常见的分布式协议与算法
我这里将主要列举一致性Hash算法、Gossip协议、QuorumNWR算法、PBFT算法、PoW算法、ZAB协议,Paxos会分开单独讲,Raft算法已经写好了一篇文章,具体可以参考:从JRaft来看Raft协议实现细节。
一致性Hash算法
一致性Hash算法是为了解决Hash算法的迁移成本,以一个10节点的集群为例,如果向集群中添加节点时,如果使用了哈希 算法,需要迁移高达 90.91% 的数据,使用一致哈希的话,只需要迁移 6.48% 的数据。
所以使用一致性Hash算法实现哈希寻址时,可以通过增加节点数降低节点 宕机对整个集群的影响,以及故障恢复时需要迁移的数据量。后续在需要时,你可以通过增 加节点数来提升系统的容灾能力和故障恢复效率。而做数据迁移时,只需要迁移部分数据,就能实现集群的稳定。
不带虚拟节点的一致性Hash算法
我们都知道普通的Hash算法是通过取模来进行路由寻址的,同理一致性Hash用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模 运算,而一致哈希算法是对 2^32 进行取模运算。你可以想象下,一致哈希算法,将整个 哈希值空间组织成一个虚拟的圆环,也就是哈希环:

在一致哈希中,你可以通过执行哈希算法,将节点映射到哈希环上,从而每个节点就能确定其在哈希环上的位置了:
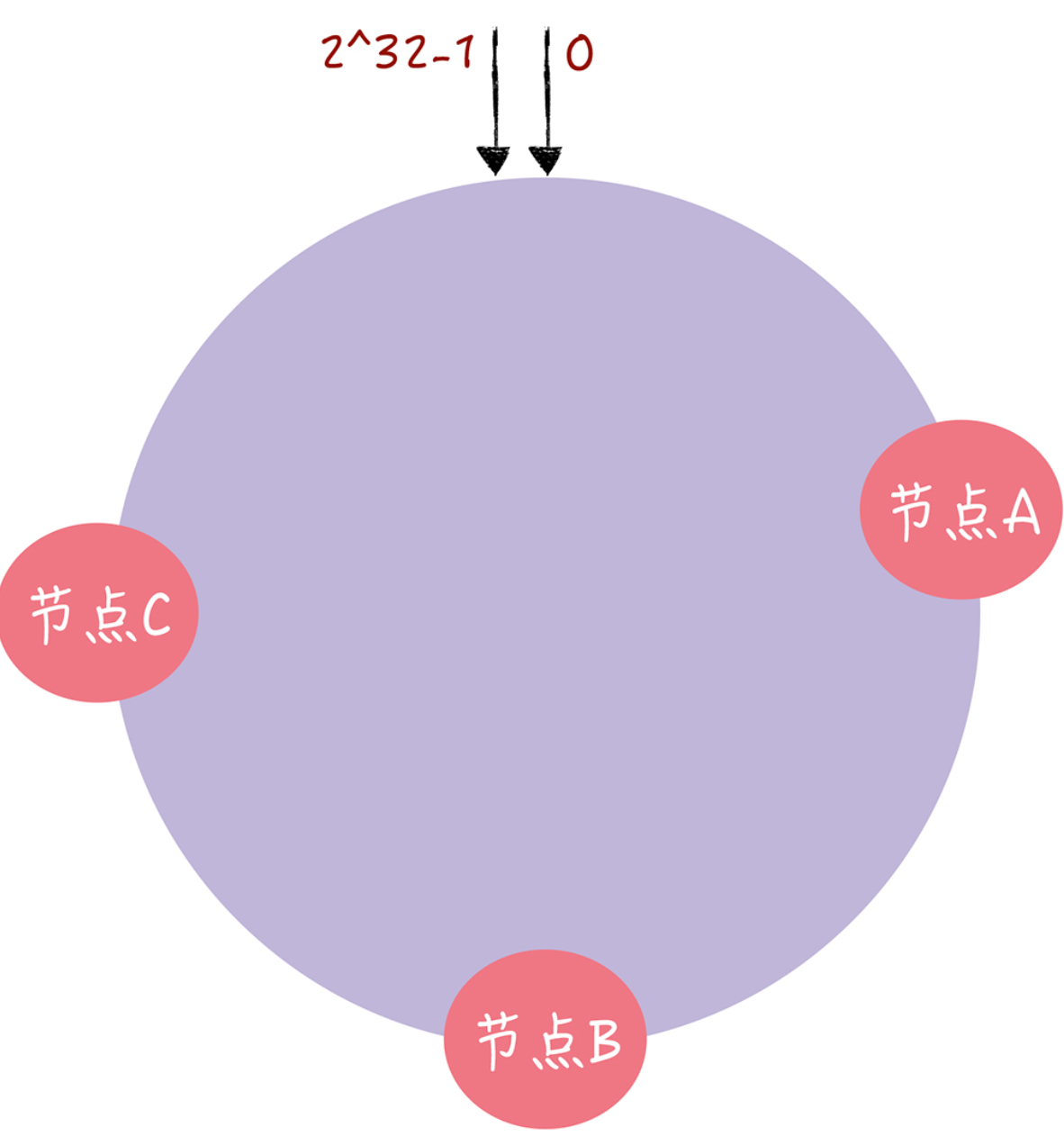
然后当要读取指定key的值的时候,通过对key做一个hash,并确定此 key 在环上的位置,从这个位置沿着哈希环顺时针“行走”,遇到的第一节点就是 key 对应的节点。
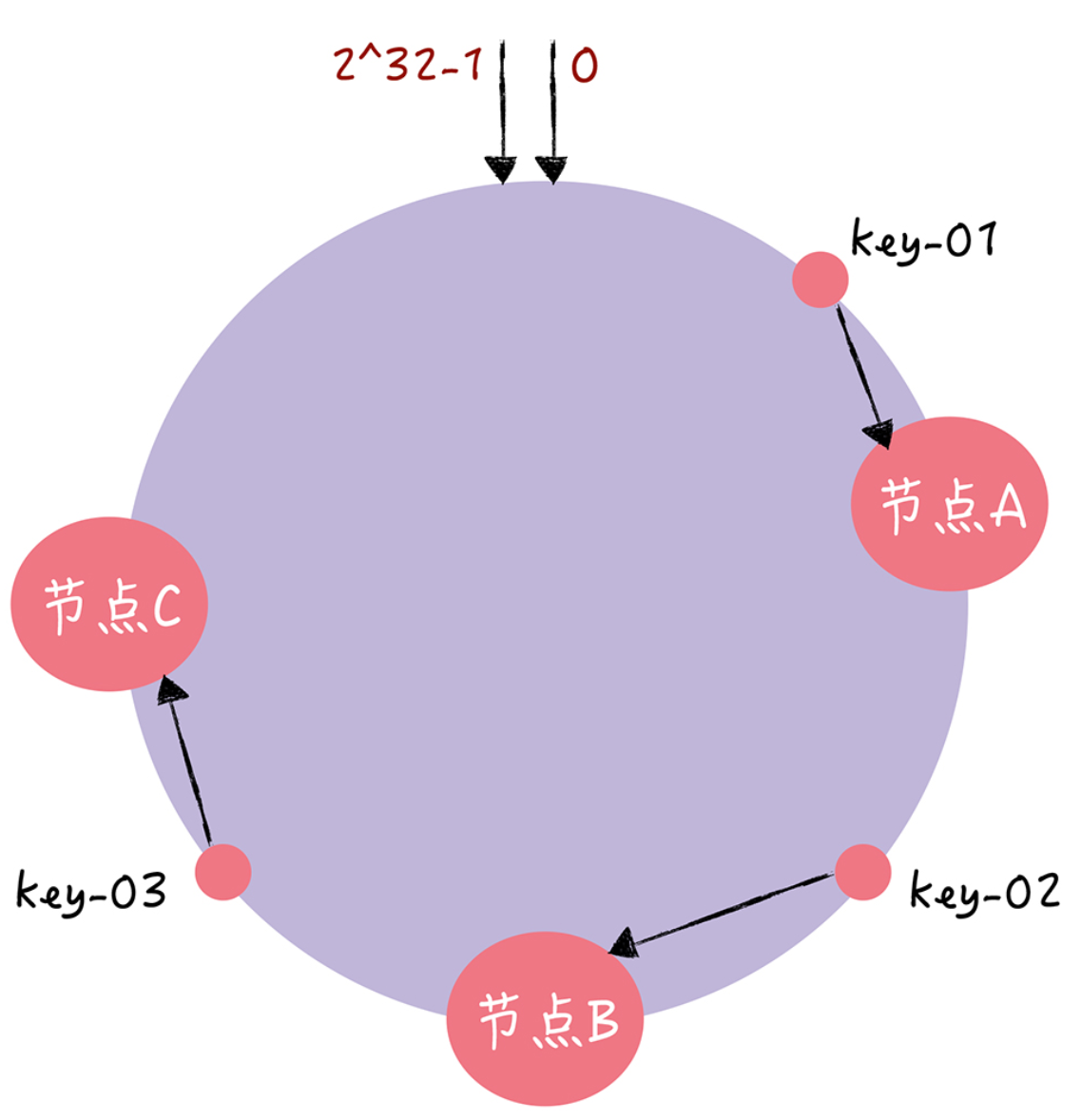
这个时候,如果节点C宕机了,那么节点B和节点A的数据实际上不会受影响,只有原来在节点C的数据会被重新定位到节点A,从而只要节点C的数据做迁移即可。
如果此时集群不能满足业务的需求,需要扩容一个节点:
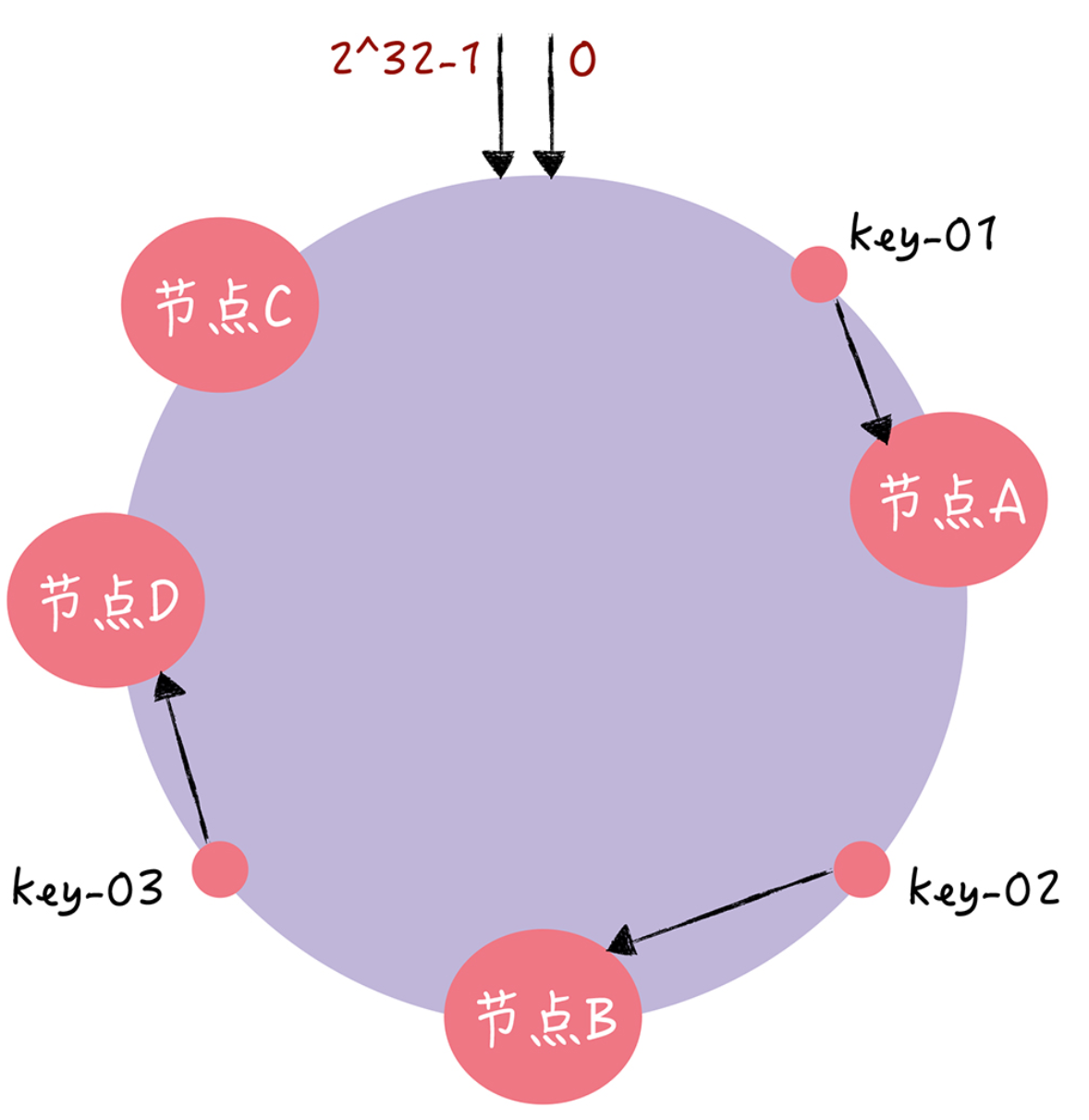
你可以看到,key-01、key-02 不受影响,只有 key-03 的寻址被重定位到新节点 D。一般 而言,在一致哈希算法中,如果增加一个节点,受影响的数据仅仅是,会寻址到新节点和前 一节点之间的数据,其它数据也不会受到影响。
实现代码如下:
/**
* 不带虚拟节点的一致性Hash算法
*/
public class ConsistentHashingWithoutVirtualNode
