

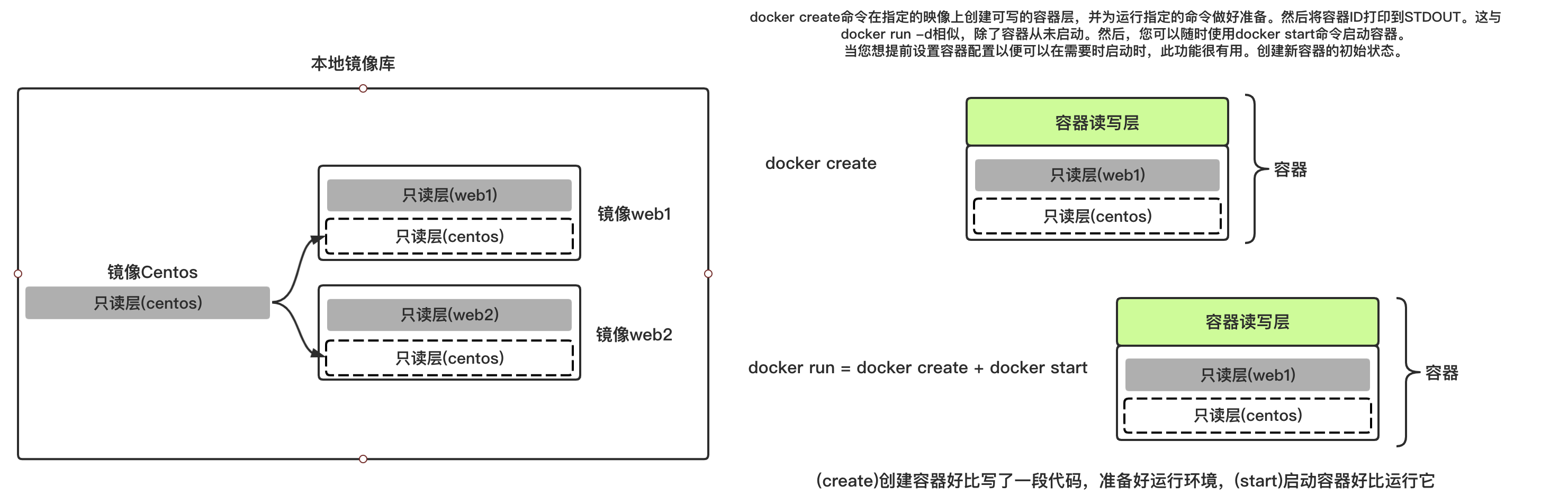
容器化-Docker-5-Docker容器
Docker容器管理(操作对象是容器)
容器启停 启停管理
- 通过一个镜像创建一个容器
- 查看已启动的容器列表
- 启、停、重启已经在容器列表的容器
- 查看容器使用的资源
- 删除在管理列表里的images
通过一个镜像创建一个容器
# 如果本地不存images会向远程仓库获取
docker run -itd --name=nginx1 --rm -p 8081:80 -v /work/nginx1/log:/var/log/nginx --cpus=4 -m=8g docker.io/nginx
# 常用参数 -itd --name -p
"""
-i: 以交互模式运行容器,通常与 -t 同时使用;
-t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;
-d: 后台运行容器,并返回容器ID;
--name=nginx1为启动的容器起一个名称,可以用它来操作容器不用使用容器id了
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
--cpus: 指定容器最大使用多少个cpu(不能超过主机上CPU数)
-m: 指定容器最大使用多少内存3g
后面跟镜像名称
"""
查看已启动的容器列表
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
68a268ed5113 docker.io/redis "docker-entrypoint..." 15 hours ago Up 15 hours 0.0.0.0:6379->6379/tcp redis-test
"""
CONTAINER ID: 容器 ID。
IMAGE: 使用的镜像。
COMMAND: 启动容器时运行的命令。
CREATED: 容器的创建时间。
STATUS: 容器状态。
状态有7种:
created(已创建)
restarting(重启中)
running(运行中)
removing(迁移中)
paused(暂停)
exited(停止)
dead(死亡)
"""
启、停、重启、删除 已经在容器列表的容器
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
68a268ed5113 docker.io/redis "docker-entrypoint..." 16 hours ago Up 2 minutes 0.0.0.0:6379->6379/tcp redis-test
# docker ps -a 展示所有容器列表的信息包含已经停止的
[root@localhost ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e080292abd47 docker.io/nginx "nginx -g 'daemon ..." 35 seconds ago Exited (0) 5 seconds ago nginx-test
68a268ed5113 docker.io/redis "docker-entrypoint..." 16 hours ago Up 2 minutes 0.0.0.0:6379->6379/tcp redis-test
[root@localhost ~]#
# 启动已停止的容器
docker start e080292abd47
# 停止已启动的容器
docker stop 68a268ed511
