python利用xpath进行图片爬取的简单示例
xpath解析知识点:
- 最常用也是最便捷高效的一种解析方式
- xpath解析原理:
- 1.实例化一个etree的对象,且需要将被解析的页面源码加载到对象中;
- 2.调用etree中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
- 环境的安装:
- pip install lxml
- 如何实例化一个etree对象
- 1.将本地html文档中的源码数据加载到etree对象中:
etree.parse(filePath)
- 2.可以将从互联网上获取的源码数据加载到该对象中
etree.HTML('page_text')
- xpath('xpath表达式')
- xpath表达式:
- /:表示的是从根节点开始定位,表示的是一个层级
- //:表示的是多个层级,表示从任意位置开始定位
- 属性定位://div[@class='card zz_other_shici'] (通用写法://tag[@attrName='attrValue'])
- 索引定位://div[@class="card zz_other_shici"]/ul/li[3] ,索引从1开始,表示定位第3个li标签
- 取文本:
- /text()是获取标签中直系的文本内容
- //text()是获取标签中所有的文本内容
- 取属性:
- /@attrName
- 其他
- 解决中文乱码问题:
如:str 显示乱码,解决方法:str = str.encode('iso-8859-1').decode('gbk')
代码:
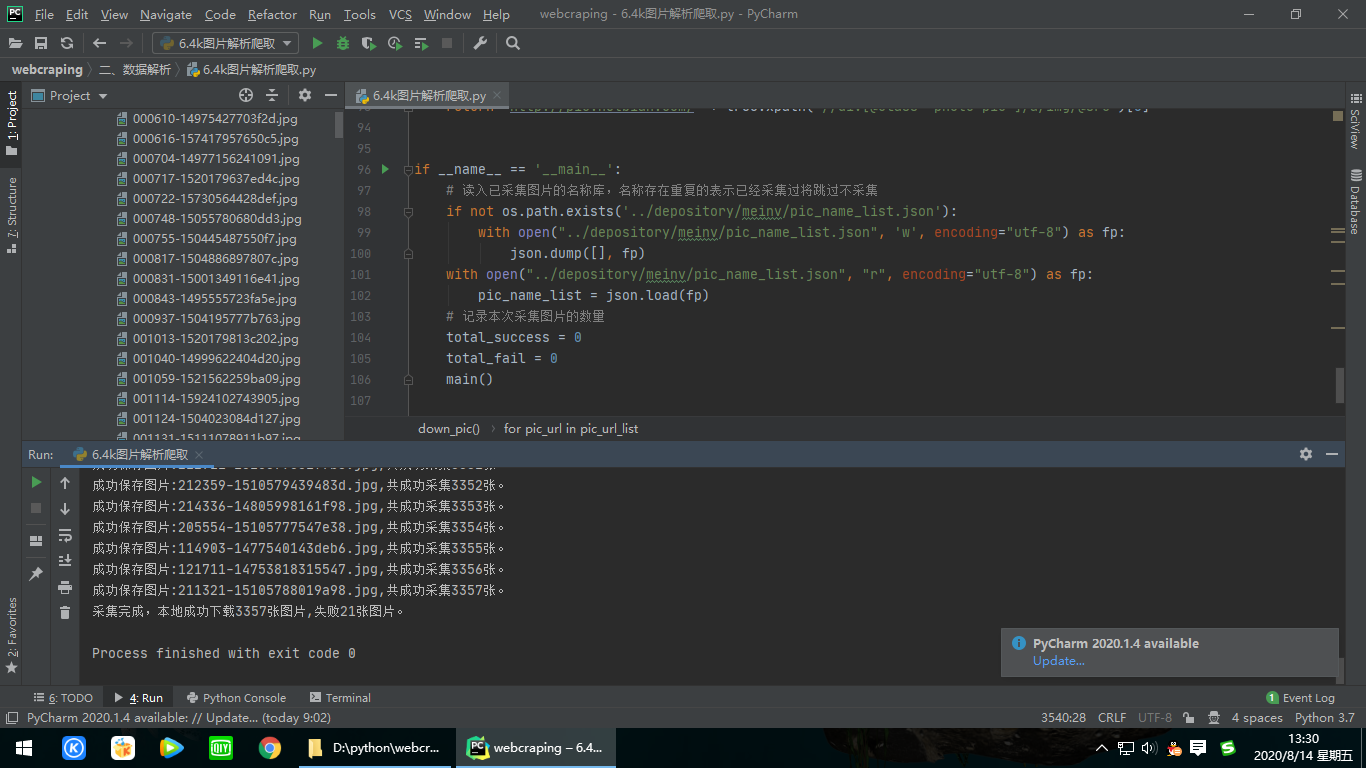
1 # _*_ coding:utf-8 _*_ 2 """ 3 @FileName :6.4k图片解析爬取.py 4 @CreateTime :2020/8/14 0014 10:01 5 @Author : Lurker Zhang 6 @E-mail : 289735192@qq.com 7 @Desc. : 8 """ 9 10 import requests 11 from lxml import etree 12 from setting.config import * 13 import json 14 import os 15 import time 16 17 18 def main(): 19 # 图片采集源地址 20 source_url = 'http://pic.netbian.com/4kmeinv/' 21 temp_url = 'http://pic.netbian.com/4kmeinv/index_{}.html' 22 # 本此采集前多少页,大于1的整数 23 page_sum = 5 24 if page_sum == 1: 25 pic_list_url = source_url 26 print('开始下载:'+pic_list_url) 27 down_pic(pic_list_url) 28 else: 29 # 先采集第一页 30 pic_list_url = source_url 31 # 调用采集单页图片链接的函数 32 down_pic(pic_list_url) 33 # 再采集第二页开始后面的页数 34 for page_num in range(2, page_sum + 1): 35 pic_list_url = temp_url.format(page_num) 36 print('开始下载:'+pic_list_url) 37 down_pic(pic_list_url) 38 39 print('采集完成,本地成功下载{0}张图片,失败{1}张图片。'