{
/**
* 待添加入Hash环的服务器列表
*/
private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"};
/**
* key表示服务器的hash值,value表示服务器的名称
*/
private static SortedMap<Integer, String> sortedMap =
new TreeMap<Integer, String>();
/**
* 程序初始化,将所有的服务器放入sortedMap中
*/
static
{
for (int i = 0; i < servers.length; i++)
{
int hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
System.out.println();
}
/**
* 得到应当路由到的结点
*/
private static String getServer(String node)
{
// 得到带路由的结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的所有Map
SortedMap<Integer, String> subMap =
sortedMap.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
// 返回对应的服务器名称
return subMap.get(i);
}
public static void main(String[] args)
{
String[] nodes = {"127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333"};
for (int i = 0; i < nodes.length; i++)
System.out.println("[" + nodes[i] + "]的hash值为" +
getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]");
}
}
带虚拟节点的一致性Hash算法
上面的hash算法可能会造成数据分布不均匀的情况,也就是 说大多数访问请求都会集中少量几个节点上。所以我们可以通过虚拟节点的方式解决数据分布不均的情况。
其实,就是对每一个服务器节点计算多个哈希值,在每个计算结果位置上,都放置一个虚拟 节点,并将虚拟节点映射到实际节点。比如,可以在主机名的后面增加编号,分别计算 “Node-A-01”,“Node-A-02”,“Node-B-01”,“Node-B-02”,“Node-C01”,“Node-C-02”的哈希值,于是形成 6 个虚拟节点:
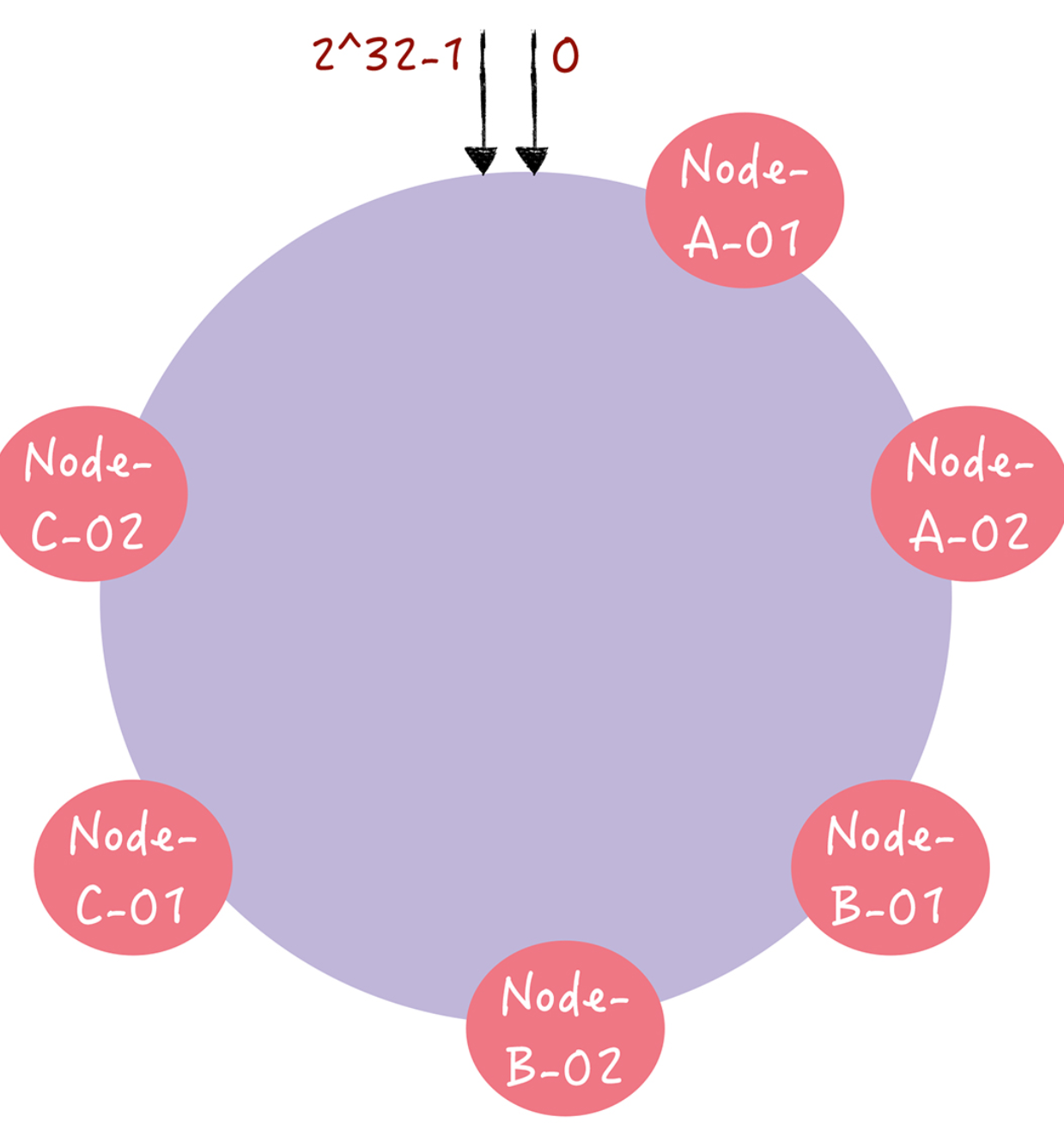
增加了节点后,节点在哈希环上的分布就相对均匀了。这时,如果有访 问请求寻址到“Node-A-01”这个虚拟节点,将被重定位到节点 A。
具体代码实现如下:
/**
* 带虚拟节点的一致性Hash算法
*/
public class ConsistentHashingWithVirtualNode
{
/**
* 待添加入Hash环的服务器列表
*/
private static String[] servers = {"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"};
/**
* 真实结点列表,考虑到服务器上线、下线的场景,即添加、删除的场景会比较频繁,这里使用LinkedList会更好
*/
private static List<String> realNodes = new LinkedList<String>();
/**
* 虚拟节点,key表示虚拟节点的hash值,value表示虚拟节点的名称
*/
private static SortedMap<Integer, String> virtualNodes =
new TreeMap<Integer, String>();
/**
* 虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应5个虚拟节点
*/
private static final int VIRTUAL_NODES = 5;
static
{
// 先把原始的服务器添加到真实结点列表中
for (int i = 0; i < servers.length; i++)
realNodes.add(servers[i]);
// 再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高
for (String str : realNodes)
{
for (int i = 0; i < VIRTUAL_NODES; i++)
{
