Python--DataFrame分组-GroupBy
DataFame分组功能及其他配合使用方法
分组统计 👉 GroupBy
# *.groupby(by=None,axis=0,level=None,as_index=True,sort=True,group_keys=True,squeeze=False,observed=False,**kwargs) # axis=0 行 / 1 列
有这样一组数据 :


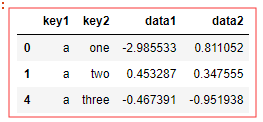
df = pd.DataFrame({ 'key1':['a','a','b','b','a'], 'key2':['one','two','one','two','three'], 'data1':np.random.randn(5), 'data2':np.random.randn(5) }) #-------------------------------# key1 key2 data1 data2 0 a one -0.205263 1.820120 1 a two 0.436864 -1.858459 2 b one 0.695624 1.134222 3 b two 0.281301 1.735320 4 a three 1.040519 0.657742
如何对 ‘key1’ 进行 分组 并求 平均值 ?
ass = df['data1'].groupby(df['key1']) #这是一个分组对象,没有进行任何计算 ass.mean() # 对"对象" 进行调用方法 # df.groupby('key1').mean() # df[['data1','data2']].groupby('key1').mean()
比较简单 ,呵 ,那么如何对多个 '字段' 进行分组 ? 要求对 key1 , key2进行分组并计算data2的平均值
df['data2'].groupby([df['key1'],df['key2']]).mean() # 这种分组 只需要将需要的字段放入数组( 也是列表[] )中即可 #---------------------------# key1 key2 a one 1.820120 three 0.657742 two -1.858459 b one 1.134222 two 1.735320 Name: data2, dtype: float64
有如下数据 :
city =Series(['北京','长沙','长沙','北京','北京']) years = Series([2018,2018,2019,2018,2019]) #---------------------------# 0 北京 1 长沙 2 长沙 3 北京 4 北京 dtype: object 0 2018 1 2018 2 2019 3 2018 4 2019 dtype: int64
那么 , 如何用城市 和 年份对 df 进行分组呢?
df['data1'].groupby([city,years]).mean() #----------------------------# 北京 2018 -0.681558 2019 1.580496 长沙 2018 -0.112299 2019 -0.498441 Name: data1, dtype: float64 # 分组的键可以是任何长度适当(=len(index))的数组 # 👆 这个就是将分组键改成了自定义城市和年份 匹配相同的相加求平均值 ,不匹配的不计算 # 北京的2018相加 求平均 北京2019 相加求平均 . 长沙的也一样
那又 如何对整个 df 的 key1 分组求平均值?
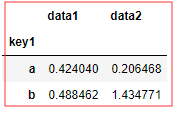
df.groupby(['key1']).mean() # 👆 自动聚合数值列,忽略 非数值 列 df.groupby(['key1','key2']).mean() # 👆 可以将 列名 作为分组键 #----------------------# data1 data2 key1 a 0.424040 0.206468 b 0.488462 1.434771 #----------------------# data1 data2 key1 key2 a one -0.205263 1.820120 three 1.040519 0.657742 two 0.436864 -1.858459 b one 0.695624 1.134222 two 0.281301 1.735320
如何求分组的 大小 ,组数量, 分组的行数 ?
