决策树原理和算法API
决策树的原理
决策树的思想的来源非常朴素。在程序设计中的条件分支结构就是 if-then 结构。 最早的决策树就是利用这类结构分割数据的一种分类学习方法。
来看2个案列:
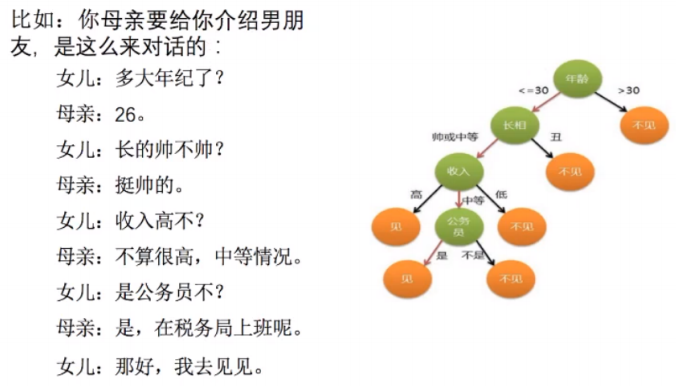
可以看到,如果男方的年龄如果大于30,那就直接over了。但是小于30,是吧,又继续往下。
长的怎么样,如果是一般或者不好看。那也就不见了。依次类推,这就是个简单的决策树。再来看另一个:
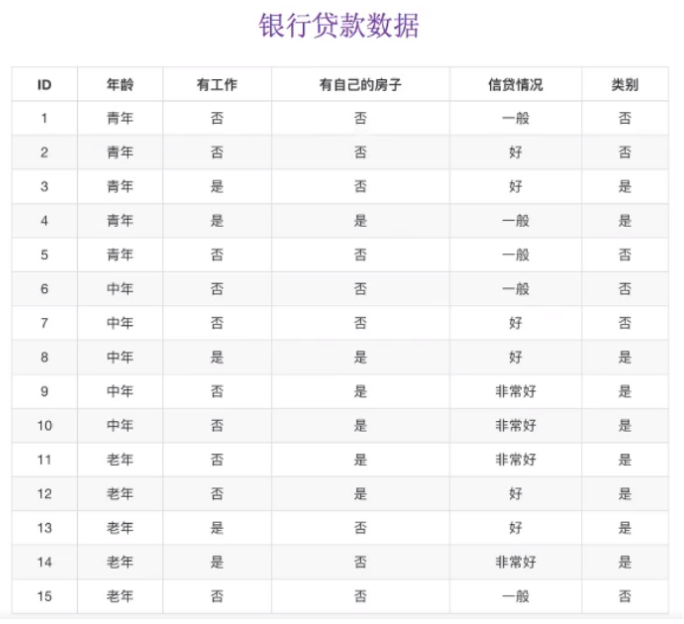
对于是否贷款,我们又会怎样做出决策依据呢?肯定是房子对不对,毕竟现在房价一直居高不下,是个硬通货。靠感觉,经验来做出决策依据。以银行贷款数据为例,年龄和工作又分为:
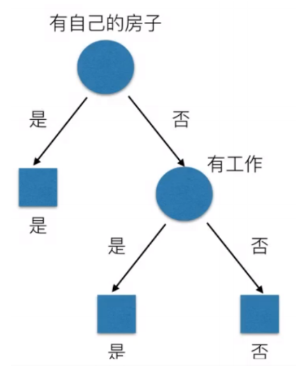
决策树的实际划分是这样的:
那么银行贷款到底是如何划分的。哪个是最主要的,最重要的?怎么得到最主要的。这就涉及到信息的度量和作用。
问题来了,假设有32支球队,我们怎么猜才能猜到谁是冠军?最少要猜几次才能知道结果?如何去猜?