String virtualNodeName = str + "&&VN" + String.valueOf(i);
int hash = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
System.out.println();
}
/**
* 得到应当路由到的结点
*/
private static String getServer(String node)
{
// 得到带路由的结点的Hash值
int hash = getHash(node);
// 得到大于该Hash值的所有Map
SortedMap<Integer, String> subMap =
virtualNodes.tailMap(hash);
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
// 返回对应的虚拟节点名称,这里字符串稍微截取一下
String virtualNode = subMap.get(i);
return virtualNode.substring(0, virtualNode.indexOf("&&"));
}
public static void main(String[] args)
{
String[] nodes = {"127.0.0.1:1111", "221.226.0.1:2222", "10.211.0.1:3333"};
for (int i = 0; i < nodes.length; i++)
System.out.println("[" + nodes[i] + "]的hash值为" +
getHash(nodes[i]) + ", 被路由到结点[" + getServer(nodes[i]) + "]");
}
}
Gossip协议
Gossip 协议,顾名思义,就像流言蜚语一样,利用一种随机、带有传染性的方式,将信息 传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。Gossip 协议通过上面的特性,可以保证系统能在极端情况下(比如集群中只有一个节点在运行)也能运行。
Gossip数据传播方式
Gossip数据传播方式分别有:直接邮寄(Direct Mail)、反熵(Anti-entropy)和谣言传播 (Rumor mongering)。
直接邮寄(Direct Mail):就是直接发送更新数据,当数据发送失败时,将数据缓存下来,然后重传。直接邮寄虽然实现起来比较容易,数据同步也很及时,但可能会因为 缓存队列满了而丢数据。也就是说,只采用直接邮寄是无法实现最终一致性的。