df.groupby('key1').size() # の , 我。。。。。 #-----------------# key1 key2 a one 1 three 1 two 1 b one 1 two 1 dtype: int64
对分组进行迭代 :groupby 对象支持迭代,可以产生一组 二元元组,由 分组名 和 数据块 组成。代码如下
for df1 ,df2 in df.groupby(['key1']): print(df1) print(df2) #--------------------------# a key1 key2 data1 data2 0 a one -0.245438 -1.030687 1 a two -0.112299 1.817918 4 a three 1.580496 0.861224 b key1 key2 data1 data2 2 b one -0.498441 -0.946496 3 b two -1.117678 0.129720
# 👆 以key1中的数据分组,分出N元元组,名字是key1中的数据名称为分组名
# len(df[df['key1'].duplicated()==False]) df的key1列中数据不重复的长度 上面输出的是 2
还可以在多元分组的基础上再对 key2 分组 ,如何实现呢? 如下
for (k1,k2),group in df.groupby(['key1','key2']): print(k1,k2) # key1的值, key2的值 print(group) # key1的值+key2的值+后面的数据 同累型a one,a two,b one。。。这种 #------------------------# a one key1 key2 data1 data2 0 a one -0.245438 -1.030687 a three key1 key2 data1 data2 4 a three 1.580496 0.861224 a two key1 key2 data1 data2 1 a two -0.112299 1.817918 b one key1 key2 data1 data2 2 b one -0.498441 -0.946496 b two key1 key2 data1 data2 3 b two -1.117678 0.12972
如何将 groupby() 之后的对象做成一个字典呢?👉 dict()
dict([('a','b'),('c','d')])

将 df 按 key1 分组后的内容转换 :
ps = dict(list(df.groupby(['key1']))) # # 把分组内容变成一个字典对象,通过健取值,如所有a,所有b print(ps) ps['a'] #取出字典中 的所有 a 组 #-----------------------# {'a': key1 key2 data1 data2 0 a one -0.205263 1.820120 1 a two 0.436864 -1.858459 4 a three 1.040519 0.657742, 'b': key1 key2 data1 data2 2 b one 0.695624 1.134222 3 b two 0.281301 1.735320} key1 key2 data1 data2 0 a one -0.205263 1.820120 1 a two 0.436864 -1.858459 4 a three 1.040519 0.657742
上面都是对 列 进行分组的, ‘行’ 可不可以呢? 怎么实现?
# 按行的数据 , 对列进行分组 axis=1 line = df.groupby(df.dtypes,axis=1) # 行 按数据类型进行分组 dict(list(line)) #--------------------# {dtype('float64'): data1 data2 0 -0.205263 1.820120 1 0.436864 -1.858459 2 0.695624 1.134222 3 0.281301 1.735320 4 1.040519 0.657742, dtype('O'): key1 key2 0 a one 1 a two 2 b one 3 b two 4 a three}
按照 分组键 ,对整个对象进行分组
df.groupby(['key1']).sum()

分组后有多列 , 那我如何选择其中的一列 或者多列 ,我如何得到 data1呢?
# 用列名对 groupby 对象进行索引,就能实现选取部分进行聚合达到目的 有效的提高效率
df.groupby(['key2'])['data1'].sum() # 返回的是一个series对象 df.groupby(['key2'])[['data1','data2']].sum() #返回的是一个DataFrame对象 #--------------------------------------# key2 one 0.490361 three 1.040519 two 0.718165 Name: data1, dtype: float64 data1 data2 key2 —————————————— one 0.490361 2.954342 three 1.040519 0.657742 two 0.718165 -0.123139
