关于分布式系统的数据一致性问题
现 在先抛出问题,假设有一个主数据中心在北京M,然后有成都A,上海B两个地方数据中心,现在的问题是,假设成都上海各自的数据中心有记录变更,需要先同步 到主数据中心,主数据中心更新完成之后,在把最新的数据分发到上海,成都的地方数据中心A,地方数据中心更新数据,保持和主数据中心一致性(数据库结构完 全一致)。数据更新的消息是通过一台中心的MQ进行转发。
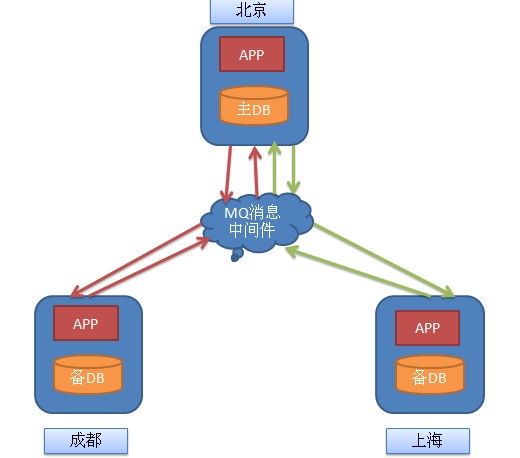
先 把问题简单化处理,假设A增加一条记录Message_A,发送到M,B增加一条记录 MESSAGE_B发送到M,都是通过MQ服务器进行转发,那么M系统接收到条消息,增加两条数据,那么M在把增加的消息群发给A,B,A和B找到自己缺 失的数据,更新数据库。这样就完成了一个数据的同步。
从正常情况下来看,都没有问题,逻辑完全合理,但是请考虑以下三个问题
1 如何保证A->M的消息,M一定接收到了,同样,如何保证M->A的消息,M一定接收到了
2 如果数据需要一致性更新,比如A发送了三条消息给M,M要么全部保存,要么全部不保存,不能够只保存其中的几条记录。我们假设更新的数据是一条条发送的。
3 假设同时A发送了多条更新请求,如何保证顺序性要求?
这两个问题就是分布式环境下数据一致性的问题
对于第一个问题,比较好解决,我们先看看一个tcp/ip协议链接建立的过程
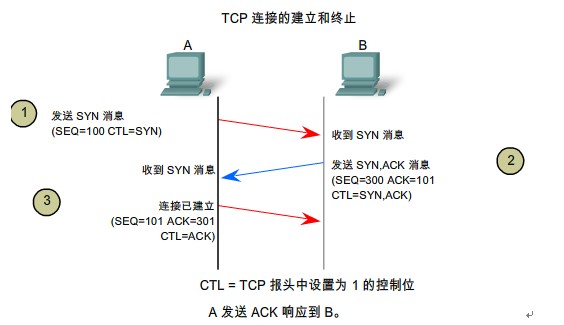
我们的思路可以从这个上面出发,在简化一下,就一个请求,一个应答。
简单的通信模型是这样的
A->M : 你收到我的一条消息没有,消息的ID是12345
M->A: 我收到了你的一条消息数据,消息数据是ID;12345
这样就一个请求,一个应答,就完成了一次可靠性的传输。如果A一致没有收到M的应答,就不断的重试。这个时候M就必须保证幂等性。不能重复的处理消息。那么最极端的情况是,怎么也收不到M的应答,这个时候是系统故障。自己检查一下吧。
这么设计就要求,A在发送消息的时候持久化这个消息的数据内容,然后不断的重试,一旦接收到M的应答,就删除这条消息。同样,M端也是一样的。不要相信MQ的持久化机制,不是很靠谱的。
那么M给A发送消息也采取类似的原理就可以了。
下面在看看第二个问题,如何保持数据的一致性更新,这个还是可以参考TCP/IP的协议。
首先A发送一条消息给M:我要发送一批消息数据给你,批次号是10000,数据是5条。
M发送一条消息给A:ok,我准备好了,批次号是10000,发送方你A
接着A发送5条消息给M,消息ID分别为1,2,3,4,5 ,批次号是10000,
紧接着,A发送一个信息给M:我已经完成5小消息的发送,你要提交数据更新了
接下来可能发送两种情况
1 那么M发送消息给A:ok,我收到了5条消息,开始提交数据
2 那么M也可以发送给A:我收到了5条消息,但是还缺少,请你重新发送,那么A就继续发送,直到A收到M成功的应答。
整个过程相当复杂。这个也就是数据一旦分布了,带来最大的问题就是数据一致性的问题。这个成本非常高。
对于第三个问题,这个就比较复杂了
这个最核心的问题就是消息的顺序性,我们只能在每个消息发一个消息的序列号,但是还是没有最好解决这个问题的办法。因为消息接收方不知道顺序。因为即使给他了序列号,也没有办法告诉他,这个应该何时处理。最好的办法是在第二种方式的基础作为一个批次来更新。
这个只是以最简单的例子来说明一下分布式系统的要保证数据一致性是一件代价很大的事情。当然有的博主会说,这个何必这么复杂,直接数据库同步不就可以了。这个例子当然是没有问题的,万一这个几个库的模型都不一样,我发送消息要处理的事情不一样的。怎么办?
