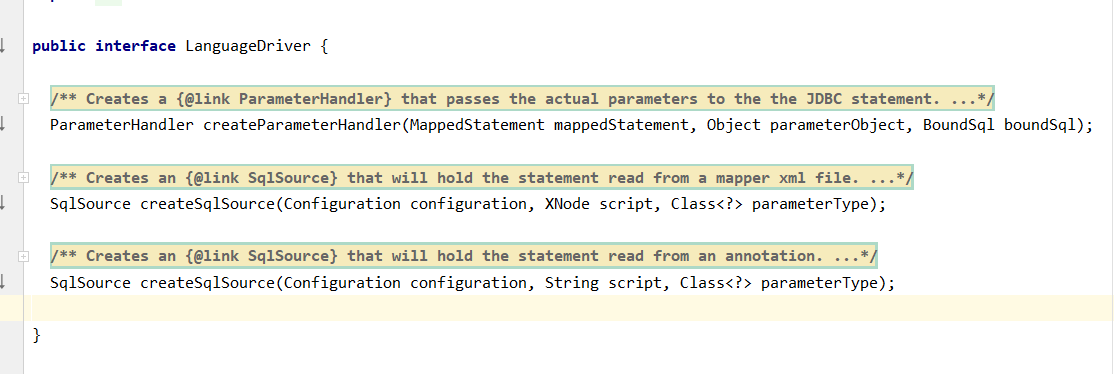
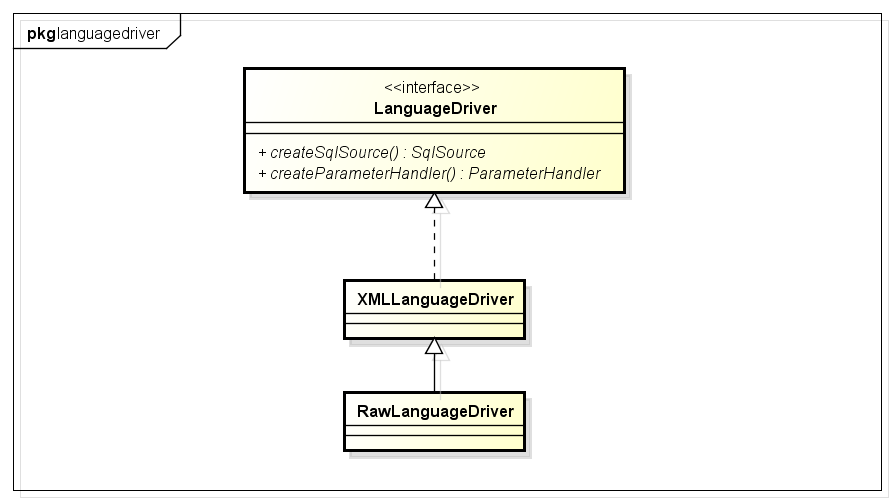
简单分析下XMLLanguageDriver(处理xml中的sql,RawLanguageDriver处理静态sql):
XMLLanguageDriver内部会使用XMLScriptBuilder解析xml中的sql部分。
ok, 大部分比较重要的类我们都已经介绍了,下面源码分析走起。
源码分析走起
SqlSessionFactory方法内部会使用XMLConfigBuilder解析属性configLocation中配置的路径,还会使用XMLMapperBuilder属性解析mapperLocations属性中的各个xml文件。
部分源码如下:
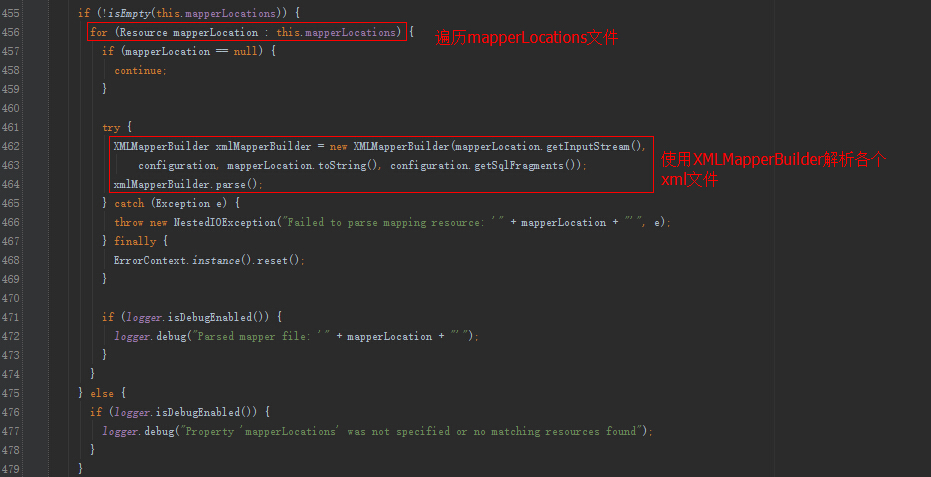
由于XMLConfigBuilder内部也是使用XMLMapperBuilder,我们就看看XMLMapperBuilder的解析细节。
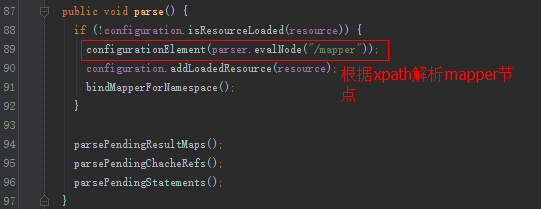

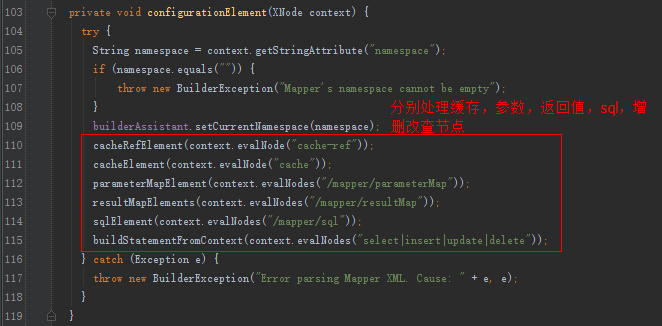
我们关注一下,增删改查节点的解析。
XMLStatementBuilder的解析:
默认会使用XMLLanguageDriver创建SqlSource(Configuration构造函数中设置)。
XMLLanguageDriver创建SqlSource:

XMLScriptBuilder解析sql:
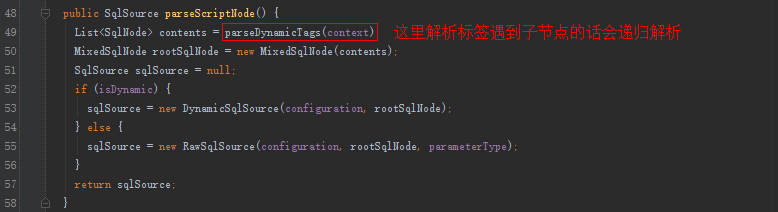
我以以下xml的解析大概说下parseDynamicTags的解析过程:
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>
在看这段解析之前,请先了解dom相关的知识,xml dom知识, dom博文
parseDynamicTags方法的返回值是一个List,也就是一个Sql节点集合。SqlNode本文一开始已经介绍,分析完解析过程之后会说一下各个SqlNode类型的作用。
1 首先根据update节点(Node)得到所有的子节点,分别是3个子节点
(1)文本节点 \n UPDATE users
(2)trim子节点 ...
(3)文本节点 \n where id = #{id}
2 遍历各个子节点
(1) 如果节点类型是文本或者CDATA,构造一个TextSqlNode或StaticTextSqlNode
(2) 如果节点类型是元素,说明该update节点是个动态sql,然后会使用NodeHandler处理各个类型的子节点。这里的NodeHandler是XMLScriptBuilder的一个内部接口,其实现类包括TrimHandler、WhereHandler、SetHandler、IfHandler、ChooseHandler等。看类名也就明白了这个Handler的作用,比如我们分析的trim节点,对应的是TrimHandler;if节点,对应的是IfHandler...
