Python--数据透视表和交叉表、数据读取
数据 透视表 and 交叉表
先看数据是什么样的 ...


# date dati = ['2019-11-01','2019-11-02','2019-11-03']*3 rng = pd.to_datetime(dati) df = DataFrame({ 'date':rng, 'key':list('abcdabcda'), 'value':np.random.randn(9)*10 }) df
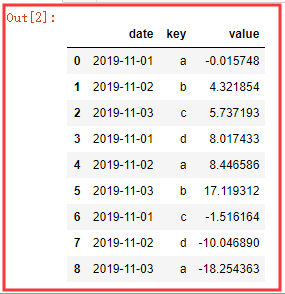
简单的透视表 方法 👉 pivot_table()
语法是这样的 :
pd.pivot_table( data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, ) # data : DataFrame 对象
# values : 要聚合的列 或者 列表 # index : 数据透视表的index , 行索引 ,从原始数据的列中进行筛选 # columns : 数据透视表的columns 列名 ,从原始数据中筛选 # aggfunc : 用于聚合的函数 , 默认是 np.mean , 支持numpy 的计算方法
所以按照语法 ,应该这样操作 ,不需要每个都填上, 根据我们需要的 ,填上对应的数据及参数就可以了.
pd.pivot_table(df , values='value',index='date',columns='key',aggfunc=np.mean)
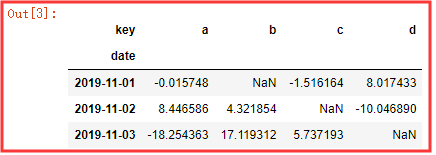
# 👆 这个就是从date中根据 值 对应的key中的值,以一对一,一对多的方式寻找 ,如果没有找到 就用NaN 填充 ,
# 👆 data 中的 2019 -11 - 01 在key 中有a , c ,d ,有就对应填充 , 而 b没有就用NaN填充。2019 -11 -02 , 2019 - 11 -03 依次类推。
pd.pivot_table(df,values='value',index=['date','key'],aggfunc=np.sum) # 以date ,key 共同做行进行索引,值为value,统计不同(date, key)情况下的计算
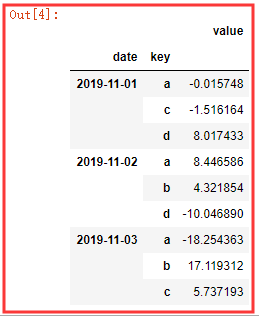
# 👆 , 这也就是用层次索引的计算嘛 , 一看图就懂了。简单的数据透视表.想深入理解,请自行百度。
交叉表的实现 方法 👉 crosstab()
在默认情况下 , crosstab() 计算因子的频率表 , 比如用于 str 的数据透视分析
语法是这样的 :
pd.crosstab( index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False, )
演示数据:
nf = DataFrame({ 'A':[1,2,2,2,2], 'B':[3,3,4,4,4], 'C':[1,1,np.nan,1,1] })
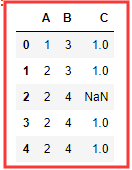
简单交叉表实现 :
pd.crosstab(nf['A'],nf['B']) # 如果crosstab 只接收两个Series 它将提供一个频率表 # 上面代码是用 A 的唯一值,统计 B 的唯一的出现次数
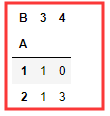
# 👆 注解 :A=1 and B =3 出现过1次 , A=2and B =3 出现过1次, B= 4 and A=1 出现过0次 ,B =4 and A =2 出现过3次,所以竖这看就是 1 1 0 3。OK!
设置 normalize 参数为 True 时,会显示百分百,总的百分百 :
pd.crosstab(nf['A'],nf['B'],normalize=True)

# 👇 下方为 交叉表C列计算 ,,,,
pd.crosstab(nf['A'],nf['B'],values=nf['C'],aggfunc=sum) # values : 可选 , 根据因子聚合的值得列或者说是数组 # aggfunc : 可选 ,如果未传递values数据,则计算频率,如果传递了数组,则按照指定计算 # 相同于按照A和B界定分组,计算每一组中第三个列C的值
# 👆 这个就是 A和B交叉表的C列的值 计算 ,A和B交叉出现几次 就把A和B交叉的对于C列计算。看图秒懂

