Python--常用数学统计算法、字符串操作、合并merge、按行连接join、沿轴连接、去重和替换
常用的数学统计算法
import numpy as np import pandas as pd from pandas import Series,DataFrame df =pd.DataFrame( { 'key1' :[4,5,3, np. nan, 2], 'key2':[1,2, np.NaN, 4,5], 'key3' :[1,2,3,'j','k'] }, index = ['a','b','c','d','e'] ) #-----输出------# key1 key2 key3 a 4.0 1.0 1 b 5.0 2.0 2 c 3.0 NaN 3 d NaN 4.0 j e 2.0 5.0 k
求 平均值 :默认按 列 统计整个dataframe求平均值 , 省略NaN及非数值
df.mean() #-----输出-----# key1 3.5 key2 3.0 dtype: float64
统计一列(平均值) :
## 参数 skipna 作用: 是否忽略NaN , 默认为True ##
df['key1'].mean() #空值,默认忽略,只统计数值类型的列 df.mean(axis=1) #统计行 df.loc[['d','a']].mean() #-----输出-----# 3.5 a 2.5 b 3.5 c 3.0 d 4.0 e 3.5 dtype: float64 key1 4.0 key2 2.5 dtype: float64
累加、累乘、累计最大值 :
df = DataFrame(np.random.randint(1,12,size=[3,4]),columns=list('ABCD'),index=list('abc')) # 累加 cumsum() df.cumsum() #依次累加计算 当前索引 :当前值+=上一个值 # 累乘 cumprod() df.cumprod() ##依次累乘计算 当前索引 :当前值*=上一个值 # 累计最大值 cummax() df.cummax() # 累计最大值,如果当前值大于下一位值,下一位等于当前值 下方折叠结果👇


