接口开发、多进程--19
一、作业问题:ABC A依赖B ,B依赖 C
- 如何获取依赖用例--递归的方法
- 死循环问题:
- A B C A依赖B B依赖C
- A 关联 B B也关联A 出现无限递归的问题
- 必须有个条件能够让递归结束 或 逐步递减
- 用例更新时。会触发相互依赖。代码本质是创建依赖关系时 我们需要判断
一层的依赖关系解决方法
1、views.py 中caseview()中修改put方法
1 def put(self, request): 2 # 用例在更新时处理自关联的关系。 3 # 先清掉之前所有的关联,然后在重新创建 4 #外键子自关联 5 rely_case = request.PUT.get('rely_case') 6 case_id = request.PUT.get('id')#当前的用例id 7 instance = self.model.objects.get(id=case_id) 8 form_obj = self.form(request.PUT, instance=instance) 9 print('form_obj的返回数据:', form_obj) # 添加的用例的全部信息 10 if form_obj.is_valid(): 11 # 通过当前用例 获取所有被依赖的用例 并删除 12 instance.case.all().delete() 13 # 重新建立自关联绑定关系 14 # 检查当前用例 有没有被依赖用例所依赖。需要知道的当前用例id,以及当前用例所依赖的用例id。 15 # check_premise检查是否被依赖的实现: 16 # 1、被依赖的用例id中 有没有当前用例。如果有 代表递归了 17 # 2、被依赖用例可能不直接依赖于当前用例,A -- B B-- C C-- A 需要递归解决。 18 for item in json.loads(rely_case): 19 check_premise_status = check_premise(case_id,item) 20 if check_premise_status:#如果为真 代表没有被依赖的用例所依赖,可以创建依赖关系 21 models.CasePremise.objects.create(case_id=instance.id, premise_case_id=item) 22 else: 23 return NbResponse(code=-1, msg="依赖用例存在依赖关系,请查证") 24 25 form_obj.save() 26 ret = NbResponse() # 默认请求成功 27 else: 28 ret = NbResponse(code=-1, msg=form_obj.error_format) 29 return ret
2、core/case-utils.py
1 from sksystem import models 2 def check_premise(case_id, premise_id): 3 ''' 4 # 检查当前用例 有没有被依赖用例所依赖。需要 当前用例id,依赖的用例id。 5 # 检查是否被依赖的实现: 6 # 1、被依赖的用例id中 有没有当前用例。如果有 代表递归了 7 # 2、被依赖用例可能不直接依赖于当前用例,A B B C C A 递归解决。 8 让递归结束的条件,最终一定会有一个用例 没有依赖。 9 :param case_id: 10 :param premise_id: 11 :return: 12 ''' 13 # 单程 14 case_obj = models.Case.objects.get(id=premise_id)# 15 qs = case_obj.case.all()#获取所有的依赖用例 16 rely_cases = [] 17 for item in qs: 18 rely_cases.append(item.premise_case.id) # 将依赖用例 所依赖的id 添加到列表 19 print('依赖用例 所依赖的用例%s'%rely_cases) 20 print('当前用例->%s 数据类型->%s'%(case_id,type(case_id))) 21 22 23 if int(case_id) in rely_cases:#如果用例id在依赖用例中,就返回False 24 return False 25 else: 26 return True
效果:![]()
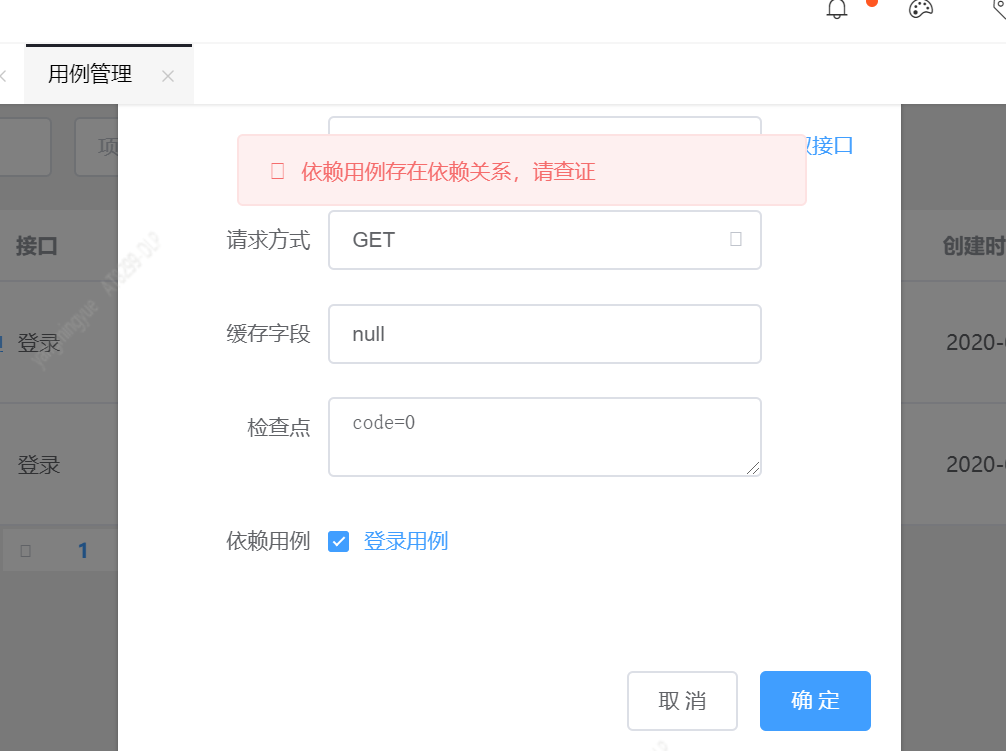
二、多层依赖
多层依赖关系需要递归的方法解决--让递归结束
递归结束的条件是最终一定有个用例没有依赖关系
1、core/case-utils.py
1 class Premise(object): 2 def __init__(self): 3 self.rely_cases = [] 4 5 def get_premise_case_id(self, case_id):#获取依赖关系 6 case_obj = models.Case.objects.get(id=case_id)# 7 qs = case_obj.case.all() 8 return qs 9 10 def loop_premise(self, case_id, premise_id):#查找所依赖的用例 11 # A B B C C A 12 qs = self.get_premise_case_id(premise_id) 13 self.rely_cases.append(premise_id) 14 for item in qs: 15 self.rely_cases.append(item.premise_case.id) # 将依赖用例 所依赖的id 添加到列表 16 if self.get_premise_case_id(item.premise_case.id): 17 self.loop_premise(case_id, item.premise_case.id) 18 return self.rely_cases 19 20 from sksystem import models 21 def check_premise(case_id, premise_id): 22 ''' 23 # 检查当前用例 有没有被依赖用例所依赖。需要 当前用例id,依赖的用例id。 24 # 检查是否被依赖的实现: 25 # 1、被依赖的用例id中 有没有当前用例。如果有 代表递归了 26 # 2、被依赖用例可能不直接依赖于当前用例,A B B C C A 递归解决。 27 让递归结束的条件,最终一定会有一个用例 没有依赖。 28 :param case_id: 29 :param premise_id: 30 :return: 31 '''
