MySQL_3_执行计划
MySQL的核心是存储引擎。
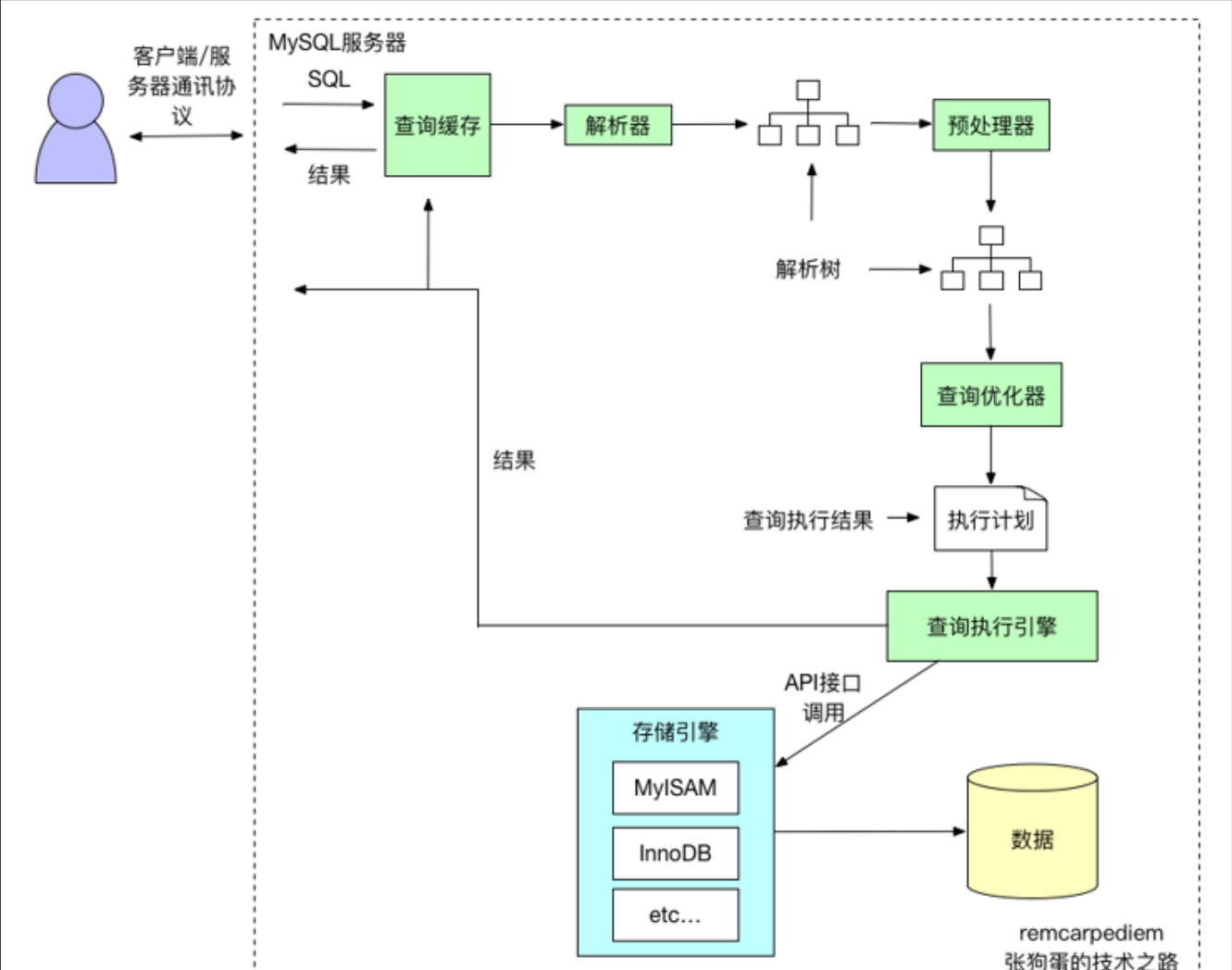
一、查询过程
1、客户端向MySQL服务器发送查询请求。
2、检查查询缓存,缓存命中直接返回数据,否则进入下一阶段。
3、服务器进行SQL解析、预处理、由优化器生成对应的执行计划。
SQL解析:
软解析:在缓存中找到了执行计划。
硬解析:缓存中没有找到对应的执行计划,则由优化器生成执行计划。
4、根据执行计划调用存储引擎的API来执行查询。
5、返回结果给客服端,同时缓存查询结果。
二、执行计划
通过关键字explain查看执行计划:
explain 查询语句;
例子:
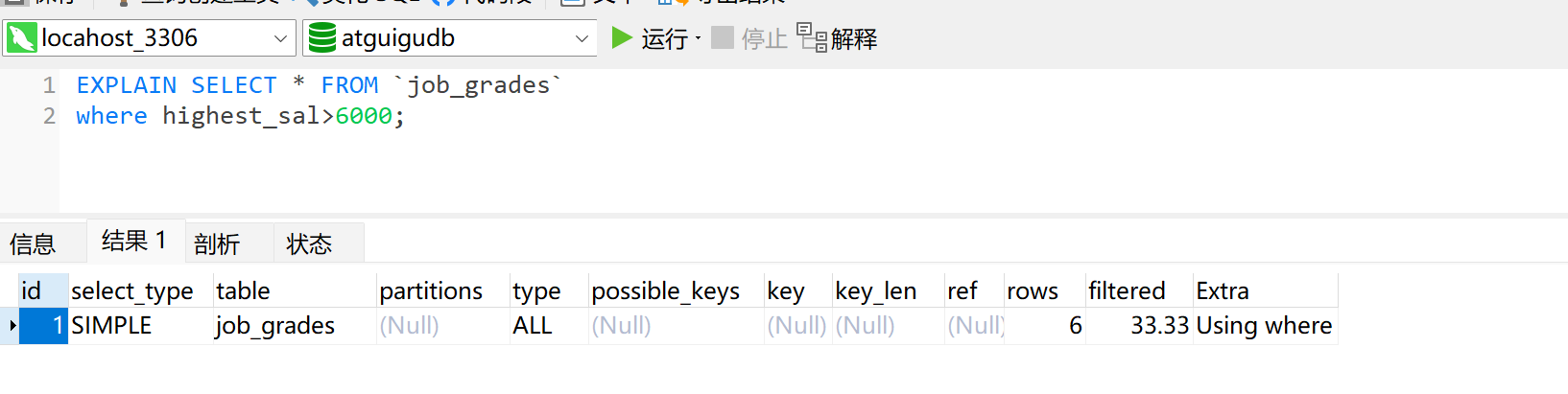
字段解释:
id:执行顺序,值越高,优先级越高,相同则由上至下执行。
select_type:查询类型:
simple,查询中不包括子查询或union。
primary,查询中包含复杂子部分,最外层的查询被标记为primary。
derived,在from列表中包含子查询。
subquery,在select或where子句中包含子查询,子查询被标记为subquery。
union,两个select查询,前者被标记为primary,后者被标记为union。union出现在from子查询中,union中第一个查询为derived,第二个为union。
union result,从union表获取结果的select被标记为union result。
table:显示这一行数据是关于哪个表,会显示别名。
partition:数据来源,如果表做了分区,则会显示数据来源哪个分区。
type:连接使用的类型,最忧-最差:system、const、eq_reg、range、index、all。
system,表中只有一条数据。如果查询的为物理表,则为all。
const,查询结果只有一条数据。
eq_ref,使用了主键索引,或者非空唯一索引,在表中只有一条记录与索引键相匹配,匹配条件是某个表的列(需要转义替换才能拿到值)。
ref,非唯一性索引扫描,和eq_ref 不同的是eq_ref 匹配的是唯一索引,ref它返回所有匹配某个单独值的行,它可能会找到多个符合条件的行。
