
论文阅读 Dynamic Network Embedding by Modeling Triadic Closure Process
3 Dynamic Network Embedding by Modeling Triadic Closure Process
Abstract
本文提出了一种利用三元组闭包过程来建模时间序列的方法。
Conclusion
在本文中,我们提出了一种新的动态网络表示学习算法,以及一种学习顶点动态表示的半监督算法。为了验证模型和学习算法的有效性,我们在三个真实网络上进行了实验。实验结果表明,与几种最先进的技术相比,我们的方法在六个应用中取得了显著的效果。(基本属于啥都没说)
Figure and table
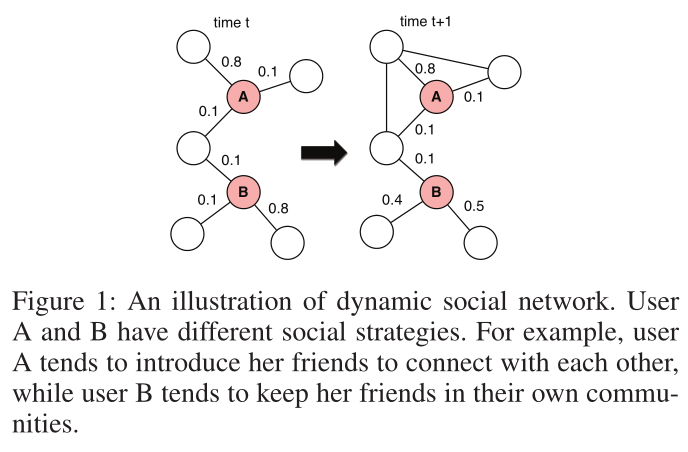
图1 动态社交网络的例证。用户A和B有不同的社交策略。例如,用户A倾向于介绍她的朋友来相互联系,而用户B倾向于将她的朋友留在自己的社区中。
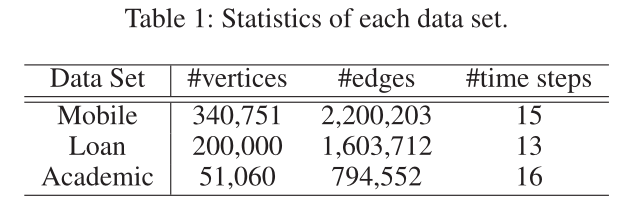
表1 数据集参数
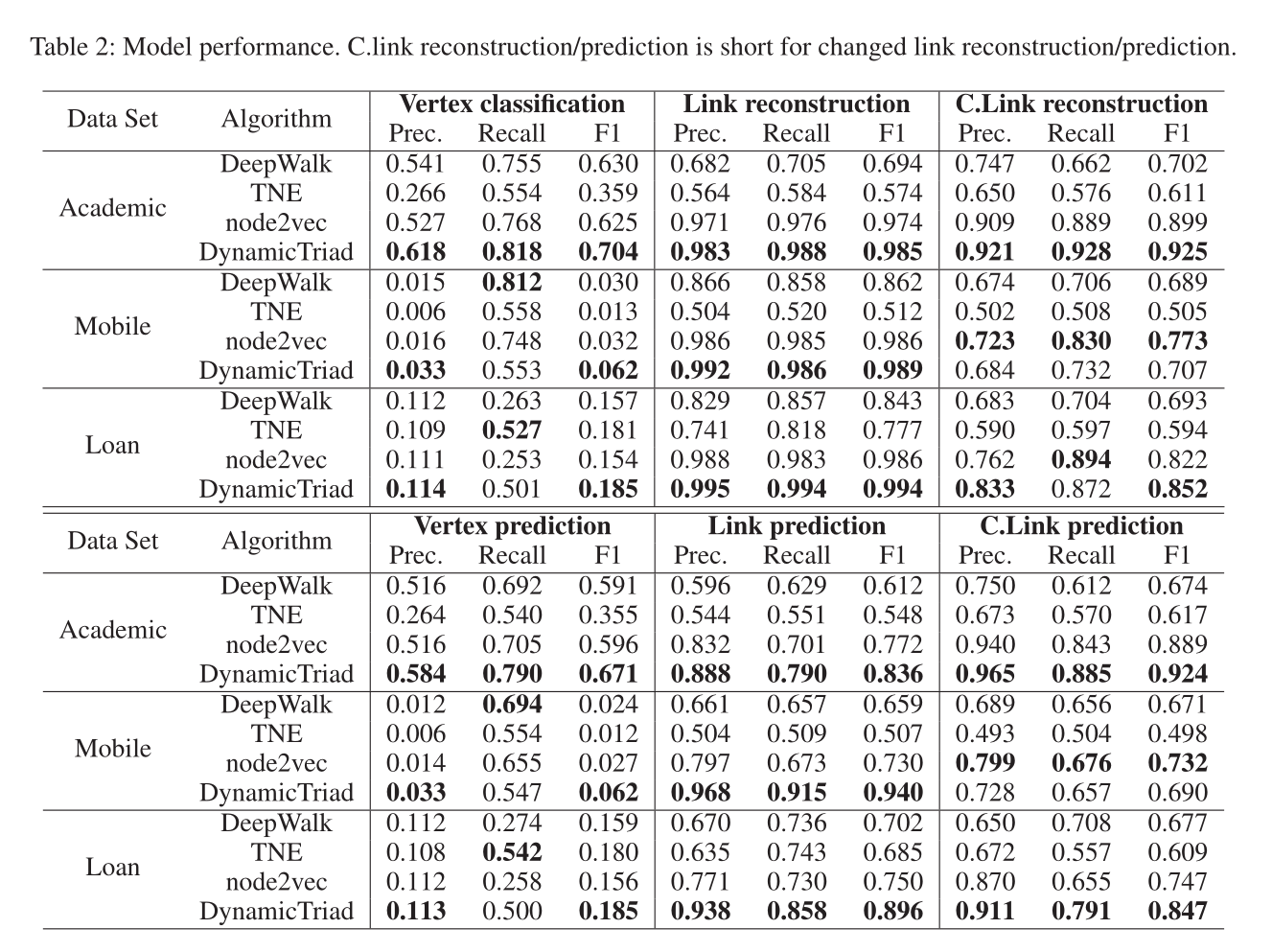
表2 模型表现(应该是测了两次)
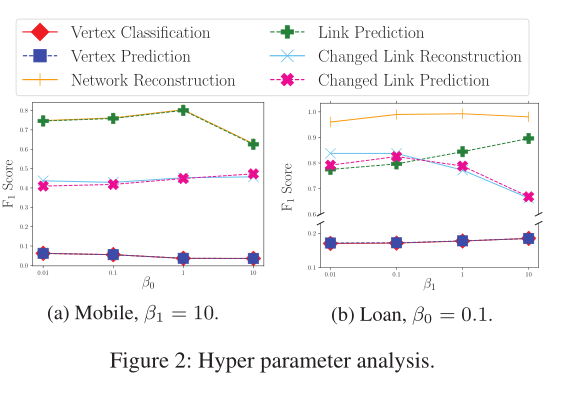
图2 超参数分析
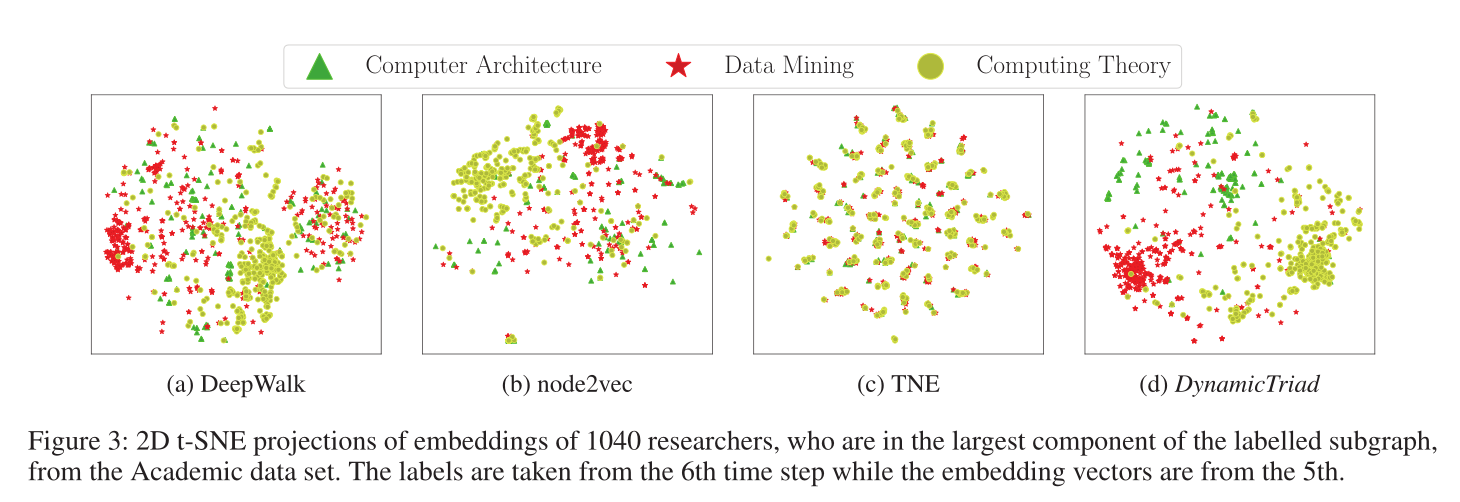
图3 使用2D t-SNE的可视化,数据集为academic。
Introduction
There is nothing permanent except change.— Heraclitus
如图1,作者认为在时间步\(t+1\),A的两对朋友相互连接,而B的朋友之间仍然没有链接。此外,用户B在时间步\(t+1\)时会将精力分散到其他朋友身上,而用户A则一直专注于发展与时间步t时相同朋友的关系。用户的不同进化模式反映了他们自己的性格和社交策略之间的差异,这些策略用于满足他们的社交需求,如与他人建立联系。例如,用户A倾向于相互介绍她的朋友,而用户B倾向于让她的朋友在自己的社区中保持紧密联系。因此,学习到的表示是否能很好地反映顶点的演化模式是网络嵌入方法的关键要求。
在本文中,通过捕捉网络的进化结构特性来学习顶点的嵌入向量。
