知识点一、list[]
1 s= 'xiaoming,suhong,zhuhongcai'#字符串,取值不好取
1 l = ['xiaoming','suhong','zhuhongcai']#列表取元素是按照编号取(索引,角标,下表)
2 # 0 1 2
3 l4 = [1,2,3,4,['a','b','c']#二维数组
4 l4[4][2] 取值结果是c
5
6 l5 = [1,2,3,4,['a','b','c',['abc','124','vbf']]#三维数组
7
8 print(l[-1])#-1 代表最后一个元素
9 print(l[0]) #0 代表第一个元素
-
#2.1 append增加元素(在末尾增加一个元素)
1 l.append('洛歆')
2 print(l[3])
-
#2.2 insert指定位置增加,如果添加的指定位置没有,会添加到末尾
1 l.insert(0,'毅熊')
2 print(l[0])
3
4 l.insert(7,'允非')
5 print(l)
l[2] = 'mingyue'
print(l)
1 l.pop(0)
2 print(l)
3
4 l.pop(5)
5 print(l)
1 l.remove('xiaoming')
2 print(l)
1 print(l.count('xiaoming'))
1 index = l.index('xiaoming')
2 print(index)
1 l2 = [54,6,14,9,23,56,78]
2 l2.sort()#默认升序
3 print(l2)
4 l2 = [54,6,14,9,23,56,78]
5 l2.sort(reverse=True) #降序
6 print(l2)
注意:
1 l2 = [54,6,14,9,23,56,78]
2 l3 = l2.sort(reverse=True) #sort只是针对l2 排序,不能赋值
3 print('l3...',l3)
结果:
![]()
1 l.clear()
2 print('l是:',l)
1 l3 = l +l2
2 print('l3是:',l3)#直接 + 就是将两个list合并
3 l.extend(l2)#将l2的元素加入到l中
4 print('l是:',l)
1 students = ['小明','小红','小白']
2 #python 实现
3 for stu in students:
4 print(stu)#直接循环取到list中每个元素
#其他语言实现方式
1 for i in range(len(students)):
2 print(students[i])
1 #判断元素存在在list中
2 if '小明' in students: #in 判断是否存在不光可以用list,还可以用在字符串中
3 print("在")
4 #判断元素不存在在list中
5 if '小光' not in students:
6 print("不在")
知识点二、字典
-
#字典 key - value key是唯一的不能重复,取值速度非常快
1 d = {'name':'xiaohong',
2 'sex':'女',
3 'adder':'北京',
4 '手机号码':'13323457896'
5 }
print(d['name'])
print(d.get('手机号码'))
#当取字典中不存在的值时
print(d['money'])#报错
print(d.get('money',0))#get('money')返回None;get('money',0)返回0,0可以设置其他内容
d['money'] = 500
d.setdefault('car','bmw')
print(d)
#增加一个已经存在的key
d['name'] = 'xiaohon'#修改key的值
print('方法一',d)
d.setdefault('sex','你那')#key的值不变
print('方法二',d)
1 d['sex'] = 400#key存在修改,key不存在时新增
1 result = d.pop('sex')#会返回删除的值
2 print(result)
3
4 del d['name']#直接删除不会告诉删除的结果
5 print(d)
1 d = {
2 "name":"小黑",
3 "grade":"天蝎座",
4 "phone":18612532946,
5 "sex":"男",
6 "age":28,
7 "addr":"河南省济源市北海大道32号"
8 }
1 for i in d:
2 print(d[i])
1 for i in d:
2 print(i,d[i])
1 for k in d:
2 value = d.get(k)
-
# 取字典中的key和value,效率没有上一个高
1 for key,value in d.items():
2 print(key,value)
3 print(d.items())#将字典转成二维数组,所以效率没那么高
结果:dict_items([('name', '小黑'), ('grade', '天蝎座'), ('phone', 18612532946), ('sex', '男'), ('age', 28), ('addr', '河南省济源市北海大道32号')])
if 'id' in d:#如果字典用in来判断,判断的是key是否存在,效率高
if 'id' in d.keys():#判断字典中key 是否存在,效率不高
1 #1、输入账号和密码,确认密码注册
2 #2、如果账号不存在的话,可以注册
3 #3、两次密码输入一致可以注册
4 stu1 = [{'username':'xiaohong','password':'12345'},{'username':'xiaohuang','password':'12345'}]#方式一
5 stu2 = {'xiaohong':'123456','小黄':'345678'}#方式二
6
7 for i in range(3):
8 username = input('请输入账号')
