从JRaft来看Raft协议实现细节

分布式系统和一致性问题
一致性问题(consensus problem)是分布式系统需要解决的一个核心问题。分布式系统一般是由多个地位相等的节点组成,各个节点之间的交互就好比几个人聚在一起讨论问题。让我们设想一个更具体的场景,比如三个人讨论中午去哪里吃饭,第一个人说附近刚开了一个火锅店,听说味道非常不错;但第二个人说,不好,吃火锅花的时间太久了,还是随便喝点粥算了;而第三个人说,那个粥店我昨天刚去过,太难喝了,还不如去吃麦当劳。结果,三个人僵持不下,始终达不成一致。
有人说,这还不好解决,投票呗。于是三个人投了一轮票,结果每个人仍然坚持自己的提议,问题还是没有解决。有人又想了个主意,干脆我们选出一个leader,这个leader说什么,我们就听他的,这样大家就不用争了。于是,大家开始投票选leader。结果很悲剧,每个人都觉得自己应该做这个leader。三个人终于发现,「选leader」这件事仍然和原来的「去哪里吃饭」这个问题在本质上是一样的,同样难以解决。
这时恐怕有些读者们心里在想,这三个人是有毛病吧……就吃个饭这么点小事,用得着争成这样吗?实际上,在分布式系统中的每个节点之间,如果没有某种严格定义的规则和协议,它们之间的交互就真的有可能像上面说的情形一样。整个系统达不成一致,就根本没法工作。
所以,就有聪明人设计出了一致性协议(consensus protocol),像我们常见的比如Paxos、Raft、Zab之类。与前面几个人商量问题类似,如果翻译成Paxos的术语,相当于每个节点可以提出自己的提议(称为proposal,里面包含提议的具体值),协议的最终目标就是各个节点根据一定的规则达成相同的proposal。但以谁的提议为准呢?我们容易想到的一个规则可能是这样:哪个节点先提出提议,就以谁的为准,后提出的提议无效。
但是,在一个分布式系统中的情况可比几个人聚在一起讨论问题复杂多了,这里边还有网络延迟的问题,举个简单的例子,假设节点A和B分别几乎同时地向节点X和Y发出了自己的proposal,但由于消息在网络中的延迟情况不同,最后结果是:X先收到了A的proposal,后收到了B的proposal;但是Y正好相反,它先收到了B的proposal,后收到了A的proposal。这样在X和Y分别看来,谁先谁后就难以达成一致了。
如果考虑到节点宕机和消息丢失的可能性,情况还会更复杂。节点宕机可以看成是消息丢失的特例,相当于发给这个节点的消息全部丢失了。这在CAP的理论框架下,相当于发生了网络分割(network partitioning),也就是对应CAP中的P。比如,有若干个节点联系不上了,也就是说,对于其它节点来说,它们发送给这些节点的消息收不到任何回应。真正的原因,可能是网络中间不通了,也可能是那些目的节点宕机了,也可能是消息无限期地被延迟了。总之,就是系统中有些节点联系不上了,它们不能再参与决策,但也不代表它们过一段时间不能重新联系上。
为了表达上更直观,下面我们还是假设某些节点宕机了。那在这个时候,剩下的节点在缺少了某些节点参与决策的情况下,还能不能对于提议达成一致呢?即使是达成了一致,那么在那些宕机的节点重新恢复过来之后(注意这时候它们对于其它节点之间已经达成一致的提议可能一无所知),它们会不会对于已经达成的一致提议重新提出异议,从而造成混乱?所有这些问题,都是分布式一致性协议需要解决的。
实际上,理解问题本身比理解问题的答案要重要的多。
拜占庭将军问题
在分布式系统理论中,这个问题被抽象成了一个著名的问题——拜占庭将军问题(Byzantine Generals Problem)。
拜占庭帝国派出多支军队去围攻一支敌军,每支军队有一个将军,但由于彼此距离较远,他们之间只能通过信使传递消息。敌方很强大,固而必须有超过半数的拜占庭军队一同参与进攻才可能击败敌人。在此期间,将军们彼此之间需要通过信使传递消息并协商一致后,在同一时间点发动进攻。
相关论文:
《The Byzantine Generals Problem》
《Reaching Agreement in the Presence of Faults》
三将军的难题
假设只有三个拜占庭将军,分别为A、B、C,他们要讨论的只有一件事情:明天是进攻还是撤退。为此,将军们需要依据“少数服从多数”原则投票表决,只要有两个人意见达成一致就可以了。
举例来说,A和B投进攻,C投撤退:
- 那么A的信使传递给B和C的消息都是进攻;
- B的信使传递给A和C的消息都是进攻;
- 而C的信使传给A和B的消息都是撤退。
如果稍微做一个改动:三个将军中出了一个叛徒呢?叛徒的目的是破坏忠诚将军间一致性的达成,让拜占庭的军队遭受损失。
作为叛徒的C,你必然不会按照常规出牌,于是你让一个信使告诉A的内容是你“要进攻”,让另一个信使告诉B的则是你“要撤退”。
至此,A将军看到的投票结果是:进攻方 :撤退方 = 2 : 1 ,而B将军看到的是 1 : 2 。第二天,忠诚的A冲上了战场,却发现只有自己一支军队发起了进攻,而同样忠诚的B,却早已撤退。最终,A的军队败给了敌人。
Raft算法要成立都是建立在一个前提下的:不存在恶意节点,才能达成一致。否则,这些著名的算法会随之失效。
从一个Counter例子说起
需求
提供一个 Counter,Client 每次计数时可以指定步幅,也可以随时发起查询。
这个看似简单的需求,主要有三个功能点:
- 实现:Counter server,具备计数功能,具体运算公式为:Cn = Cn-1 + delta;
- 提供写服务,写入 delta 触发计数器运算;
- 提供读服务,读取当前 Cn 值;
除此之外,我们还有一个可用性的可选需求,需要有备份机器,读写服务不能不可用。
系统架构1.0
根据刚才分析出来的功能需求,我们设计出 1.0 的架构,这个架构很简单,一个节点 Counter Server 提供计数功能,接收客户端发起的计数请求和查询请求。
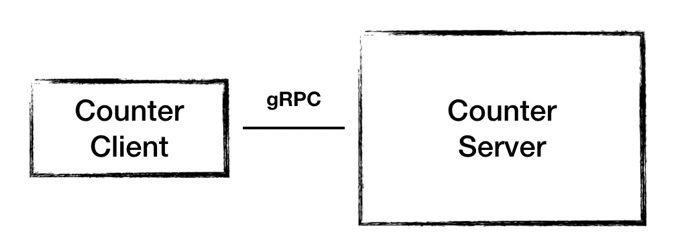
但是这样的架构设计存在这样两个问题:一是 Server 是一个单点,一旦 Server 节点故障服务就不可用了;二是运算结果都存储在内存当中,节点故障会导致数据丢失。
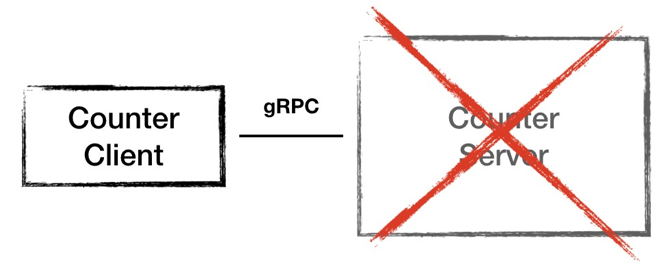
系统架构1.5
针对问题一,当节点故障之时,我们要新起一台备用机器。针对问题二,我们优化一下,加一个本地文件存储。这样每次计数器完成运算之后都将数据落盘。
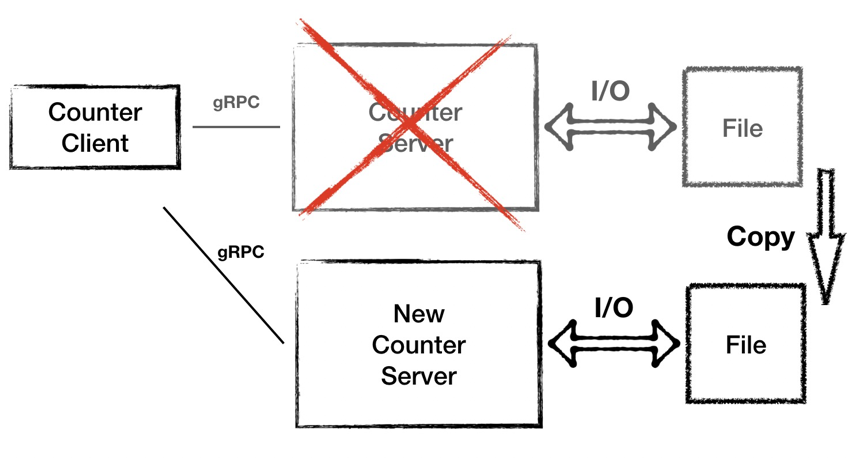
但是同时也引来另外的问题:磁盘 IO 很频繁,同时这种冷备的模式也依然会导致一段时间的服务不可用。
系统架构2.0
由于上面的问题仅仅通过加机器已经无法解决,所以我们提出架构 2.0,采用集群的模式提供服务。我们用三个节点组成集群,由一个节点对外提供服务,当 Server 接收到 Client 发来的写请求之后,Server 运算出结果,然后将结果复制给另外两台机器,当收到其他所有节点的成功响应之后,Server 向 Client 返回运算结果。