# 👆 选取一组列的时候 ,用列表的方式,返回的是 DataFrame 对象
## df['data1'].groupby(df['key1']).mean() 等于 df.groupby(['key1'])['data1'].mean() ##
通过 字典 或者 Series 进行分组
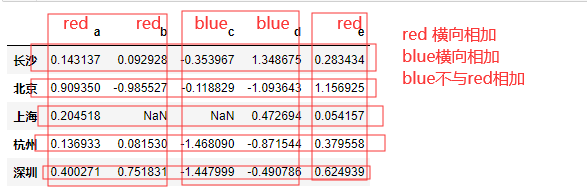
df = DataFrame(np.random.randn(5,5),columns=list('abcde'),index=['长沙','北京','上海','杭州','深圳']) df.loc[2:3,['b','c']] = np.NaN #添加几个NaN值 # 假设已知列的分组关系,希望根据分组计算列的总和
colors = {'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
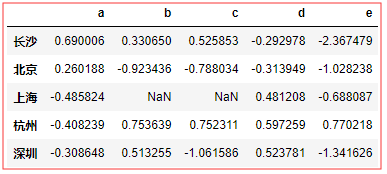

dt = df.groupby(colors,axis=1) dt.sum() # 就是对columns 使用colors重命名 同名合并 行的值 横向sum() #------------------# blue red 长沙 0.994708 0.519499 北京 -1.212472 1.080747 上海 0.472694 0.258676 杭州 -2.339634 0.598021 深圳 -1.938784 1.777040
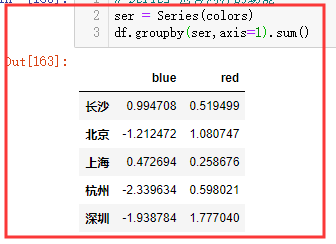
Series 也有同样的功能 ,使用方法如下 :
ser = Series(colors) df.groupby(ser,axis=1).sum() # axis =1 列之间相加 red+red+red , blue+blue
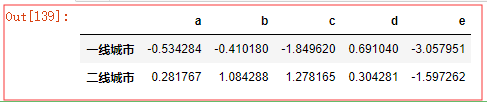
还可以通过 自定义函数 进行分组 :
def city_level(self): frist_city = ['北京','上海','深圳'] if self in frist_city: return '一线城市' return '二线城市' df.groupby(city_level,axis=0).sum() # 👆 会在分组键上调用一次city_level , 并且会将分组键作为参数传给city_level 返回值作为新的分组名称
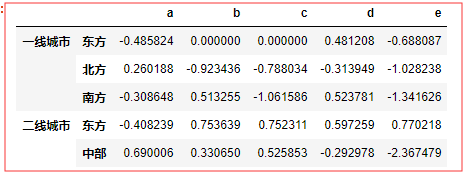
还可以 组合使用,比如对城市分地域 , 所以是这么用的: 传入的函数和数组使用 ‘[ ]’ 列表的方式 用列表来包裹在一起
ars = ['中部','北方','东方','东方','南方'] df.groupby([city_level,ars]).sum()
对于层次索引 , 如何根据索引的级别 来 分组 :
有这么一组数据 :
columns = pd.MultiIndex.from_arrays([['北京','北京','北京','长沙','长沙'],[1,3,4,1,2]],names=['城市','级别']) dfs = DataFrame(np.random.randn(4,5),columns=columns,index=[2016,2017,2018,2019])
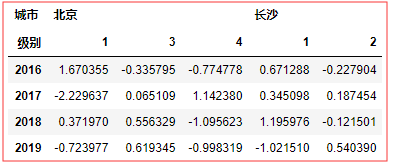
所以这样: 👇
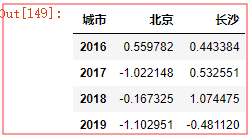
dfs.groupby(level='城市',axis=1).sum()
# 这个就是按城市 合并sum() 行的值 = 各列相加 北京 1 3 4 相加 ,长沙1 2 相加 #
常用的数据聚合函数(复习并知道)
count、sum、mean、median、std、var、min、max、prod、first、last -- 取到分组之后的每个组的函数运算的值
df.groupby('key1').get_group('a') # 得到某一个分组 #运行前,重置下df 我运行前 前面的df都改动了#
面向 多列的函数应用 -- Agg()
# 一次性应用多个函数计算 #
# 有这么一个数据 # df = DataFrame({ 'a':[1,1,2,2], 'b':np.random.rand(4), 'c':np.random.rand(4), 'd':np.random.rand(4) })
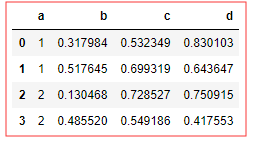