\core\case_utils.py # 递归实现
1 premise = Premise() 2 premise_ids = premise.loop_premise(case_id, premise_id) 3 print('递归获取到的依赖用例%s' % premise_ids) 4 if int(case_id) in premise_ids: 5 return False 6 else: 7 return True
三、单个用例运行
1、views.py
1 class CaseRunView(View): 2 def post(self, request): 3 case_id = request.POST.get('case_id')#用例id 4 user_id = request.POST.get('user_id') 5 6 for item_id in json.loads(case_id): 7 # 当页面调用异步任务时,会返回一个唯一的任务id 8 task_id = run_case.delay(item_id, request.user.id) 9 print('当前用例的task_id',task_id) 10 models.Case.objects.filter(id=item_id).update(report_batch=task_id, status=3)#修改用例状态,3是运行中的状态 11 return NbResponse()
2、tasks.py 调用异步任务
1 class Run(object): 2 ''' 3 提供执行单个用例的方法(执行用例最终都是执行单个用例) 4 功能一:获取依赖用例 5 功能二:运行的方法 6 判断是用例运行还是集合运行, 7 用例运行先获取到用例的id,调用异步任务,单个用例获取单个用例的依赖的用例 8 9 10 ''' 11 12 def __init__(self): 13 self.rely_cases = [] 14 15 def get_premise_case_id(self, case_id): 16 #获取当前用例的依赖用例 17 case_obj = models.Case.objects.get(id=case_id) 18 qs = case_obj.case.all() 19 return qs 20 21 def loop_premise(self, case_id,premise_case):#查找所依赖的用例 22 # A B B C C D 依赖用例应先执行,所有执行顺序应该是D C B A 23 qs = self.get_premise_case_id(case_id) 24 # self.rely_cases.append(case_id) 25 for item in qs: 26 self.rely_cases.insert(0,item.premise_case.id) # 依赖用例先执行,使用insert方法 27 if self.get_premise_case_id(item.premise_case.id): 28 self.loop_premise(item.premise_case.id) 29 self.rely_cases.append(case_id)#最后将当前用例添加到用例列表 30 return self.rely_cases 31 32 @app.task(name='run_case') 33 def run_case(case_id,user_id): 34 task_id = run_case.request.id 35 logger.debug('task_id-->%s'%task_id) 36 run = Run() 37 all_case= run.loop_premise(case_id) 38 logger.debug('所有要运行的用例-->%'%all_case)
启动celery命令
celery -A celery_tasks.main worker -l debug -P eventlet
3、运行效果
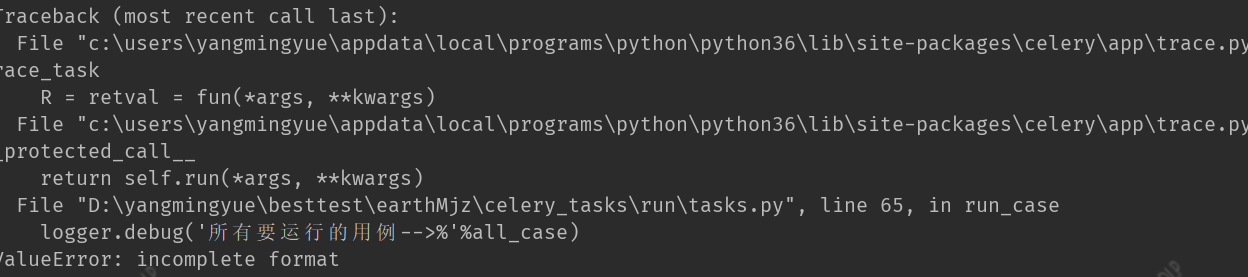
用例去重tasks.py
1 class Run(object): 2 ''' 3 提供执行单个用例的方法(执行用例最终都是执行单个用例) 4 功能一:获取依赖用例 5 功能二:运行的方法 6 判断是用例运行还是集合运行, 7 用例运行先获取到用例的id,调用异步任务,单个用例获取单个用例的依赖的用例 8 9 10 ''' 11 12 def __init__(self): 13 self.rely_cases = [] 14 15 def get_premise_case_id(self, case_id): 16 #获取当前用例的依赖用例 17 case_obj = models.Case.objects.get(id=case_id) 18 qs = case_obj.case.all() 19 return qs 20 21 def loop_premise(self, case_id):#查找所依赖的用例 22 # A B B C C D 依赖用例应先执行,所有执行顺序应该是D C B A 23 qs = self.get_premise_case_id(case_id) 24 # self.rely_cases.append(case_id) 25 for item in qs: 26 self.rely_cases.insert(0,item.premise_case.id) # 依赖用例先执行,使用insert方法 27 if self.get_premise_case_id(item.premise_case.id): 28 self.loop_premise(item.premise_case.id) 29 self.rely_cases.append(case_id)#最后将当前用例添加到用例列表 30 #如果要执行的用例重复,会拖累执行时间 31 #去重时要保证原有的顺序不发生改变 32 logger.debug('去重前的用例id-->%s'%self.rely_cases) 33 all_case = list(set(self.rely_cases))#用例去重 34 # 去重后列表顺序会发生变化,需要依赖用例前未去重的顺序, 35 #sort(key = 去重前的用例.角标) 36 all_case.sort(key=self.rely_cases.index) 37 logger.debug('去重后的用例id-->%s'%all_case) 38 return all_case