9 pwd = input("请输入密码")
10 cpwd = input('请再次输入密码')
11 if username == '' or pwd == '' or cpwd == '':
12 print('输入内容不能为空')
13 elif username in stu2:
14 print('用户已注册')
15 elif pwd != cpwd:
16 print('两次输入密码不一致')
17 else:
18 #stu2[username] = pwd
19 stu2.setdefault(username,pwd )
20 print('注册成功')
1 #登录从字典中取值
2 #1、写一个登陆的程序,最多登陆失败3次
3 #2、输入账号 密码,如果登录成功,程序结束,提示 欢迎 xx 登录,
4 #3、登录失败,重新登陆
5 #3、要判断输入是否为空
6 stu1 = [{'username': 'xiaohong', 'password': '12345'}, {'username': 'xiaohuang', 'password': '12345'}] # 方式一
7 stu2 = {'xiaohong': '123456', '小黄': '345678'} # 方式二
8
9 for i in range(3):
10 username = input('请输入账号')
11 pwd = input("请输入密码")
12 if username == '' or pwd == '':
13 print('输入内容不能为空')
14 elif username not in stu2:
15 print('用户不存在,请注册')
16 else:
17 if pwd == stu2[username]:
18 print('欢迎%s登录' %username)
19 break
20 else:
21 print('密码不正确')
22 else:
23 print('最多输入3次')
知识点三、切片
1 print(l[0:3])#取前3个元素,顾头不顾尾,取下标 0,1,2
2 print(l[:3])#也是取前3个元素
3 print(l[2:])#取下标2之后的数据
4 print(l[:])#全部取值
1 s = 'abvds'
2 print(s[2:5])#vds
3
4 l2 = l[0:7:2]#步长
5 print('步长为2:',l2)#步长不写默认为1,写2步长为2结果是: [1, 3, 6]
6
7 l3 = l[::-1]#步长-1,从后往前取:[7, 6, 5, 3, 2, 1]
8 l3 = l[-1:-5:-1] #步长-1,前面也要是负数[7, 6, 5, 3]
9 print(l3)
知识点四、元组
1 l= (1,2,3,4,5)#元组里的元素不可以修改
2 print(l[0])#取值
3 print(l[::2])#切片取值
4 #字符串和元组的值都不能修改,会报错
5 l[0] = 3
6 print(l)
7
8 s= 'abc'
9 s[0] = 'A'
10 print(s)
#python 的数据类型可以分成可变数据类型和不可变数据类型
#可变数据类型:list ,字典,
#不可变数据类型 元组,字符串,flout, int,不可变数据类型存在的原因是为了数据安全,比如密码
1 s = (1,)#元组只有一个元素时不认为是元组,需要加逗号
2 print(type(s))#<class 'tuple'>
3 ss= 'abc'
4 print('upper',ss.upper())#upper()方法是将字符串内容变成大写赋给一个变量,字符串本身的内容没有变化
5 print(ss)
1 l = [1,1,2,3,4,5,7,8,9]
2 for i in l:
3
4 if i%2 != 0:
5 l.remove(i)
6 print(l)
#结果:[1, 2, 4, 7, 8]
#第一次循环 不要循环删除list,会导致下标错乱,解决办法创建两个list,内容一致,l2循环,删除l的元素
1 l = [1,1,2,3,4,5,7,8,9]
2 l2 = [1,1,2,3,4,5,7,8,9]
3 for i in l2:
4 if i%2 != 0:
5 l.remove(i)
6 print(l)
#结果:[2, 4, 8]
知识点五、深拷贝浅拷贝
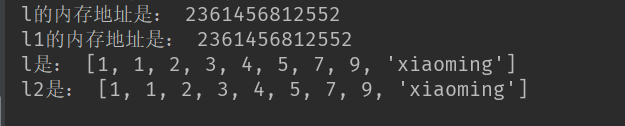
l = [1,1,2,3,4,5,7,8,9]
l2 = l
print('l的内存地址是:',id(l))
print('l1的内存地址是:',id(l2))
l.append('xiaoming')
l2.remove(8)
print('l是:',l)
print('l2是:',l2)
![]()
-
#浅拷贝 内存地址一致,改变一个list 的元素,另外的list也受到影响
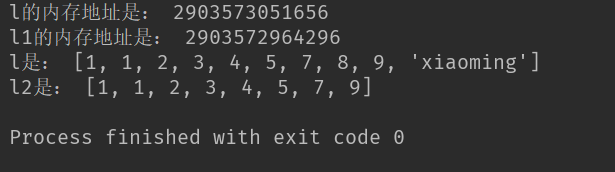
1 import copy
2 print('l1的内存地址是:',id(l2))
3 l.append('xiaoming')
4 l2.remove(8)
5 print('l是:',l)
6 print('l2是:',l2
7 l = [1,1,2,3,4,5,7,8,9]
8 l2 = copy.deepcopy(l)
9 print('l的内存地址是:',id(l)))
![]()
-
#内存地址不变一定是浅拷贝,内存地址改变也可能是浅拷贝,只有copy.deepcopy()是深拷贝,其他都是浅拷贝
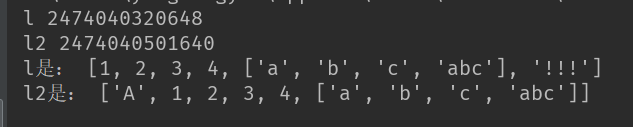
1 l = [1,2,3,4,['a','b','c']]
2 #l2 = copy.deepcopy(l)#深拷贝
3 l2 = l.copy()#浅拷贝
4 print('l',id(l))
5 print('l2',id(l2))
6 l[-1].append('abc')
7 l2.insert(0,'A')
8 l.append('!!!')