# 重启已启动的容器(容器容器已停止的话直接拉起)
docker restart e080292abd47
# 从容器列表删除已停掉的容器
docker rm e080292abd47
# 从容器列表中删除已经启动的容器,加-f强制删除
docker rm -f 68a268ed5113
# 从容器列表中删除所有已经停掉的所有容器
docker container prune
如何进入退出容器
Docker是进程的容器必须启动一个前台任务
- 启用一个交互终端
- 直接进入启动的daocker容器内不再开启一个终端(不推荐很容易误操作退出)
# 打开一个交互式的shell
docker exec -it a82cf07ddc39 "/bin/bash"
# 直接进入容器,如果exit会退出
# Docker attach可以attach到一个已经运行的容器的stdin,然后进行命令执行的动作。
# 但是需要注意的是,如果从这个stdin中exit,会导致容器的停止。
docker attach centos
# 可以使用组合键 Ctrl + p + q 按住Ctrl 和 p不放在按q就退出容器了,不会关闭容器
查看容器使用的资源
[root@localhost ~]# docker stats --no-stream
CONTAINER CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
a82cf07ddc39 0.19% 8.375 MiB / 972.6 MiB 0.86% 656 B / 656 B 0 B / 0 B 4
[CONTAINER]:容器ID
[CPU %]:CPU 百分比的使用情况。
[MEM USAGE / LIMIT]:当前使用的内存和最大可以使用的内存。
[MEM %]:以百分比的形式显示内存使用情况。
[NET I/O]:网络 I/O 数据。
[BLOCK I/O]:磁盘 I/O 数据。
[PIDS]:PID号
inspect 检查容器或者镜像相关信息
json对象
jq 是一个json格式化工具 yum install -y jq 安装下就成
docker没有提供这个json美化功能
[@hbhly_SG11_176_84 ~]# docker inspect web1 -f '{{json .Mounts}}'|jq
[
{
"Type": "volume",
"Name": "volume_web1",
"Source": "/var/lib/docker/volumes/volume_web1/_data",
"Destination": "/online",
"Driver": "local",
"Mode": "z",
"RW": true,
"Propagation": ""
}
]
list
如果是一个列表的话先获取到索引在获取json
[@hbhly_SG11_176_84 ~]# docker inspect web1 -f '{{json (index .Mounts 0).Name}}'
"volume_web1"
模糊检索
从某个范围内取出某个值
docker inspect web1 -f '{{range .Mounts}} {{.Name}} {{end}}'
组合格式化输出
[@hbhly_SG11_176_84 ~]# docker inspect web1 -f '{{json .NetworkSettings.Ports}}' |jq
{
"8080/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "80"
}
],