效果:如下图

四、集合--多用例用例一起运行
1、views.py 中新增集合运行接口
1 class CollectionRunView(View): 2 def post(self, request): 3 collect_id = request.POST.get('collect_id')#集合id 4 user_id = request.POST.get('user_id') 5 for item_id in json.loads(collect_id): 6 # 当页面调用异步任务时,会返回一个唯一的任务id 7 task_id = run_collection.delay(item_id, request.user.id) 8 print('集合的task_id',task_id) 9 models.CaseCollection.objects.filter(id=item_id).update(report_batch=task_id, status=3)#修改用例状态,3是运行中的状态 10 return NbResponse()
2、tasks.py 新增集合运行内容
1 @app.task(name='run_collect') 2 def run_collection(collect_id, user_id): 3 task_id = run_collection.request.id 4 #根据集合id 去获取集合下所有的用例id 5 collect_obj = models.CaseCollection.objects.get(id = collect_id) 6 qs = collect_obj.case.all()#查询多对多,获取所有的用例qs 7 #想要所有的用例id 8 cases_id = [] 9 for item in qs: 10 # cases_id.append(item.id)#将集合下的用例添加到列表中 11 logger.debug('获取所用的用例%s'%item.id)
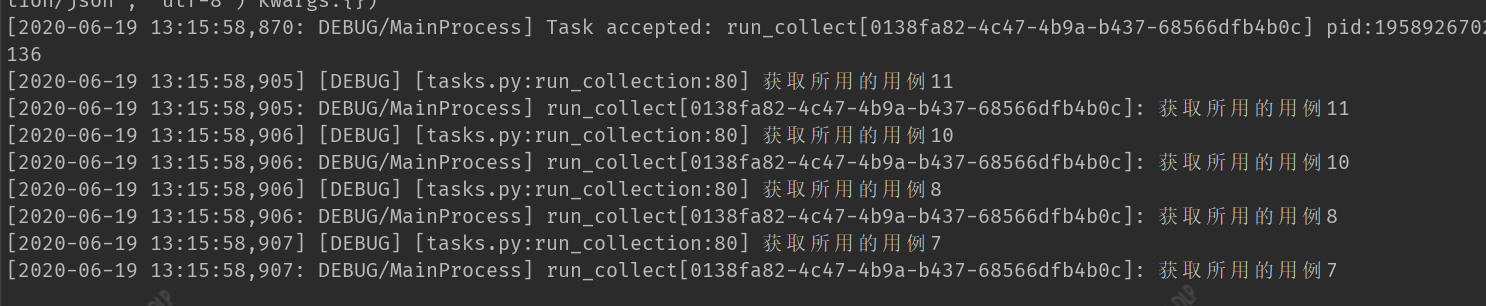
3、修改Run()增加--用例去重和排序的方法,loop递归不要写复杂
1 class Run(object): 2 ''' 3 提供执行单个用例的方法(执行用例最终都是执行单个用例) 4 功能一:获取依赖用例 5 功能二:运行的方法 6 判断是用例运行还是集合运行, 7 用例运行先获取到用例的id,调用异步任务,单个用例获取单个用例的依赖的用例 8 9 ''' 10 11 def __init__(self): 12 self.rely_cases = [] 13 14 def get_premise_case_id(self, case_id): 15 #获取当前用例的依赖用例 16 case_obj = models.Case.objects.get(id=case_id) 17 qs = case_obj.case.all() 18 return qs 19 20 def loop_premise(self, case_id): 21 #查找所依赖的用例 22 # A B B C C D 依赖用例应先执行,所有执行顺序应该是D C B A 23 qs = self.get_premise_case_id(case_id)#调用get_premise_case_id获取到的当前用例的依赖用例 24 # self.rely_cases.append(case_id) 25 for item in qs: 26 self.rely_cases.insert(0,item.premise_case.id) # 依赖用例先执行,使用insert方法 27 if self.get_premise_case_id(item.premise_case.id): 28 self.loop_premise(item.premise_case.id) 29 self.rely_cases.append(case_id)#最后将当前用例添加到用例列表 30 31 def set_premise_case(self,case_ids): 32 ''' 33 去除重复用例,并按用例执行的初始顺序排序 34 # 如果要执行的用例重复,会拖累执行时间 35 # 去重时要保证原有的顺序不发生改变 36 :param case_ids: 37 :return: 38 ''' 39 for case_id in case_ids: 40 self.loop_premise(case_id)#调用loop_premise 查找依赖用例 41 logger.debug('去重前的用例id-->%s' % self.rely_cases) 42 all_case = list(set(self.rely_cases)) # 用例去重 43 # 去重后列表顺序会发生变化,需要依赖用例前未去重的顺序, 44 # sort(key = 去重前的用例.角标) 45 all_case.sort(key=self.rely_cases.index) 46 logger.debug('去重后的用例id-->%s' % all_case) 47 return all_case 48 49 50 @app.task(name='run_case') 51 def run_case(case_id,user_id): 52 task_id = run_case.request.id 53 logger.debug('task_id-->%s'%task_id) 54 run = Run()56 all_case= run.set_premise_case([case_id]) 57 time.sleep(10) 58 logger.debug('所有要运行的用例-->%s'%all_case) 59 60 61 @app.task(name='run_collect') 62 def run_collection(collect_id, user_id): 63 task_id = run_collection.request.id 64 #根据集合id 去获取集合下所有的用例id 65 collect_obj = models.CaseCollection.objects.get(id = collect_id) 66 qs = collect_obj.case.all()#查询多对多,获取所有的用例qs 67 #想要所有的用例id 68 case_ids = [] 69 for item in qs: 70 case_ids.append(item.id)#将集合下的用例添加到列表中 71 logger.debug('获取所用的用例%s'%item.id) 72 logger.debug('当前集合下的真实用例-->%s'%case_ids) 73 run = Run() 74 all_case = run.set_premise_case(case_ids) 75 time.sleep(10) 76 logger.debug('所有要运行的用例-->%s' % all_case)
