花了两天研究的测试用例的字符串提取方式,直接拿走
我们前面跟大家分享了接口之间的数据依赖关系,解决接口之间的关系依赖方式是:
第一步:先通过jsonpath 去提取值,第二步我们接着再替换值
那么我们这个值是怎么进行替换的呢?
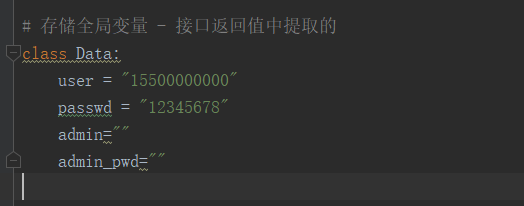
——直接从我们建立的Data 类(我们建立的my_data全局变量文件)当中取属性值为替换
还有:
1、在一条测试用例当中,你是怎么知道哪些值需要替换,哪些不需要呢?
——解决方法:打标记 #全局变量名#。
2、一条测试用例数据中,url 、data 、assert 要替换的话,你是怎么识别到有多少字段需要替换呢?你是怎么处理的?
——解决方法:一条用例当中,从excel 当中读取出来是一个字典,把字典转换成字符串,统一从字符串找所有的标识符。
3、一条测试用例数据当中,要替换多个不同的数据,你是怎么处理的?也就说,怎么样能把所有的mark 一次性找出来
——解决方法:不同的mark ,通过正则表达式,全部都找到了并且放在了列表当中。遍历标记符mark 列表,如果mark 是全局
变量的属性名,那么就将mark 替换为真实的值。
4、你是如何将用例中要替换的标识,与Data 全局变量关联起来的?
——解决方法:标识符# ,要与Data 类属性名匹配。
示例代码如下:
""" 框架当中,提取标识符(mark)的正则表达式: res = re.findall("#(\w+)#",ss2) print(res) res的结果:是一个列表。如果列表不为空,表示提取到了标识符(mark) """ import re from common.my_data import Data # 第一步:准备一条测试数据 case = { "url":"member/login", "method":"post", "req_data": '{"mobile_phone":#user#,"pwd":#passwd#}', "extract": '{"token":"$..token","member_id":"$..id","leave_amount":"$..leave_amount"}' } # 第二步,把excel当中的一整个测试用例(excel当中的一行)转换成字符串 case_str = str(case) print(case_str) # 第三步,利用正则表达式提取mark标识符 res = re.findall("#(\w+)#",case_str) print(res) # 第四步:遍历标识符mark,如果标识符是全局变量Data类的属性名,则用属性值替换掉mark if res: for mark in res: # 如果全局变量Data类有mark这个属性名 if hasattr(Data, mark): # 使用全局变量Data类的mark属性值,去替换测试用例当中的#mark# case_str = case_str.replace(f"#{mark}#", getattr(Data,mark)) print(case_str) # 第五步:将完全替换后的一整个测试用例,转换回字典 case_dict = eval(case_str) print(case_dict)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号