反熵(Anti-entropy):反熵指的是集群中的节点,每隔段时间就随机选择某个其他节点,然后通过互相交换自己的 所有数据来消除两者之间的差异,实现数据的最终一致性。
在实现反熵的时候,主要有推、拉和推拉三种方式。推方式,就是将自己的所有副本数据,推给对方,修复对方副本中的熵,拉方式,就是拉取对方的所有副本数据,修复自己副本中的熵。
谣言传播 (Rumor mongering):指的是当一个节点有了新数据后,这个节点变成活跃状态,并周期性地联系其他节点向其发送新数据,直到所有的节点都存储了该新数据。由于谣言传播非常具有传染性,它适合动态变化的分布式系统
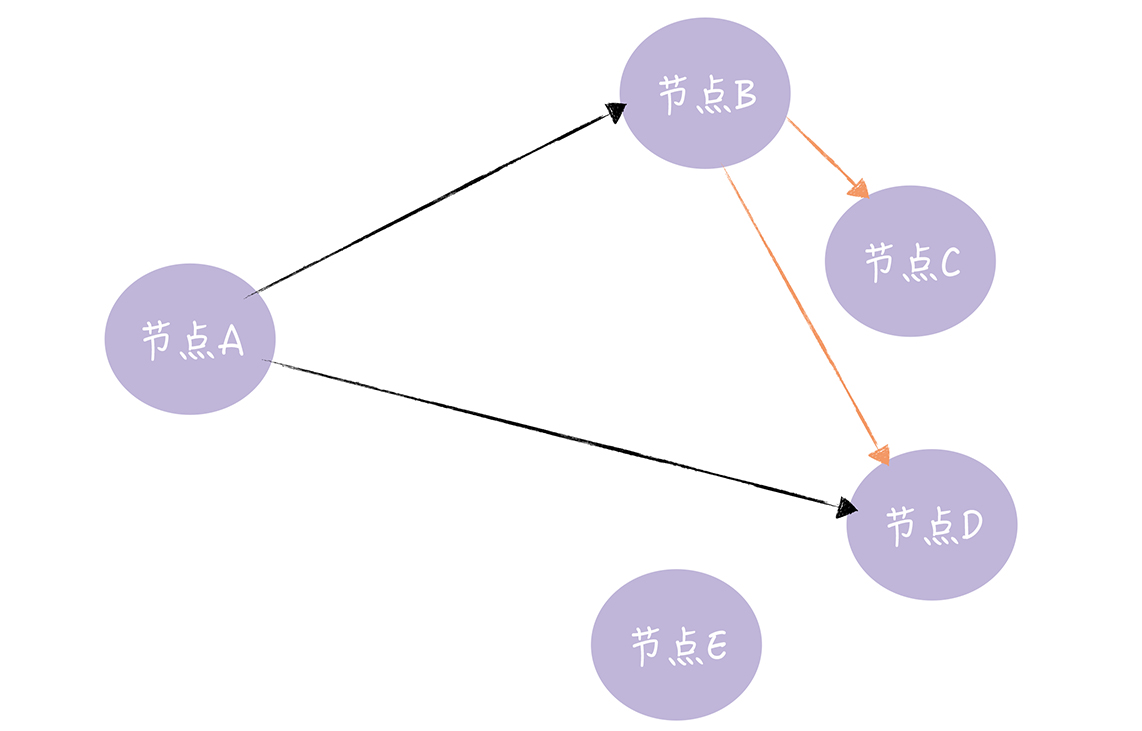
Quorum NWR算法
Quorum NWR 中有三个要素,N、W、R。
N 表示副本数,又叫做复制因子(Replication Factor)。也就是说,N 表示集群中同一份 数据有多少个副本,就像下图的样子:
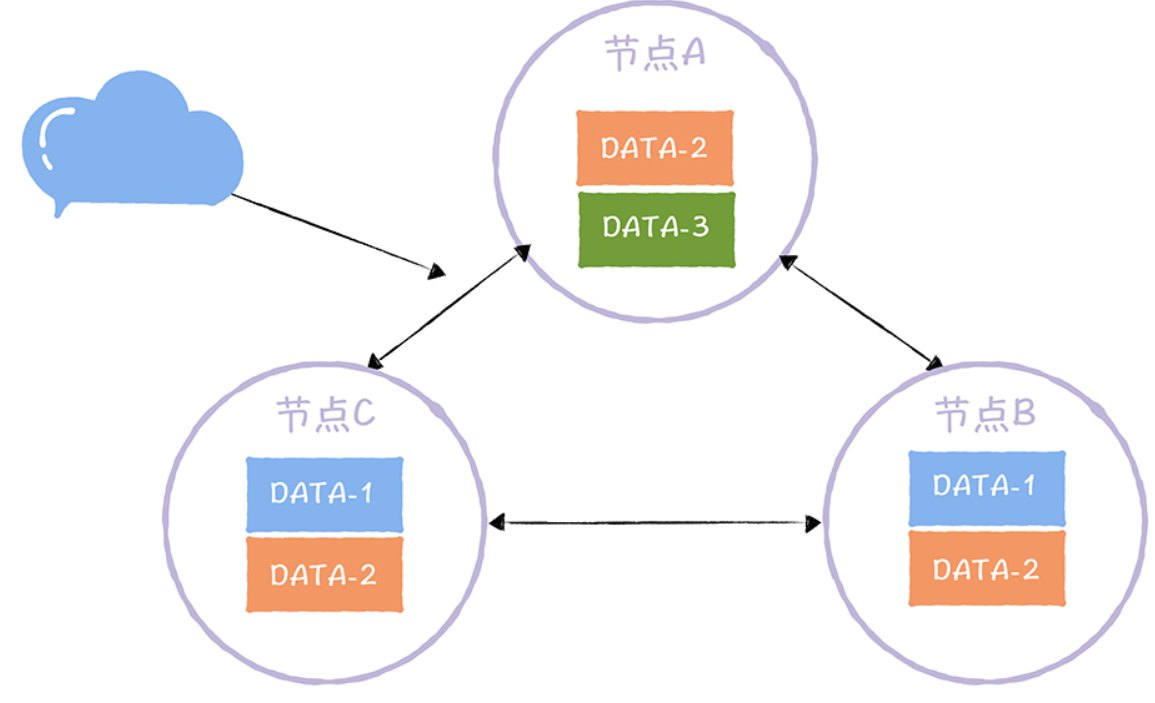
在这个三节点的集群中,DATA-1 有 2 个副本,DATA-2 有 3 个副 本,DATA-3 有 1 个副本。也就是说,副本数可以不等于节点数,不同的数据可以有不同 的副本数。
W,又称写一致性级别(Write Consistency Level),表示成功完成 W 个副本更新。
R,又称读一致性级别(Read Consistency Level),表示读取一个数据对象时需要读 R 个副本。
通过 Quorum NWR,你可以自定义一致性级别,通过临时调整写入或者查询的方式,当 W + R > N 时,就可以实现强一致性了。
所以假如要读取节点B,我们再假设W(2) + R(2) > N(3)这个公式,也就是当写两个节点,读的时候也同时读取两个节点,那么读取数据的时候肯定是读取返回给客户端肯定是最新的那份数据。
关于 NWR 需要你注意的是,N、W、R 值的不同组合,会产生不同的一致性效 果,具体来说,有这么两种效果:
当 W + R > N 的时候,对于客户端来讲,整个系统能保证强一致性,一定能返回更新后的那份数据。
当 W + R < N 的时候,对于客户端来讲,整个系统只能保证最终一致性,可能会返回旧数据。
PBFT算法
PBFT 算法非常实用,是一种能在实际场景中落地的拜占庭容错算法。