备注:整体查看运行用例和运行集合,查看结果可以达到预期效果
五、执行校验重点--替换全局参数
tasks.py 中class_Run()新增方法
1 #数据替换,将${}内容替换成真实的数据,主要涉及到全局参数,用例参数、header、cookies涉及到这个方法 2 def data_replace(self,data): 3 for k,v in data.items(): 4 keys = re.findall(r'\$\{(.*?)\}', str(v))#正则表达式,用处是将${}内容替换真实的数据 5 if keys: 6 #如果keys存在,代表有需要替换的参数 7 #从全局参数开始替换 8 value = models.Parameter.objects.get(name = keys[0]).value 9 data[k] = value 10 logger.debug('替换后的data-->%s'%data) 11 return data
校验重点:
1、const.py文件
1 page_limit = 20 # 每页展示的数量 2 token_expire = 60 * 60 * 24 # token失效时间 3 token_prefix = 'earth:seession:' #token key开头 4 cache_prefix = 'earth:cache:' #token key开头
2、tasts.py-- 中class_Run()新增方法simple_run
1 from utils.http import MyRequest#返回值 2 from utils.response import ResponseCheck#校验返回值是否正确 3 from utils import const 4 5 6 7 def simple_run(self,case_id): 8 ''' 9 功能: 10 1、获取请求的各种信息,请求方式,url,接口,参数,header 11 2、是否有${}格式内容需要替换,难题 12 3、是否需要缓存 13 4、报告 14 5、更新用例状态 15 16 :param case_id: 17 :return: 18 ''' 19 #获取用例的对象 20 # logger.debug('开始') 21 case_obj = models.Case.objects.get(id = case_id) 22 23 #域名 24 host = case_obj.project.host 25 26 # 接口 27 uri = case_obj.interface.uri 28 29 # 请求方式 30 # method = case_obj.method#稍微有点问题 31 method = case_obj.get_method_display() 32 33 #请求参数 34 # 1、接口的默认参数 case_obj.interface.params,本质是json格式,本质是str类型,想要字典类型,需要用json.loads()转换 35 # 接口参数默认有可能为空,如果为真返回interface_params,否则返回空{} 36 interface_params= json.loads(case_obj.interface.params) if case_obj.interface.params else {}
37 # 2、用例的参数,以用例的为准,涉及到根据用例更新参数 38 case_params = json.loads(case_obj.params) if case_obj.params else{} 39 40 # header 41 # 1、case_obj.interface.headers,本质是json格式,想要str,想要字段类型 需要用json.loads()转换 42 # interface_header默认有可能为空,如果为真返回interface_params,否则返回{} 43 # 接口header 44 interface_header = json.loads(case_obj.interface.headers) if case_obj.interface.headers else {} 45 46 # case内的header 47 case_header = json.loads(case_obj.headers) if case_obj.headers else {} 48 49 #用例当中涉及到is_json 50 is_json =case_obj.is_json
51 # json的数据 52 json_data =json.loads(case_obj.is_json) if case_obj.is_json else{} 53 54 #下一步要做组装的操作,合并参数并且替换,新增更新,相同替换 55 # 用到之前学到的字典参数 57 # 1、用例参数为蓝本 58 interface_header.update(case_header)#用例的header覆盖接口的header 59 header = self.data_replace(interface_header)#将接口中header数据替换 60 61 #2、参数合并,需要根据is_json 的状态来判断以谁为蓝本,如果是json的字段,那就是json和接口参数合并,如果不是json字段,就是用例和接口参数合并 62 #以用例为蓝本,将接口的参数替换 63 if is_json: 64 interface_params.update(json_data) 65 else: 66 interface_params.update(case_params) 