机器学习和数据集介绍、数据集划分、特征抽取、归一化
机器学习介绍和数据集介绍
机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为
工具并致力于真实实时的模拟人类学习方式,并将现有内容进行知识结构划分来有效提高学习效率。
型),并利用规律对未知数据进行预测。
机器学习是从历史数据获得规律,那这些历史数据是什么样的呢?
- scikit-learn数据量较小, 方便学习
- kaggle大数据竞赛平台,80万科学家, 真实数据,数据量巨大
- UCI收录了360个数据集,覆盖科学,生活,经济等领域,数据量几十万
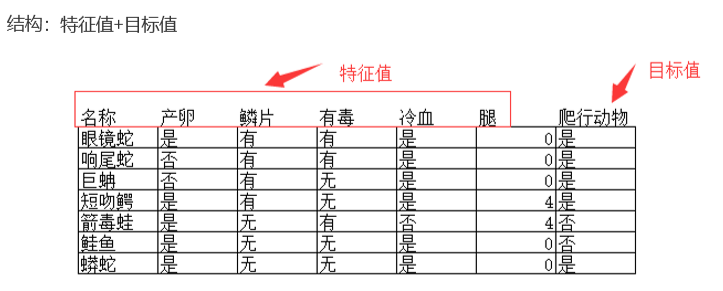
# 注意 : 有些数据集可以没有目标值 。每一行就是一个样本。 每一列就是一个特征。 最后要预测的值就是目标。
scikit-learn
scikit-learn是基于Python语言的机器学习工具
- 简单高效的数据挖掘和数据分析工具
- 可供大家在各种环境中重复使用
- 建立在Numpy , SciPy 和 matplotlib上
- 开源 , 可商业使用 -BSD许可证
Scikit-learn 数据集API介绍
1. sklearn.datasets 1.1 加载获取流行数据集 1.2 datasets.load_*() -- 获取小规模数据集,数据包含在datasets里 1.3 datasetss.fetch_*(data_home=None) 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home, 表示数据集。下载目录,默认是-/scikit-learn_data/ 2. load_* 和 fetch_* 返回的数据类型是datasets.base.Bunch(字典格式) data:特征数据数组,是[n_ samples*n_features]的二维numpy.ndarray数组 target:标签数组,是n_samples的维numpy.ndarray数组 DESCR:数据描述 feature_names:特征名,新闻数据,手写数字,回归数据集没有 target_names;标签名
#关于第二点, load_* 用于获取小数据集 , fetch_* 用于获取大数据集
scikit-learn 的使用 :
# 导入方式 from sklearn.datasets import load_iris # load_iris 导入是鸢尾花的数据 # 加载鸢尾花的数据 li = load_iris() print('获取特征值',li.data) # 鸢尾花的特征,官方早已分类好的,可供直接使用 print('目标值',li.target) # 分了3个类 li.DESCR # 鸢尾花的描述li.feature_names # 鸢尾花的特征名 花长 花宽li.target_names # 鸢尾花的标签名


#1 特征值 # 值太多,只复制一部分展示 获取特征值 [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2] [4.4 2.9 1.4 0.2] [4.9 3.1 1.5 0.1] [5.4 3.7 1.5 0.2] [4.8 3.4 1.6 0.2] [4.8 3. 1.4 0.1] [4.3 3. 1.1 0.1] [5.8 4. 1.2 0.2] [5.7 4.4 1.5 0.4] [5.4 3.9 1.3 0.4] [5.1 3.5 1.4 0.3] [5.7 3.8 1.7 0.3] [5.1 3.8 1.5 0.3] [5.4 3.4 1.7 0.2] [5.1 3.7 1.5 0.4] [4.6 3.6 1. 0.2] [5.1 3.3 1.7 0.5] [4.8 3.4 1.9 0.2] [5. 3. 1.6 0.2] [5. 3.4 1.6 0.4] [5.2 3.5 1.5 0.2] [5.2 3.4 1.4 0.2] [4.7 3.2 1.6 0.2] [4.8 3.1 1.6 0.2] [5.4 3.4 1.5 0.4] [5.2 4.1 1.5 0.1] [5.5 4.2 1.4 0.2] [4.9 3.1 1.5 0.2] [5. 3.2 1.2 0.2] [5.5 3.5 1.3 0.2] [4.9 3.6 1.4 0.1] [4.4 3. 1.3 0.2] [5.1 3.4 1.5 0.2] [5. 3.5 1.3 0.3] [4.5 2.3 1.3 0.3] [4.4 3.2 1.3 0.2] [5. 3.5 1.6 0.6] [5.1 3.8 1.9 0.4] [4.8 3. 