如果我想拿到 [ b , c ,d ] 的 平均值 和 总值 怎么搞? 一次拿到
df.groupby('a').agg(['mean',np.sum])
# 通过 agg 方法,传入一个列表,列表中的元素就是要作用到 每列 上的方法,可以是 字符串,也可是np的函数 #
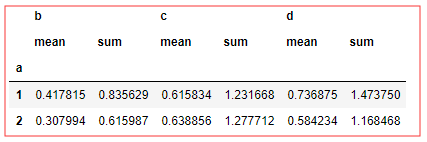
还可以传入 字典 , key 就是columns , value 就是要 作用/使用 的函数
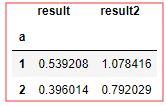
df.groupby('a')['b'].agg({'result':np.mean,'result2':np.sum}) df.groupby('a').agg([('res1','mean'),('res2',np.sum)])
dfn.groupby('a').agg(res1=np.mean,res2=np.sum) # 如果运行错误,原因是pandas的版本未更新,重新安装一下就好了 # 通过二元元组列表指定列名 # 指定列名的时候,会形成层次化的索引 # df已更改,所以值和上面的对不上,使用方法是对的,###官方以后会改方法,我运行出警告了###
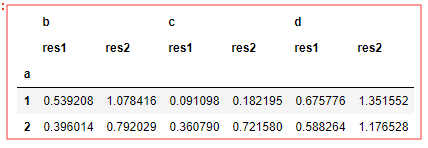

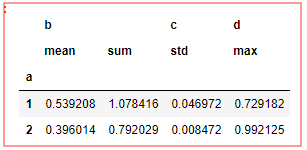
如何对不同的 列 ,进行不同的函数 :
df.groupby('a').agg({'b':['mean',np.sum],'c':np.std,'d':'max'}) # 面向列的多函数应用
数据分组转换 👇
有如下数据 :
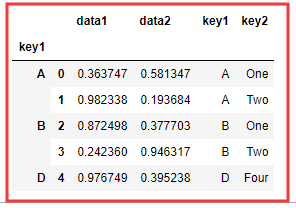
df = DataFrame({ 'data1':np.random.rand(5), 'data2':np.random.rand(5), 'key1':list('AABBD'), 'key2':['One','Two','One','Two','Four'] })
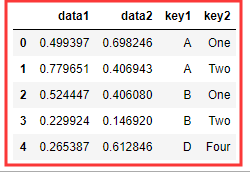
那么问题来了,如何为df 添加用于存放个索引分组平均值列 mean_*
# 方法一 : 先聚合,在合并
means = df.groupby('key1').mean().add_prefix('mean_') #.add_prefix('**_') 给列名添加前缀
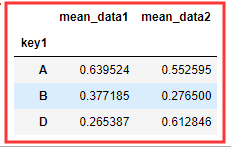
# 合并 merge() pd.merge(df,key1,left_on='key1',right_index=True) # 默认按分组排序 left_on 是列 l/r_index 是索引
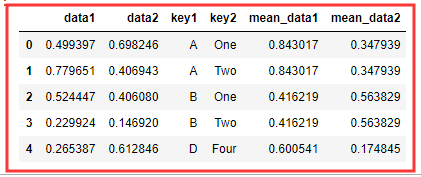
# 方法二 : 通过 transform()
dms = df.groupby('key1').transform(np.mean).add_prefix('mean_') df.join(dms) # dms 有对应索引 所以 join 会匹配索引合并
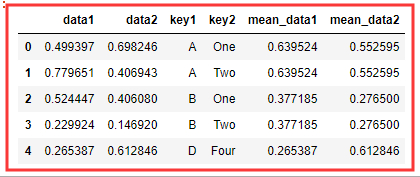
👆 transform 会将一个函数应用到各个分组, 然后将结果放在合适的位置上 。
df.groupby('key1').apply(lambda x:x.describe()) # 对每个分组都进行计算,包括count,mean,std,min,max等等
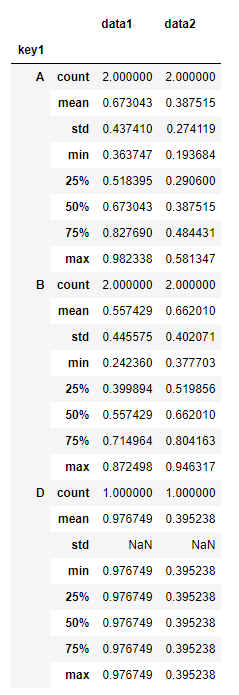
# 👆 数据重新生成的#
apply() :
传入的第一个参数是 函数 , apply方法会将分组(groupby后)的每一个片段作为参数传入函数 。返回结果,最后尝试将各个结果运行组合到一起,也就是函数运行后的结果组合到一起。
def f_df1(d,m): return (d.sort_index()[:m]) #DataFrame排序后按索引选前m行数据 def f_df2(d,k1): return (d[k1]) # 选择DataFrame的k1列,结果为Series,层次化索引
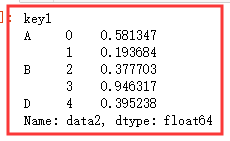
dfs.groupby('key1').apply(f_df1,2) # 返回分组'key1'排序后的每组前2行 dfs.groupby('key1').apply(f_df2,'data2') # 返回分组后表的k1列,也就是data2.结果为Series
# dfs 原数据 data1 data2 key1 key2 0 0.363747 0.581347 A One 1 0.982338 0.193684 A Two 2 0.872498 0.377703 B One 3 0.242360 0.946317 B Two 4 0.976749 0.395238 D Four