这里子节点trim被TrimHandler处理,TrimHandler内部也使用parseDynamicTags方法解析节点
3 遇到子节点是元素的话,重复以上步骤
trim子节点内部有7个子节点,分别是文本节点、if节点、是文本节点、if节点、是文本节点、if节点、文本节点。文本节点跟之前一样处理,if节点使用IfHandler处理
遍历步骤如上所示,下面我们看下几个Handler的实现细节。
IfHandler处理方法也是使用parseDynamicTags方法,然后加上if标签必要的属性。
private class IfHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
String test = nodeToHandle.getStringAttribute("test");
IfSqlNode ifSqlNode = new IfSqlNode(mixedSqlNode, test);
targetContents.add(ifSqlNode);
}
}
TrimHandler处理方法也是使用parseDynamicTags方法,然后加上trim标签必要的属性。
private class TrimHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
String prefix = nodeToHandle.getStringAttribute("prefix");
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
String suffix = nodeToHandle.getStringAttribute("suffix");
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}
以上update方法最终通过parseDynamicTags方法得到的SqlNode集合如下:
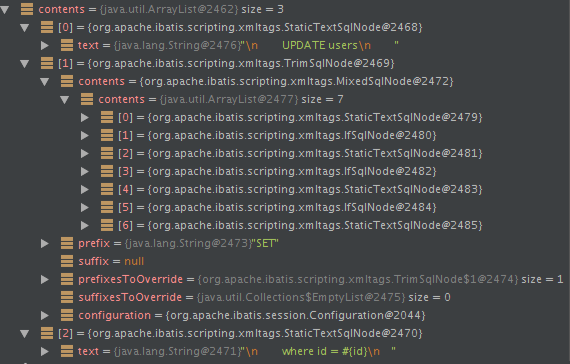
trim节点:
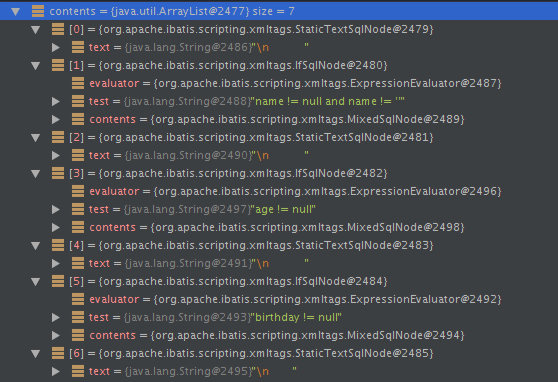
由于这个update方法是个动态节点,因此构造出了DynamicSqlSource。
DynamicSqlSource内部就可以构造sql了:
DynamicSqlSource内部的SqlNode属性是一个MixedSqlNode。
然后我们看看各个SqlNode实现类的apply方法
下面分析一下两个SqlNode实现类的apply方法实现:
MixedSqlNode:
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : contents) {
sqlNode.apply(context);
}
return true;
}
MixedSqlNode会遍历调用内部各个sqlNode的apply方法。
StaticTextSqlNode:
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
直接append sql文本。
IfSqlNode:
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
这里的evaluator是一个ExpressionEvaluator类型的实例,内部使用了OGNL处理表达式逻辑。
TrimSqlNode:
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
TrimSqlNode的apply方法也是调用属性contents(一般都是MixedSqlNode)的apply方法,按照实例也就是7个SqlNode,都是StaticTextSqlNode和IfSqlNode。 最后会使用FilteredDynamicContext过滤掉prefix和suffix。
总结
大致讲解了一下mybatis对动态sql语句的解析过程,其实回过头来看看不算复杂,还算蛮简单的。 之前接触mybaits的时候遇到刚才分析的那一段动态sql的时候总是很费解。
总结
这边结合获取SqlSession的流程,做下简单的总结:
- SqlSessionFactoryBuilder解析配置文件,包括属性配置、别名配置、拦截器配置、环境(数据源和事务管理器)、Mapper配置等;解析完这些配置后会生成一个Configration对象,这个对象中包含了MyBatis需要的所有配置,然后会用这个Configration对象创建一个SqlSessionFactory对象,这个对象中包含了Configration对象;
- 拿到SqlSessionFactory对象后,会调用SqlSessionFactory的openSesison方法,这个方法会创建一个Sql执行器(Executor组件中包含了Transaction对象),这个Sql执行器会代理你配置的拦截器方法。