67 data = self.data_replace(interface_params)#替换接口参数 68 69 #实例化.results直接返回结果 70 response = MyRequest(url = host+uri,method = method,data = data,is_json = is_json,headers = header).results 71 logger.debug('接口返回值-->%s'%response) 72 73 74 # logger.debug('host-->%s' % host) 75 logger.debug('url-->%s' %(host+uri)) 76 logger.debug('method-->%s' % method) 77 logger.debug('参数-->%s' % data) 78 # logger.debug('interface_params-->%s' % interface_params) 79 # logger.debug('interface_params-->%s' % case_params) 80 # logger.debug('interface_header-->%s' % interface_header) 81 # logger.debug('case_header-->%s' % case_header) 82 # logger.debug('is_josn-->%s' % is_json) 83 # logger.debug('json_data-->%s' % json_data) 84 85 #验证接口返回值 86 check = case_obj.check 87 res = ResponseCheck(check,response) 88 # 用例结果状态 89 status = res.status
90 #失败原因 91 reason = res.reason 92 93 logger.debug('用例状态-->%s'%status) 94 logger.debug('失败原因-->%s'%reason) 95 96 #缓存问题 97 # status = 1,用例通过,则缓存状态,缓存存在时 98 if status ==1: 99 cache_filed = case_obj.cache_field 100 if cache_filed: 101 res_cache_value = ResponseCheck.get_response_value(cache_filed,response) 102 logger.debug('从返回值中换取的缓存字段-->%s'%res_cache_value) 103 self.redis.set(const.cache_prefix +cache_filed,res_cache_value,const.token_expire)#请求redis,写入缓存
3、tasks.py运行:
1 @app.task(name='run_case') 2 def run_case(case_id,user_id): 3 task_id = run_case.request.id 4 logger.debug('task_id-->%s'%task_id) 5 run = Run() 6 logger.debug('go') 7 all_case= run.set_premise_case([case_id]) 8 time.sleep(10) 9 logger.debug('所有要运行的用例-->%s'%all_case) 10 for case_id in all_case: 11 run.simple_run(case_id)
4、单个用例执行(没有依赖关系)可以运行的用例,效果如图:

tasks.py--优化代码, class_Run()新增方法将缓存单独一个函数set_cache方法
1 def set_cache(self, cache, response): 2 caches = cache.split(',')#多个缓存字段用英文逗号分割 3 for item in caches: 4 item = item.replace(' ', '')#万一有空格,用replace方法替换成空 5 res_cache_value = ResponseCheck.get_response_value(item, response)#从返回值中获取到缓存字段 6 logger.debug('从返回值中获取的缓存字段-->:%s' % res_cache_value) 7 self.redis.set(const.cache_prefix + item, res_cache_value, const.token_expire)#将缓存写入redis
tasks.py--run_case调用缓存函数使用:
1 # 如果用例结果为1 代表用例通过则缓存字段 2 if status == 1: 3 cache_field = case_obj.cache_field 4 if cache_field: 5 self.set_cache(cache_field, response)
六、报告
1、tasks.py--class Run()中simple_run中新增以下内容
备注:方法中新增传参字段
1 def simple_run(self, case_id, task_id, user_id, collection_id=None):
1 # 创建报告的数据结构 2 create_data = { 3 'response': str(response),#待解释,为什么不用json.loads() 4 'case': case_obj, 5 'batch': task_id, 6 'status': status, 7 'duration': 100, 8 'user': models.User.objects.get(id=user_id), 9 'case_collection': models.CaseCollection.objects.get(id=collection_id) if collection_id else None,#如果集合存在执行,否则为空 10 'reason': reason, 11 'params': json.dumps(data), 12 'url': host + uri, 13 'title': case_obj.title, 14 'project': case_obj.project, 15 } 16 models.Report.objects.create(**create_data)#创建 17 if collection_id:#集合运行 18 models.CaseCollection.objects.filter(id=collection_id).update(status=status)#等于当前的用例状态 19 else:#用例运行 20 models.Case.objects.filter(id=case_id).update(status=status)
