Hadoop2.X HA搭建
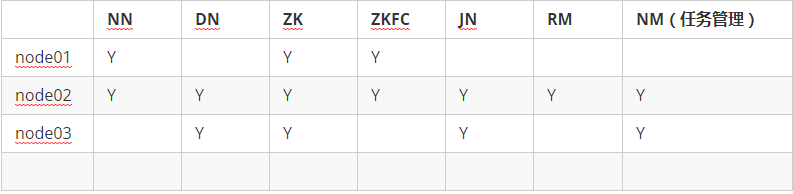
三台机器:node01, node02, node03
Hadoop-env.sh:配置jdk(hadoop 1x已配置)
配置类似于hadoop1.x,依次配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Jackie</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.nameservices</name>
<value>sxt</value>
</property>
<property>
<name>dfs.ha.namenodes.sxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn2</name>
<value>node02:50070</value>
</property>
<property>
<!-- 指定namenode元数据存储在journalnode中的路径 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/sxt</value>
</property>
<property>
<!-- 指定HDFS客户端连接active namenode的java类 -->
<name>dfs.client.failover.proxy.provider.Jackie</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置隔离机制为ssh 防止**脑裂** -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!-- 指定秘钥的位置 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<!-- 指定journalnode日志文件存储的路径 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/data</value>
</property>
<property>
<!-- 开启自动故障转移 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
3.配置hadoop中的slaves(1.x已配置)
4.准备zookeeper:
a) 三台zookeeper:hadoop1,hadoop2,hadoop3
b) 编辑zoo.cfg配置文件
i. 修改dataDir=/opt/zookeeper
ii. server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
c) 在dataDir目录中创建一个myid的文件,文件内容分别为1,2,3
5.发送其他节点服务器 环境变量配置
------------------------------------------------------------------------------------------------------------------------------------------
6.启动三个zookeeper:./zkServer.sh start
7.启动三个JournalNode:./hadoop-daemon.sh start journalnode
8.在其中一个namenode上格式化:hdfs namenode -format
9.
a) 启动刚刚格式化的namenode : hadoop-daemon.sh start namenode
b) 在没有格式化的namenode上执行:hdfs namenode -bootstrapStandby
c) 启动第二个namenode hadoop-daemon.shstart namenode
10.在其中一个namenode上初始化zkfc:hdfs zkfc -formatZK
11.停止上面节点:stop-dfs.sh
12.全面启动:start-dfs.sh
13.yarn-daemon.sh start resourcemanager (yarn resourcemanager )
-----------------------------------------------------------------------------------------------------------------
总结:
1, 确认每台机器防火墙均关掉
2, 确认每台机器的时间是一致的
3, 确认配置文件无误,并且确认每台机器上面的配置文件一样
4, 如果还有问题想重新格式化,那么先把所有节点的进程关掉,killjavaall
5, 删除之前格式化的数据目录hadoop.tmp.dir属性对应的目录,所有节点同步都删掉,别单删掉之前的一个,删掉三台JN节点中dfs.journalnode.edits.dir属性所对应的目录
6, 接上面的第6步又可以重新格式化已经启动了
7, 最终Active Namenode停掉的时候,StandBy可以自动接管!
