Cache 和 MongoDB ,局抄 !
最近接触客户过程中,遇到了部分业务采用 Cache 或 MongoDB 作为底层数据管理。下面是从网上收集的点滴资料用做备查(to看官: 不正确的地方欢迎指正哈!)
一、Cache数据库
cache是国外医疗行业用的多的数据库产品,国内部分医院已开始使用,以对象方式存储管理医患数据(HIS用的多)。
1、cache数据库的存取模式:采用多维数据存储数据;可以用各种技术存取数据。
2、cache数据库有一个多维数组引擎和一个分布式缓存协议。多维数组用于数据存储、并发管理、事务处理、过程管理,分布式缓存协议使得存取速度快。
3、cache数据库采用以下四种方式存取数据:
(1)Web存取:cache服务器页面(CSP:cache server page),在数据服务器商运行,与他们存取的数据放在一起。
(2)对象存取:cache支持多种面向对象建模技术,可以和ration rose双向开发。
(3)SQL存取:SQL92、SQL网关技术,可以和其他关系型数据库共存(如Oracle、DB2、SQL Server、MySQL等),集成整合工作环境。
(4)多维存取:兼容Open M 语言程序(看起有点高级,不熟,看官自己查查吧)。
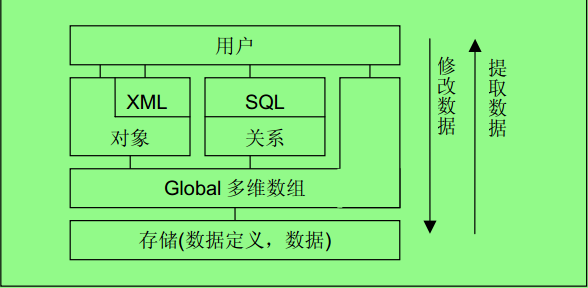
4、多维数组(Global):一种类似树的存储形式,定义形式为 Global(“节点1”,“节点2”,“节点3”)=“数据”。可以建立自己的Global,添加、删除、修改、遍历其节点。
在下图基础上,把global可以映射为对象或者关系型格式,通过对象接口或基于SQL接口进行访问。
看网上论坛Oracle和cache几爷子的PK贴,唯一收获如下:
某三甲医院HIS系统(64位RedHat 5.3、Cache 2009.1版本,IBM HS22刀片8核Xeon5570的CPU)有4000万条记录(约1.5TB)计算的性能参考如下:
1、性能方案:
(1)单台服务器:数据库平均 1,190,000 次访问/秒,高峰2,021,000 次访问/秒
(2)多台服务器使用ECP技术情况下:
1台服务器:数据库评价 992,000次访问/秒,高峰 1,690,000 次访问/秒;
4台服务器:数据库评价 4,900,000次访问/秒,高峰 6,165,000 次访问/秒;
8台服务器:数据库评价 8,900,000次访问/秒,高峰 16,690,000 次访问/秒。
2、分库问题:Cache分库的方法是使用 Global Mapping,能方便把数据拆分到不同的物理或逻辑服务器,完全不需要对应用做修改。
3、处理历史数据(死数据):医院数据不能随便删除,哪怕是确认无用的数据,Cache可以随时根据需要删除、修改、添加字段。
4、锁问题:Cache是基于Global节点的方式保存数据,锁机制可以方便地定义,可以锁到某个节点。
二、MongoDB
MongoDB是一个基于分布式文件存储的数据库,C++语言编写。能为 Web 应用提供可扩展的、高性能的数据存储解决方案,是一个介于关系数据库和非关系数据库之间的产品,它支持的数据结构非常松散,是类似 JSON 的 bson 格式,因此可以存储比较复杂的数据类型。
1、架构模式:复制集(Replica Set)、分片集群(Sharding clust)。
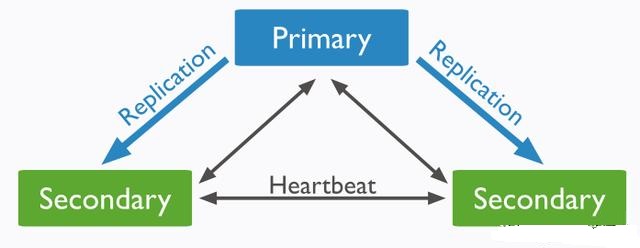
复制集通常是三个对等的节点构成一个“复制集”的集群,有“primary” 和“secondary” 等多种角色,其中 primary 负责读写请求;secondary 可以负责读请求(由配置决定)。
其中,secondary 紧跟 primary 并应用 write 操作;如果primary失效,则集群进行“多数派” 选举,选举出新的primary,即 failover机制(HA架构)。
好处:复制集解决了单点故障问题,也是MongoDB垂直扩展的最小部署单位;
缺点:集群数据容量受限于单个节点的磁盘大小,如果数据量不断增加,复制集不容易扩容。
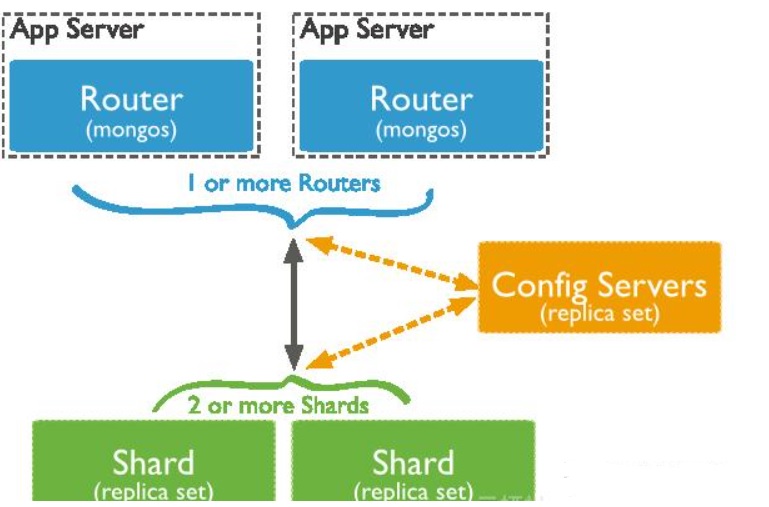
Sharding cluster 分片集群是MongoDB 数据水平扩展的手段之一,扩容方便。将整个collection 的数据根据sharding key 被 sharding 到多个 MongoDB 节点上,即每个节点持有 collection 的一部分数据,这个集群持有全部数据,原则上 sharding可以支撑数 TB的数据。
数据存取原理不写了,网上一堆。
===================================
以上资料来自网络“局抄"----局部抄,哈哈,感谢原著的 牛人!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号