#-----原数据-----# A B C D a 11 6 2 11 b 3 2 6 7 c 5 2 11 3 #-----累加-----# A B C D a 11 6 2 11 b 14 8 8 18 c 19 10 19 21 #-----累乘-----# A B C D a 11 6 2 11 b 33 12 12 77 c 165 24 132 231 #-----累计最大值-----# A B C D a 11 6 2 11 b 11 6 6 11 c 11 6 11 11
唯一值 unique() : 返回一个唯一值的数组
pds = Series(list('qwerasassssd')) # DataFrame 没有 unique() 啧啧啧 print(pds) pds.unique() #-----输出----# 0 q 1 w 2 e 3 r 4 a 5 s 6 a 7 s 8 s 9 s 10 s 11 d dtype: object array(['q', 'w', 'e', 'r', 'a', 's', 'd'], dtype=object)
求 值频率 value_counts() :
pds.value_counts() #-----输出-----# s 5 a 2 d 1 w 1 r 1 q 1 e 1 dtype: int64
👆 返回一个新的Series ,计算出 值 出现的频率 。新的 Series 的索引就是原数据的值 。
成员资格 isin() :
pds = Series(np.arange(5,10)) pdt = DataFrame( { 'key1':list('ABCDEFG'), 'key2':np.arange(8,15) } ) #-----数据是这样的-----# 0 5 1 6 2 7 3 8 4 9 dtype: int32 key1 key2 0 A 8 1 B 9 2 C 10 3 D 11 4 E 12 5 F 13 6 G 14
isin() :
pds.isin([8,12]) #pds判断数组中是否出现包含 [8,12]的值, 是8和12 不是8到12。返回一个布尔值组成的新的DataFrame. pdt.isin(['A','G','H',7,8]) # 同上👆 # 👆 都会返回一个由布尔值组成的DataFrame #-----输出-----# 0 False 1 False 2 False 3 True 4 False dtype: bool key1 key2 0 True True 1 False False 2 False False 3 False False 4 False False 5 False False 6 True False
# count 计算非NAN值的数量 # describe 针对Series或各DataFrame列计算总统计值 # min/max 计算最大值、最小值 # idxmin、idxmax 计算能够获取到的最小值和最大值的索引位置(整数) # idxmin、idxmaxe'zui'da'zhi 计算能够获取到的最小值和最大值的索引值 # quantile 计算样本的分位数(0到1) # sum 值的总和 # mean 值的平均数 # median 值的中位数 # mad 根据平均值计算平均绝对距离差 # var 样本数值的方差 # std 样本标准偏差 # cumsum 样本值的累计和 # cummin、cummax 样本的累计最小值、最大值 # cumprod 样本值的累计积 # pct_change 计算百分数变化
字符串操作
文本数据的处理 , 针对字符串的API
# 示例数据 # st = Series(['A','b','C','bbhello','123',np.NaN,'hj','aa']) df = DataFrame({ 'key':list('abcdef'), 'key2':['hee','fv','w','hija','123',np.NaN] })
通过 .str 调用方法 :
st.str.count('b') # 统计没有元素含有的 'b' 的个数 0 0.0 1 1.0 2 0.0 3 2.0 4 0.0 5 NaN 6 0.0 7 0.0 dtype: float64
st.str.upper() #字符串大写 st.str.lower() #字符串小写 st.str.replace('A','aa') # 替换 自动过滤 NaN df.columns.str.upper() #列索引 大写 df.columns也是一个index对象
# str 运行结果 # st.str.upper() 0 A 1 B 2 C 3 BBHELLO 4 123 5 NaN 6 HJ 7 AA dtype: object 0 a # st.str.lower() 1 b 2 c 3 bbhello 4 123 5 NaN 6 hj 7 aa dtype: object 0 aa # st.str.replace('A','aa') 1 b 2 C 3 bbhello 4 123 5 NaN 6 hj 7 aa dtype: object Index(['KEY', 'KEY2'], dtype='object') # df.columns.str.upper()
字符串的索引 :
st.str[0] #拿到第一个字符 值的第一个 st.str[:3] #取前3个字符 ,和字符串本身索引方式相同 #-----输出-----# 0 A 1 b 2 C 3 b 4 1 5 NaN 6 h 7 a dtype: object 0 A 1 b 2 C 3 bbh 4 123 5 NaN 6 hj 7 aa dtype: object
字符串的常用方法(网络分享) :
# 1. 字符串拼接 + repr(str) 表达式 # 2.截取字符串 # 3.len()函数 # 4.split()方法 # 5.join()方法 # 6.count()方法 # 7.find()方法 # 8.index()方法 # 9.字符串对齐方法{ljust()、rjust()、center()} # 10. startwith() 和 endwith() # 11.字符串大小写转换(3种) # 12.去除字符串中空格及删除指定字符 # 13.format() 格式化输出方法 # 14.encode() 和 decode() 方法 # 15.dir() 和 help() 帮助函数 #网络资源 http://c.biancheng.net/python/str_method/ #如果没有了 ,自行百度 : Python 字符串的常用方法
合并 -- Merge
# merge() 语法 : pd.merge(left , right ,how='inner', on=None , left_on = None , right_on = None, left_index=False ,rigth_index=Flase, sort=True,suffixes=('_x','_y') ,copy = True , indicator=False)
(演示操作数据)
# 演示参数 df1 = DataFrame({ 'key':['k1','k2','k3','k4'], 'A':['a0','a1','a2','a3'], 'B':['b0','b1','b2','b3'] } ) df2 = DataFrame({ 'key':['k1','k2','k3','k4'], 'C':['c0','c1','c2','c3'], 'D':['d0','d1','d2','d3'] } ) df3 = DataFrame({ 'key1':['k1','k1','k2','k3'], 'key2':['k1','k2','k1','k2'], 'A':['a0','a1','a2','a3'], 'B':['b0','b1','b2','b3'] } ) df4 = DataFrame({ 'key1':['k1','k2','k2','k3'], 'key2':['k1','k1','k1','k1'], 'C':['c0','c1','c2','c3'], 'D':['d0','d1','d2','d3'] } )
key data1 0 a 0 1 b 1 2 c 2 3 d 3 4 e 4 5 f 5 6 h 6 data2 a 100 b 101 c 102 d 103 e 104 key1 key2 A B 0 k1 k1 a0 b0 1 k1 k2 a1 b1 2 k2 k1 a2 b2 3 k3 k2 a3 b3 key1 key2 C D 0 k1 k1 c0 d0 1 k2 k1 c1 d1 2 k2 k1 c2 d2 3 k3 k1 c3 d3
普通连接 :
pd.merge(df1,df2,on='key') # on 通过设置列 索引连接
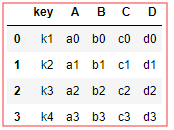
# 👆 此为一 一 对应连接,较简单,不做解释
多键连接 :
pd.merge(df3,df4,on=['key1','key2']) # on 设置列表 多键连接 [columns1,columns2]
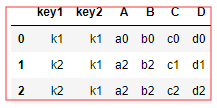
👆 解释 : 通过 第一张表(为主)的key1 和key2 的值 和第二张表(为副)的key1 和key2的值匹配
👆 如果都存在(key1和key2)则合并,如果(双方)都不存在 ,则不存在(为主的)的不要了,(副)的也不要了
合并连接方式 :
pd.merge(df3,df4,on=['key1','key2'],how='outer') # how 合并方式 inner 取交集 ,默认 outer 取并集 不匹配的值用NaN填充 # left 按左边参考 , rigth 按照右边参考 # 👆 全合并,重复填充,不存在NaN填充 print('------------------------\n',df3,'\n',df4) pd.merge(df3,df4,on=['key1','key2'],how='left') # 👆 #所有表的key1,key2的都合并,单个的key1,key2合并,(副)表没有的用NaN填充 下方结果(已折叠)
key1 key2 A B C D 0 k1 k1 a0 b0 c0 d0 1 k1 k2 a1 b1 NaN NaN # how ='outer' 2 k2 k1 a2 b2 c1 d1 3 k2 k1 a2 b2 c2 d2 4 k3 k2 a3 b3 NaN NaN 5 k3 k1 NaN NaN c3 d3 ------------------------ key1 key2 A B 0 k1 k1 a0 b0 1 k1 k2 a1 b1 # df3 2 k2 k1 a2 b2 3 k3 k2 a3 b3 key1 key2 C D 0 k1 k1 c0 d0 1 k2 k1 c1 d1 #df4 2 k2 k1 c2 d2 3 k3 k1 c3 d3 key1 key2 A B C D 0 k1 k1 a0 b0 c0 d0 1 k1 k2 a1 b1 NaN NaN # how='left' 2 k2 k1 a2 b2 c1 d1 3 k2 k1 a2 b2 c2 d2 4 k3 k2 a3 b3 NaN NaN
当键不为一个列时,两边的键索引不一致,如何合并,合并结果如何 :
df1 = DataFrame({'lkey':list('bbacaab'),'data1':range(7)})
df2 = DataFrame({'rkey':list('abd'),'data2':range(3)})
print(df1,'\n',df2)
pd.merge(df1,df2,left_on='lkey',right_on='rkey')
lkey data1
0 b 0
1 b 1
2 a 2
3 c 3
4 a 4
5 a 5
6 b 6
rkey data2
0 a 0
1 b 1
2 d 2
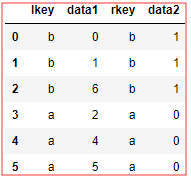
👆 左边 以 lkey 为准, 右边以 rkey 为准 默认会排序 ,如不想,设置sort 为False即可
👆 个人注解 : 全部一 一寻找合并,双表不存在的剔除,从上往下(副表)依次寻找合并 。
对于索引不同的数据 , 如何合并 ?
df1 = DataFrame({'key':list('abcdefh'),'data1':range(7)})
df2 = DataFrame({'data2':range(100,105)},index=list('abcde'))
key data1
0 a 0
1 b 1
2 c 2
3 d 3
4 e 4
5 f 5
6 h 6
data2
a 100
b 101
c 102
d 103
e 104
pd.merge(df1,df2,left_on='key',right_index=True) # 👆 left_index :参数为True时 ,左边的df以Index(行索引)为连接雄 # 👆 right_index :参数为True时 ,右边的df以Index(行索引)为连接雄 #所以 left_on,right_on,left_index ,right_index 可以相互组合 # left_on + right_on ,left_on + right_index, left_index+right_on ,left_index + right_index