range,在有索引的字段中使用范围查询。
index,对索引树进行扫描。
all,全表扫描。
possible_keys,:查询字段涉及到的索引,可能未使用。
key:实际使用的索引。
key_len:索引中使用的字节数。
ref:实际用到的索引是哪个表的列, const代表常量。
rows:估计查询需要读取的行数。
fitered:通过条件过滤出的函数的百分比估计值。
Extra:解析查询的额外信息,包括使用了什么索引、排序方式、临时表。
using where : 使用了where条件。
using index: 使用了覆盖索引 (通常情况下这是一种好现象,意味着查询的数据直接在二级索引返回了,从而减少了回表的过程)。
using filesort : 文件排序,意思就是使用了非索引的字段进行排序(通常这种情况需要优化)。
using index sort : 使用索引排序 (通常情况下这是一种好现象,索引天然有序,所以避免了通过sort buffer来排序的流程)。
using temporary : 使用了临时表(常见于group by、order by)。
using join buffer : 使用了join buffer缓存(这种情况关注一下关联查询的字段是不是没有建索引)。
三、存储引擎
对数据文件进行操作的程序。
查看当前可使用的存储引擎:
show ENGINES;
常见的数据库引擎:
1、Isam,支持索引查询,查询效率高,不支持事务处理,不支持数据恢复。需要经常手动备份。
2、MyIsam,是isam的扩展,添加了锁机制,不支持事务处理,不支持外键,需要经常使用Optimize Table命令清理空间。会生成三个文件:.frm,表信息结构,.MYD,数据文件,.MYI,表的索引信息。
3、InnoDB,支持事务,支持外键,查询效率比Isam低。(5.5以后的默认存储引擎。)
修改数据库级别存储引擎:
1、修改my.ini配置文件:default-storage-engine=存储引擎名称
2、重启MySQL
修改表级别存储引擎:
alter table 表名 ENGINES=存储引擎名



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步