在上文,简单的介绍了分布式数据的同步问题,上面的问题比较抽象,在目前的互联网应用中还很少见,这次在通过一个比较常见的例子,让大家更深入的了解一下分布式系统设计中关于数据一致性的问题
这次我们拿我们经常使用的功能来考虑吧,最近网购比较热门,就以京东为例的,我们来看看京东的一个简单的购物流程
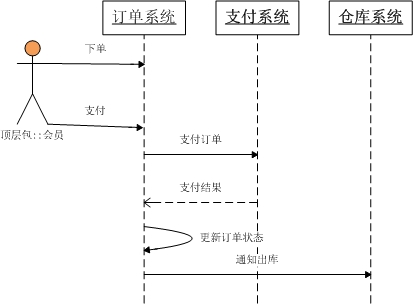
用户在京东上下了一个订单,发现自己在京东的账户里面有余额,然后使用余额支付,支付成功之后,订单状态修改为支付成功,然后通知仓库发货。假设订单系统,支付系统,仓库系统是三个独立的应用,是独立部署的,系统之间通过远程服务调用。
订单的有三个状态:I:初始 P:已支付 W:已出库,订单金额100, 会员帐户余额200
如果整个流程比较顺利,正常情况下,订单的状态会变为I->P->W,会员帐户余额100,订单出库。
但是如果流程不顺利了?考虑以下几种情况
1:订单系统调用支付系统支付订单,支付成功,但是返回给订单系统数据超时,订单还是I(初始状态),但是此时会员帐户余额100,会员肯定会马上找京东骂京东,为啥不给老子发货,我都付钱了
2:订单系统调用支付系统成功,状态也已经更新成功,但是通知仓库发货失败,这个时候订单是P(已支付)状态,此时会员帐户余额是100,但是仓库不会发货。会员也要骂京东。
3:订单系统调用支付系统成功,状态也已经更新成功,然后通知仓库发货,仓库告诉订单系统,没有货了。这个时候数据状态和第二种情况一样。
对于问题一,我们来分析一下解决方案,能想到的解决方案如下
1 假设调用支付系统支付订单的时候先不扣钱,订单状态更新完成之后,在通知支付系统你扣钱
如 果采用这种设计方案,那么在同一时刻,这个用户,又支付了另外一笔订单,订单价格200,顺利完成了整个订单支付流程,由于当前订单的状态已经变成了支付 成功,但是实际用户已经没有钱支付了,这笔订单的状态就不一致了。即使用户在同一个时刻没有进行另外的订单支付行为,通知支付系统扣钱这个动作也有可能完 不成,因为也有可能失败,反而增加了系统的复杂性。
2 订单系统自动发起重试,多重试几次,例如三次,直到扣款成功为止。
这个看起来也是不错的考虑,但是和解决方案一样,解决不了问题,还会带来新的问题,假设订单系统第一次调用支付系统成功,但是没有办法收到应答,订单系统又发起调用,完了,重复支付,一次订单支付了200。
假设支付系统正在发布,你重试多少次都一样,都会失败。这个时候用户在等待,你怎么处理?