我们从一个例子入手,看看PBFT 算法的具体实现:
假设苏秦再一次带队抗秦,这一天,苏秦和 4 个国家的 4 位将军赵、魏、韩、楚商量军机 要事,结果刚商量完没多久苏秦就接到了情报,情报上写道:联军中可能存在一个叛徒。这 时,苏秦要如何下发作战指令,保证忠将们正确、一致地执行下发的作战指令,而不是被叛 徒干扰呢?
需要注意的是,所有的消息都是签名消息,也就是说,消息发送者的身份和消息内容都是 无法伪造和篡改的(比如,楚无法伪造一个假装来自赵的消息)。
首先,苏秦联系赵,向赵发送包含作战指令“进攻”的请求(就像下图的样子)。

当赵接收到苏秦的请求之后,会执行三阶段协议(Three-phase protocol)。
赵将进入预准备(Pre-prepare)阶段,构造包含作战指令的预准备消息,并广播给其他 将军(魏、韩、楚)。
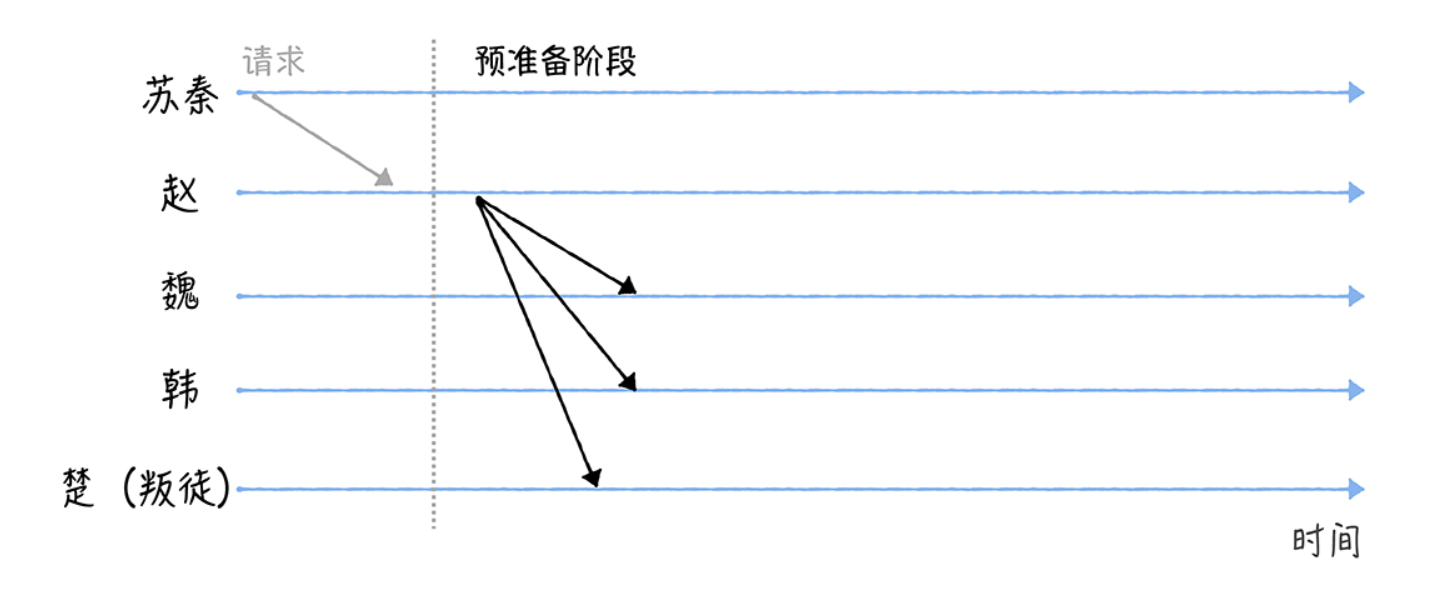
因为魏、韩、楚,收到消息后,不能确认自己接收到指令和其他人接收到的指令是相同的。所以需要进入下一个阶段。
接收到预准备消息之后,魏、韩、楚将进入准备(Prepare)阶段,并分别广播包含作战 指令的准备消息给其他将军。
比如,魏广播准备消息给赵、韩、楚(如图所示)。为了 方便演示,我们假设叛徒楚想通过不发送消息,来干扰共识协商(你能看到,图中的楚 是没有发送消息的)。
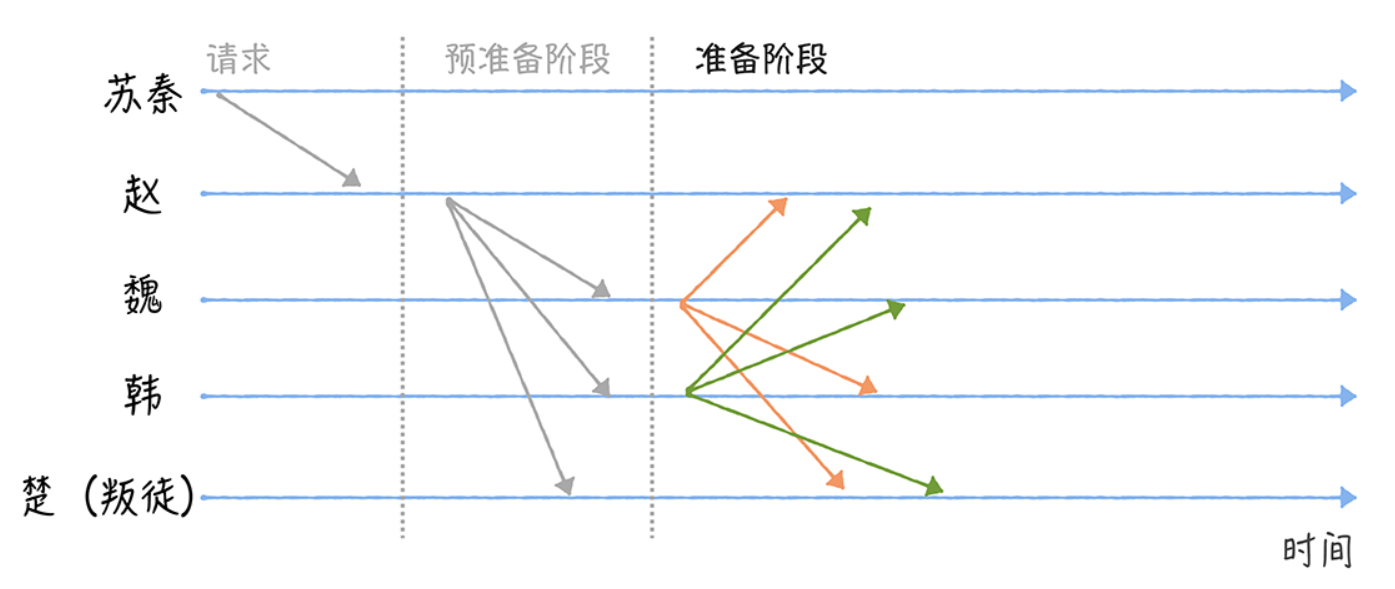
因为魏不能确认赵、韩、楚是否收到了 2f(这里的 2f 包括自己,其中 f 为叛徒数,在我的演示中是 1) 个一致的包含作战指令的准备消 息。所以需要进入下一个阶段Commit。
进入提交阶段后,各将军分别广播提交消息给其他将军,也就是告诉其他将军,我已经 准备好了,可以执行指令了。
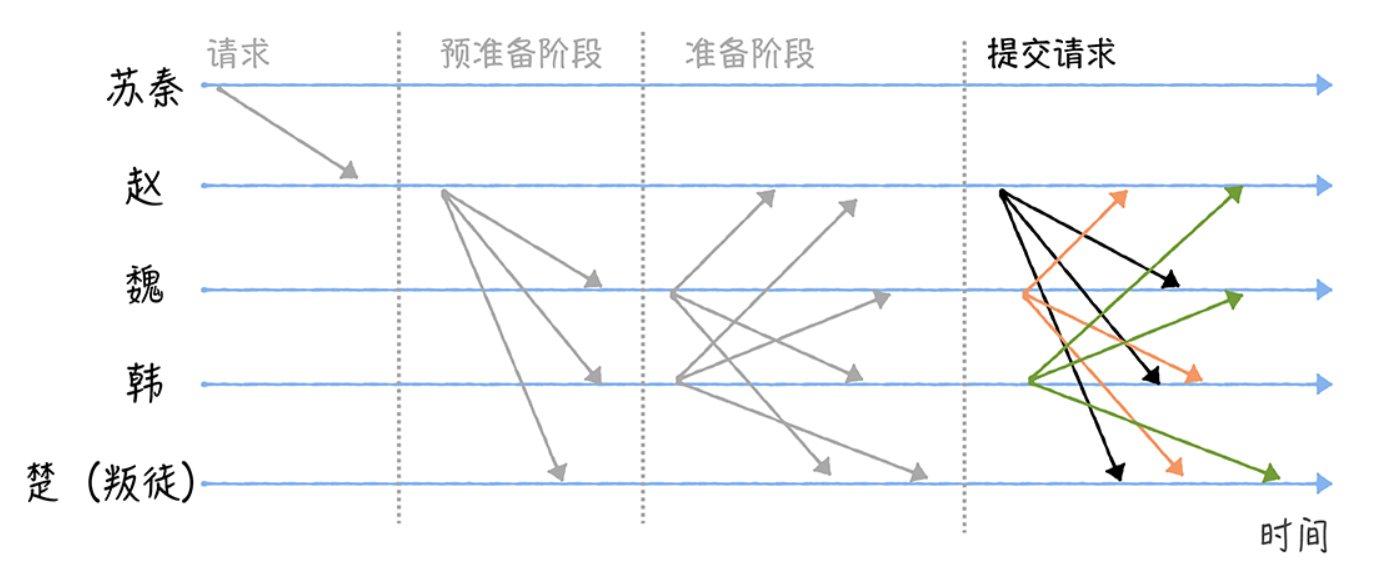
最后,当某个将军收到 2f + 1 个验证通过的提交消息后,大部分的将军们已经达成共识,这时可以执行作战指 令了,那么该将军将执行苏秦的作战指令,执行完毕后发送执行成功的消息给苏秦。
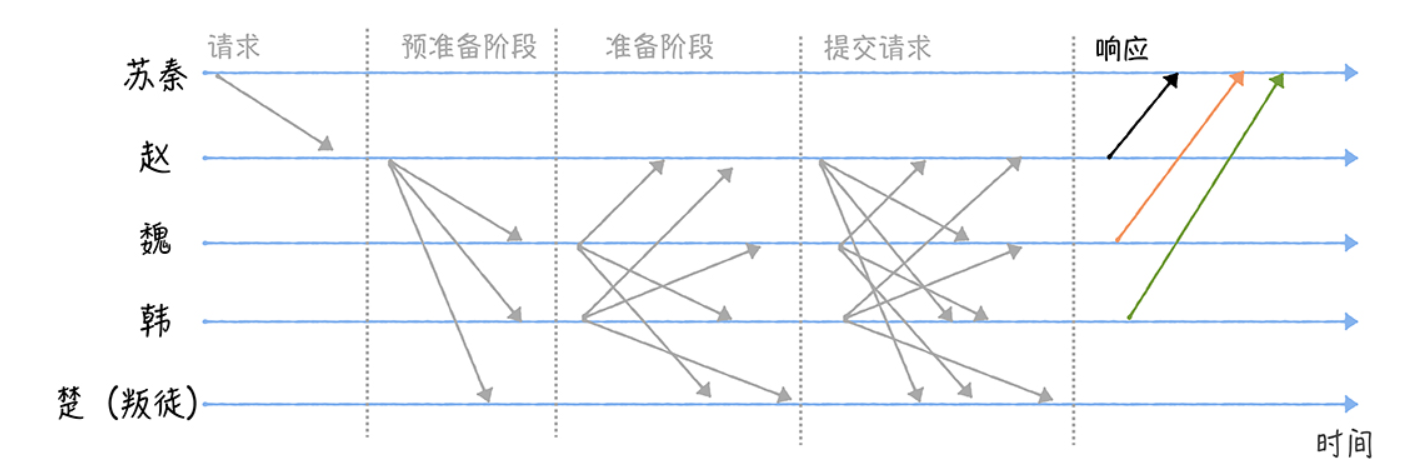
最后,当苏秦收到 f+1 个相同的响应(Reply)消息时,说明各位将军们已经就作战指令达 成了共识,并执行了作战指令。
在上面的这个例子中:
可以将赵、魏、韩、楚理解为分布式系统的四个节点,其中赵是主节点(Primary node),魏、韩、楚是从节点(Secondary node);
