Java Web中的中文编码
Java Web开发中经常会遇到中文编码问题,那么为什么需要编码呢?因为人类需要表示的符号太多,无法用1个字节来表示,而计算机中存储信息最小单元为1个字节。所以必须指定char与byte之间的编码规则了。
1 常见的编码方式
计算机中提供了多种编码方式,常见的有ASCII、ISO-8859-1、GBK、GB2312、UTF-16、UTF-8等。
- ASCII 码
- 学过计算机的人都知道 ASCII 码,总共有 128 个,用一个字节的低 7 位表示,0~31 是控制字符如换行回车删除等;32~126 是打印字符,可以通过键盘输入并且能够显示出来。
- ISO-8859-1
- 128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
- GB2312
- 它的全称是《信息交换用汉字编码字符集 基本集》,它是双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字。
- GBK
- 全称叫《汉字内码扩展规范》,是国家技术监督局为 windows95 所制定的新的汉字内码规范,它的出现是为了扩展 GB2312,加入更多的汉字,它的编码范围是 8140~FEFE(去掉 XX7F)总共有 23940 个码位,它能表示 21003 个汉字,它的编码是和 GB2312 兼容的,也就是说用 GB2312 编码的汉字可以用 GBK 来解码,并且不会有乱码。
- GB18030
- 全称是《信息交换用汉字编码字符集》,是我国的强制标准,它可能是单字节、双字节或者四字节编码,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。
- UTF-16
- 说到 UTF 必须要提到 Unicode(Universal Code 统一码),ISO 试图想创建一个全新的超语言字典,世界上所有的语言都可以通过这本字典来相互翻译。可想而知这个字典是多么的复杂,关于 Unicode 的详细规范可以参考相应文档。Unicode 是 Java 和 XML 的基础,下面详细介绍 Unicode 在计算机中的存储形式。
- UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
- UTF-8
- UTF-16 统一采用两个字节表示一个字符,虽然在表示上非常简单方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的今天,这样会增大网络传输的流量,而且也没必要。而 UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以是由 1~6 个字节组成。
2 编码的场景
在IO操作中我们一般需要进行编码,这里的IO操作包括磁盘IO、网络IO等,比如下面就是一个磁盘IO的例子:
public static void main(String[] args) throws IOException { String file = "H:/name.txt"; String charset = "utf-8"; // 写字符到字节流 FileOutputStream outputStream = new FileOutputStream(file); OutputStreamWriter writer = new OutputStreamWriter(outputStream, charset); try { writer.write("中文名杭州"); } finally { writer.close(); } // 读字节流到字符 FileInputStream inputStream = new FileInputStream(file); InputStreamReader reader = new InputStreamReader(inputStream, charset); try { char[] buffer = new char[64]; reader.read(buffer); System.out.println(buffer); } finally { reader.close(); } }
在程序中设计IO编解码,只要我们指定统一的编解码Charset字符集,一般不会有问题(或者编解码都是在同一个系统中,都使用默认的字符集)。但是如果我们指定的编解码不一致,就会出现中文乱码问题。如果把代码中的InputStreamReader指定为GBK编码,就会出现乱码问题。
InputStreamReader reader = new InputStreamReader(inputStream, "GBK");

Java中使用String类型也是可以指定字节到字符转换的编码字符集的。
1 String xxx = "你好"; 2 String yyy = new String(xxx.getBytes(), "utf-8"); 3 System.out.println(yyy);
3 几种编码格式比较
对中文字符GBK/GB2312/UTF-16/UTF-8四种编码格式都能处理,GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
4 常见问题分析
当我们碰到一些乱码时,应该怎么处理这些问题?出现乱码问题唯一的原因都是在 char 到 byte 或 byte 到 char 转换中编码和解码的字符集不一致导致的,由于往往一次操作涉及到多次编解码,所以出现乱码时很难查找到底是哪个环节出现了问题,下面就几种常见的现象进行分析。
中文变成了看不懂的字符
例如,字符串“淘!我喜欢!”变成了“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”编码过程如下图所示
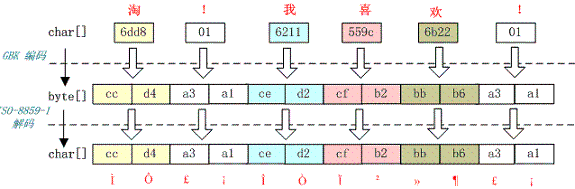
字符串在解码时所用的字符集与编码字符集不一致导致汉字变成了看不懂的乱码,而且是一个汉字字符变成两个乱码字符。
一个汉字变成一个问号
例如,字符串“淘!我喜欢!”变成了“??????”编码过程如下图所示:

将中文和中文符号经过不支持中文的 ISO-8859-1 编码后,所有字符变成了“?”,这是因为用 ISO-8859-1 进行编解码时遇到不在码值范围内的字符时统一用 3f 表示,这也就是通常所说的“黑洞”,所有 ISO-8859-1 不认识的字符都变成了“?”。
一个汉字变成两个问号
例如,字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示:

这种情况比较复杂,中文经过多次编码,但是其中有一次编码或者解码不对仍然会出现中文字符变成“?”现象,出现这种情况要仔细查看中间的编码环节,找出出现编码错误的地方。
参考:
2、《深入分析Java Web技术内幕》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号