3 在第二种方案的基础上,我们先解决订单的重复支付行为,我们需要在支付系统上对订单号进行控制,一笔订单如果已经支付成功,不能在进行支付。返回重复支付标识。那么订单系统根据返回的标识,更新订单状态。
接 下来解决重试问题,我们假设应用上重试三次,如果三次都失败,先返回给用户提示支付结果未知。假设这个时候用户重新发起支付,订单系统调用支付系统,发现 订单已经支付,那么继续下面的流程。如果会员没有发起支付,系统定时(一分钟一次)去核对订单状态,如果发现已经被支付,则继续后续的流程。
这种方案,用户体验非常差,告诉用户支付结果未知,用户一定会骂你,你丫咋回事情,我明明支付了,你告诉我未知。假设告诉用户支付失败,万一实际是成功的咋办。你告诉用户支付成功,万一支付失败咋办。
4 第三种方案能够解决订单和支付数据的一致性问题,但是用户体验非常差。当然这种情况比较可能是少数,可以牺牲这一部分的用户体验,我们还有没有更好的解决方案,既能照顾用户体验,又能够保证资金的安全性。
我 们再回来看看第一种方案,我们先不扣钱,但是有木有办法让这一部分钱不让用户使用,对了,我们先把这一部分钱冻结起来,订单系统先调用支付系统成功的时 候,支付系统先不扣钱,而是先把钱冻结起来,不让用户给其他订单支付,然后等订单系统把订单状态更新为支付成功的时候,再通知支付系统,你扣钱吧,这个时 候支付系统扣钱,完成后续的操作。
看 起来这个方案不错,我们仔细在分析一下流程,这个方案还存在什么问题,假设订单系统在调用支付系统冻结的时候,支付系统冻结成功,但是订单系统超时,这个 时候返回给用户,告知用户支付失败,如果用户再次支付这笔订单,那么由于支付系统进行控制,告诉订单系统冻结成功,订单系统更新状态,然后通知支付系统, 扣钱吧。如果这个时候通知失败,木有问题,反正钱都已经是冻结的了,用户不能用,我只要定时扫描订单和支付状态,进行扣钱而已。
那 么如果变态的用户重新拍下来一笔订单,100块钱,对新的订单进行支付,这个时候由于先前那一笔订单的钱被冻结了,这个时候用户余额剩余100,冻结 100,发现可用的余额足够,那就直接在对用户扣钱。这个时候余额剩余0,冻结100。先前那一笔怎么办,一个办法就是定时扫描,发现订单状态是初始的 话,就对用户的支付余额进行解冻处理。这个时候用户的余额变成100,订单数据和支付数据又一致了。假设原先用户余额只有100,被冻结了,用户重新下 单,支付的时候就失败了啊,的确会发生这一种情况,所以要尽可能的保证在第一次订单结果不明确的情况,尽早解冻用户余额,比如10秒之内。但是不管如何快 速,总有数据不一致的时刻,这个是没有办法避免的。
第二种情况和第三种情况如何处理,下次在分析吧。
由 于互联网目前越来越强调分布式架构,如果是交易类系统,面临的将会是分布式事务上的挑战。当然目前有很多开源的分布式事务产品,例如java JPA,但是这种解决方案的成本是非常高的,而且实现起来非常复杂,效率也比较低下。对于极端的情况:例如发布,故障的时候都是没有办法保证强一致性的。
在上文主要介绍了数据分布的情况下保证一致性的情况,在第二篇文章里面,我这里提出了三个问题
1.订单系统调用支付系统支付订单,支付成功,但是返回给订单系统数据超时,订单还是I(初始状态),但是此时会员帐户余额100,会员肯定会马上找京东骂京东,为啥不给老子发货,我都付钱了
2.订单系统调用支付系统成功,状态也已经更新成功,但是通知仓库发货失败,这个时候订单是P(已支付)状态,此时会员帐户余额是100,但是仓库不会发货。会员也要骂京东。
3.订单系统调用支付系统成功,状态也已经更新成功,然后通知仓库发货,仓库告诉订单系统,没有货了。这个时候数据状态和第二种情况一样。
重点分析解决了第一个的问题以及相应的方案,发现在数据分布的环境下,很难绝对的保证数据一致性(任何一段区间),但是有办法通过一种补偿机制,最终保证数据的一致性。
在下面在分析一下第二个问题
订单系统调用支付系统成功,状态也已经更新成功,但是通知仓库发货失败,这个时候订单是P(已支付)状态,此时会员帐户余额是100,但是仓库不会发货。会员也要骂京东。
通过在上一篇文章里面分析过,这个相对来说是比较简单的,我可以采取重试机制,如果发现通知仓库发货失败,就一致重试,
这里面有两种方式:
1 异步方式:通过类似MQ(消息通知)的机制,这个是异步的通知
2 同步调用:类似于远程过程调用
对于同步的调用的方式,比较简单,我们能够及时获取结果,对于异步的通知,就必须采用请求,应答的方式进行,这一点在(关于分布式系统的数据一致性问题(一))里面有介绍。这里面就不再阐述。
来看看第三个问题
订单系统调用支付系统成功,状态也已经更新成功,然后通知仓库发货,仓库告诉订单系统,没有货了。这个时候数据状态和第二种情况一样。