将苏秦理解为业务,也就是客户端;
将消息理解为网络消息;
将作战指令“进攻”,理解成客户端提议的值,也就是希望被各节点达成共识,并提交 给状态机的值。
最终的共识是否达成,客户端是会做判断的,如果客户端在指定时间内未 收到请求对应的 f + 1 相同响应,就认为集群出故障了,共识未达成,客户端会重新发送请 求。
PBFT 算法通过视图变更(View Change)的方式,来处理主节点作 恶,当发现主节点在作恶时,会以“轮流上岗”方式,推举新的主节点。感兴趣的可以自己去查阅。
相比 Raft 算法完全不适应有人作恶的场景,PBFT 算法能容忍 (n 1)/3 个恶意节点 (也可以是故障节点)。另外,相比 PoW 算法,PBFT 的优点是不消耗算 力。PBFT 算法是O(n ^ 2) 的消息复杂度的算法,所以以及随着消息数 的增加,网络时延对系统运行的影响也会越大,这些都限制了运行 PBFT 算法的分布式系统 的规模,也决定了 PBFT 算法适用于中小型分布式系统。
PoW算法
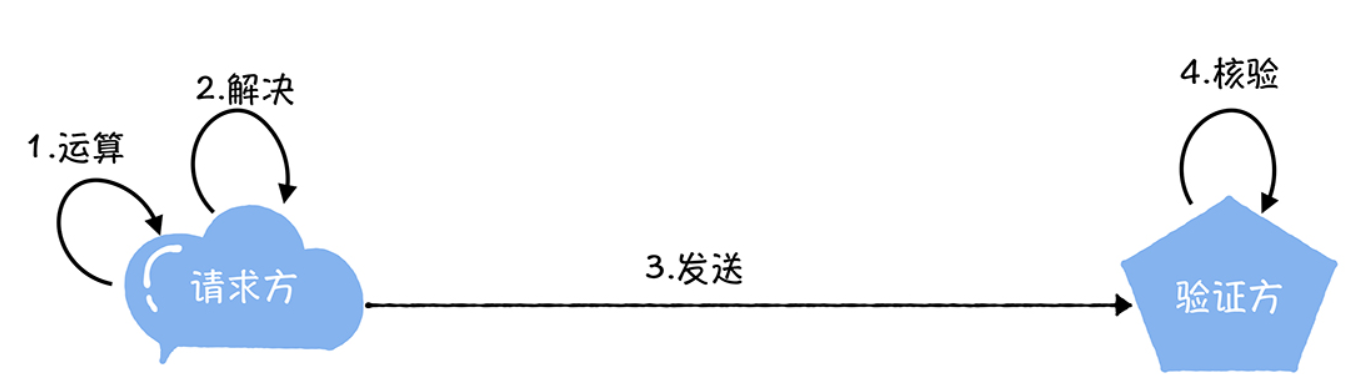
工作量证明 (Proof Of Work,简称 PoW),就是一份证明,用 来确认你做过一定量的工作。具体来说就是,客户端需要做一定难度的工作才能得出一个结果,验 证方却很容易通过结果来检查出客户端是不是做了相应的工作。
具体的工作量证明过程,就像下图中的样子:
所以工作量证明通常用于区块链中,区块链通过工作量证明(Proof of Work)增加了坏人作恶的成本,以此防止坏 人作恶。
工作量证明
哈希函数(Hash Function),也叫散列函数。就是说,你输入一个任意长度的字符串,哈 希函数会计算出一个长度相同的哈希值。
在了解了什么是哈希函数之后,那么如何通过哈希函数进行哈希运算,从而证明工作量呢?
例如,我们可以给出一个工作量的要求:基于一个基本的字符串,你可以在这个字 符串后面添加一个整数值,然后对变更后(添加整数值) 的字符串进行 SHA256 哈希运 算,如果运算后得到的哈希值(16 进制形式)是以"0000"开头的,就验证通过。
为了达到 这个工作量证明的目标,我们需要不停地递增整数值,一个一个试,对得到的新字符串进行 SHA256 哈希运算。
通过这个示例你可以看到,工作量证明是通过执行哈希运算,经过一段时间的计算后,得到 符合条件的哈希值。也就是说,可以通过这个哈希值,来证明我们的工作量。
区块链如何实现 PoW 算法的?