按行连接 -- Join
pd.join() -----------------------------
left = DataFrame({ 'A':['A0','A1','A2'], 'B':['B0','B1','B2'] },index=['K0','K1','K2']) right = DataFrame({ 'C':['C0','C2','C3'], 'D':['D0','D2','D3'] },index=['K0','K2','K3']) left.join(right) # 默认是交集 how = inner ## 共同有的(索引index) 合并连接,不存在的值NaN填充
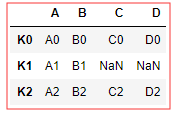
left.join(right,how='outer') # 默认是交集。 how = outer 全部合并 等同于 👇 pd.merge(left,right,left_index=True,right_index=True,how='outer') # 👈
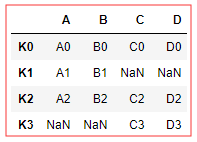
suffxies参数 对相同的键设置区分,取别名,不设置易混淆 :
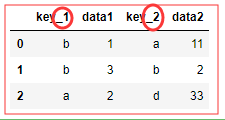
df1 = DataFrame({ 'key':list('bbacaab'), 'data1':[1,3,2,4,5,9,7] }) df2 = DataFrame({ 'key':list('abd'), 'data2':[11,2,33] }) key data1 0 b 1 1 b 3 2 a 2 3 c 4 4 a 5 5 a 9 6 b 7 key data2 0 a 11 1 b 2 2 d 33
pd.merge(df1,df2,left_index=True,right_index=True,suffixes=('_1','_2')) # suffixes
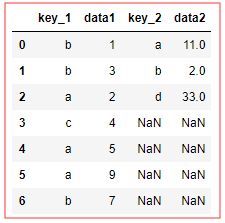
Join 连接 如上数据 如何设置?如下
df1.join(df2,lsuffix='_1',rsuffix='_2') # join 对于相同键重名名 l/r suffix ,其他参数一样
沿轴连接 Concat
有如下数据 , s1,s2,s3,s4
s1 = pd.Series([1,2,3]) s2 = pd.Series([2,3,4]) s3 = pd.Series([1,2,3],index=list('ach')) s4 = pd.Series([2,3,4],index=list('bed'))
0 1 1 2 2 3 dtype: int64 0 2 1 3 2 4 dtype: int64 a 1 c 2 h 3 dtype: int64 b 2 e 3 d 4 dtype: int64
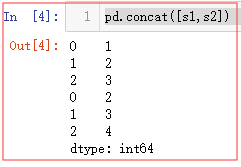
Concat 直接连接 ,合并 ,会返回一个新的 DataFrame
pd.concat([s1,s2]) #轴直接合并连接+到一起
Concat 参数(部分) axis sort jon 等
pd.concat([s3,s4],axis=1,sort=False) # concat axis=0 行+行 # 当axis = 1 时 就是列+列 默认NaN填充 需要设置sort False / True
# axis 0为行 / 1为列
# sort False / True 索引(index)排序
# join inner 交集 / outer 并集 . ## 其他参数 jupyter对方法按shift+2次table 查看 ##