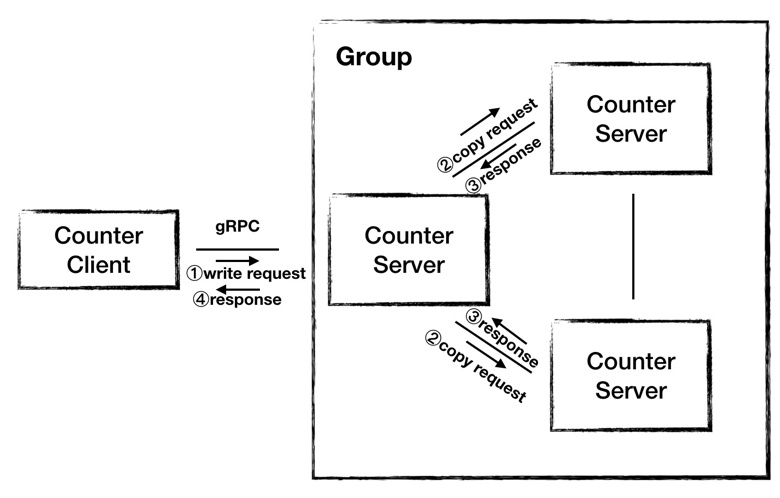
但是这样的架构也存在这问题:
- 我们选择哪一台 Server 扮演 Leader 的角色对外提供服务;
- 当 Leader 不可用之后,选择哪一台接替它;
- Leader 处理写请求的时候需要等到所有节点都响应之后才能响应 Client;
- 也是比较重要的,我们无法保证 Leader 向 Follower 复制数据是有序的,所以任一时刻三个节点的数据都可能是不一样的;
所以为了保证复制数据的顺序和内容,这就有了共识算法的用武之地,我们使用SOFAJRaft来构建我们的3.0 架构。
系统架构3.0
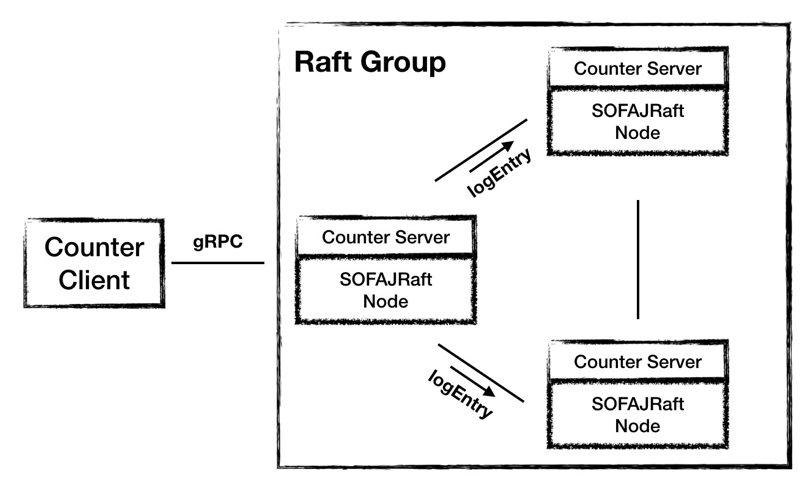
3.0 架构中,Counter Server 使用 SOFAJRaft 来组成一个集群,Leader 的选举和数据的复制都交给 SOFAJRaft 来完成。

在时序图中我们可以看到,Counter 的业务逻辑重新变得像架构 1.0 中一样简洁,维护数据一致的工作都交给 SOFAJRaft 来完成,所以图中灰色的部分对业务就不感知了。
在使用 SOFAJRaft 的 3.0 架构中,SOFAJRaft 帮我们完成了 Leader 选举、节点间数据同步的工作,除此之外,SOFAJRaft 只需要半数以上节点响应即可,不再需要集群所有节点的应答,这样可以进一步提高写请求的处理效率。
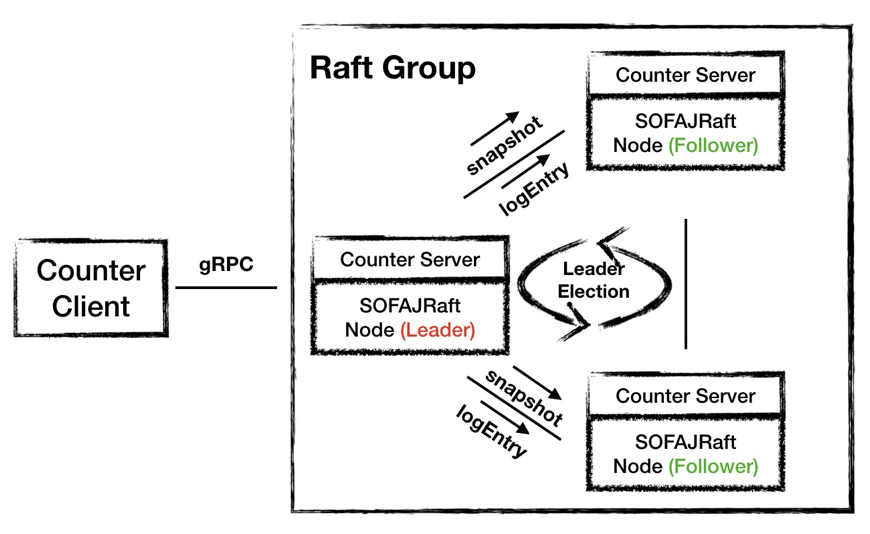
Raft 共识算法
小论文:《In Search of an Understandable consensus Algorithm》
大论文:《Consensus:Bridging theory and practice》
Raft 是一种共识算法,其特点是让多个参与者针对某一件事达成完全一致:一件事,一个结论。同时对已达成一致的结论,是不可推翻的。可以举一个银行账户的例子来解释共识算法:假如由一批服务器组成一个集群来维护银行账户系统,如果有一个 Client 向集群发出“存 100 元”的指令,那么当集群返回成功应答之后,Client 再向集群发起查询时,一定能够查到被存储成功的这 100 元钱,就算有机器出现不可用情况,这 100 元的账也不可篡改。这就是共识算法要达到的效果。
Raft 中的基本概念
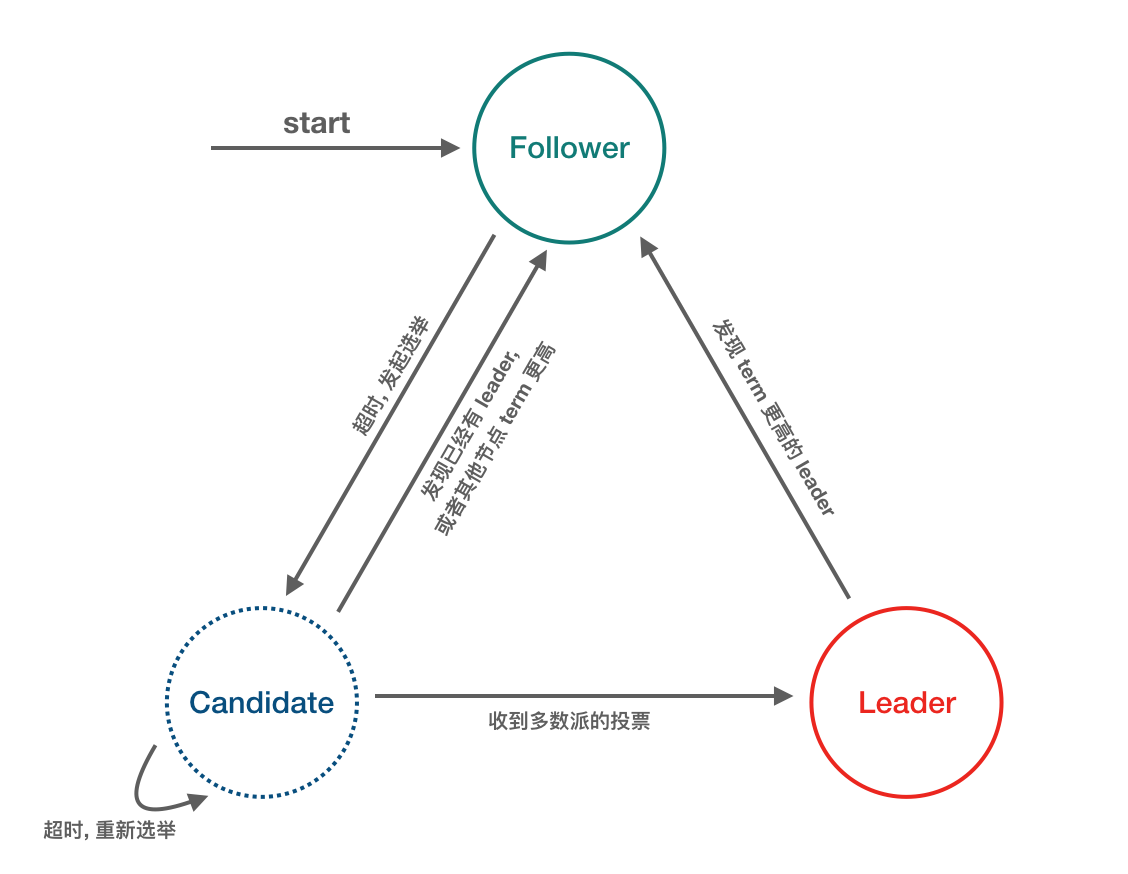
Raft-node 的 3 种角色/状态
在一个由 Raft 协议组织的集群中有三类角色:
- Leader(领袖)
- Follower(群众)
- Candidate(候选人)
就像一个民主社会,领袖由民众投票选出。刚开始没有领袖,所有集群中的参与者都是群众,那么首先开启一轮大选,在大选期间所有群众都能参与竞选,这时所有群众的角色就变成了候选人,民主投票选出领袖后就开始了这届领袖的任期,然后选举结束,所有除领袖的候选人又变回群众角色服从领袖领导。这里提到一个概念「任期」,用术语 Term 表达。
Message 的 3 种类型
- RequestVote RPC:由 Candidate 发出,用于发送投票请求;
- AppendEntries (Heartbeat) RPC:由 Leader 发出,用于 Leader 向 Followers 复制日志条目,也会用作 Heartbeat (日志条目为空即为 Heartbeat);
- InstallSnapshot RPC:由 Leader 发出,用于快照传输,虽然多数情况都是每个服务器独立创建快照,但是Leader 有时候必须发送快照给一些落后太多的 Follower,这通常发生在 Leader 已经丢弃了下一条要发给该Follower 的日志条目(Log Compaction 时清除掉了) 的情况下。
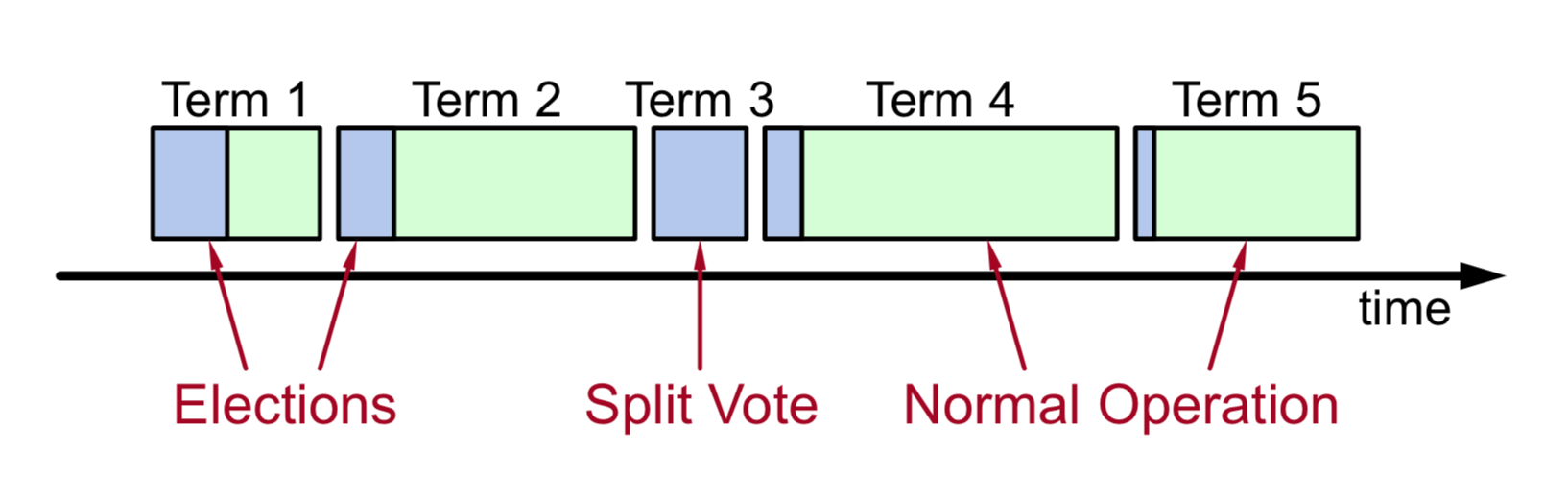
任期逻辑时钟
- 时间被划分为一个个任期 (term),term id 按时间轴单调递增;
- 每一个任期的开始都是 Leader 选举,选举成功之后,Leader 在任期内管理整个集群,也就是 “选举 + 常规操作”;
- 每个任期最多一个 Leader,可能没有 Leader (spilt-vote 导致)。
Leader election
选举步骤
这里摘取了论文中的步骤来进行说明:
- When servers start up, they begin as followers
- If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader
- To begin an election, a follower increments its current term and transitions to candidate state
- then votes for itself and issues RequestVote RPCs in parallel to each of
the other servers in the cluster. - A candidate wins an election if it receives votes from a majority of the servers in the full cluster for the same term
- Once a candidate wins an election, it becomes leader
- a candidate may receive an AppendEntries RPC
- If the leader’s term is at least as large as the candidate’s current term, then the candidate recognizes the leader as legitimate and returns to follower state
- If the term in the RPC is smaller than the candidate’s current term, then the candidate rejects the RPC and continues in candidate state
vote split
if many followers become candidates at the same time, votes could be split so that no candidate obtains a majority. When this happens, each candidate will time out and start a new election by incrementing its term and initiating another round of RequestVote RPCs.
Raft uses randomized election timeouts to ensure that split votes are rare and that they are resolved quickly.
下面来使用一个个的例子来具体说明选举的过程
选举要解决什么
一个分布式集群可以看成是由多条战船组成的一支舰队,各船之间通过旗语来保持信息交流。这样的一支舰队中,各船既不会互相完全隔离,但也没法像陆地上那样保持非常密切的联系,天气、海况、船距、船只战损情况导致船舰之间的联系存在但不可靠。
舰队作为一个统一的作战集群,需要有统一的共识、步调一致的命令,这些都要依赖于旗舰指挥。各舰船要服从于旗舰发出的指令,当旗舰不能继续工作后,需要有别的战舰接替旗舰的角色。
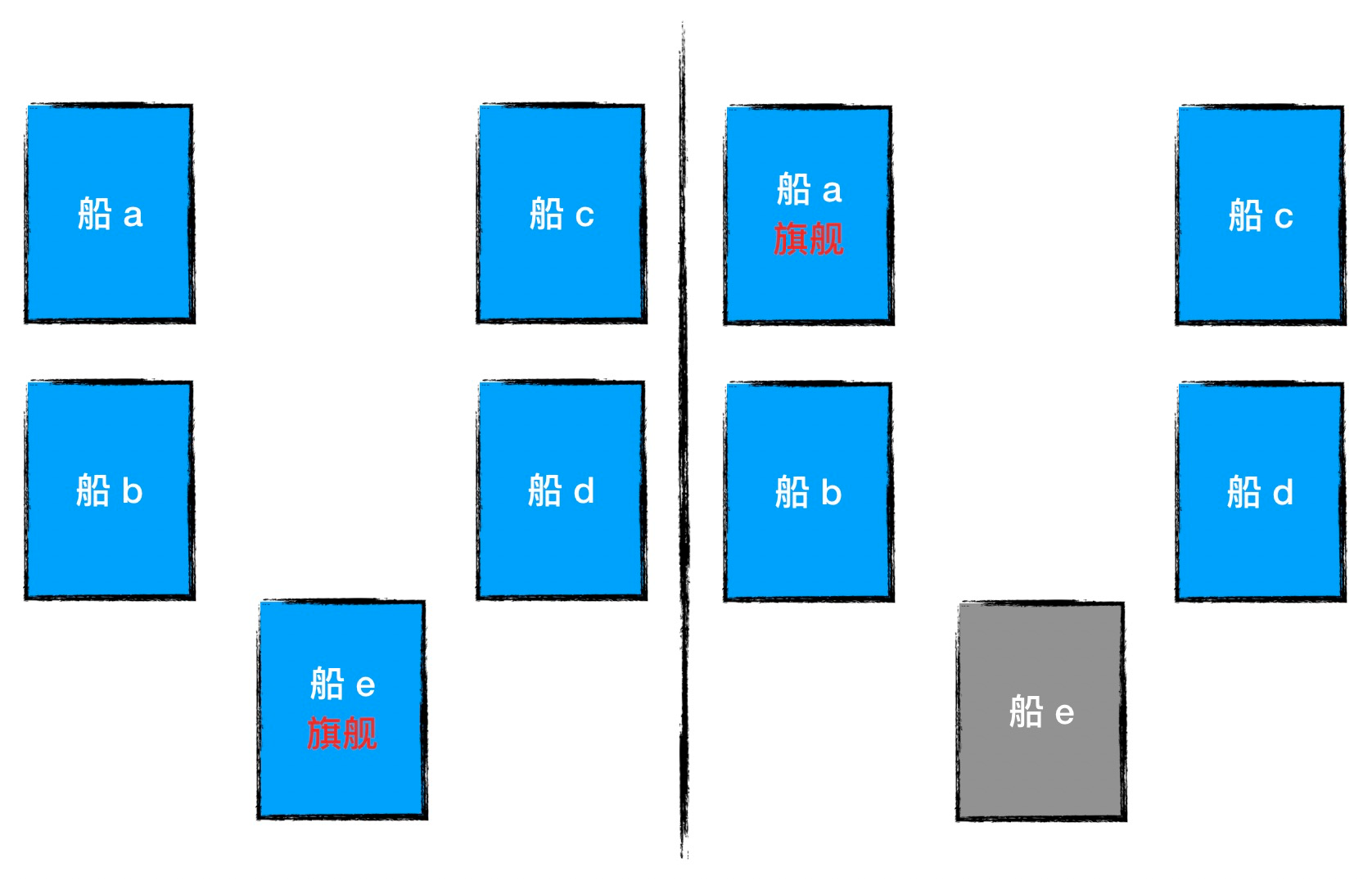
如何在舰队中,选出一艘得到大家认可的旗舰,这就是 SOFAJRaft 中选举要解决的问题。
何时可以发起选举
在 SOFAJRaft 中,触发标准就是通信超时,当旗舰在规定的一段时间内没有与 Follower 舰船进行通信时,Follower 就可以认为旗舰已经不能正常担任旗舰的职责,则 Follower 可以去尝试接替旗舰的角色。这段通信超时被称为 Election Timeout (简称 ET), Follower 接替旗舰的尝试也就是发起选举请求。
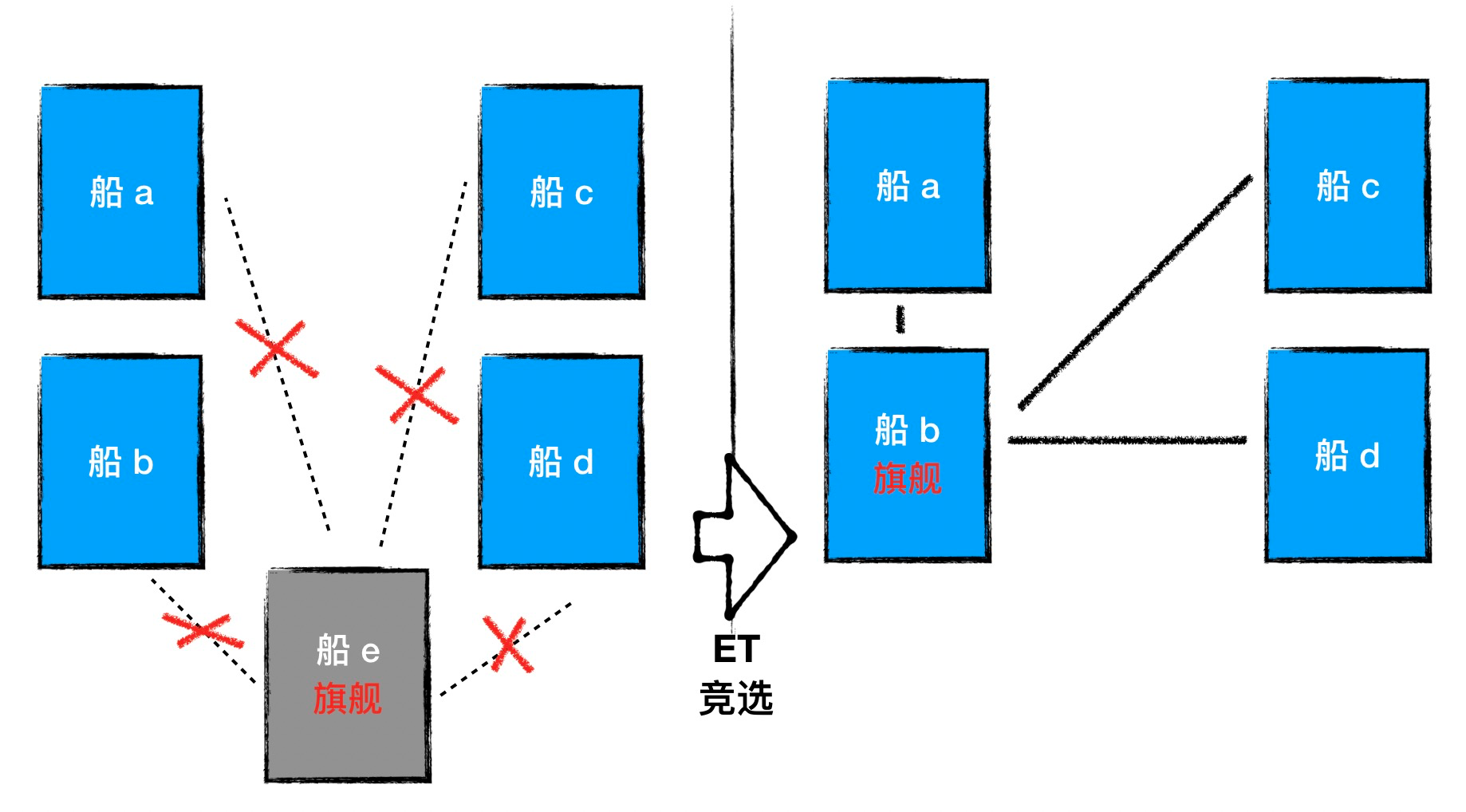
何时真正发起选举
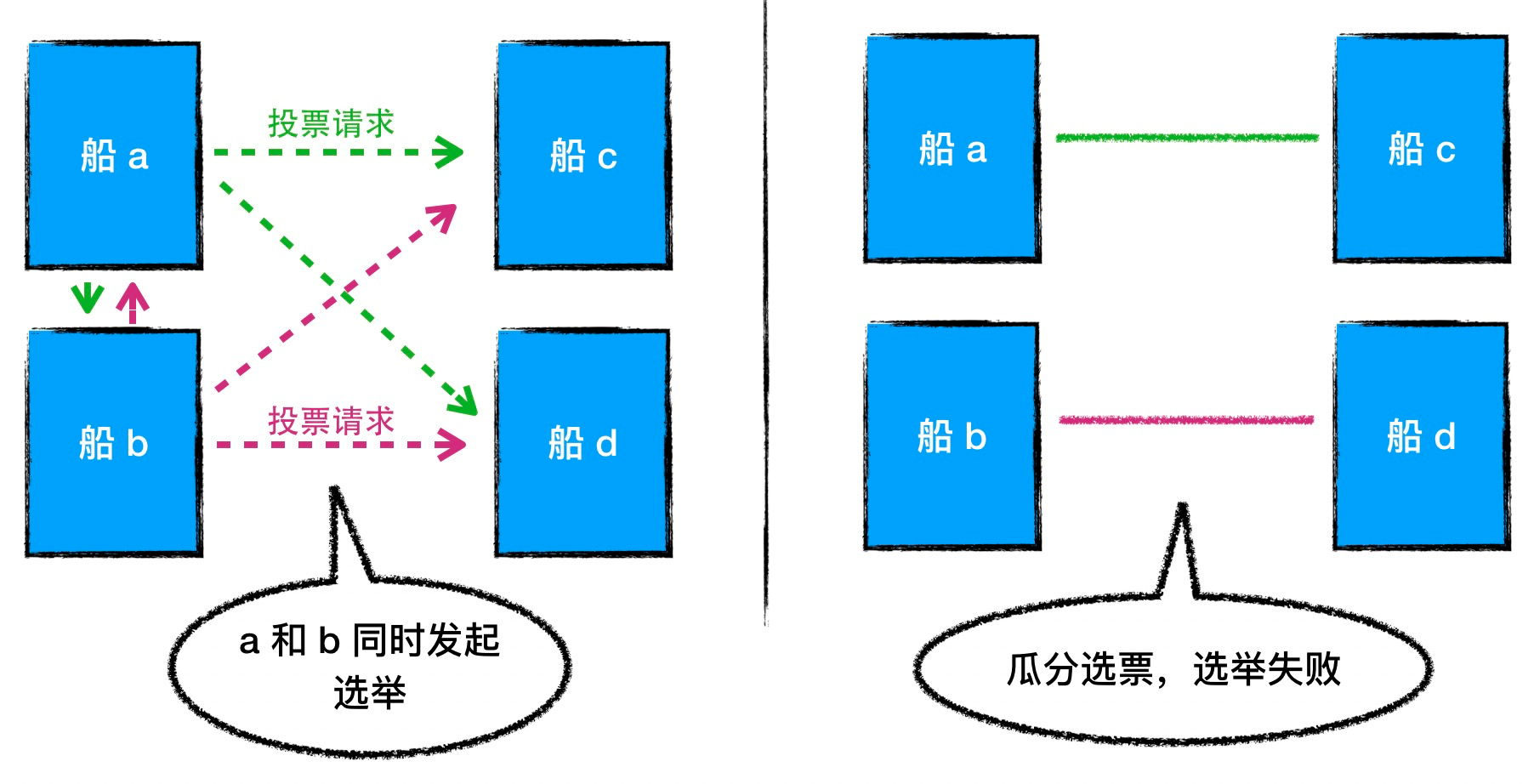
在选举中,只有当舰队中超过一半的船都同意,发起选举的船才能够成为旗舰,否则就只能开始一轮新的选举。所以如果 Follower 采取尽快发起选举的策略,试图尽早为舰队选出可用的旗舰,就可能引发一个潜在的风险:可能多艘船几乎同时发起选举,结果其中任何一支船都没能获得超过半数选票,导致这一轮选举无果,这就是上面所说的vote split。
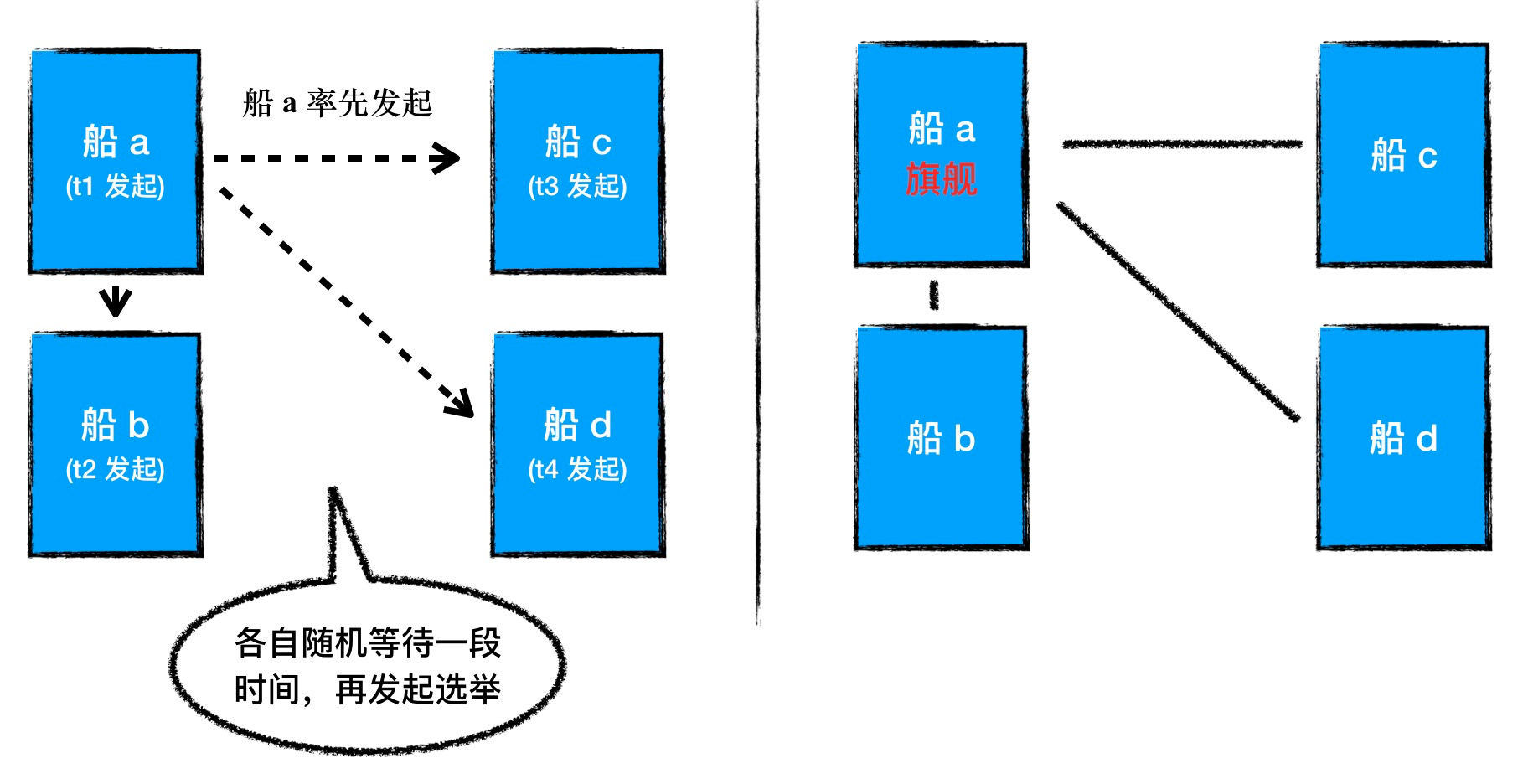
为避免这种情况,我们采用随机的选举触发时间,当 Follower 发现旗舰失联之后,会选择等待一段随机的时间 Random(0, ET) ,如果等待期间没有选出旗舰,则 Follower 再发起选举。
哪些候选者值得选票
SOFAJRaft 的选举中包含了对两个属性的判断:LogIndex 和 Term,这是整个选举算法的核心部分。
- Term:我们会对舰队中旗舰的历史进行编号,比如舰队的第1任旗舰、第2任旗舰,这个数字我们就用 Term 来表示。由于舰队中同时最多只能有一艘舰船担任旗舰,所以每一个 Term 只归属于一艘舰船,显然 Term 是单调递增的。
- LogIndex:每任旗舰在职期间都会发布一些指令(称其为“旗舰令”,类比“总统令”),这些旗舰令当然也是要编号归档的,这个编号我们用 Term 和 LogIndex 两个维度来标识,表示“第 Term 任旗舰发布的第 LogIndex 号旗舰令”。不同于现实中的总统令,我们的旗舰令中的 LogIndex 是一直递增的,不会因为旗舰的更迭而从头开始计算。
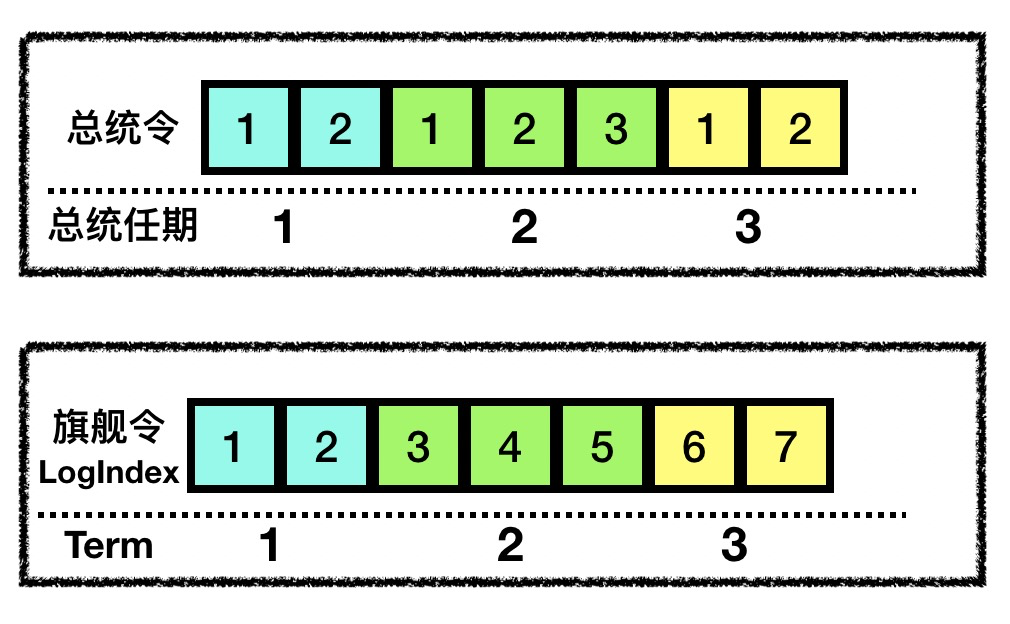
具体来说,参与投票的船 V 不会对下面两种候选者 C 投票:一种是 lastTermC < lastTermV;另一种是 (lastTermV == lastTermC) && (lastLogIndexV > lastLogIndexC)。
第一种情况说明候选者 C 最后一次通信过的旗舰已经不是最新的旗舰了;第二种情况说明,虽然 C 和 V 都与同一个旗舰有过通信,但是候选者 C 从旗舰处获得的旗舰令不如 V 完整 (lastLogIndexV > lastLogIndexC),所以 V 不会投票给它。

什么情况下会发生step down
step down可以发生在Candidate回退到Follower,也可以发生在Leader中。如果是Candidate发生step down,那么放弃竞选本届 Leader。如果是Leader,那么会回退到Follower状态,重新开启选举。
如下两种情况会让 Candidate 退回 (step down) 到 Follower:
- 如果在 Candidate 等待 Servers 的投票结果期间收到了其他拥有更高 Term 的 Server 发来的投票请求;
- 如果在 Candidate 等待 Servers 的投票结果期间收到了其他拥有更高 Term 的 Server 发来的心跳;
而对于Leader来说,当发现有 Term 更高的 Leader 时也会退回到 Follower 状态。
如何避免不够格的候选者“捣乱”
SOFAJRaft 将 LogIndex 和 Term 作为选举的评选标准,所以当一艘船发起选举之前,会自增 Term 然后填到选举请求里发给其他船只 (可能是一段很复杂的旗语),表示自己竞选“第 Term + 1 任”旗舰。
这里要先说明一个机制,它被用来保证各船只的 Term 同步递增:当参与投票的 Follower 船收到这个投票请求后,如果发现自己的 Term 比投票请求里的小,就会自觉更新自己的 Term 向候选者看齐,这样能够很方便的将 Term 递增的信息同步到整个舰队中。
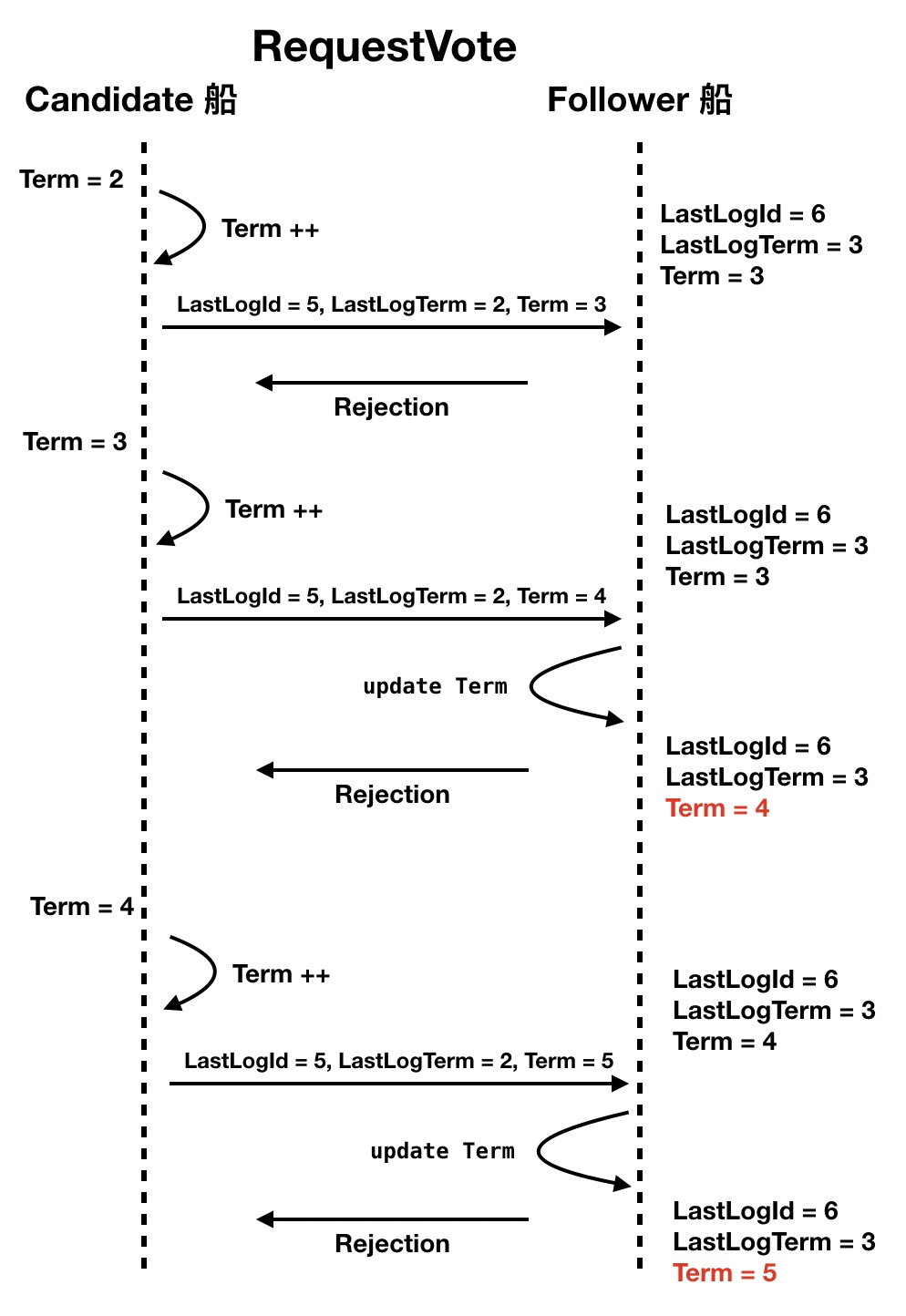
但是这种机制也带来一个麻烦,如果一艘船因为自己的原因没有看到旗舰发出的旗语,他就会自以为是的试图竞选成为新的旗舰,虽然不断发起选举且一直未能当选(因为旗舰和其他船都正常通信),但是它却通过自己的投票请求实际抬升了全局的 Term,这在 SOFAJRaft 算法中会迫使旗舰 stepdown (从旗舰的位置上退下来)。

所以我们需要一种机制阻止这种“捣乱”,这就是预投票 (pre-vote) 环节。候选者在发起投票之前,先发起预投票,如果没有得到半数以上节点的反馈,则候选者就会识趣的放弃参选,也就不会抬升全局的 Term。
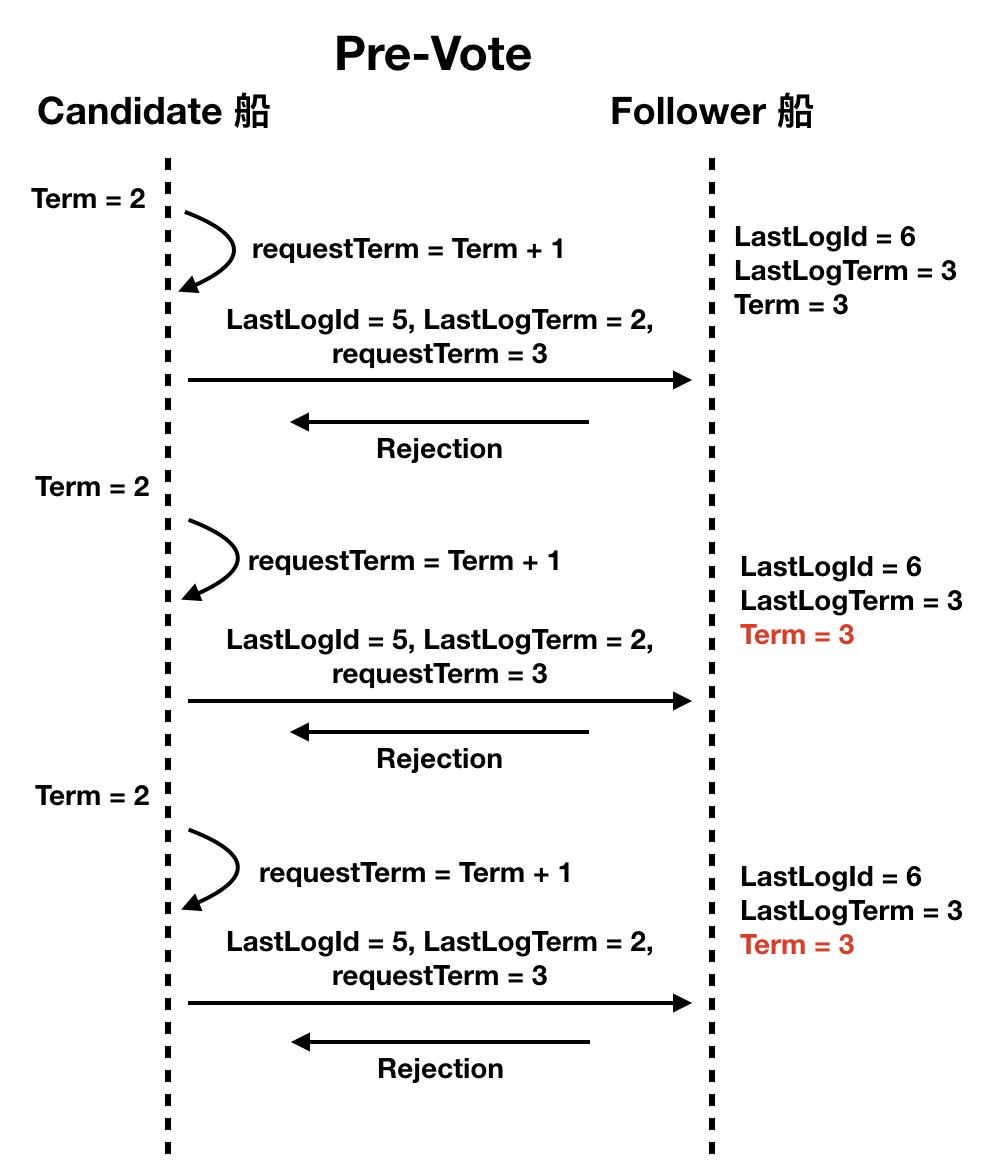
在上面的比喻中,我们可以看到整个选举操作的主线任务就是:
- Candidate 被 ET 触发
- Candidate 开始尝试发起 pre-vote 预投票
- Follower 判断是否认可该 pre-vote request
- Candidate 根据 pre-vote response 来决定是否发RequestVoteRequest
- Follower 判断是否认可该 RequestVoteRequest
- Candidate 根据 response 来判断自己是否当选
Log replication
-
leader对外提供服务
一旦leader被选举出来后,就需要对外提供服务了。下面是论文的原文:
Once a leader has been elected, it begins servicing client requests. Each client request contains a command to be executed by the replicated state machines.
翻译:一旦leader被选举出来后,它需要对外提供服务。每个发送给leader的请求都会被复制的状态机执行。
-
leader执行日志复制
The leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry.
翻译:leader会将每次请求的指令作为一个对象写入日志中,然后通过AppendEntries操作通知其他Follower复制该日志。
-
日志复制成功
当leader复制给Follower的时候,有两种情况,一种是日志被安全的复制到Follower节点中:
When the entry has been safely replicated (as described below), the leader applies the entry to its state machine and returns the result of that execution to the client.
翻译:当日志被安全的复制到Follower后,leader会将该请求交给状态机执行,然后返回执行结果给客户端。
-
日志复制失败
另一种情况是Follower出现故障的情况:
If followers crash or run slowly, or if network packets are lost, the leader retries AppendEntries RPCs indefinitely (even after it has responded to the client) until all followers eventually store all log entries.
翻译:如果Follower宕机或者运行很慢,亦或是网络包丢失,那么leader会重复的进行AppendEntries操作,直到Follower正常处理该日志复制。
LogEntry
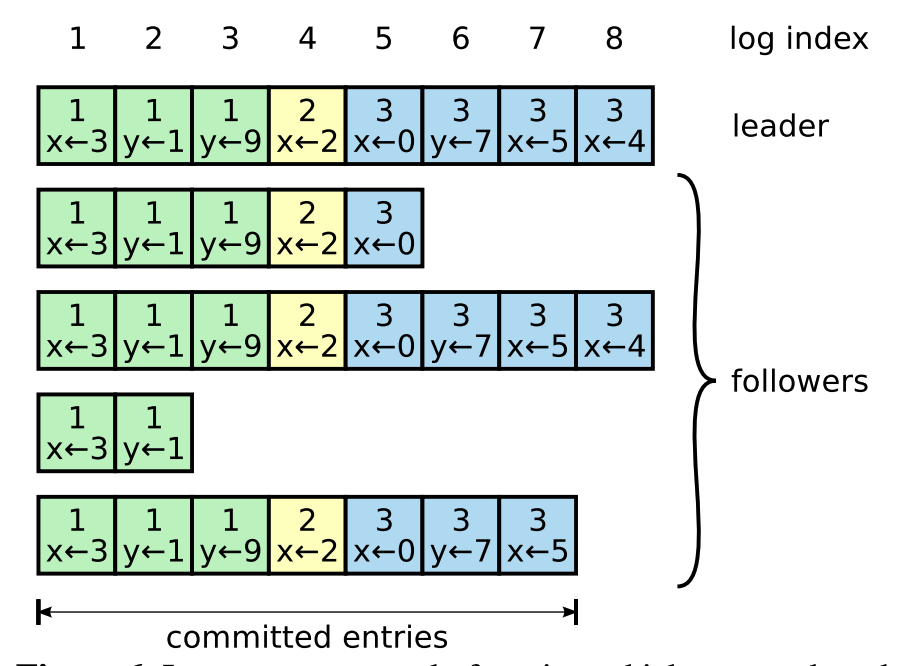
如上图所示,每个方格代表一个LogEntry,可以看到Log是由一个个LogEntry组成的,理想情况下所有实例上该数组都是一致的。Log元素根据状态的不同,又分为未提交和已提交。只有已提交的LogEntry才会返回客户端写入成功。
最上面一行是log index,也就是下标值,单调递增,且连续的。方格内的数字代表的是term任期。
committed entry:A log entry is committed once the leader that created the entry has replicated it on a majority of the servers
也就是说如果一个日志被复制到大多数的节点中,那么这个日志才能算是一个已提交的日志。
Once a follower learns that a log entry is committed, it applies the entry to its local state machine (in log order).
一旦Follower得知这个LogEntry已提交,那么就会将这个LogEntry放到状态机中执行。
Follower日志不一致
一般的情况下,leader和Follower的日志是保持一致的,然后现实中leader并不能保证不会crash,所以日志可能会出现如下所示不一致的情况:
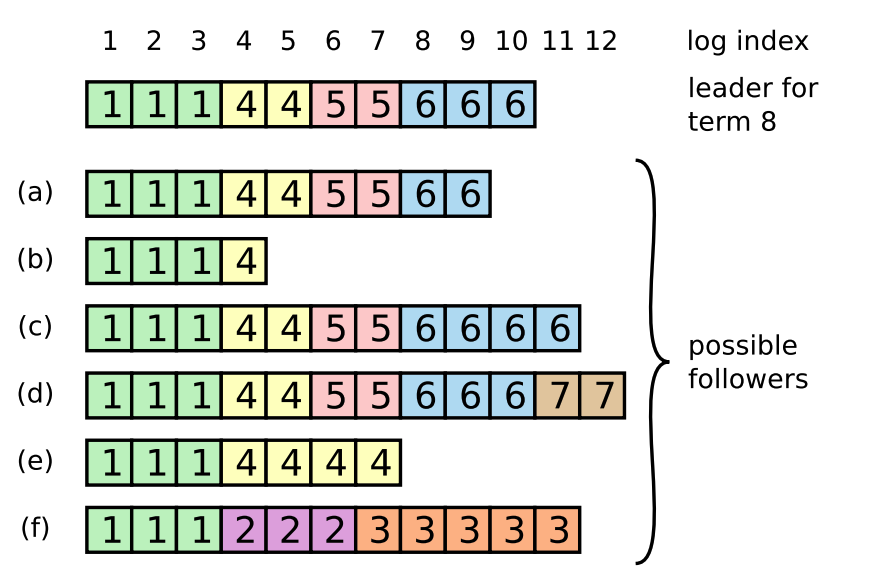
如上图,Follower可能比leader日志少,可能会有多余的日志,可能会既丢失日志也出现多余的日志。
所以Raft需要载保证日志的一致性下做这几件事:
-
consistency check
由于leader在发送LogEntry的时候会带上index和term,所以Follower在收到LogEntry之后要去检测这条LogEntry是否是和之前的日志是连续的,所以 Follower 会拒绝无法和本地已有 Log 保持连续的复制请求,那么这种情况下就需要走 Log 恢复的流程。
-
find the latest log entry
如果不一致的话,那么需要找到leader和Follower双方都认可的那条日志,这条日志必须在Follower中是连续的,并且是在leader中存在的,具体操作如下:
-
由于leader会为每个Follower维护一个nextIndex表,所以leader知道Follower最新的日志需要发送哪条。
The leader maintains a nextIndex for each follower,
which is the index of the next log entry the leader will send to that follower. -
当leader首次当选的时候,会将nextIndex设置为自己最新的log的下一个Index
When a leader first comes to power, it initializes all nextIndex values to the index just after the last one in its log.