首先看看什么是区块链:
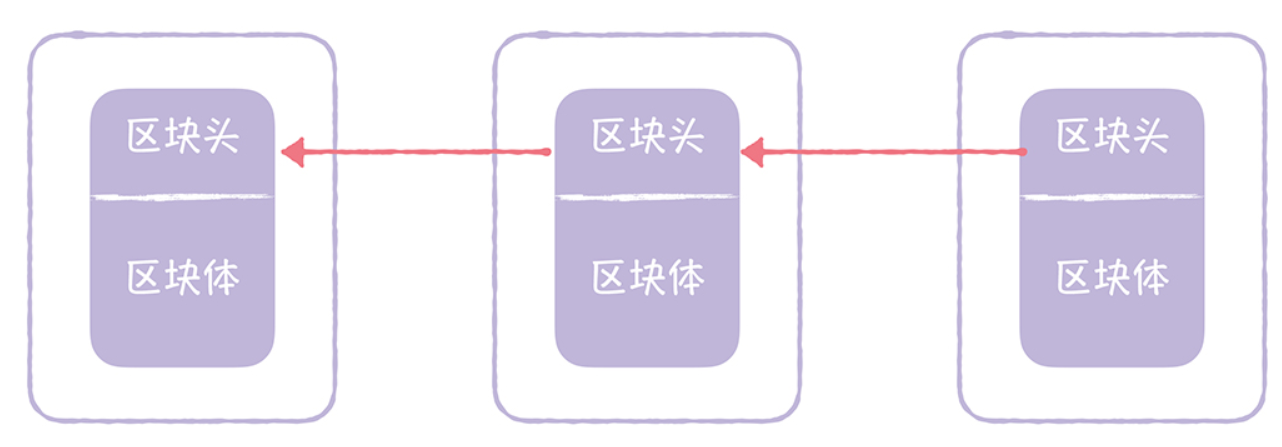
区块链的区块,是由区块头、区块体 2 部分组成的:
-
区块头(Block Head):区块头主要由上一个区块的哈希值、区块体的哈希值、4 字节 的随机数(nonce)等组成的。
-
区块体(Block Body):区块包含的交易数据,其中的第一笔交易是 Coinbase 交易, 这是一笔激励矿工的特殊交易。
在区块链中,拥有 80 字节固定长度的区块头,就是用于区块链工作量证明的哈希运算中输 入字符串,而且通过双重 SHA256 哈希运算(也就是对 SHA256 哈希运算的结果,再执行 一次哈希运算),计算出的哈希值,只有小于目标值(target),才是有效的,否则哈希值 是无效的,必须重算。
所以,在区块链中是通过对区块头执行 SHA256 哈希运算,得到小于目标 值的哈希值,来证明自己的工作量的。
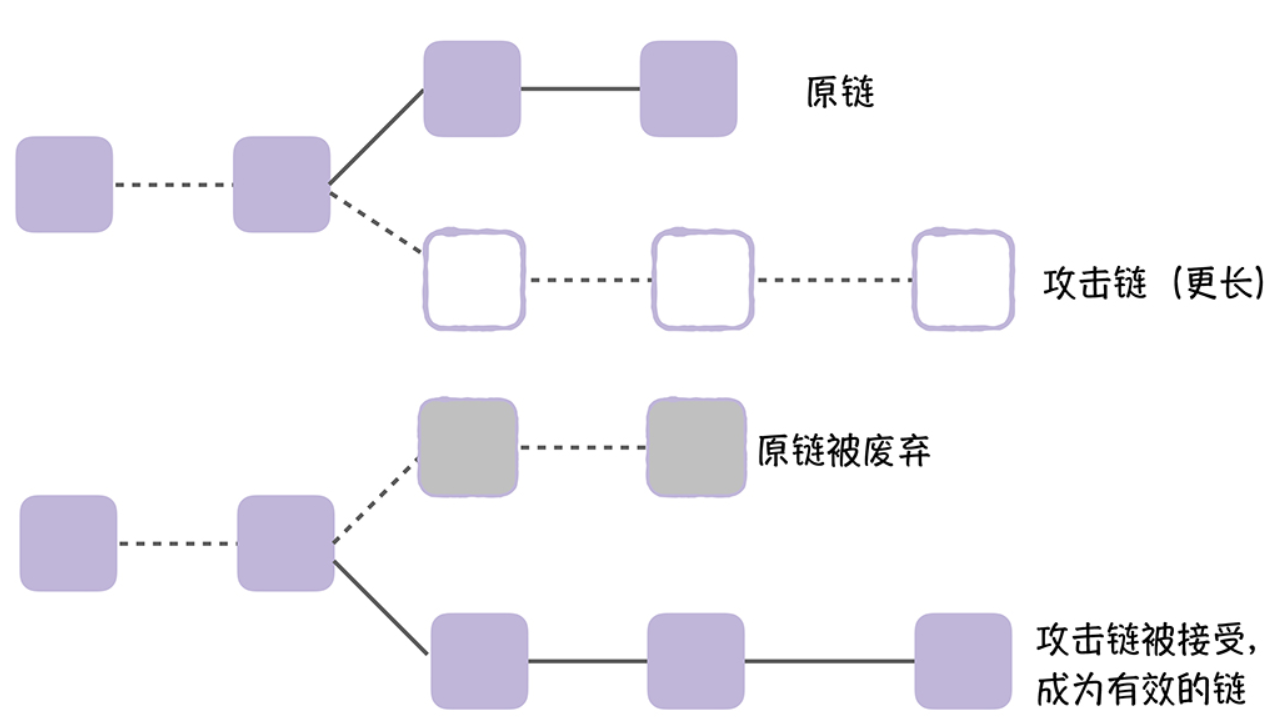
计算出符合条件的哈希值后,矿工就会把这个信息广播给集群中所有其他节点,其他节点验 证通过后,会将这个区块加入到自己的区块链中,最终形成一串区块链,就像下图的样子:
所以,就是攻击者掌握了较多的算力,能挖掘一条比原链更长的攻击链,并将攻击链 向全网广播,这时呢,按照约定,节点将接受更长的链,也就是攻击链,丢弃原链。就像下 图的样子:
ZAB协议
Zab协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper原子广播)。Zookeeper 是通过 Zab 协议来保证分布式事务的最终一致性。ZAB 协议的最核心设计目标就是如何实现操作的顺序性。
由于ZAB不基于状态机,而是基于主备模式的 原子广播协议(Atomic Broadcast),最终实现了操作的顺序性。
主要有以下几点原因导致了ZAB实现了操作的顺序性:
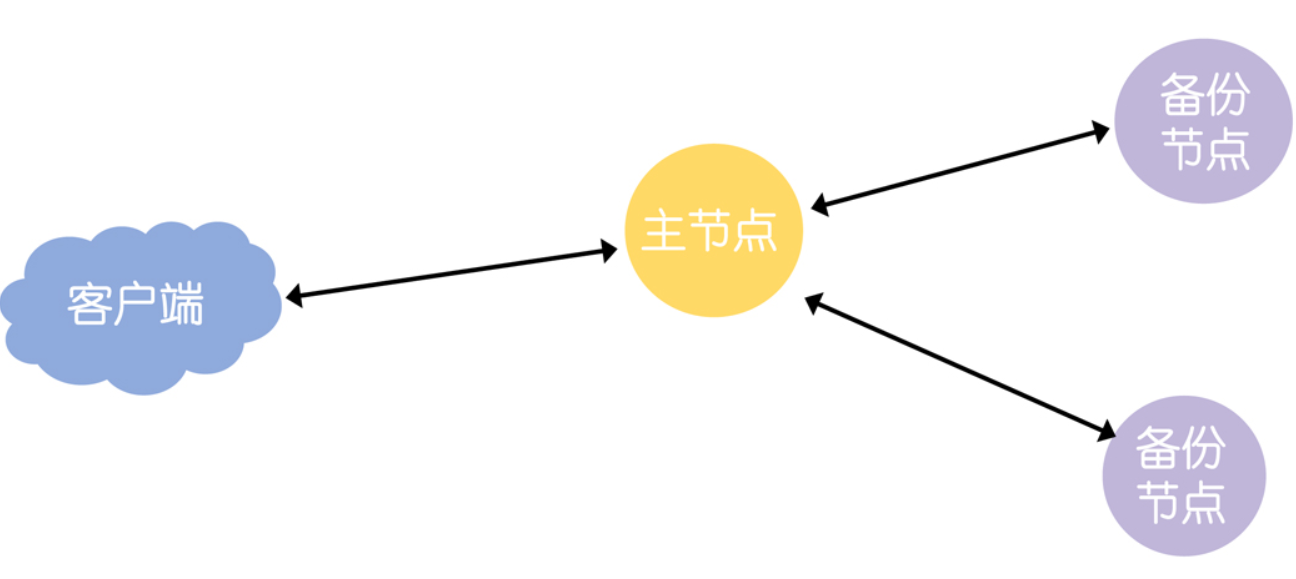
首先,ZAB 实现了主备模式,也就是所有的数据都以主节点为准:
其次,ZAB 实现了 FIFO 队列,保证消息处理的顺序性。
最后,ZAB 还实现了当主节点崩溃后,只有日志最完备的节点才能当选主节点,因为日志 最完备的节点包含了所有已经提交的日志,所以这样就能保证提交的日志不会再改变。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号