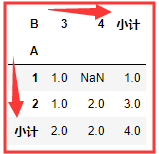
margins 参数 :布尔值 ,默认是False ,用于添加 行 or 列 的小计,就是求和
pd.crosstab(nf['A'],nf['B'],values=nf['C'],margins=True,margins_name='小计',aggfunc=sum) # margins_name 就是重命名嘛 , 一看就懂了, , , NaN值都是自动忽略的
数据的读取 txt / csv / excel ...... 方法 👉 read_*()
* 就是 按Tab 键位 会出现read_ 列表 ,选取自己所需要的
read_table() 主要用来读取简单的数据 , txt or csv
文件打开是这样的 :
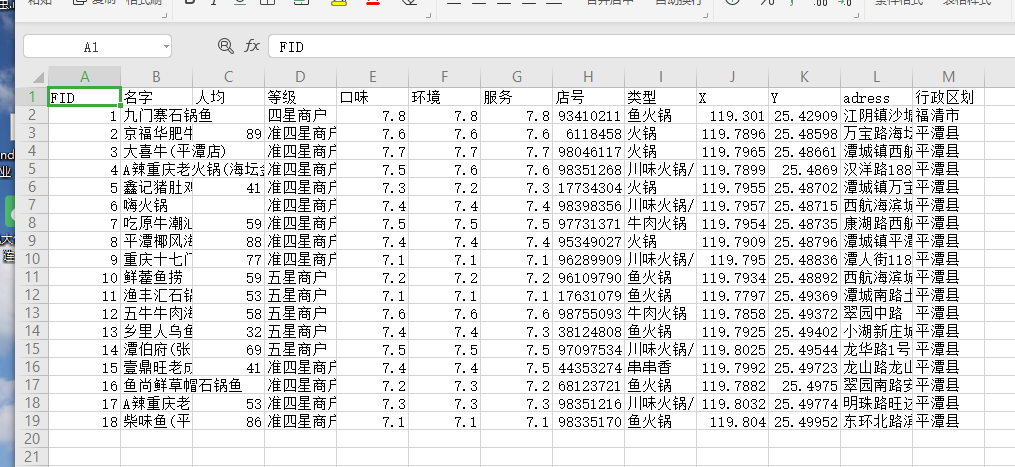
👇 文件数据的读取 :
dinner = pd.read_table('diner.csv',delimiter=',',header=0,index_col=0 ,encoding='gbk') dinner.head() # 默认取前5条数据
# delimiter : 用于拆分的字符 ,也可以使用sep=','
# header : 用作列名的序号 ,默认为 0 也就是第一行 .如果没有,header=None
# index_col : 指定某列为行索引 ,否则自动索引(0,1,2....)
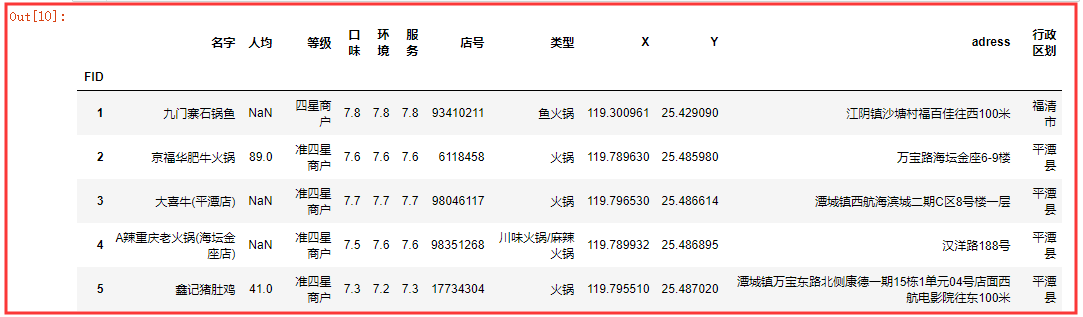
专门用来读取 csv 数据 👉 read_csv() :
作用和上面的一样,不过上面的写法更为标准
d_csv = pd.read_csv('diner.csv',engine='python') d_csv.head()
还有读取excel 数据 👉 read_excel()
d_excel = pd.read_excel('demo.xlsx',sheet_name='demo',header=0) d_excel.head() # sheet_name : 取 excel文件中的一张表 ,返回多张使用sheet_name=[0,1],sheet_name=None 返回全表 # 1. int / string 返回的是dataframe # 2. none / list 返回的是dict 字典


 浙公网安备 33010602011771号
浙公网安备 33010602011771号