kafka基础配置+kafka与java结合
1. 配置虚拟机
1.1 IP和主机名称配置
1.1.1 vm配置
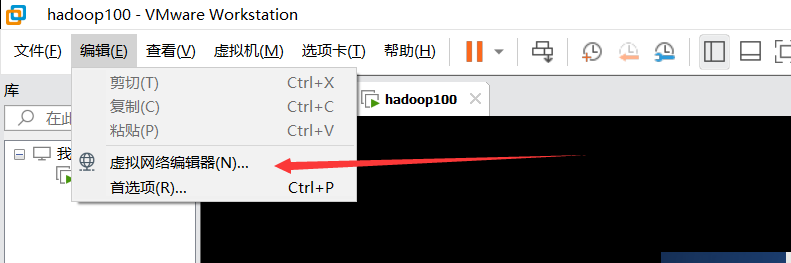
打开后,右下角,管理员权限修改,然后vm8,子网IP随意,(1,2,3,4,5...)
NAT设置,将网关IP与子网IP一致,192.168.10.2
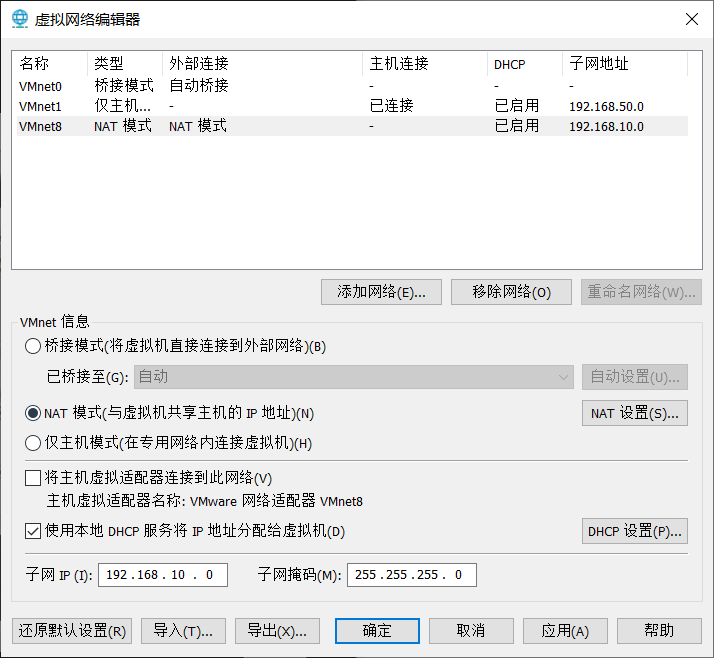
1.1.2 win配置
如果没有vm8,将上面的还原默认设置

1.1.3 centos配置
如果是安装的最小安装系统
-
首先要安装net-tool:工具包合集,包含ifconfig等命令
yum install -y net-tools
-
vim:编辑器
yum install -y vim
-
切换到root用户
su root -
修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33 #注意文件名字,建议cd打开到当前目录,然后ll命令,查看文件名字,我的不是ens33改动态获取ip为静态ip
BOOTPROTO = "static" #文件末尾加 IPADDR = 192.168.10.100 #网关 GATEWAY = 192.168.10.2 #域名解析器 DNS1 = 192.168.10.2按ESC,输入wq保存退出
-
修改主机名称
vim /etc/hostname修改为hadoop100
-
主机名称映射
vim /etc/hosts文档末尾添加
192.168.10.100 hadoop100 192.168.10.101 hadoop101 192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104 192.168.10.105 hadoop105 192.168.10.106 hadoop106 192.168.10.107 hadoop107 -
reboot重启
-
测试
#查看ip地址是否正确 ifconfig #查看网络是否可用 ping www.baidu.com #查看主机名称 hostname
1.2 xshell远程访问
新建连接即可,略过
1.2.1修改主机映射
C:\Windows\System32\drivers\etc\hosts
在文件末尾加上
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
建立连接时可以直接
1.3 模板虚拟机搭建
1.3.1 安装epel-release
yum install -y epel-release
1.3.2 创建文件夹,并修改所属组
-
/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module [root@hadoop100 ~]# mkdir /opt/software -
修改两个文件夹的所有者和所属组
[root@hadoop100 opt]# chown luomuchen:luomuchen /opt/module [root@hadoop100 opt]# chown luomuchen:luomuchen /opt/software
2. 开始配置kafka
2.1 安装前准备
-
需要zookeeper包,java1.8包,以及kafka包
-
虚拟机安装lrzsz这样可以省略ftp相关的一些指令
yum install -y lrzsz -
输入rz可以将安装包传入虚拟机中

-
解压安装包
[root@hadoop100 software]# tar -zxvf jdk-8u333-linux-x64.tar.gz -C /opt/module [root@hadoop100 software]# tar -zxvf kafka_2.12-3.2.0.tgz -C /opt/module [root@hadoop100 software]# tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module -
配置JDK的环境变量
vim /etc/profile在这个文件最后,配置JAVA_HOME
## JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_333 ## PATH export PATH=$PATH:$JAVA_HOME/bin重启资源
[root@hadoop100 etc]# source /etc/profile然后查看是否配置成功(java -version)
-
配置zookeeper
在conf目录下,修改 zoo_sample.cfg名字为 zoo.cfg
mv zoo_sample.cfg zoo.cfg配置zoo.cfg
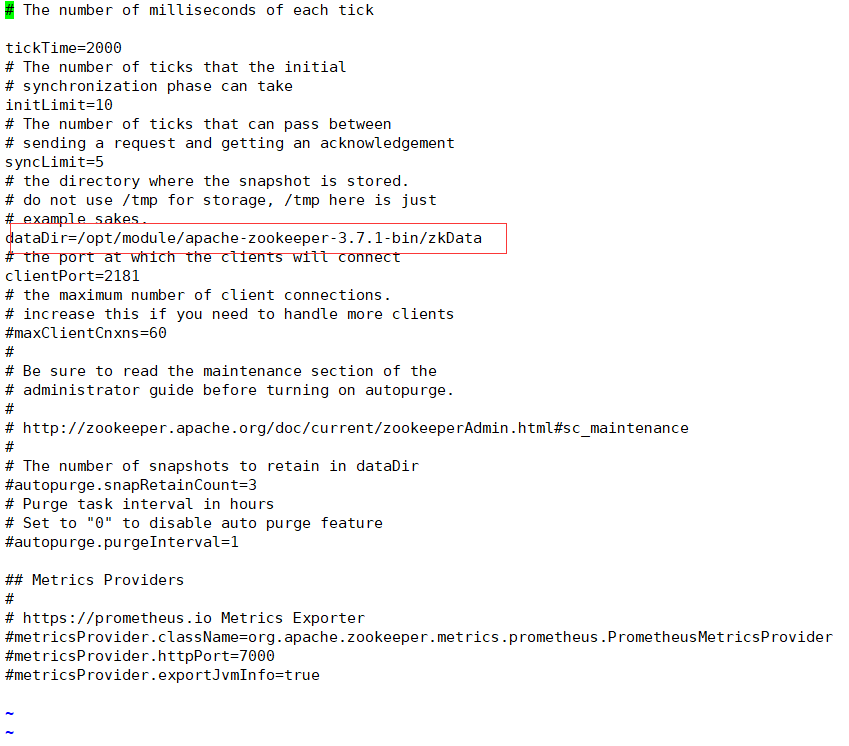
-
zookeeper相关指令
[root@hadoop100 apache-zookeeper-3.7.1-bin]# bin/zkServer.sh start [root@hadoop100 apache-zookeeper-3.7.1-bin]# bin/zkServer.sh stop
2.2 开始配置kafka
-
config目录下,修改server.properties
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以 配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/opt/module/kafka/datas #配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理) #zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka #由于我只有一台,所以改为这样就可 zookeeper.connect=localhost:2181/kafka -
配置环境变量,同java
## KAFKA_HOME export KAFKA_HOME=/opt/module/kafka_2.12-3.2.0 export PATH=$PATH:$KAFKA_HOME/bin
2.3 启动kafka
先启动zookeeper,然后启动kafka
[root@hadoop100 apache-zookeeper-3.7.1-bin]# bin/zkServer.sh start
[root@hadoop100 kafka_2.12-3.2.0]# bin/kafka-server-start.sh -daemon config/server.properties
/opt/module/apache-zookeeper-3.7.1-bin/bin/zkServer.sh start
/opt/module/kafka_2.12-3.2.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.2.0/config/server.properties
3. 开始使用kafka
3.1 生产者
-
kafka操作主题(topic)的命令参数
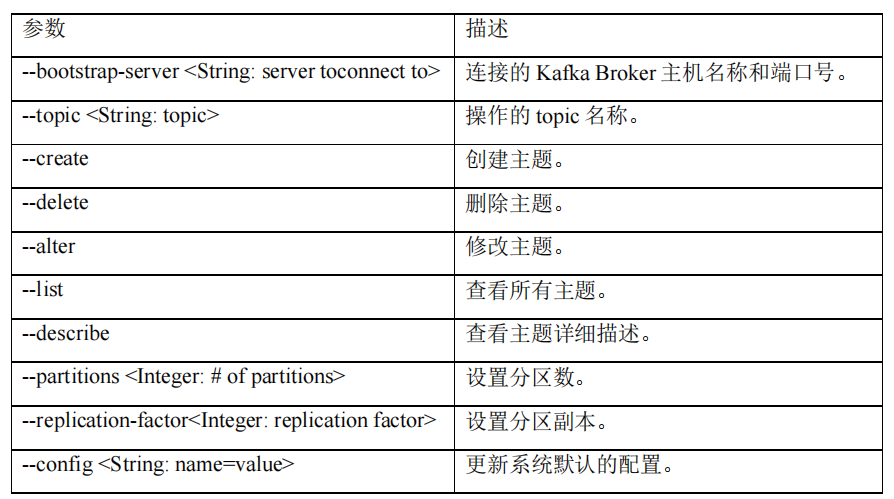
-
查看所有topic列表
[luomuchen@hadoop100 kafka_2.12-3.2.0]$ bin/kafka-topics.sh --bootstrap-server hadoop100:9092 --list -
创建topic first
由于只有一台虚拟机,所以就省略了设置分区数和设置分区副本
[luomuchen@hadoop100 kafka_2.12-3.2.0]$ bin/kafka-topics.sh --bootstrap-server hadoop100:9092 --create --topic first -
查看 first 主题的详情
[luomuchen@hadoop100 kafka_2.12-3.2.0]$ bin/kafka-topics.sh --bootstrap-server hadoop100:9092 --describe --topic first -
修改分区数(注意:分区数只能增加,不能减少)
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3 -
再次查看 first 主题的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
3.2 生产者命令行操作
-
生产者命令参数

-
发送消息
[luomuchen@hadoop100 kafka_2.12-3.2.0]$ bin/kafka-console-producer.sh --bootstrap-server hadoop100:9092 --topic first >hellow^H ^H^H^H^H^H^H^H^H^H^H >jhe^H^H^H >je >helloworld >luop^Hmuchen #alt+z停止 ^H是回退标志
3.3 消费者命令行操作
-
查看操作消费者命令参数


-
消费消息
-
消费 first 主题中的数据。
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first #一台主机暂时无法测试这个 -
把主题中所有的数据都读取出来(包括历史数据)。
[luomuchen@hadoop100 kafka_2.12-3.2.0]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop100:9092 --from-beginning --topic first jhelo je helloworld luomuchen
-
4. kafka和java结合
注:项目采用了springboot框架,因此结合会简单一些。
注意关闭防火墙,注意关闭防火墙,注意关闭防火墙!!!