具体来说 ,本文通过使用三元组的闭合过程来模拟网络结构的动态变化。
本文有三点贡献
1)我们提出了一种新的动态网络表示学习模型。我们的模型能够保留网络的结构信息和演化模式。
2)我们开发了一种用于参数估计的半监督学习算法。
3)模型可以在几个最先进的基线上实现显著的改进(例如,在链路预测方面,F1提高了34.4%)。
Method
Our Approach
Model Description
三元闭合过程:从时间t的一个开放三元组\((v_i,v_j,v_k)\)的示例开始,其中,用户\(v_i\)和\(v_j\)彼此不认识,但他们都是\(v_k\)的朋友(即\(e_{ik}、e_{jk}∈ E^t\)和\(e_{ij}\notin E^t\))。现在,用户\(v_k\)将决定是否引入\(v_i\)和\(v_j\),让它们相互了解,并在下一个时间步\(t+1\)在它们之间建立连接。我们自然会假设\(v_k\)将根据她与\(v_i\)和\(v_j\)(在潜在空间中)的接近程度做出决定,这由\(d\)维向量\(x^t_{ijk}\)量化为
其中\(w^t_{ik}\)是在\(t\)时刻\(v_i\)和\(v_k\)的强度(应该是线性变换的可训练矩阵)
\(\boldsymbol{u}_{k}^{t}\)是在\(t\)时刻\(v_k\)的嵌入表示
此外,定义了一个社交策略参数\(θ\),它是一个维度向量,用于提取嵌入每个节点潜在向量中的社交策略信息。
基于上述定义,定义开放三元组\((v_i,v_j,v_k)\)演变为闭合三元组的概率。即在\(v_k\)的介绍(或影响)下,\(v_i\)和\(v_j\)将在时间\(t+1\)时在它们之间建立链接的概率如下(将上述的距离用sigmoid映射为\([0,1]\)的概率)
同样,\(v_i\)和\(v_j\)可能由他们的几个共同朋友介绍,因此,我们的下一个目标是联合建模多个开放三元组(具有一对共同的未链接顶点)是如何演化的。首先定义集合\(B^t(i,j)\)为\(v_i\)和\(v_j\)在\(t\)时间的共同邻居,并且定义一个向量\(\boldsymbol{\alpha}^{t, i, j}=\left(\alpha_{k}^{t, i, j}\right)_{k \in B^{t}(i, j)}\),其中对于每一维的值如下定义,如果\(t+1\)处的开放三元组\((v_i,v_j,v_k)\)将发展为闭合三元组。换句话说,在\(v_k\)的影响下,\(v_i\)和\(v_j\)将成为朋友,则为1。