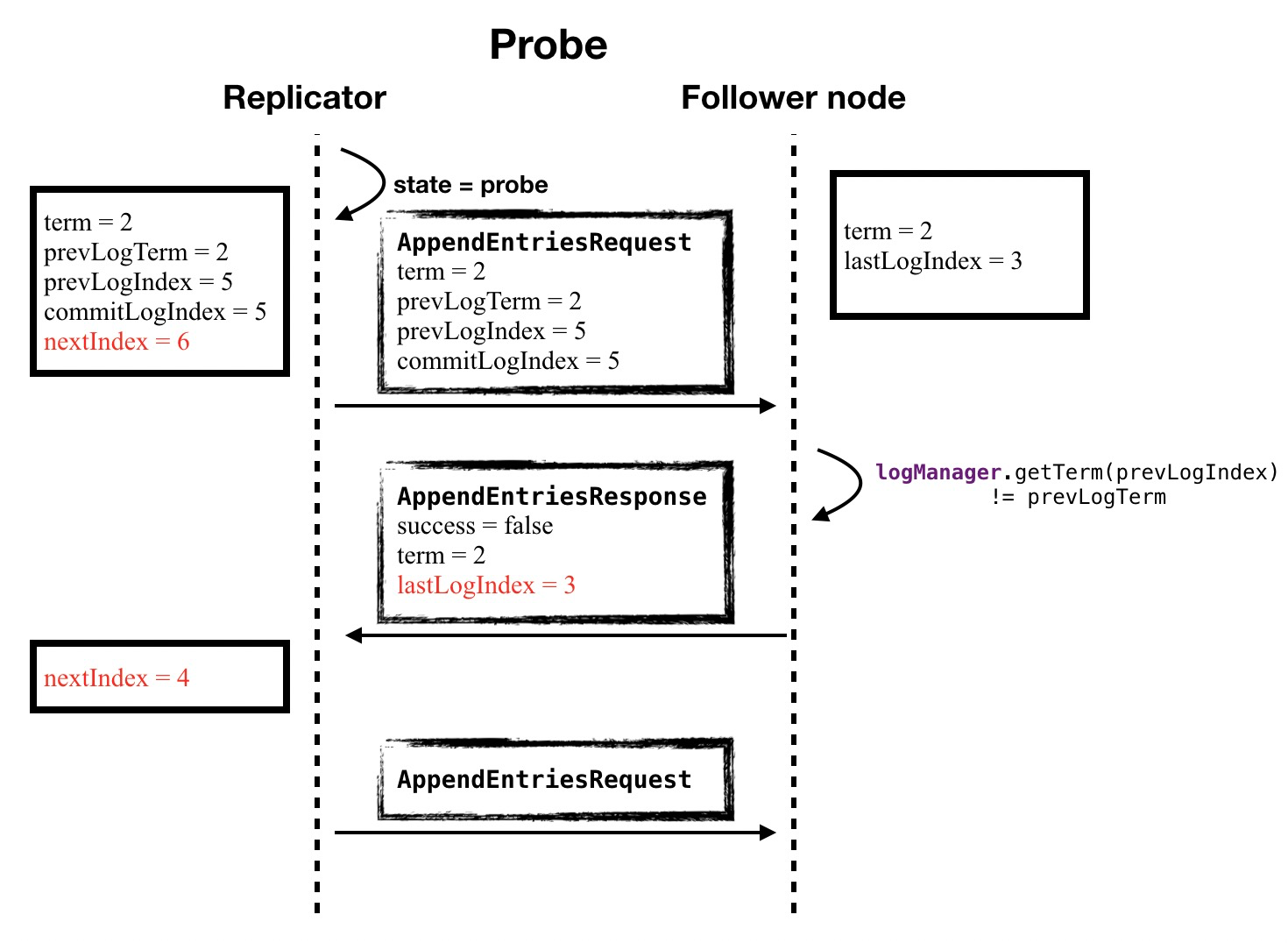
-
Leader 节点在通过 Replicator 和 Follower 建立连接之后,要发送一个 Probe 类型的探针请求,目的是知道 Follower 已经拥有的的日志位置
-
如果发现日志不一致(term和index要一致),那么leader将会decrement nextIndex,然后重新发送AppendEntries请求,直至达到一个双方都认可的日志位置
If a follower’s log is inconsistent with the leader’s, the AppendEntries consistency check will fail in the next AppendEntries RPC. After a rejection, the leader decrements nextIndex and retries the AppendEntries RPC. Eventually nextIndex will reach a point where the leader and follower logs match.
-
当leader发送的AppendEntries请求是成功的时候,那么Follower会清除冲突的日志,并接受leader的日志。
Eventually nextIndex will reach a point where the leader and follower logs match. When this happens, AppendEntries will succeed, which removes any conflicting entries in the follower’s log and appends entries from the leader’s log
-
下面讲一下JRaft中日志复制的细节
被复制的日志是有序且连续的
SOFAJRaft 在日志复制时,其日志传输的顺序也要保证严格的顺序,所有日志既不能乱序也不能有空洞 (也就是说不能被漏掉)。
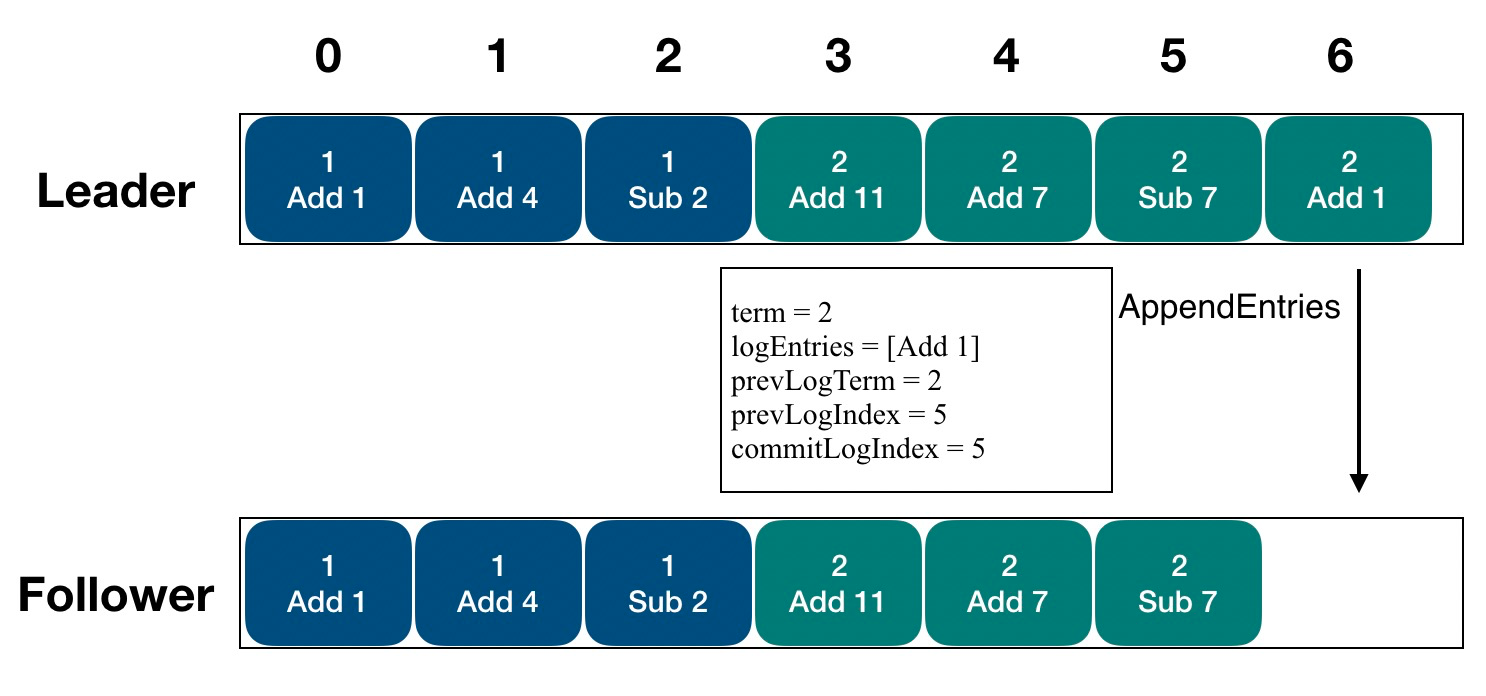
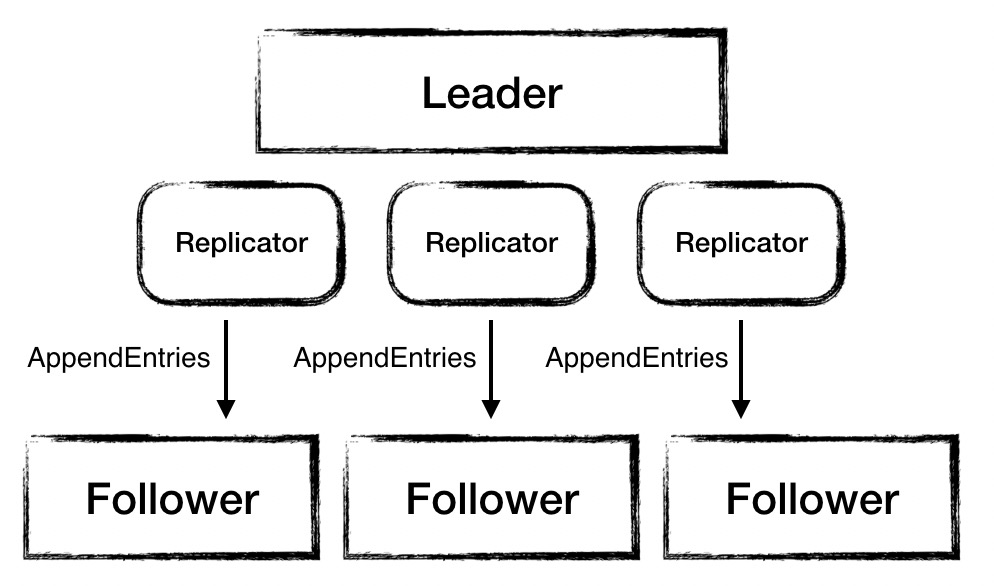
复制日志是并发的
SOFAJRaft 中 Leader 节点会同时向多个 Follower 节点复制日志,在 Leader 中为每一个 Follower 分配一个 Replicator,专用来处理复制日志任务。
复制日志是批量的
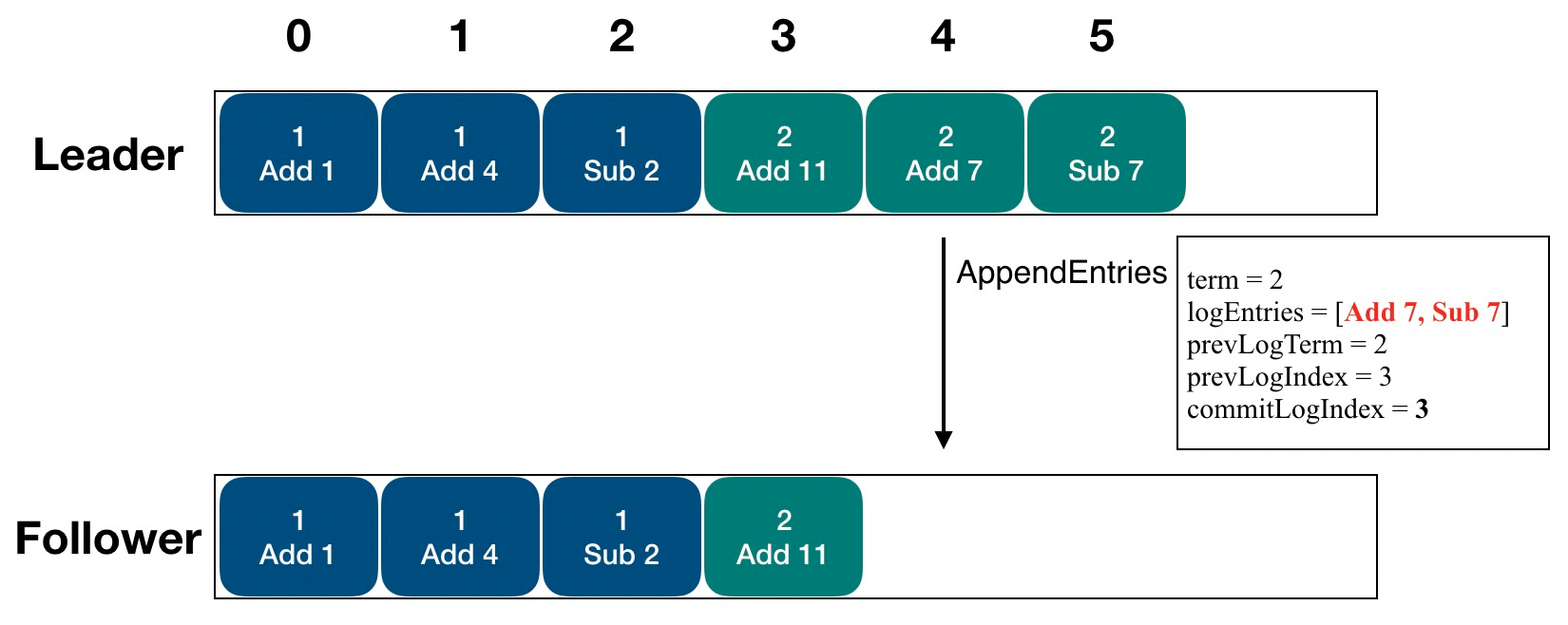
日志复制中的快照
用 Snapshot 能够让 Follower 快速跟上 Leader 的日志进度,不再回放很早以前的日志信息,即缓解了网络的吞吐量,又提升了日志同步的效率。
复制日志的 pipeline 机制
Pipeline 使得 Leader 和 Follower 双方不再需要严格遵从 “Request -Response - Request” 的交互模式,Leader 可以在没有收到 Response 的情况下,持续的将复制日志的 AppendEntriesRequest 发送给 Follower。
在具体实现时,Leader 只需要针对每个 Follower 维护一个队列,记录下已经复制的日志,如果有日志复制失败的情况,就将其后的日志重发给 Follower。这样就能保证日志复制的可靠性。

复制日志的细节
-
检测Follower日志状态
Leader 节点在通过 Replicator 和 Follower 建立连接之后,要发送一个 Probe 类型的探针请求,目的是知道 Follower 已经拥有的的日志位置,以便于向 Follower 发送后续的日志。
- 用 Inflight 来辅助实现 pipeline
Inflight 是对批量发送出去的 logEntry 的一种抽象,他表示哪些 logEntry 已经被封装成日志复制 request 发送出去了。
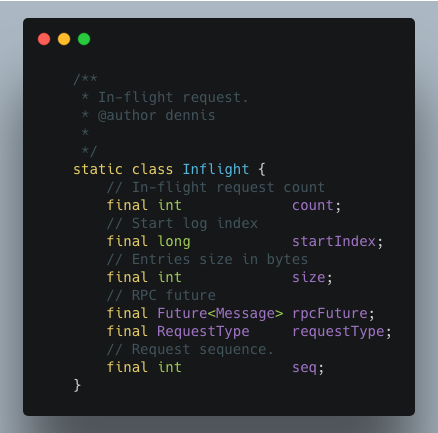
Leader 维护一个 queue,每发出一批 logEntry 就向 queue 中 添加一个代表这一批 logEntry 的 Inflight,这样当它知道某一批 logEntry 复制失败之后,就可以依赖 queue 中的 Inflight 把该批次 logEntry 以及后续的所有日志重新复制给 follower。既保证日志复制能够完成,又保证了复制日志的顺序不变。
线性一致性读
所谓线性一致读,一个简单的例子是在 t1 的时刻我们写入了一个值,那么在 t1 之后,我们一定能读到这个值,不可能读到 t1 之前的旧值。
当 Client 向集群发起写操作的请求并且获得成功响应之后,该写操作的结果要对所有后来的读请求可见。
Raft Log read
实现线性一致读最常规的办法是走 Raft 协议,将读请求同样按照 Log 处理,通过 Log 复制和状态机执行来获取读结果,然后再把读取的结果返回给 Client。因为 Raft 本来就是一个为了实现分布式环境下线性一致性的算法,所以通过 Raft 非常方便的实现线性 Read,也就是将任何的读请求走一次 Raft Log,等此 Log 提交之后在 apply 的时候从状态机里面读取值,一定能够保证这个读取到的值是满足线性要求的。