其实,我们可以在 “一无所知” 的情况下,一半一半的猜。
首先我们可以猜:冠军在1-16之内吗? 如果它不在,那么它肯定在17-32之间。
接着猜,它在17-25之间吗?如果又不在,那么它就在26-32之间。依次类推,最终的到结果。
信息论 :
32支球队 ,log32 = 5比特
64支球队 ,log64 = 6比特
5比特,6比特,也就是在没有任何信息的情况下,最少猜到结果的次数。
信息论的创始人:克劳德·艾尔伍德·香农,非常NB的一个人!

信息熵 -- 对信息的度量
“谁才是世界杯的冠军”的信息量应该比 5比特 少,香农指出,它的准确信息量应该是这样算的:
H = -( p1㏒1 + p2㏒2 + p3㏒3 +...+ p32㏒32)
H 的专业术语称之为 : 信息熵,单位比特
公式:H(X)=∑x∈XP(x)㏒P(x)
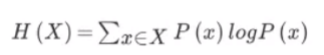
当这32支球队夺冠的几率相同时,对应的信息熵等于5比特
- 信息和消除不确定性是相联系的
- 信息熵越大不确定性越大,信息熵越小不确定性越小。我可以理解为信息熵越大就越难看出那个能夺冠,反而信息熵越小,我觉得有可能Ta就夺冠了。。。。。。zzzzz
决策树的划分依据之一 : 信息增益
特征A 对 训练集D的信息增益g(D,A) , 定义为 集合D 的信息熵H(D) 与 特征A 在给定条件下的信息条件熵H(D|A)之差,即公式为
g(D,A) = H(D) - H(D|A)
注:信息增益表示得知特征X的信息而使得类Y的信息不确定性减少程度。
信息增益的计算:
结合前面的贷款数据来看我们的公式:
信息熵的计算:
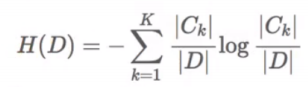
条件熵的计算: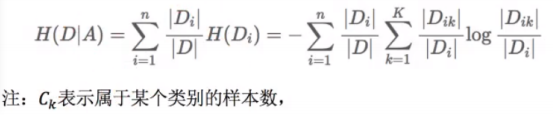
有了这两个公式,我们根据前面 是否通过贷款申请 的例子来 通过计算 得出我们的决策特征顺序,那么我们首先计算 总的信息熵为:
H(D) = - (9/15log(9/15)+6/15log(6/15)) = 0.971 # 9个通过贷款申请,6个未通过贷款申请
然后我们让A1 , A2 , A3 , A4分别表示年龄 ,有工作,有自己的房子和信贷情况4个特征,首先计算出年龄的信息增益为:

# 👆 2/5,3/5....为是否在本年龄阶段通过贷款申请的。👆#
同理其他的也可以计算出来:
g(D,A2) = 0.324 -- 有无工作
g(D,A3) = 0.420 -- 有无房子
g(D,A4) = 0.363 -- 信贷情况
相比较来说,其中特征A3(有自己的房子)的信息增益最大,所以我们选择特征A3为最优特征。也就是第一个决策条件为有房子,这个是计算出来的结果。
决策树的算法API及案例
常见决策树算法
- ID3 信息增益,最大的准则
- c4.5 信息增益比最大的准则
- Cart
- 回归树:平法误差,最小
- 分类树:基尼系数,最小的准则,在sklearn中可以选择划分的原则。
决策树API:
sklearn.tree.DecisionTreeClassifier(criterion='gini',max_depth=None,random_state=None) 决策树的分类器 criterion: 默认是'gini'系数,也可以选择信息增益的熵'entropy'. #决策树的划分方式,默认为gini,更加精细化# max_depth: 树的深度大小,层 random_state:随机数种子 method: decision_path:返回决策树的路径
决策树案例:泰坦尼克号→从灾难中学习机器
项目背景:
- 泰坦尼克号的沉没是历史上最臭名昭著的海难之一。
- 1912年4月15日,在她的处女航中,被广泛认为的“沉没”RMS泰坦尼克号与冰山相撞后沉没。不幸的是,船上没有足够的救生艇供所有人使用,导致2224名乘客和机组人员中的1502人死亡。
- 尽管幸存有- -些运气,但似乎有些人比其他人更有可能生存。
- 在这一挑战中,我们要求您使用乘客数据(即姓名,年龄,性别,社会经济阶层等)来建立一个回答以下问题的预测模型:“什么样的人更有可能生存? "。
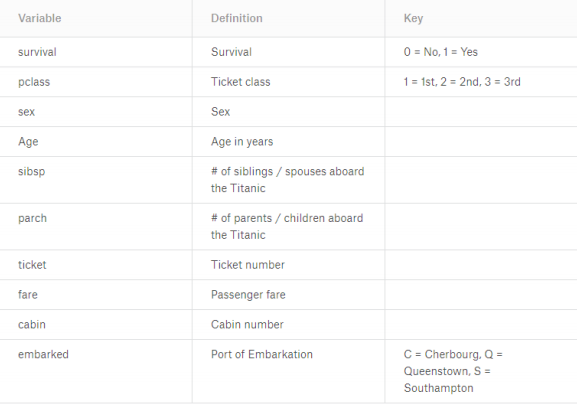
数据:
在本竞赛中,您将可以访问两个类似的数据集,其中包括乘客信息,例如姓名,年龄,性别,社会经济舱等。一个数据集名为“train.csv",另一个数据集名为" test.csv"。Train.csv将包含部分机上乘客的详细信息(准确地说是891名) , 并且重要的是,它们将揭示他们是否 幸存下来,也称为“地面真理"。 “test.csv”数据集包含类似的信息,但未透露每位乘客的"基本事实"。预测这些结果是您的工作。 使用您在train.csv数据中找到的模式,预测机上其他418名乘客(在test.csv中找到) 是否还幸免于难。
## 数据来源于机器学习竞赛的一个平台,www.kaggle.com , 搜索 Titanic 即可获取数据 ##
那么我们如何去做这个训练测试呢,案例的工作流程如下:
- 数据的下载及读取加载
- 选择有影响的特征,如果特征数据中有缺失值,那么一定要对缺失值进行处理
- 进行特征工程,抽取特征
- 决策树估计流程
第一步:导入需要使用的库,接口
import pandas as pd from sklearn.tree import DecisionTreeClassifier #决策树接口 from sklearn.model_selection import train_test_split #分割器,对数据集进行分割 from sklearn.feature_extraction import DictVectorizer #特征抽取,对字典的特征抽取 # 数据加载,读取数据 titan = pd.read_csv('titanic passenger list.csv') # 因为数据是处理好的,第一行是列名,所以直接读取就好了
数据是这样的,加载的数据和原数据:titan.head().
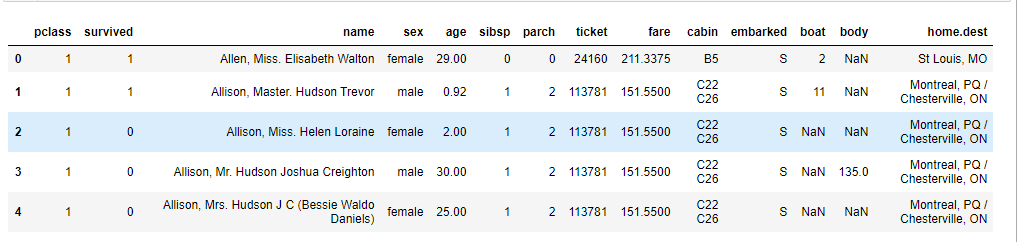