1.4 0.3] [5.1 3.8 1.6 0.2] [4.6 3.2 1.4 0.2] [5.3 3.7 1.5 0.2] #2 目标值 目标值 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] #3 描述 '.. _iris_dataset:\n\nIris plants dataset\n--------------------\n\n**Data Set Characteristics:**\n\n :Number of Instances: 150 (50 in each of three classes)\n :Number of Attributes: 4 numeric, predictive attributes and the class\n :Attribute Information:\n - sepal length in cm\n - sepal width in cm\n - petal length in cm\n - petal width in cm\n - class:\n - Iris-Setosa\n - Iris-Versicolour\n - Iris-Virginica\n \n :Summary Statistics:\n\n ============== ==== ==== ======= ===== ====================\n Min Max Mean SD Class Correlation\n ============== ==== ==== ======= ===== ====================\n sepal length: 4.3 7.9 5.84 0.83 0.7826\n sepal width: 2.0 4.4 3.05 0.43 -0.4194\n petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)\n petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)\n ============== ==== ==== ======= ===== ====================\n\n :Missing Attribute Values: None\n :Class Distribution: 33.3% for each of 3 classes.\n :Creator: R.A. Fisher\n :Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)\n :Date: July, 1988\n\nThe famous Iris database, first used by Sir R.A. Fisher. The dataset is taken\nfrom Fisher\'s paper. Note that it\'s the same as in R, but not as in the UCI\nMachine Learning Repository, which has two wrong data points.\n\nThis is perhaps the best known database to be found in the\npattern recognition literature. Fisher\'s paper is a classic in the field and\nis referenced frequently to this day. (See Duda & Hart, for example.) The\ndata set contains 3 classes of 50 instances each, where each class refers to a\ntype of iris plant. One class is linearly separable from the other 2; the\nlatter are NOT linearly separable from each other.\n\n.. topic:: References\n\n - Fisher, R.A. "The use of multiple measurements in taxonomic problems"\n Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to\n Mathematical Statistics" (John Wiley, NY, 1950).\n - Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.\n (Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.\n - Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System\n Structure and Classification Rule for Recognition in Partially Exposed\n Environments". IEEE Transactions on Pattern Analysis and Machine\n Intelligence, Vol. PAMI-2, No. 1, 67-71.\n - Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions\n on Information Theory, May 1972, 431-433.\n - See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II\n conceptual clustering system finds 3 classes in the data.\n - Many, many more ...' #4 特征名 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] #5 标签名 array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