我觉得这是一个很有意思的问题,我们还是考虑几种解决的方案
1 在会员下单的时刻,就告诉仓库,我要你把货物留下来,
2 在会员支付订单时候,在支付之前检查仓库有没有货,如果没有货,就告知会员木有货物了
3 如果会员支付成功,这个时候没有货了,就会退款给用户或者等待有货的时候在发货
正常情况,京东的仓库一般都是有货的,所以影响到的会员很少,但是在秒杀和营销的时候,这个时候就不一定了,我们考虑假设仓库有10台iphone
如果采用第一种方案,
1 在会员下单的时候,相当于库存就-1,那么用户恶意拍下来,没有去支付,就影响到了其他用户的购买。京东可以设置一个订单超时时间,如果这段时间内没有支付,就自动取消订单
2 在会员支付之前,检查仓库有货,这种方案了,对于用户体验不好,但是对于京东比较好,至少我东西都卖出去了。那些没有及时付款的用户,只能投诉了京东无故取消订单
3 第三种方案,这个方案体验更不好,而且用户感觉受到京东欺诈,但是对于京东来说,比第二种方案更有益,毕竟我还可以多卖出一点东西。
个 人觉得,京东应该会采用第二种或者第三种方式来处理这类情况,我在微博上搜索了 “京东 无故取消订单”,发现果真和我预料的处理方式。不过至于这里的无故取消是不是技术上的原因我不知道,如果真的是技术上的原因,我觉得京东可以采用不同的处 理方案。对于秒杀和促销商品,可以考虑第一种方案,大多数人都会直接付款,毕竟便宜啊,如果用户抢不到便宜的东西,抱怨当然很大了。这样可以照顾大多数用 户的体验。对于一般的订单,可以采用第二种或者第三种方式,这种情况下,发生付款之后仓库没有货的情况会比较少,并且就算发生了,用户也会觉得无所谓,大 不了退钱吗,这样就可以实现自己的利益最大化而最低程度的减少用户体验。
而铁道部在这个问题上,采用的是第一种方案,为什么和京东不一样,就是因为用户体验,如果用户把票都买了,你告诉我木有票了,旅客会杀人的。哈哈,不过铁道部不担心票卖不出去,第一种方案对他影响没有什么。
说了这么多,就是说 分布式环境下(数据分布)要任何时刻保证数据一致性是不可能的,只能采取妥协的方案来保证数据最终一致性。这个也就是著名的CAP定理。
在前面三篇文章中,介绍了关于分布式系统中数据一致性的问题,这一篇主要介绍CAP定理以及自己对CAP定理的了解。
CAP定理是2000年,由 Eric Brewer 提出来的
Brewer认为在分布式的环境下设计和部署系统时,有3个核心的需求,以一种特殊的关系存在。这里的分布式系统说的是在物理上分布的系统,比如我们常见的web系统。
这3个核心的需求是:Consistency,Availability和Partition Tolerance,赋予了该理论另外一个名字 - CAP。
Consistency:一致性,这个和数据库ACID的一致性类似,但这里关注的所有数据节点上的数据一致性和正确性,而数据库的ACID关注的是在在一个事务内,对数据的一些约束。
Availability:可用性,关注的在某个结点的数据是否可用,可以认为某一个节点的系统是否可用,通信故障除外。
Partition Tolerance:分区容忍性,是否可以对数据进行分区。这是考虑到性能和可伸缩性。
为 什么不能完全保证这个三点了,个人觉得主要是因为一旦进行分区了,就说明了必须节点之间必须进行通信,涉及到通信,就无法确保在有限的时间内完成指定的行 文,如果要求两个操作之间要完整的进行,因为涉及到通信,肯定存在某一个时刻只完成一部分的业务操作,在通信完成的这一段时间内,数据就是不一致性的。如 果要求保证一致性,那么就必须在通信完成这一段时间内保护数据,使得任何访问这些数据的操作不可用。
如果想保证一致性和可用性,那么数据就不能够分区。一个简单的理解就是所有的数据就必须存放在一个数据库里面,不能进行数据库拆分。这个对于大数据量,高并发的互联网应用来说,是不可接受的。
我们可以拿一个简单的例子来说明:假设一个购物系统,卖家A和卖家B做了一笔交易100元,交易成功了,买家把钱给卖家。
这里面存在两张表的数据:Trade表Account表 ,涉及到三条数据Trade(100),Account A ,Account B
假 设 trade表和account表在一个数据库,那么只需要使用数据库的事务,就可以保证一致性,同时不会影响可用性。但是随着交易量越来越大,我们可以考 虑按照业务分库,把交易库和account库单独分开,这样就涉及到trade库和account库进行通信,也就是存在了分区,那么我们就不可能同时保 证可用性和一致性。
我们假设初始状态