- 获得上面的Sql执行器后,会创建一个SqlSession(默认使用DefaultSqlSession),这个SqlSession中也包含了Configration对象和上面创建的Executor对象,所以通过SqlSession也能拿到全局配置;
- 获得SqlSession对象后就能执行各种CRUD方法了。
以上是获得SqlSession的流程,下面总结下Sql的执行流程:
- 调用SqlSession的getMapper方法,获得Mapper接口的动态代理对象MapperProxy,调用Mapper接口的所有方法都会调用到MapperProxy的invoke方法(动态代理机制);
- MapperProxy的invoke方法中唯一做的就是创建一个MapperMethod对象,然后调用这个对象的execute方法,sqlSession会作为execute方法的入参;
- 往下,层层调下来会进入Executor组件(如果配置插件会对Executor进行动态代理)的query方法,这个方法中会创建一个StatementHandler对象,这个对象中同时会封装ParameterHandler和ResultSetHandler对象。调用StatementHandler预编译参数以及设置参数值,使用ParameterHandler来给sql设置参数。
Executor组件有两个直接实现类,分别是BaseExecutor和CachingExecutor。CachingExecutor静态代理了BaseExecutor。Executor组件封装了Transction组件,Transction组件中又分装了Datasource组件。
- 调用StatementHandler的增删改查方法获得结果,ResultSetHandler对结果进行封装转换,请求结束。
Executor、StatementHandler 、ParameterHandler、ResultSetHandler,Mybatis的插件会对上面的四个组件进行动态代理。
重要类
- MapperRegistry:本质上是一个Map,其中的key是Mapper接口的全限定名,value的MapperProxyFactory;
- MapperProxyFactory:这个类是MapperRegistry中存的value值,在通过sqlSession获取Mapper时,其实先获取到的是这个工厂,然后通过这个工厂创建Mapper的动态代理类;
- MapperProxy:实现了InvocationHandler接口,Mapper的动态代理接口方法的调用都会到达这个类的invoke方法;
- MapperMethod:判断你当前执行的方式是增删改查哪一种,并通过SqlSession执行相应的操作;
- SqlSession:作为MyBatis工作的主要顶层API,表示和数据库交互的会话,完成必要数据库增删改查功能;
- Executor:MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护;
StatementHandler:封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合。
ParameterHandler:负责对用户传递的参数转换成JDBC Statement 所需要的参数,
ResultSetHandler:负责将JDBC返回的ResultSet结果集对象转换成List类型的集合;
TypeHandler:负责java数据类型和jdbc数据类型之间的映射和转换
MappedStatement:MappedStatement维护了一条节点(一条sql语句)的封装,
SqlSource:负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回
BoundSql:表示动态生成的SQL语句以及相应的参数信息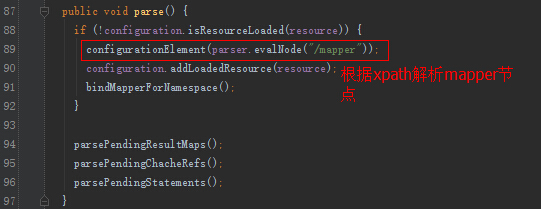
Configuration:MyBatis所有的配置信息都维持在Configuration对象之中。
调试主要关注点
- MapperProxy.invoke方法:MyBatis的所有Mapper对象都是通过动态代理生成的,任何方法的调用都会调到invoke方法,这个方法的主要功能就是创建MapperMethod对象,并放进缓存。所以调试时我们可以在这个位置打个断点,看下是否成功拿到了MapperMethod对象,并执行了execute方法。
- MapperMethod.execute方法:这个方法会判断你当前执行的方式是增删改查哪一种,并通过SqlSession执行相应的操作。Debug时也建议在此打个断点看下。
- DefaultSqlSession.selectList方法:这个方法获取了获取了MappedStatement对象,并最终调用了Executor的query方法;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?