👆 这是用于分类的小数据集 , 👇用于分类的大数据集
1. sklearn.datasets.fetch_20newsgroups(data_home=None,subset='train' 1.1 subset:'train'或者'test','all',可选,选择要加载的数据集 --train:训练集,test:测试集,all:两者全部 1.2 datasets.clear_data_home(data_home=None) --清除目录下的数据 #代码案例 from sklearn.datasets import fetch_20newsgroups news = fetch_20newsgroups(subset='all')
用于回归的数据集 :
1. sklearn.datasets.load_boston() -- 加载并返回波士顿房价数据集 2. sklearn.datasets.load_diabetes() -- 加载和返回糖尿病数据集 # 代码案例 from sklearn.datasets import load_boston lb = load_boston() print('特征值', lb.data) # 目标值是连续的 回归问题的特性 print('目标值', lb.target)
数据集划分
数据集会划分成两部分:训练集和测试集。
训练集用来训练,构建模型,测试集用来评估预测结果。
比例一般为75%的数据为训练集,25%的数据为测试集。
API :
sklearn.model_selection.train_test_split
from sklearn.model_selection import train_test_split
# x_train ,x_test ,y_train , y_test = train_test_split(x,y,test_size=0.*)
# x : 数据集的特征值
# y : 数据集的目标值
# test_size : 测试集的大小,一般为float
# radom_state : 随机数种子,不同的种子会造成不同的随机采样结果.相同的种子采样结果相同
# return -- 方法返回4个结果: 训练集特征值, 测试集特征值, 训练集目标值, 测试值目标值(默认随机取值)
x_train ,x_test , y_train , y_test = train_test_split(li.data,li.target,test_size=0.25) #传入的值 1. 特征值 2. 目标值 3. 测试集的大小 # 接收为固定写法
# 👆 以鸢尾花的数据为例 , 写了训练集。这个是训练方法 。
x_train.shape # 训练集大小 112条 为原数据集的75% li.data.shape # 原数据集大小 150条

特征抽取
特征工程 :
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的 预测准确性.
特征抽取 :
对文本等数据进行特征值化, 让计算机更好的理解数据.
对字典特征抽取 :
对字典数据进行特征值化. 主要是对类别特征进行One-hot编码.
API 接口 : 字典 Dict
sklearn.feature_extraction.DictVectorizer 1. DictVectorizer.fit_transform(X) x:字典或者包含字典的迭代器 返回值:返回sparse矩阵(稀疏矩阵) 2. DictVectorizer.inverse_transform(X) x:array数组或者sparse矩阵 返回值:转换之前数据格式 3. DictVectorizer.get_feature_names() 返回特征名称 4. DictVectorizer.transform(x) 按照原先的标准转换 流程 : 实例化类 DictVerctorizer 调用 fit_transform方法输入数据并转换
案例 :案例 :案例 :案例 :