很明显,一旦\((v_i,v_j,v_k)\)闭合,所有与\(v_i\)和\(v_j\)相关的开放三元组都将关闭。因此,通过进一步假设每个普通朋友对\(v_i\)和\(v_j\)潜在链接的影响之间的独立性,我们将在时间步\(t+1\)创建新链接\(e_{ij}\)的概率定义为(伯努利分布)
同时,如果\(v_i\)和\(v_j\)没有受到任何共同朋友的影响,则不会创建边缘\(e_{ij}\)。我们将其概率定义为
将上述两条可能的开放三元组(vi、vj、vk)演化可能放在一起,
且定义
\(S_{+}^{t}=\left\{(i, j) \mid e_{i j} \notin E^{t} \wedge e_{i j} \in E^{t+1}\}\right.\)为在t+1时刻成功创建链接的集合,
\(S_{-}^{t}=\left\{(i, j) \mid e_{i j} \notin E^{t} \wedge e_{i j} \notin E^{t+1}\}\right.\)为在t+1时刻没有创建链接的集合
然后,我们将三元组闭合过程的损失函数定义为数据的负对数似然:
社会同质性与时间平滑:我们利用另外两个假设来加强DynamicTriad:社会同质性与时间平滑。社会同质性表明,高度连接的顶点应该紧密嵌入潜在的表示空间中。形式上,我们将两个顶点之间的距离\(v_j\)和\(v_k\)的嵌入\(u^t_j\)和\(u^t_k\)定义为
在当前时间步t,我们将所有顶点对分为两组
边组:$E^t_+ = E^t $
和非边组:\(E^t_- =\left\{e_{j k} \mid j \in\{1, \cdots, N\}, k \in\{1, \cdots, N\}, j \neq k, e_{j k} \notin E^{t}\right\}\)
根据同质性假设,如果两个顶点相互连接,它们往往嵌入在潜在表示空间中更紧密,所以对于社会同质性的基于排名的损失函数为
这里先提一下排名损失函数(ranking loss-based function),知乎回答链接:https://zhuanlan.zhihu.com/p/158853633