集合运行:
1 # 集合运行 2 @app.task(name='run_collection') 3 def run_collection(collect_id, user_id): 4 task_id = run_collection.request.id 5 # 根据集合id 需要查找到集合下的所有用例id 6 collection_obj = models.CaseCollection.objects.get(id=collect_id) 7 qs = collection_obj.case.all() 8 case_ids = [] 9 for item in qs: 10 case_ids.append(item.id) # 将集合下的用例 添加到列表中。 11 # logger.debug('item-->%s'%item.id) # 13 12 logger.debug('当前集合下真实的用例-->%s' % case_ids) 13 # 以集合下的用例为基础,获取所有要运行的用例,也就是依赖用例 14 run = Run() 15 all_case = run.set_premise_case(case_ids) 16 for case_id in all_case: 17 run.simple_run(case_id,task_id,user_id,collect_id) 18 19 tmp_case = [] 20 for case_id in case_ids: 21 all_case = run.loop_premise(case_id) 22 tmp_case += all_case 23 logger.debug("tmp_case-->%s"%tmp_case)
七、用例运行,集合运行,报告接口
1 运行用例 2 class CaseRunView(View): 3 def post(self, request): 4 case_id = request.POST.get('case_id')#用例id 5 user_id = request.POST.get('user_id')#用户id 6 7 for item_id in json.loads(case_id): 8 # 当页面调用异步任务时,会返回一个唯一的任务id 9 #delay()将程序的执行暂停一段时间(毫秒) 10 task_id = run_case.delay(item_id, request.user.id)#调用tasks 11 print('当前用例的task_id',task_id) 12 #点击用例运行后,用例的状态应显示运行中 13 models.Case.objects.filter(id=item_id).update(report_batch=task_id, status=3)#修改用例状态,3是运行中的状态 14 return NbResponse()
1 #运行集合 2 class CollectionRunView(View): 3 def post(self, request): 4 collect_id = request.POST.get('collect_id')#集合id 5 user_id = request.POST.get('user_id') 6 for item_id in json.loads(collect_id): 7 # 当页面调用异步任务时,会返回一个唯一的任务id 8 task_id = run_collection.delay(item_id, request.user.id) 9 print('集合的task_id',task_id) 10 models.CaseCollection.objects.filter(id=item_id).update(report_batch=task_id, status=3)#修改用例状态,3是运行中的状态 11 return NbResponse()
1 class CaseReportView(View): 2 # 用例报告中没有header字段,从report的数据表开始改起。--毕业作业 3 def get(self, request): 4 case_id = request.GET.get('id') 5 report_batch = request.GET.get('report_batch') 6 case = models.Case.objects.get(id=case_id) 7 report = models.Report.objects.filter(batch=report_batch, case_id=case.id).first() 8 if report: 9 data = { 10 'title': case.title, 11 'run_time': report.create_time, 12 'project_name': case.project.name, 13 'status': report.status, 14 'case_collection': report.case_collection if report.case_collection else '单用例运行', 15 'duration': report.duration, 16 'run_user': report.user.username, 17 'url': report.url, 18 'method': case.get_method_display(),#请求方式返回 19 'check': case.check, 20 'reason': report.reason, 21 'params': report.params, 22 'response': report.response 23 } 24 return NbResponse(data=data) 25 else: 26 return NbResponse(-1, msg='用例运行中,请耐心等待..')