# 导入接口 from sklearn.feature_extraction import DictVectorizer # 数据 data = [{'name':'汉唐店','Satisfaction':3.5}, {'name':'花溪店','Satisfaction':2.5}, {'name':'温泉店','Satisfaction':3}] # 实例化 dv = DictVectorizer() # 调用转换接口 res = dv.fit_transform(data) print(res.toarray()) # 转换成数组 看起来更清晰 # 结果注解👇 : 第一个特征值 是3.5 所以第1个 是1 ,二个是2.5≠3.5 所以是0 ,第三个值是3 ≠3.5 ,所以是0 ;第二,第三列类似第一种 dv.get_feature_names() # 特征名称

文本特征的抽取 text.CountVectorizer
API接口 文本 Text
sklearn.feature_extraction.text.CountVectorizer 1. CountVectorizer.fit_transform(X) x:文本或者包含文本字符串的可迭代对象 返回值:返回sparse矩阵(稀疏矩阵) 2. CountVectorizer.inverse_transform(X) x:array数组或者sparse矩阵 返回值:转换之前数据格式 3. CountVectorizer.get_feature_names() 返回单词列表 CountVectorizer.transform(x) 按照原先的标准转换 流程 实例化 CountVectorizer 调用 fit_transform 方法输入数据并转换
案例:案例:案例:案例:
# 上面是英文的特征抽取 ,那么中文是否一样,该如何操作? from sklearn.feature_extraction.text import CountVectorizer import jieba # 中文分词工具库
cv = CountVectorizer()
data = ['''君不见,黄河之水天上来,奔流到海不复回。 君不见,高堂明镜悲白发,朝如青丝暮成雪。 人生得意须尽欢,莫使金樽空对月。 天生我材必有用,千金散尽还复来。 烹羊宰牛且为乐,会须一饮三百杯。 岑夫子,丹丘生,将进酒,杯莫停。 与君歌一曲,请君为我倾耳听。 钟鼓馔玉不足贵,但愿长醉不复醒。 古来圣贤皆寂寞,惟有饮者留其名。 陈王昔时宴平乐,斗酒十千恣欢谑。 主人何为言少钱,径须沽取对君酌。 五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。''', '''唧唧复唧唧,木兰当户织。不闻机杼声,惟闻女叹息。 问女何所思,问女何所忆。女亦无所思,女亦无所忆。昨夜见军帖,可汗大点兵,军书十二卷,卷卷有爷名。阿爷无大儿,木兰无长兄,愿为市鞍马,从此替爷征。 东市买骏马,西市买鞍鞯,南市买辔头,北市买长鞭。旦辞爷娘去,暮宿黄河边,不闻爷娘唤女声,但闻黄河流水鸣溅溅。旦辞黄河去,暮至黑山头,不闻爷娘唤女声,但闻燕山胡骑鸣啾啾。 万里赴戎机,关山度若飞。朔气传金柝,寒光照铁衣。将军百战死,壮士十年归。 归来见天子,天子坐明堂。策勋十二转,赏赐百千强。可汗问所欲,木兰不用尚书郎,愿驰千里足,送儿还故乡。 ''']
# 对中文进行处理 data = [' '.join(jieba.cut(x)) for x in data] # 中文分词,并在分词后方加入空格 res = cv.fit_transform(data) #中文需要分词 fit_transform 默认用空格分词 cv.get_feature_names() # 获取特征值 res.toarray() # 转化特征值相比在N章(以上是2个str)中出现的次数

在上述的文本抽取中,我们是依据各个分词出现的频率进行分类的,但是这会出现一个问题,因为有些词,会出现在所有的文本中且占比高,这样就不利于我们将提取出独有的文本特征,即提炼出各个文本的关键词。
原理 : tf:term frequency 词频 idf:inverse document frequency 逆文档频率 log(中文档数量/该词出现的文档数量) log1=0 tf*idf = 词的重要性程度 TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则 认为此词或者短语具有很好的类别区分能力,适合用来分类。 TF-IDF作用:用以评估一个词对于一个文章集或一个语料库中的其中一份的重要程度
API 接口 关键字的重要程度
sklearn.feature_extraction.text.TfidVectorizer
返回词的权重矩阵
TfidVectorizer.fit_transform(X)
x:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵(稀疏矩阵)
TfidVectorizer.inverse_transform(X)
x:array数组或者sparse矩阵
返回值:转换之前数据格式
TfidVectorizer.get_feature_names()
返回单词列表
TfidVectorizer.transform(x)
按照原先的标准转换
流程
实例化 TfidVectorizer
调用 fit_transform 方法输入数据并转换
案例:案例:案例:案例:
#导入接口 from sklearn.feature_extraction.text import TfidfVectorizer # 实例化 tf = TfidfVectorizer()