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,I)
account(accountNo,balance) = account(A,300)
account(accountNo,balance) = account(B,10)
在理想情况下,我们期望的状态是
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,S)
account(accountNo,balance) = account(A,200)
account(accountNo,balance) = account(B,110)
但是考虑到一些异常情况
假设在trade(20121001,S)更新完成之前,帐户A进行扣款之后,帐户A进行了另外一笔300款钱的交易,把钱消费了,那么就存在一个状态
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,S)
account(accountNo,balance) = account(A,0)
account(accountNo,balance) = account(B,10)
产生了数据不一致的状态
由 于这个涉及到资金上的问题,对资金要求比较高,我们必须保证一致性,那么怎么办,只能在进行trade(A,B,20121001)交易的时候,对于任何 A的后续交易请求trade(A,X,X),必须等到A完成之后,才能够进行处理,也就是说在进行trade(A,B,20121001)的时 候,Account(A)的数据是不可用的。
任 何架构师在设计分布式的系统的时候,都必须在这三者之间进行取舍。首先就是是否选择分区,由于在一个数据分区内,根据数据库的ACID特性,是可以保证一 致性的,不会存在可用性和一致性的问题,唯一需要考虑的就是性能问题。对于可用性和一致性,大多数应用就必须保证可用性,毕竟是互联网应用,牺牲了可用 性,相当于间接的影响了用户体验,而唯一可以考虑就是一致性了。
牺牲一致性
对 于牺牲一致性的情况最多的就是缓存和数据库的数据同步问题,我们把缓存看做一个数据分区节点,数据库看作另外一个节点,这两个节点之间的数据在任何时刻都 无法保证一致性的。在web2.0这样的业务,开心网来举例子,访问一个用户的信息的时候,可以先访问缓存的数据,但是如果用户修改了自己的一些信息,首 先修改的是数据库,然后在通知缓存进行更新,这段期间内就会导致的数据不一致,用户可能访问的是一个过期的缓存,而不是最新的数据。但是由于这些业务对一 致性的要求比较高,不会带来太大的影响。
异常错误检测和补偿
还有一种牺牲一致性的方法就是通过一种错误补偿机制来进行,可以拿上面购物的例子来说,假设我们把业务逻辑顺序调整一下,先扣买家钱,然后更新交易状态,在把钱打给卖家
我们假设初始状态
account(accountNo,balance) = account(A,300)
account(accountNo,balance) = account(B,10)
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,I)
那么有可能出现
account(accountNo,balance) = account(A,200)
trade(buyer,seller,tradeNo,status) = trade(A,B,20121001,S)
account(accountNo,balance) = account(B,10)
那么就出现了A扣款成功,交易状态也成功了,但是钱没有打给B,这个时候可以通过一个时候的异常恢复机制,把钱打给B,最终的情况保证了一致性,在一定时间内数据可能是不一致的,但是不会影响太大。
两阶段提交协议
当 然,还有一种方式就是我另外一篇文章里面《X/Open DTP-分布式事务模型》里面说的,但是再第一阶段和第二阶段之间,数据也可不能是一致性的,也可能出现同样的情况导致异常。而且DTP的分布式事务模型 限制太多,例如必须有实现其功能的相关的容器支持,并且资源管理器也必须实现了XA规范。限制比较多。
国外有的架构师有两种方案去解决CAP的限制,但是也是比较适合特定的业务,而没有通用的解决方案,
探知分区->分区内操作->事后补偿
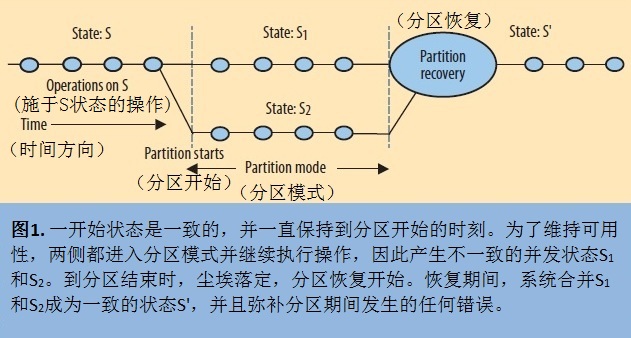
就是上面介绍的异常检测恢复机制,这种机制其实还是有限制,
首先对于分区检测操作,不同的业务涉及到的分区操作可能不一样
分区内操作限制:不同的业务对应的约束不一致
事后补偿:由于业务约束不一样,补偿方式也不一样。
所以这只能作为一种思想,不能做一个通用的解决方案