"8081/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "81"
}
]
}
[@hbhly_SG11_176_84 ~]# docker inspect -f '{{range $p, $conf := .NetworkSettings.Ports}} {{$p}} -> {{(index $conf 0).HostPort}} {{end}}' web1
8080/tcp -> 80 8081/tcp -> 81
# 解释$p, $conf := .NetworkSettings.Ports 这里命名了两次值
# {{$p}} -> {{(index $conf 0).HostPort}} 这里格式化输出了下
容器数据持久存储(docker volume)
docker 镜像是以 layer 概念存在的,一层一层的叠加,最终成为我们需要的镜像。但该镜像的每一层都是 ReadOnly 只读的。只有在我们运行容器的时候才会创建读写层。文件系统的隔离使得:
- 容器不再运行时,数据将不会持续存在,数据很难从容器中取出。
- 无法在不同主机之间很好的进行数据迁移。
- 数据写入容器的读写层需要内核提供联合文件系统,这会额外的降低性能。
数据卷
主机卷
直接指定本地的一个目录和容器内的目录做一个bind
docker run -itd --rm --name=web1 -v /work/web1:/work/web1 web bash
# 查看
docker inspect web1 -f '{{json .Mounts}}' |jq
[
{
"Type": "bind",
"Source": "/work/web1",
"Destination": "/work/web1",
"Mode": "",
"RW": true,
"Propagation": "rprivate"
}
]
[@hbhly_SG11_176_84 volumes]#
匿名卷
不指定卷名
docker run -itd --rm --name=web2 -v /work/web2 web bash
# 查看
docker inspect web2 -f '{{json .Mounts}}' |jq
[
{
"Type": "volume",
"Name": "91c1e48918d782505cebb3b3cfa4cd0ff4ddd756b4d664759f4a914feddc0c78",
"Source": "/var/lib/docker/volumes/91c1e48918d782505cebb3b3cfa4cd0ff4ddd756b4d664759f4a914feddc0c78/_data",
"Destination": "/work/web2",
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
]
创建一个数据卷,然后让容器使用
命名卷
先创建一个数据卷可以指定,数据卷的大小、名称等相关信息
[@hbhly_SG11_176_84 volumes]# docker volume create --name=web3 -o o=size=100m
web3
[@hbhly_SG11_176_84 volumes]# docker volume ls
DRIVER VOLUME NAME
local 91c1e48918d782505cebb3b3cfa4cd0ff4ddd756b4d664759f4a914feddc0c78
local web3
[@hbhly_SG11_176_84 volumes]# docker volume inspect web3
[
{