## 第一列为列名称,列名下面才是训练数据 ##
第二步: 数据处理,筛选特征值,目标值
# 我们人为的选择3个特征值,仓位(有钱人优先),年龄(老人先走),性别(女士优先) # x = titan[['pclass'],['age'],['sex']] # 从加载的titan选取3个特征值 y = titan['survived'] # 目标值,他们的存活率
第三步:数据是否有缺失值,如何处理
x['age'].hasnans # 空值检测,返回布尔值,True为有空值
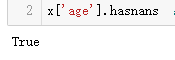
# 缺失值的处理方式包括:1,随便填写。2,删除该条数据。3,平均值 # 一般选取平均值填充,处理方式如下 x['age'].fillna(x['age'].mean(),inplace=True) # 因为数据是csv文件中导出的,设置inplace为True是不返回数据,直接修改,所以titan对象中空值也被修改了 #
第四步:分割数据集
x_train , x_test , y_train , y_test = train_test_split(x ,y ,test_size=0.25) # 老套路 # 分割完后,查看数据,发现特征值sex 是英文的female和male ,所以要转换,重新编码为 0,1。用one hot 编码
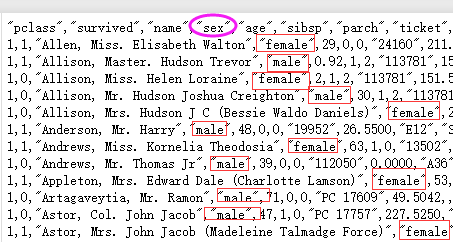
第五步:进行特征工程,类别特征→one hot 编码,重新编码为不同变量
dv = DictVectorizer(sparse=False) # 选择稀疏矩阵,为True得到的不为完整矩阵
# 数据传入,需要传入字典列表数据,我们可以看到数据现在是这样的 #
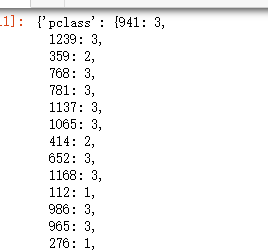
# 这样比较难以看懂,取得数据需要依次索引,所以在to_dict() 设置属性转换 , orient = 'records' #
x_train.to_dict(orient='records') # 转换完后查看数据变成怎样了 👇,这样数据就转换完成了

# 所以根据上面的了解,特征工程传入数据应该这样写:#
x_train = dv.fit_transform(x_train.to_dict(orient='recodrs')) # 还有知道特征值的情况,dv.feature_names_ 查看特征值属性 print(dv.feature_names_) x_train # 结果如下 ,一一对应 #

x_train训练集的特征值抽取了,与之对应,x_test测试集也需要做特征抽取
x_test = dv.transform(x_test.to_dict(orient='records'))
第六步:数据处理好了就该做决策树算法进行预测,决策树算法
dt = DecisionTreeClassifier(max_depth=5) # max_depth 树深度,暂设置5 dt.fit(x_train , y_train) # 机器学习

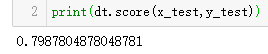
第七步:查看预测准确性→dt.score()
print(dt.score(x_test,y_test))
针对决策树的结构,是可以保存下来的。#由于未进行剪枝算法,图片内容会很密集#
决策树的结构→本地保存
1、sklearn.tree.export_graphviz() 该函数能够导出DOT格式 tree.export_graphviz(esimator , out_file='tree.dot' , feature_names=[","]) 2、工具(能够将dot文件转换为PDF , png) 安装graphviz ubuntu:sudo apt-get install graphviz mac:brew install graphviz 3、运行命令 dot-Tpng tree.dot -o tree.png
那么来保存看下:
from sklearn.tree import export_graphviz export_graphviz(dt,out_file='tree.dot')
保存后,打开tree.dot 是这样的:

## 额,有点难以看懂,还是能看懂一些,那么转换之后能看的更明白。由于本人也没安装操作过,转换等自己上网查吧,嘿!##
决策树总结:
优点
- 简单的理解和解释,树木可视化
- 需要很少的数据准备,其他技术通常需要做数据归一化
缺点
- 决策树学习者可以创建但是不能很好推广过于复杂的树。这被称为过拟合。
改进
- 剪枝算法 Cart (决策树api中已经实现)
- 随机森林,下章讲到!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号