inline hook原理(x86平台实现)
概念
inline hook是一种通过修改机器码的方式来实现hook的技术。
原理
对于正常执行的程序,它的函数调用流程大概是这样的:
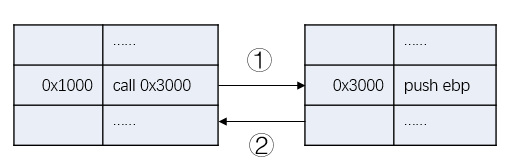
0x1000地址的call指令执行后跳转到0x3000地址处执行,执行完毕后再返回执行call指令的下一条指令。
我们在hook的时候,可能会读取或者修改call指令执行之前所压入栈的内容。那么,我们可以将call指令替换成jmp指令,jmp到我们自己编写的函数,在函数里call原来的函数,函数结束后再jmp回到原先call指令的下一条指令。如图:
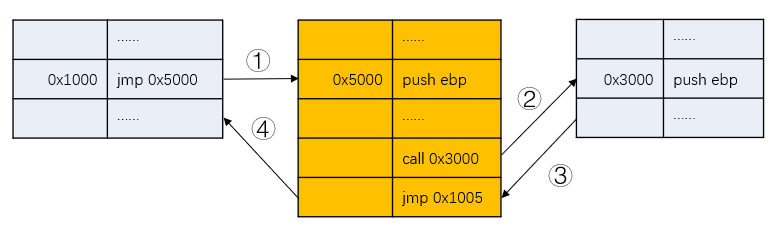
通过修改机器码实现的inline hook,不仅不会破坏原本的程序逻辑,而且还能执行我们的代码,读写被hook的函数的数据。
inline hook流程
(1)寻找hook位置
在逆向的时候,会遇到不同类型的call,它们所占的字节可能是不一样的,本文构造一个长度为5字节的jmp指令(jmp的机器码占用1字节,跳转到的地址偏移占用4字节)来替换原来的5字节的call指令。即我们需要寻找长度为5字节的call,来进行inline hook。5字节的call形如:

(2)inline hook代码实现
在x86汇编中,同样有很多类型的jmp,本文构造inline hook使用的是近距离地址跳转的jmp指令,它的机器码为E9,这种类型的jmp指令需要一个参数,参数是当前jmp指令地址距离目标函数地址的字节数。
假设需要hook的call的指令的内存地址为:0x1000,我们想要它执行后跳转到我们的函数(假设函数在内存中的地址:0x5000),那么,构造jmp指令时,指令应为:
jmp (0x5000-(0x1000 + 5))
即:
jmp 0x3FFB
对于5字节指令的hook,上面的计算公式是固定的,jmp指令本身占用5字节,所以加上5
懂了这些知识,就可以动手编写hook代码了:
int StartHook(DWORD hookAddr, BYTE backCode[5], void(*FuncBeCall)()) {
DWORD jmpAddr = (DWORD)FuncBeCall - (hookAddr + 5);
BYTE jmpCode[5];
*(jmpCode + 0) = 0xE9;
*(DWORD *)(jmpCode + 1) = jmpAddr;
HANDLE hProcess = OpenProcess(PROCESS_ALL_ACCESS, NULL, GetCurrentProcessId());
if (ReadProcessMemory(hProcess, (LPVOID)hookAddr, backCode, 5 , NULL) == 0) {
return -1;
}
if (WriteProcessMemory(hProcess, (LPVOID)hookAddr, jmpCode, 5, NULL) == 0) {
return -1;
}
return 0;
}
上面的StartHook函数,hookAddr接收一个将被替换的call指令的内存地址;backCode接收一个长度为5字节的数组缓冲区,用于备份原有的call指令;FuncBeCall参数接收一个返回值为void函数地址。
StartHook函数的逻辑是:根据FuncBeCall的地址计算jmp的地址,并构造一条完整的jmp指令,存入数组。我们要hook当前的进程,所以调用OpenProcess打开当前进程。调用ReadProcessMemory读取当前进程hookAddr处的指令,写入backCode数组。调用WriteProcessMemory将构造好的jmp指令写入当前进程hookAddr处。
StartHook函数第3个参数接收一个函数地址,这个函数地址指向的函数应该是这样的:
_declspec(naked) void OnCall() {
......
}
OnCall函数用_declspec(naked)修饰,被它修饰的函数我们常称它为裸函数,裸函数的特点是在编译生成的时候不会产生过多用于平衡堆栈的指令,这意味着在裸函数中我们要编写内联汇编控制堆栈平衡。一个比较简单写法是备份所有的寄存器,做完其他操作后再把寄存器的值还原回去,代码示例如下:
DWORD tEax = 0,tEcx = 0,tEdx = 0,tEbx = 0,tEsp = 0,tEbp = 0,tEsi = 0,tEdi = 0;
_declspec(naked) void OnCall() {
__asm {
mov tEax, eax
mov tEcx, ecx
mov tEdx, edx
mov tEbx, ebx
mov tEsp, esp
mov tEbp, ebp
mov tEsi, esi
mov tEdi, edi
}
//do something
__asm {
mov eax, tEax
mov ecx, tEcx
mov edx, tEdx
mov ebx, tEbx
mov esp, tEsp
mov ebp, tEbp
mov esi, tEsi
mov edi, tEdi
call ...
jmp ...
}
}
裸函数编写规则可以参考msdn上的这篇文档。
当我们替换到进程的jmp代码被执行,它就会跳转到该裸函数。在裸函数里,先备份所有的寄存器,然后编写我们的hook代码,编写hook代码时可以通过esp寄存器读取或者修改原call的参数,或者通过修改eax寄存器以修改原call的返回值,再或者调用其他函数等等。执行完我们的hook代码再把寄存器的值还原回去。这样就不会导致程序逻辑出错而崩溃。
但是,上面内联汇编代码的写法看起来似乎不太简洁,有更好的写法吗,答案是有的。例如:
_declspec(naked) void OnCall() {
__asm {
pushad
}
//do something
__asm {
popad
call ...
jmp ...
}
}
看,是不是简洁多了。
上面代码中,pushad的作用是把8个通用寄存器入栈,相当于:
push EAX
push ECX
push EDX
push EBX
push ESP
push EBP
push ESI
push EDI
popad作用是把栈顶的8个元素出栈,再把它们传到相应的通用寄存器,出栈顺序与pushad指令的入栈顺序正好相反,相当于:
pop EDI
pop ESI
pop EBP
pop ESP
pop EBX
pop EDX
pop ECX
pop EAX
使用pushad和popad指令,通用寄存器的数据就能方便的保存下来,也可以方便的还原回去。
卸载inline hook流程
卸载hook的流程比较简单,也是打开当前进程,把hook时备份的call指令写回原来的位置
int Unhook(DWORD hookAddr, BYTE backCode[5]) {
HANDLE hProcess = OpenProcess(PROCESS_ALL_ACCESS, NULL, GetCurrentProcessId());
if (WriteProcessMemory(hProcess, (LPVOID)hookAddr, backCode, 5, NULL) == 0) {
return -1;
}
return 0;
}
参数hookAddr是原来hook的call的内存地址,参数backCode是原来备份下来的call指令。
总结
本文是针对5字节的call进行inline hook,在寻找call的时候可能会遇到许多不同的call,比如6字节的call,或者7字节的call。对于不同的call,只要掌握了inline hook原理,就可以根据实际情况编写hook代码。