data1 = ['''君不见,黄河之水天上来,奔流到海不复回。 君不见,高堂明镜悲白发,朝如青丝暮成雪。 人生得意须尽欢,莫使金樽空对月。 天生我材必有用,千金散尽还复来。 烹羊宰牛且为乐,会须一饮三百杯。 岑夫子,丹丘生,将进酒,杯莫停。 与君歌一曲,请君为我倾耳听。 钟鼓馔玉不足贵,但愿长醉不复醒。 古来圣贤皆寂寞,惟有饮者留其名。 陈王昔时宴平乐,斗酒十千恣欢谑。 主人何为言少钱,径须沽取对君酌。 五花马,千金裘,呼儿将出换美酒,与尔同销万古愁。''', '''唧唧复唧唧,木兰当户织。不闻机杼声,惟闻女叹息。 问女何所思,问女何所忆。女亦无所思,女亦无所忆。昨夜见军帖,可汗大点兵,军书十二卷,卷卷有爷名。阿爷无大儿,木兰无长兄,愿为市鞍马,从此替爷征。 东市买骏马,西市买鞍鞯,南市买辔头,北市买长鞭。旦辞爷娘去,暮宿黄河边,不闻爷娘唤女声,但闻黄河流水鸣溅溅。旦辞黄河去,暮至黑山头,不闻爷娘唤女声,但闻燕山胡骑鸣啾啾。 万里赴戎机,关山度若飞。朔气传金柝,寒光照铁衣。将军百战死,壮士十年归。 归来见天子,天子坐明堂。策勋十二转,赏赐百千强。可汗问所欲,木兰不用尚书郎,愿驰千里足,送儿还故乡。 ''']
# 特征抽取 #
data1 = [' '.join(jieba.cut(x)) for x in data1] # 文本数据 res = tf.fit_transform(data1) # 输入数据并转换 print(tf.get_feature_names()) # 特征值 print(res.toarray()) # 很多
['一曲', '一饮', '万古愁', '万里', '三百杯', '不复醒', '不用', '不足', '不闻', '与尔同销', '东市', '丹丘', '为乐', '主人', '之水', '五花马', '人生', '从此', '会须', '传金', '但愿', '但闻', '何为', '倾耳', '关山', '军帖', '出换', '北市', '十二', '十二卷', '十千', '十年', '千里', '千金', '南市', '卷卷', '古来', '可汗', '叹息', '君不见', '君歌', '君酌', '呼儿', '唧唧', '圣贤', '壮士', '复来', '大点', '天上', '天子', '天生我材必有用', '夫子', '奔流', '女亦无所忆', '女声', '宰牛', '寂寞', '寒光', '将军', '将进酒', '尚书郎', '平乐', '度若飞', '归来', '当户织', '径须', '得意', '恣欢', '惟有', '惟闻', '愿为', '愿驰', '戎机', '战死', '所忆', '所思', '所欲', '故乡', '散尽', '斗酒', '无大儿', '旦辞', '明堂', '明镜', '昔时', '昨夜', '暮宿', '暮成', '暮至', '替爷征', '朔气', '朝如', '木兰', '机杼', '杯莫停', '流水', '海不复', '烹羊', '燕山', '爷名', '爷娘', '留其名', '白发', '百千', '策勋', '美酒', '胡骑鸣', '莫使', '西市', '言少', '请君', '赏赐', '辔头', '送儿', '金樽空', '钟鼓馔玉', '铁衣', '长兄', '长醉', '长鞭', '问女何', '阿爷', '陈王', '青丝', '鞍鞯', '鞍马', '须尽欢', '饮者', '骏马', '高堂', '鸣溅', '黄河', '黑山头'] [[0.12081891 0.12081891 0.12081891 0. 0.12081891 0.12081891 0. 0.12081891 0. 0.12081891 0. 0.12081891 0.12081891 0.12081891 0.12081891 0.12081891 0.12081891 0. 0.12081891 0. 0.12081891 0. 0.12081891 0.12081891 0. 0. 0.12081891 0. 0. 0. 0.12081891 0. 0. 0.24163782 0. 0. 0.12081891 0. 0. 0.24163782 0.12081891 0.12081891 0.12081891 0. 0.12081891 0. 0.12081891 0. 0.12081891 0. 0.12081891 0.12081891 0.12081891 0. 0. 0.12081891 0.12081891 0. 0. 0.12081891 0. 0.12081891 0. 0. 0. 0.12081891 0.12081891 0.12081891 0.12081891 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.12081891 0.12081891 0. 0. 0. 0.12081891 0.12081891 0. 0. 0.12081891 0. 0. 0. 0.12081891 0. 0. 0.12081891 0. 0.12081891 0.12081891 0. 0. 0. 