1 class CollectionReport(View): 2 def get(self, request): 3 case_collection_id = request.GET.get('id') 4 report_batch = request.GET.get('report_batch') 5 case_collection = models.CaseCollection.objects.get(id=case_collection_id) 6 report = models.Report.objects.filter(batch=report_batch, case_collection=case_collection.id).first() 7 fail_count = models.Report.objects.filter(batch=report_batch, case_collection=case_collection.id, 8 status=999).count() 9 pass_count = models.Report.objects.filter(batch=report_batch, case_collection=case_collection.id, 10 status=1).count() 11 if report: 12 data = { 13 'case_collection': case_collection.name, 14 'run_time': report.create_time, 15 'case_count': case_collection.case.all().count(), 16 'pass_count': pass_count, 17 'run_user': report.user.username, 18 'fail_count': fail_count, 19 'duration': 100, 20 'report_batch': case_collection.report_batch, 21 } 22 return NbResponse(data=data) 23 else: 24 return NbResponse(-1, msg='用例集合运行中,请耐心等待..')
1 class ReportView(BaseView): 2 search_field = ['title'] 3 filter_field = ['project', 'case_collection', 'batch'] 4 model_class = models.Report 5 exclude_fields = ['is_delete'] 6 7 def get(self, request): 8 page_data, page_obj = self.get_query_set_page_data() # 获取分页之后的数据 9 data_list = [] 10 for instance in page_data: # 11 model_dict = model_to_dict(instance, self.fields, self.exclude_fields) # 转成字典 12 model_dict['title'] = instance.case.title 13 model_dict['project_name'] = instance.case.project.name 14 model_dict['case_collection'] = instance.case_collection.name if instance.case_collection else '单用例运行' 15 model_dict['status'] = instance.case.status 16 model_dict['run_user'] = instance.user.username 17 model_dict['run_time'] = instance.create_time 18 model_dict['check'] = instance.case.check 19 model_dict['method'] = instance.case.get_method_display() 20 data_list.append(model_dict) 21 return NbResponse(data=data_list, count=page_obj.count)
urls.py中新增接口路径:
1 path('collection_report', views.CollectionReport.as_view()), 2 path('run', views.CaseRunView.as_view()), 3 path('run_collection', views.CollectionRunView.as_view()),
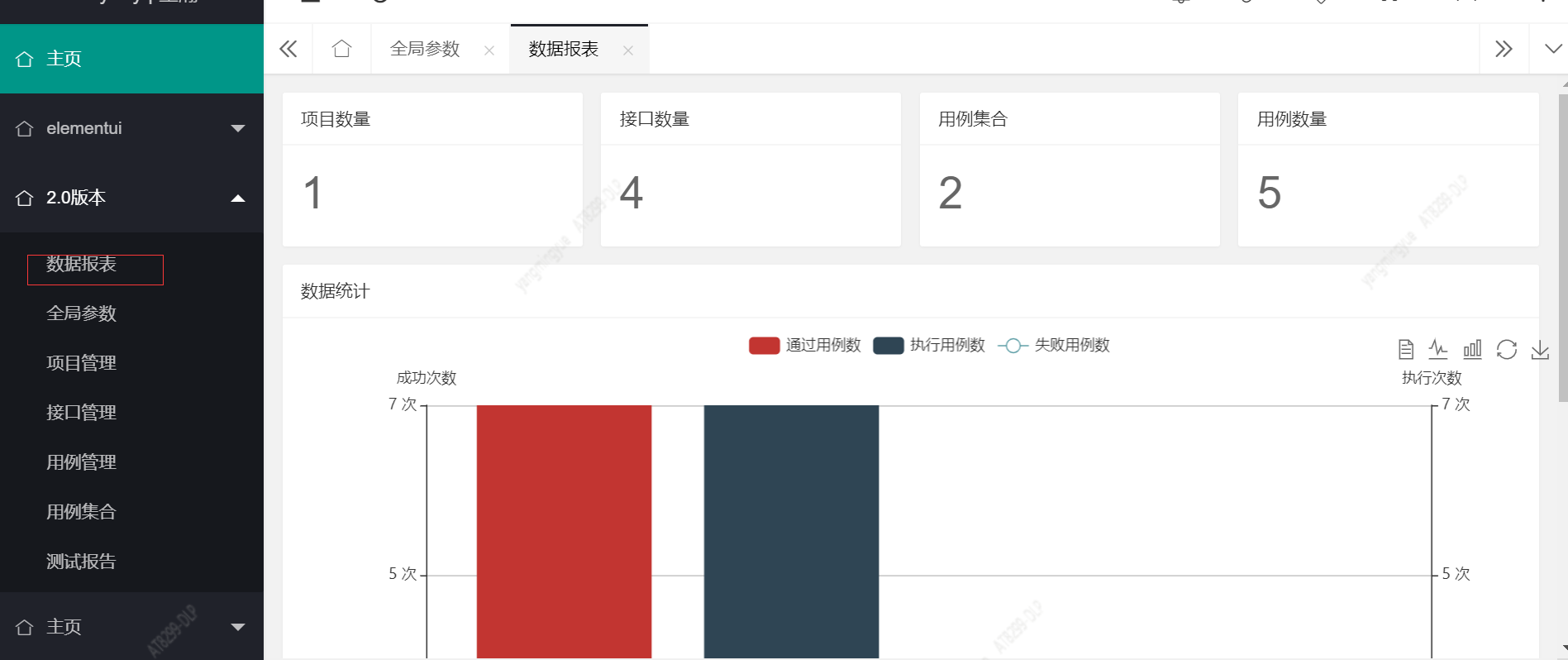
八、数据报表功能
1、models.py中数据库新增数据库创建内容:
1 class HomeData(BaseModel): 2 date = models.DateField(verbose_name='统计时间', unique=True) 3 pass_count = models.IntegerField(verbose_name='成功次数', default=0) 4 all_count = models.IntegerField(verbose_name='执行次数', default=0) 5 fail_count = models.IntegerField(verbose_name='失败次数', default=0) 6 7 class Meta: 8 verbose_name = '首页数据统计' 9 verbose_name_plural = verbose_name 10 db_table = 'home_data' 11 ordering = ['-id']