.format(total_success, total_fail)) 40 # 存储已下载文件名列表: 41 with open("../depository/meinv/pic_name_list.json",'w',encoding='utf-8') as fp: 42 json.dump(pic_name_list,fp) 43 44 45 def down_pic(pic_list_url): 46 global total_success, total_fail,pic_name_list 47 # 获取图片列表页的网页数据 48 pic_list_page_text = requests.get(url=pic_list_url, headers=headers).text 49 tree_1 = etree.HTML(pic_list_page_text) 50 # 获取图片地址列表 51 pic_show_url_list = tree_1.xpath('//div[@class="slist"]/ul//a/@href') 52 pic_url_list = [get_pic_url('http://pic.netbian.com' + pic_show_url) for pic_show_url in pic_show_url_list] 53 54 # 开始下载并保存图片 55 for pic_url in pic_url_list: 56 picname = get_pic_name(pic_url) 57 if not picname in pic_name_list: 58 if save_pic(pic_url, picname): 59 # 将下载过的图片记录到已下载图片的列表中 60 pic_name_list.append(picname) 61 total_success += 1 62 print("成功保存图片:{0},共成功采集{1}张。".format(picname,total_success)) 63 64 else: 65 print(picname + "保存失败") 66 total_fail += 1 67 else: 68 print("跳过,已下载过图片:" + picname) 69 total_fail += 1 70 71 72 def save_pic(pic_url, picname): 73 # 获取日期作为保存位置文件夹 74 path = '../depository/meinv/' + time.strftime('%Y%m%d', time.localtime()) + '/' 75 if not os.path.exists(path): 76 os.mkdir(path) 77 pic = requests.get(url=pic_url, headers=headers).content 78 try: 79 with open(path + picname, 'wb') as fp: 80 fp.write(pic) 81 except IOError: 82 return 0 83 else: 84 return 1 85 86 87 def get_pic_name(pic_url): 88 return pic_url.split('/')[-1] 89 90 91 def get_pic_url(pic_show_url): 92 tree = etree.HTML(requests.get(url=pic_show_url, headers=headers).text) 93 return 'http://pic.netbian.com/' + tree.xpath('//div[@class="photo-pic"]/a/img/@src')[0] 94 95 96 if __name__ == '__main__': 97 # 读入已采集图片的名称库,名称存在重复的表示已经采集过将跳过不采集 98 if not os.path.exists('../depository/meinv/pic_name_list.json'): 99 with open("../depository/meinv/pic_name_list.json", 'w', encoding="utf-8") as fp: 100 json.dump([], fp) 101 with open("../depository/meinv/pic_name_list.json", "r", encoding="utf-8") as fp: 102 pic_name_list = json.load(fp) 103 # 记录本次采集图片的数量 104 total_success = 0 105 total_fail = 0 106 main()
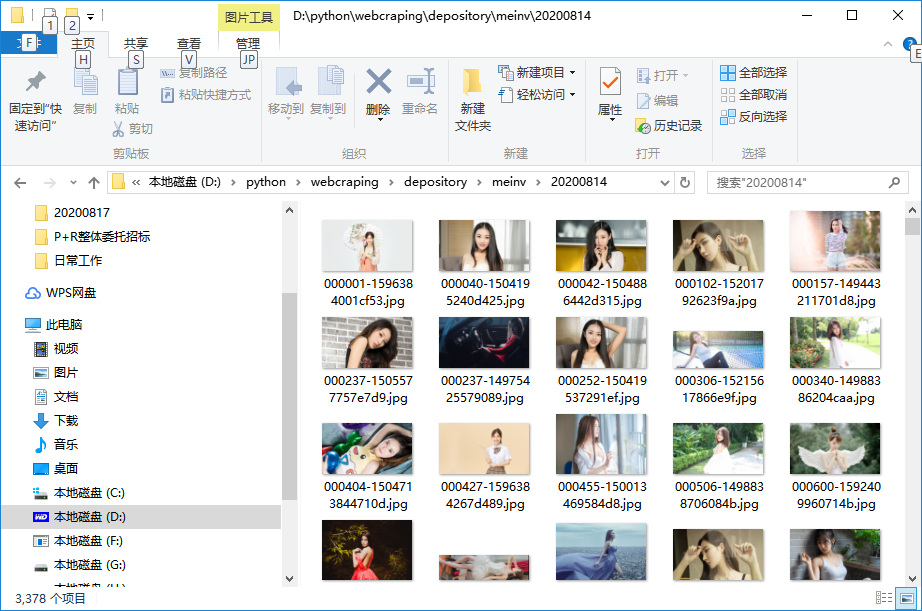
运行结果: