YOLO 学习之路
参考自官网 https://pjreddie.com/darknet/install/
1. 下载darknet 并编译
git clone https://github.com/pjreddie/darknet.git
注意事项: 如果是使用CPU, 那么就需要设置以下几个参数
GPU=0
CUDNN=0
OPENCV=1
OPENMP=0
DEBUG=0
如果opencv是使用的自己编译的库,那么就需要更改opencv路径 改这里:
LDFLAGS+= `pkg-config --libs opencv` -lstdc++
COMMON+= `pkg-config --cflags opencv`
2. test
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
3. train the dataset of VOC
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
4. yolo 的各种参数,比如batch_size
https://blog.csdn.net/hjxu2016/article/details/80015559
5. 训练需要的文件
(1) picture files :
/darknet/VOCdevkit/VOC2007/JPEGImages/000001.jpg ... ...

(2) labels such as :
content of the txt is as flow:
11 0.344192634561 0.611 0.416430594901 0.262
14 0.509915014164 0.51 0.974504249292 0.972
explain :
11 is classfied as a dog and (0.34,0.6,0.4, 0.26) is position (center.x , center.y , w , h) of the object .
14 is the dog and its poistion
if the 2 position is draw on the picture , it will dispalys as :
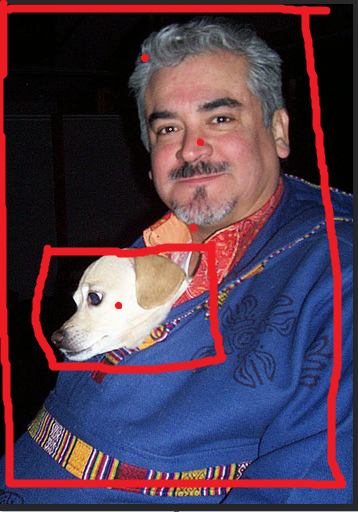
(3) train.txt this files contains all the picture to train . its contents is as folows:
/root/darknet/VOCdevkit/VOC2012/JPEGImages/2009_000001.jpg
... ...
(4) cfg/voc.data
classes= 20
train = ./train.txt
valid = ./2007_test.txt
names = data/voc.names
backup = backup
(5) data/voc.names the names of classes form 0 - 19
aeroplane
bicycle
bird
boat
bottle
bus
car
cat
chair
cow
diningtable
dog
horse
motorbike
person
pottedplant
sheep
sofa
train
tvmonitor
(6) pre-trained convlutional weights :
darknet53.conv.74
综上所述 如果你要训练一个模型,你得按以下步骤
1. 获得你要训练的图片,包括 正例 和 反例
2. 给你的正例和反例进行标注, 生成labels
3.将你的数据分成两拨, 一波是训练集, 一波是测试集
4. 修改train.txt lables cfg/voc.data ....
4 yolov3 训练人脸数据集
https://blog.csdn.net/ycdhqzhiai/article/details/81205503
5. GPU版本
5.1 install NVIDA driver
install Nvida cuda
install Nvida cudnn
modify Makefile as flow
你的arch 要根据这个网站来查 算力查询 : https://developer.nvidia.com/cuda-gpus
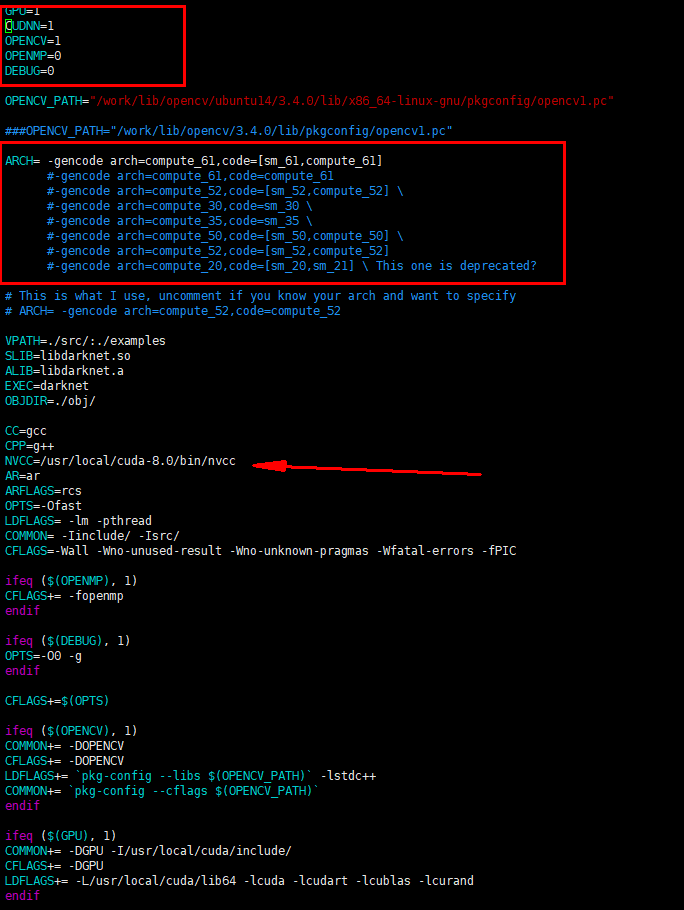
5.2 make
5.3 test ./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
5.4 modify cfg/yolov3-voc.cfg 使batch=64 , subsions=16
5.5 train start
5.6 after train , you can test your models as flow :
6. yolo 训练日志解释
- 每个batch都会有这样一个输出:
2706: 1.350835, 1.386559 avg, 0.001000 rate, 3.323842 seconds, 173184 imag
2706:batch是第几组。
1.350835:总损失
1.386559 avg : 平均损失
0.001000 rate:当前的学习率
3.323842 seconds: 当前batch训练所花的时间
173184 images : 目前为止参与训练的图片总数 = 2706 * 64
Region 82 Avg IOU: 0.798032, Class: 0.559781, Obj: 0.515851, No Obj: 0.006533, .5R: 1.000000, .75R: 1.000000, count: 2Region Avg IOU: 表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比.
Class: 标注物体分类的正确率,期望该值趋近于1。
Obj: 越接近1越好。
No Obj: 期望该值越来越小,但不为零。
count: count后的值是所有的当前subdivision图片(本例中一共4张)中包含正样本的图片的数量。
7. 训练参数 cfg
https://blog.csdn.net/qq_35608277/article/details/79922053
https://github.com/jaskarannagi19/yolov3#when-should-i-stop-training
1.当看到平均损失0.xxxxxx avg在多次迭代时不再减少时,您应该停止训练,一旦训练停止,从最后一个文件中darknet\build\darknet\x64\backup选择最好的.weights文件.
2. 0.XXX avg < 0.06 时
您在9000次迭代后停止了训练,但最佳结果可以给出之前的权重之一(7000,8000,9000)。它可能由于过度拟合而发生。
过度拟合 - 例如,您可以从training-dataset检测图像上的对象,但无法检测任何其他图像上的对象。你应该从早期停止点获得权重:
9.mAP
基本定义: precision和recall的含义, preicision是在你认为的正样本中, 有多大比例真的是正样本, recall则是在真正的正样本中, 有多少被你找到了。
10 mAP 计算
https://blog.csdn.net/amusi1994/article/details/81564504
11 基于前面的模型继续训练
build\darknet\x64\darknet.exe detector train .\cfg\pikaiqiu.data .\cfg\yolov3_pikaqiu.cfg backup\yolov3_pikaqiu_2500.weights
12 yolov3 里的mask的含义
mask = 6,7,8 ### 第一层标记为6 7 8 因为我们需要在第一层预测size较大的物体,同理第二层那个预测小一点的物体
#anchors是可以事先通过cmd指令计算出来的,是和图片数量,width,height以及cluster(应该就是下面的num的值,即想要使用的anchors的数量)相关的预选框,可以手工挑选,也可以通过kmeans 从训练样本中学>出!
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1 #类别数量 网络需要识别的物体种类数
num=9 #每个grid cell预测几个box,和anchors的数量一致。当想要使用更多anchors时需要调大num,且如果调大num后训练时Obj趋近0的话可以尝试调大object_scale
jitter=.3 #数据扩充的抖动操作 利用数据抖动产生更多数据,YOLOv2中使用的是crop,filp,以及net层的angle,flip是随机的,jitter就是crop的参数,tiny-yolo-voc.cfg中jitter=.3,就是>在0~0.3中进行crop
ignore_thresh = .5 #决定是否需要计算IOU误差的参数,大于thresh,IOU误差不会夹在cost function中
truth_thresh = 1
random=1 #默认参数1,如果显存很小,将random设置为0,关闭多尺度训练;如果为1,每次迭代图片大小随机从320到608,步长为32,如果为0,每次训练大小与输入大小一致
13 如何提高mAP
https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
14 训练出来测试的时候有null 怎么解决?? 感觉像是因为模型没有训练出来的原因啊??

15:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】