ranking loss的目的是去预测输入样本之间的相对距离。这里用的是两个节点去做三元组的排名损失变种(因为这里没有锚点),希望正样本\(g^{t}(j, k)\)的距离越小越好(接近于0),负样本\(g^{t}(j^{\prime}, k^{\prime})\)的距离越大越好(起码大于一个边界值\(\xi\))
其中$[x]_+ = m a x ( 0, x) $
\(\xi\)是边界值(margin value)
函数\(h(.,.)\)结合了权重和嵌入差异度量,通常\(h(w, x) = w · x\)
假设一个网络会随着时间的推移而平稳发展,而不是在每一个时间步中完全重建。因此,我们通过最小化相邻时间步长中嵌入向量之间的欧氏距离来定义时间平滑度。形式上,相应的损失函数为
因此,给出第一个T时间步的总体优化问题是
Model Learning
对数似然近似:从三元闭包的损失开始(等式5),对于计算非边的项\(-\sum_{(i, j) \in S_{-}^{t}} \log P_{\mathrm{tr}_{-}}^{t}(i, j)\)可计算为如下(浅推了一下,只能说通透):
推导如下
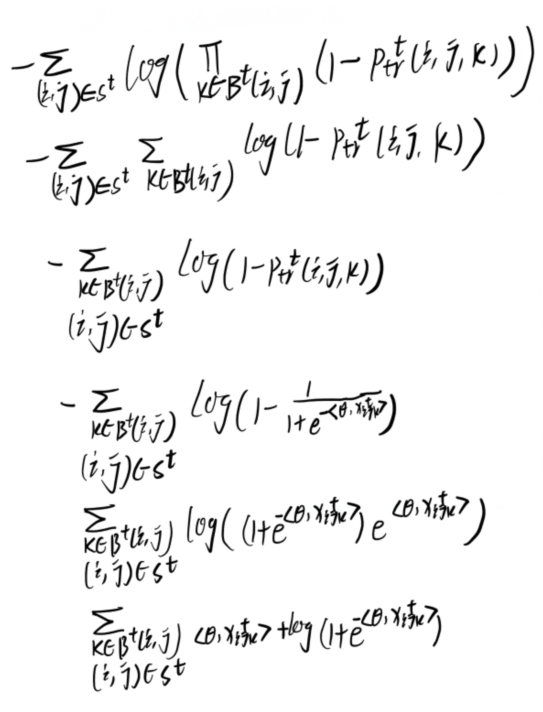
但是比较棘手的是第一项的正采样,因为\({\alpha}^{t, i, j}\)具有指数数量的可能值,为了解决这个问题,我们采用了一种类似于期望最大化(expectation maximization,EM)算法的方法来优化这个项的上界。具体来说,我们计算该项的上界为
其中
可以在迭代开始时给定\(i、j、k\)和\(t\)预先计算,\(θ(n)\)和\(u(n)\)是当前迭代下的模型参数。由于篇幅有限,省略了推导细节。结合式(10)和式(11),我们得到了\(L^t_{tr}\)的上界
采样:如果对所有正负样本均进行计算,开销较大。所以采样策略为在时间步t处给定一个正采样(边)\(e_{jk}\),先随机选择一个节点\(v_{{j^\prime} \in \{j,k\}}\),再从其他节点随机选择一个节点\(v_{{k^\prime}}\),使得\(v_{{j^\prime,k^\prime}} \notin E^t\),即为负采样。