2、views.py中实现接口
1 class HomePageView(View): 2 def get_source_data(self, day): 3 pass_count = models.Report.objects.filter(create_time__contains=day, status=1).count() 4 fail_count = models.Report.objects.filter(create_time__contains=day, status=999).count() 5 all_count = models.Report.objects.filter(create_time__contains=day).count() 6 data = { 7 "pass_count": pass_count, 8 "fail_count": fail_count, 9 "all_count": all_count 10 } 11 return data 12 13 def get(self, request): 14 import datetime 15 today = datetime.date.today() 16 # 统计数据 当天数据 17 data = self.get_source_data(today) 18 if models.HomeData.objects.filter(date=today).first(): 19 models.HomeData.objects.filter(date=today).update(**data) 20 else: 21 data.update({"date": today}) 22 models.HomeData.objects.create(**data) 23 # 昨天数据 24 25 yesterday = today - datetime.timedelta(days=1) 26 data = self.get_source_data(yesterday) 27 if models.HomeData.objects.filter(date=yesterday).first(): 28 models.HomeData.objects.filter(date=yesterday).update(**data) 29 else: 30 data.update({"date": yesterday}) 31 models.HomeData.objects.create(**data) 32 33 # 最大执行次数和最大成功次数,用于确认页面的y轴数据 34 max_all_count = models.Report.objects.all().count() 35 max_pass_count = models.Report.objects.filter(status=1).count() 36 37 project_count = models.Project.objects.filter(is_delete=1).count() 38 interface_count = models.Interface.objects.filter(is_delete=1).count() 39 collection_count = models.CaseCollection.objects.filter(is_delete=1).count() 40 case_count = models.Case.objects.filter(is_delete=1).count() 41 home_data = models.HomeData.objects.all().values() 42 43 pass_count = qs_to_list(home_data, 'pass_count') 44 date = qs_to_list(home_data, 'date') 45 all_count = qs_to_list(home_data, 'all_count') 46 fail_count = qs_to_list(home_data, 'fail_count') 47 data = { 48 'project_count': project_count, 49 'interface_count': interface_count, 50 'collection_count': collection_count, 51 'case_count': case_count, 52 'pass_count': pass_count, 53 'date': date, 54 'all_count': all_count, 55 'fail_count': fail_count, 56 'max_all_count': max_all_count, 57 'max_pass_count': max_pass_count 58 } 59 return NbResponse(data=data)
3、urls.py中新增接口路径
1 path('home_page', views.HomePageView.as_view()),
4、效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号