当然,因为每次 Read 都需要走 Raft 流程,Raft Log 存储、复制带来刷盘开销、存储开销、网络开销,走 Raft Log不仅仅有日志落盘的开销,还有日志复制的网络开销,另外还有一堆的 Raft “读日志” 造成的磁盘占用开销,导致 Read 操作性能是非常低效的,所以在读操作很多的场景下对性能影响很大,在读比重很大的系统中是无法被接受的,通常都不会使用。
在 Raft 里面,节点有三个状态:Leader,Candidate 和 Follower,任何 Raft 的写入操作都必须经过 Leader,只有 Leader 将对应的 Raft Log 复制到 Majority 的节点上面认为此次写入是成功的。所以如果当前 Leader 能确定一定是 Leader,那么能够直接在此 Leader 上面读取数据,因为对于 Leader 来说,如果确认一个 Log 已经提交到大多数节点,在 t1 的时候 apply 写入到状态机,那么在 t1 后的 Read 就一定能读取到这个新写入的数据。
也就是说,这样相比Raft Log read来说,少了一个Log复制的过程,取而代之的是只要确认自己的leader身份就可以直接从leader上面直接读取数据,从而保证数据一定是准确的。
那么如何确认 Leader 在处理这次 Read 的时候一定是 Leader 呢?在 Raft 论文里面,提到两种方法:
- ReadIndex Read
- Lease Read
ReadIndex Read
第一种是 ReadIndex Read,当 Leader 需要处理 Read 请求时,Leader 与过半机器交换心跳信息确定自己仍然是 Leader 后可提供线性一致读:
- Leader 将自己当前 Log 的 commitIndex 记录到一个 Local 变量 ReadIndex 里面;
- 接着向 Followers 节点发起一轮 Heartbeat,如果半数以上节点返回对应的 Heartbeat Response,那么 Leader就能够确定现在自己仍然是 Leader;
- Leader 等待自己的 StateMachine 状态机执行,至少应用到 ReadIndex 记录的 Log,直到 applyIndex 超过 ReadIndex,这样就能够安全提供 Linearizable Read,也不必管读的时刻是否 Leader 已飘走;
- Leader 执行 Read 请求,将结果返回给 Client。
使用 ReadIndex Read 提供 Follower Read 的功能,很容易在 Followers 节点上面提供线性一致读,Follower 收到 Read 请求之后:
- Follower 节点向 Leader 请求最新的 ReadIndex;
- Leader 仍然走一遍之前的流程,执行上面前 3 步的过程(确定自己真的是 Leader),并且返回 ReadIndex 给 Follower;
- Follower 等待当前的状态机的 applyIndex 超过 ReadIndex;
- Follower 执行 Read 请求,将结果返回给 Client。
ReadIndex Read 使用 Heartbeat 方式代替了日志复制,省去 Raft Log 流程。相比较于走 Raft Log 方式,ReadIndex Read 省去磁盘的开销,能够大幅度提升吞吐量。虽然仍然会有网络开销,但是 Heartbeat 本来就很小,所以性能还是非常好的。
Lease Read
虽然 ReadIndex Read 比原来的 Raft Log Read 快很多,但毕竟还是存在 Heartbeat 网络开销,所以考虑做更进一步的优化。
Raft 论文里面提及一种通过 Clock + Heartbeat 的 Lease Read 优化方法,也就是 Leader 发送 Heartbeat 的时候首先记录一个时间点 Start,当系统大部分节点都回复 Heartbeat Response,由于 Raft 的选举机制,Follower 会在 Election Timeout 的时间之后才重新发生选举,下一个 Leader 选举出来的时间保证大于 Start+Election Timeout/Clock Drift Bound,所以可以认为 Leader 的 Lease 有效期可以到 Start+Election Timeout/Clock Drift Bound 时间点。Lease Read 与 ReadIndex 类似但更进一步优化,不仅节省 Log,而且省掉网络交互,大幅提升读的吞吐量并且能够显著降低延时。
Lease Read 基本思路是 Leader 取一个比 Election Timeout 小的租期(最好小一个数量级),在租约期内不会发生选举,确保 Leader 不会变化,所以跳过 ReadIndex 的发送Heartbeat的步骤,也就降低了延时。
由此可见 Lease Read 的正确性和时间是挂钩的,依赖本地时钟的准确性,因此虽然采用 Lease Read 做法非常高效,但是仍然面临风险问题,也就是存在预设的前提即各个服务器的 CPU Clock 的时间是准的,即使有误差,也会在一个非常小的 Bound 范围里面,时间的实现至关重要,如果时钟漂移严重,各个服务器之间 Clock 走的频率不一样,这套 Lease 机制可能出问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号