对每个边\(e_{jk}\)重复采样过程,我们将训练集定义为\(E_{\mathrm{sh}}^{t}=\left\{\left(j, k, j^{\prime}, k^{\prime}\right) \mid(j, k) \in E^{t}\right\}\),损失函数可以表示为
对于三元组闭合过程的损失函数,\((j, k, j^{\prime}, k^{\prime})\in E_{\mathrm{sh}}^{t}\)。我们首先从\({v_j,v_k}\)中随机选择一个顶点,在影响结果的情况下,我们假设选择了vk。然后我们的目标是采样一个顶点\(v_i\),其中\(e_{ik} \in E_t,e_{ij} \notin E_t\),所以我们得到一个开放的三元组\((i,j,k)\),其中\(v_k\)连接\(v_i\)和\(v_j\)。开放三元组可以是一个正实例,也可以是一个负实例,取决于它是否在下一个时间步骤中闭合(即\(e_{ij} \in E_{t+1}\)),结合公式13如下
由于\(L^t_{tr,1}\)依赖于时间步\(t+1\)处的信息,最后一个时间步T有一个特例
综上所述,训练阶段的总体损失函数为
其中前两项共享一组相同的样本,第三项对应于时间平滑度。
 续联
续联
算法流程如上
优化:采用随机梯度下降(SGD)框架和Adagrad方法。
Experiment
Experimental Results
Data Sets
Mobile, Loan,Academic
参数信息见表1
Tasks and Baselines
六个任务:节点分类,节点预测,链接重构(两个节点是否存在边),链接预测(和重构的区别是根据当前时间步t的嵌入,去预测下个时间步t+1中边缘的存在),更改链接重建和预测。
三个baseline:DeepWalk,node2vec,Temporal Network Embedding 。
Quantitative Results
具体sota见表2
参数对本文模型的影响见图2(影响较小)
嵌入可视化见图3
Summary
本文通过捕捉网络中三元组的闭合来达到建模网络演化过程,在动态图中是一种较为独特的思路,公式较多,但是解释清楚。尤其是对正样本的损失处理为了避免指数数量的可能值,采用了一种类似于期望最大化算法的方法来做,很巧妙。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号