0.12081891 0.12081891 0. 0. 0.12081891 0. 0.12081891 0. 0.12081891 0.12081891 0. 0. 0. 0.12081891 0.12081891 0. 0. 0.12081891 0. 0. 0. 0.12081891 0.12081891 0. 0. 0.12081891 0.12081891 0. 0.12081891 0. 0.08596365 0. ] [0. 0. 0. 0.09033007 0. 0. 0.09033007 0. 0.27099022 0. 0.09033007 0. 0. 0. 0. 0. 0. 0.09033007 0. 0.09033007 0. 0.18066015 0. 0. 0.09033007 0.09033007 0. 0.09033007 0.09033007 0.09033007 0. 0.09033007 0.09033007 0. 0.09033007 0.09033007 0. 0.18066015 0.09033007 0. 0. 0. 0. 0.18066015 0. 0.09033007 0. 0.09033007 0. 0.18066015 0. 0. 0. 0.09033007 0.18066015 0. 0. 0.09033007 0.09033007 0. 0.09033007 0. 0.09033007 0.09033007 0.09033007 0. 0. 0. 0. 0.09033007 0.09033007 0.09033007 0.09033007 0.09033007 0.09033007 0.18066015 0.09033007 0.09033007 0. 0. 0.09033007 0.18066015 0.09033007 0. 0. 0.09033007 0.09033007 0. 0.09033007 0.09033007 0.09033007 0. 0.27099022 0.09033007 0. 0.09033007 0. 0. 0.09033007 0.09033007 0.27099022 0. 0. 0.09033007 0.09033007 0. 0.09033007 0. 0.09033007 0. 0. 0.09033007 0.09033007 0.09033007 0. 0. 0.09033007 0.09033007 0. 0.09033007 0.18066015 0.09033007 0. 0. 0.09033007 0.09033007 0. 0. 0.09033007 0. 0.09033007 0.19281177 0.09033007]]
# 以上就是对特征值得抽取,部分注意事项等 #
归一化
特征预处理 :
通过特定的统计方法(数学方法)将数据转换成算法要求的数据
数值类型标准数据缩放 :
归一化
标准化
类别型数据 : one-hot编码
时间类型 : 时间的切分
sklearn 特征处理API 👉 sklearn.preprocessing
类: sklearn.prepocessing.MinMaxScaler MinMaxScaler(feature_range=(0,1)...) 每个特征缩放到给定范围(默认[0,1]) MinMaxScalar.fit_transform(x) x:numpy array格式的数据(n_samples,n_features) 返回值:转换后的形状相同的array 步骤 实例化 MinMaxScalar 通过 fit_transform 转换
# 特征预处理--数据 data = np.array([[5000,2,10,40],[6000,3,15,45],[50000,5,15,40]]) #--------------------# array([[ 5000, 2, 10, 40], [ 6000, 3, 15, 45], [50000, 5, 15, 40]])
👆 有时候,你可能会注意到某些特征比其他特征拥有高得多的跨度值。举个例子,将一个人的 收入和他的 年龄进行比较,通过缩放可以避免某些特征比其他特征获得大小非常悬殊的权重值。即使得某一个特征 不会对结果造成过大的影响.
归一化 :
特点:通过对原始数据进行变换吧数据映射到(默认为[0,1])之间
# 导入接口 from sklearn.preprocessing import MinMaxScaler # 实例化 mm = MinMaxScaler() # 默认0-1之间 # 对数据进行转换-归一化 res = mm.fit_transform(data) res

还可以指定范围缩减 :
mm = MinMaxScaler(feature_range=(0,3)) res = mm.fit_transform(data) res

👆 缺点 👆 在特定的场景下大值小值是变化的,另外,大值与小值非常容易受异常点的影响,所以这种方 法的鲁棒性(稳定性)较差,只适合传统精确小数据场景。所以一般不会使用,广泛使用的是标准化。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号