9 print('l是:',l)
10 print('l2是:',l2)
![]()
1 import copy
2 l = [1,2,3,4,['a','b','c']]
3 l2 = copy.deepcopy(l)#深拷贝
4 #l2 = l.copy()#浅拷贝
5 l2 = l[:]#切片方式也是浅拷贝
6 l2 = copy.copy(l)#浅拷贝
7 print('l',id(l))
8 print('l2',id(l2))
9 l[-1].append('abc')
10 l2.insert(0,'A')
11 l.append('!!!')
12 print('l是:',l)
13 print('l2是:',l2)
知识点六、字符串常用方法
1 s= 'abc'
2 s.strip()
3 s.lstrip()
4 s.rsplit()
5 s.lower()
6 s.upper()
7 s.count()
8 s.index()#找下标,找不到的元素会报错
9 s.find()#找下标,找不到的元素会返回-1
10 name = '小黑'
11 a = '你的名字是{}'.format(name)
12 print(a)
13 s = '你的名字是{name}'
14 print(s.format_map({'name':"小白"}))
15
16 s.isupper()#判断是不是大写字母
17 s.islower()#判断是不是小写字母
18 s.isdigit()#判断返回是不是数字
19
20 s.endswith()#判断是以什么结尾
21 s.startswith()#判断是以什么开头
22 s.isalpha()#如果是字母和汉字返回True,
23 s.isalnum()#如果是字母,汉字和数字返回True,只要不包含特殊字符都返回True
24 s.isspace()#判断是不是空格
25 s.istitle()#判断是否是标题,判断的标准是:判断英文开头是不是大写
26 s.capitalize()#把首字母变成大写
27 s.title()#把所有的英文单词第一个字母变成大写
28 s.center()#把字符串居中
1 s = '欢迎登录'
2 print(s.center(50,'*'))
3 #结果是
4 ***********************欢迎登录***********************
5
6 s= '5'
7 print(s.zfill(3))#填充
#结果
005
1 s = 'abcaas'
2 ss = s.replace('a','A',2)#替换
3 print('ss',ss)
4 print('s',s)
结果是:
ss AbcAas
s abcaas
1 s = 'suhong,xiaoming,chouhong,suhong'
2 #按照指定元素字符串分割
3 result = s.split(',')#不能传空字符串,会报错
4 print(result)
结果:['suhong', 'xiaoming', 'chouhong', 'suhong']
1 import pprint
2 l = ['a','b','c']#想要abc
3 pprint.pprint(str(l))#结果:"['a', 'b', 'c']"
4 #join 用规定的字符连接字符串
5 pprint.pprint(''.join(l))#结果:'abc'
6 pprint.pprint(','.join(l))#结果:'a,b,c'
7 s = 'hhaaahh'
8 pprint.pprint('-'.join(s))#结果:'h-h-a-a-a-h-h'
9 t = ('a','b','c')
10 pprint.pprint('-'.join(t))#'a-b-c'
11
12 d = {'name':'xiaoming','sex':'n'}
13 pprint.pprint('-'.join(d))#结果:'name-sex'
14
15 l3 = [1,2,3,4]
16 pprint.pprint('-'.join(l3))#报错,连接需要时字符串,不能是int,不能嵌套
1 l = [1,2,3,4,5]
2 #方法一
3 l2 = [ str(i) for i in l ] #这一行代码和下面2行是一样的
4 #方法二
5 l2 = []
6 for i in l:
7 l2.append(str(i))
8
9 #方法一
10 l3 = [ i for i in range(10) if i%2==0 ]#这一行代码和下面4行效果是一样的
11 #方法二
12 l3=[]
13 for i in range(10):
14 if i%2==0:
15 l3.append(i)
16
17 print(l3)
知识点七、文件操作
1 f = open('a.txt',encoding='utf-8')#打开文件
2 result = f.read()#读文件
3 print(result)
4 f.close()#关闭文件
1 f= open('a.txt','w',encoding='utf-8')
2 f.write('hello'+'\n')#写的时候会清空原来的文件
3 f.write('wangruiji'+'\n')#\n 换行符
4 f.close()
注意:f = open(r'c:\users\niuhanyang\a.txt')#加r不会被转译成\n,或者用\\替代\
1 f = open('a.txt','w',encoding='utf-8')
2 l = ['abc','123','abc1']
3 for i in l:
4 f.write(i+'\n')
5 f.close()
知识点八、集合
1 s = {1,2,3,1,2,3}#有元素的集合
2 s2 = set() #空集合
3
4 l = [1,2,2,3,4,5,4]
5 print(set(l))#set(l)将list转换成集合,结果会去重
6 print(s)
1 a = {1,2,3}
2 b = {3,4,5}
3
4 print(a & b) #取交集
5 print(a.intersection(b)) #取交集
6
7 print(a.union(b)) #并集,把两个集合合并到一起,然后取掉重复的
8 print(a|b)#并集
9
10 print( a - b ) #差集,在a集合里面存在,但是在b集合里面没有的
11 print( a.difference(b))#差集
12 a.add('123')#增加,
13 a.remove('232')#删除


 浙公网安备 33010602011771号
浙公网安备 33010602011771号