s5 = pd.Series([1,2,3],index=['a','b','c']) s6 = pd.Series([2,3,4],index=['b','c','d']) print(pd.concat([s5,s6],axis=1,sort=True)) #join 默认为outer 取并集 pd.concat([s5,s6],axis=1,sort=True ,join='inner') #取交集
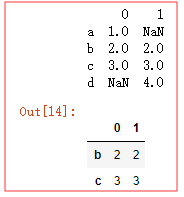
层次索引 ,多层次索引 ,上面的列 是 0 , 1 设置参数 keys 对列重明名 :
arr = pd.concat([s5,s6],keys=['one','two']) # keys : 指定列名称 print(arr) # 这是一个有层次索引的序列

arr['one']['a'] arr['one'].iloc[[0,1]] #取值方式 # 其他...
去重 和 替换
去重复 duplicated()
# 有以下数据 ser = Series([1,2,3,3,2,2,1,3,2,2,2,1,2]) ser.duplicated() # 返回一个 布尔值序列 对当前的值判断是否有重复,从开始判断到最后 # 下:输出
0 False 1 False 2 False 3 True 4 True 5 True 6 True 7 True 8 True 9 True 10 True 11 True 12 True dtype: bool
如何取出所有不重复或者重复的值呢?
ser[ser.duplicated()==False] # 索引不重复 !=False 为重复 或者 True

如何得到去除重复值的对象呢? 👉drop_duplicated()
ser1 =ser.drop_duplicates()
ser1

上面都是对一维数组的判断,多维数组的判断又是如何实现,怎样判断的???
如下 :
df = DataFrame({ 'key1':['a','a',3,4,5], 'key2':['a','a','b','b','c'] }) print(df) df.duplicated()

👆 多维数组是对整行 ,一条索引来进行判断,包括所有的列,也就是key1,ke2,........
👉 想对单列判断,把那列取出来判断即可 , 如 : df['key2'].duplicated()
替换 replace()
ser = Series(['a','b','c','c','d','e']) ser.replace('a','A') # 和字符串的替换方式一样 ,这是一次替换一个
普通替换,就和字符串一样。这是一次替换一个;

👉 那么如何一次替换多个值呢? 如下用列表的方式
ser.replace(['b','c'],np.NaN)

👉 还有一次性 多个 一对一替换,怎么实现? 字典 知道把 就是这样 你看:
ser.replace({'a':'小可爱','e':'大可爱','c':'I like you'})

暂时就这些,如想获取更多,请自行百度,3Q

 浙公网安备 33010602011771号
浙公网安备 33010602011771号