- yml配置文件
spring: kafka: #kafka集群 bootstrap-servers: hadoop100:9092 producer: value-serializer: org.apache.kafka.common.serialization.StringSerializer key-serializer: org.apache.kafka.common.serialization.StringSerializer consumer: key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer group-id: 1 - pom.xml引入kafka的包
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.6.0</version> </dependency> - kafka生产
使用kakfa包中自带的KafkaTemplate类来进行kakfa的写入,也就是kafka的生产者@Service("kafkaService") public class KafkaServiceImpl implements KafkaService { @Autowired private KafkaTemplate<String, String> kafkaTemplate; @Override public void kafkaSend(String topic, String msg) { kafkaTemplate.send(topic, msg); } } - kafka消费
使用@KafkaListener(topics = "") 注解,可以写入一个或多个topic进行消费@KafkaListener(topics = "goodMsg") public void goodMsgTopic(String msg){ log.info("接收到一条不含敏感词的短信:" + msg); }@Order(1) @Service @Slf4j public class KafkaConsumers extends ServiceImpl<TopicMapper, Topic> implements InitializingBean { private static KafkaConsumer<String, String> consumer; private List<String> topicList; @Autowired private WordService wordService; @Autowired private KafkaService kafkaService; private GfaUtil gfaUtil = new GfaUtil(); @Value("${spring.kafka.bootstrap-servers}") private String bootstrapServers; @Value("${spring.kafka.consumer.group-id}") private String groupId; @Value("${spring.kafka.consumer.key-deserializer}") private String keyDeserializer; @Value("${spring.kafka.consumer.value-deserializer}") private String valueDeserializer; @Autowired private static TopicService topicService; public List<String> getTopicList(){ try { List<String> list = new ArrayList<>(); List<Topic> list2 = baseMapper.selectList(null); for (Topic topic : list2) { list.add(topic.getTopicValue()); } return list; } catch (Exception e){ log.error(e.toString()); } return null; } public KafkaConsumer<String, String> getInitConsumer(List<String> topicList) { //配置信息 Properties props = new Properties(); //kafka服务器地址 props.put("bootstrap.servers", bootstrapServers); //必须指定消费者组 props.put("group.id", groupId); //设置数据key和value的序列化处理类 props.put("key.deserializer", keyDeserializer); props.put("value.deserializer", valueDeserializer); //创建消息者实例 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); //订阅topic的消息 consumer.subscribe(topicList); return consumer; } @Override public void afterPropertiesSet() throws Exception { topicList = getTopicList(); if (topicList != null && !topicList.isEmpty()) { consumer = getInitConsumer(topicList); // 开启一个消费者线程 new Thread(() -> { while (true) { ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> record : records) { String msg = (String) record.value(); if (record.topic().equals("input")){ //如果字典树未生成,需要先生成字典树 if(DictionaryConfig.DICTIONARY_MAP == null){ List<Word> wordList = wordService.getAllWord(); Set<String> wordSet = new HashSet<>(); for (Word word : wordList) { wordSet.add(word.getWord()); DictionaryConfig.WORD_MAP.put(word.getWord(), word.getId()); } DictionaryConfig.DICTIONARY_MAP = gfaUtil.setDictionary(wordSet); } if (!gfaUtil.check(msg, DictionaryConfig.DICTIONARY_MAP)){ //log.info(msg + "包含敏感词"); kafkaService.kafkaSend("badMsg", msg); } else{ kafkaService.kafkaSend("goodMsg", msg); } } else if(record.topic().equals("badMsg")){ log.info("接收到一条含有敏感词的短信:" + msg); } else{ log.info("接收到一条不含敏感词的短信:" + msg); } } } }).start(); } } }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构