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/web3/_data",
"Name": "web3",
"Options": {
"o": "size=100m"
},
"Scope": "local"
}
]
[@hbhly_SG11_176_84 volumes]#
三者有什么区别,匿名卷和命名卷都可以通过Docker Cli进行管理
docker volume help
但是它只能放在/var/lib/docker/volumes/ 就比较恶心了
备注下:Docker File里指定的Volums使用的是匿名卷
Docker容器网络配置
常用的网络知识
常用的网络类型有两个:
- bridge/nat 在linux叫bridge在windows叫nat
- host直接用主机的网络
默认的叫bridge和host,当然你也可以自己创建新的网络
名称为:my_network_nat 类型为bridge或nat 或者host都行
容器支持的网络模式有:
- bridge/nat 在linux叫bridge在windows叫nat,默认模式最常用基本上这个就够了
- host 容器与主机相同的 network namespace,在这种情况下,访问主机端口就能访问容器
- overlay : 借助 docker 集群模块 docker swarm 来搭建的跨 docker daemon 网络,可以通过它搭建跨物理主机的虚拟网络,进而让不同物理机中运行的容器感知不到多个物理机的存在
- macvlan :docker 主机网卡接口逻辑上分为多个子接口,每个子接口标识一个 vlan。容器接口直接连接 docker 主机网卡接口,通过路由策略转发到另一台 docker 主机。
- none : 禁用所有网络。通常与自定义网络驱动程序一起使用。此模式下创建容器是不会为容器配置任何网络参数的,如:容器网卡、IP、通信路由等,全部需要自己去配置。这也给喜欢自己玩的用户更大的自由度
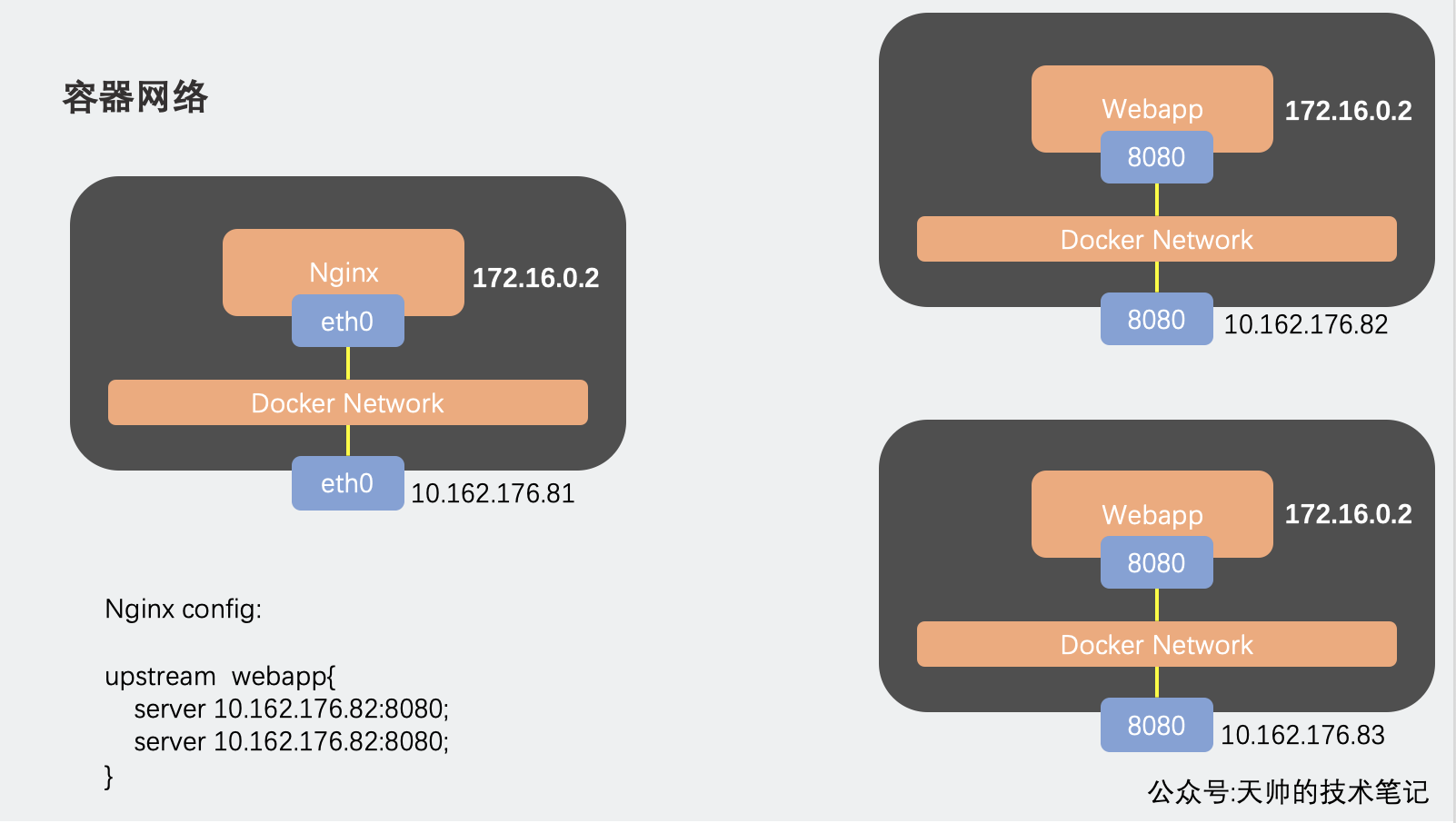
我们最常用的bridge/nat如下图

在安装Docker时,会自动安装一块Docker网卡称为docker0,用于Docker各容器及宿主机的网络通信,网段为172.0.0.1。
ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
ether 02:42:aa:85:f0:d5 txqueuelen 0 (Ethernet)
RX packets 271795 bytes 16005013 (15.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 311995 bytes 896796913 (855.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
容器内部的请求都会请求到docker0,然后通过IPTABLES转发请求到外面
端口映射
端口映射默认就使用的bridge/nat网络
docker run -itd --rm --name=web1 -p 80:8080 --cpus=4 -m=8g docker.io/busybox
容器互联(单机)
bridge/nat模式默认都是单机网络,只能和本主机内的通网络内容器通信和互联
只有使用第三方的模块才容器网段(172.17.0.2/16)可以跨主机通信
容器网络实现
容器网络实质上也是由Docker为应用程序所创造的虚拟环境的一部分,它能让应用从宿主机操作系统的网络环境中独立出来,形成容器自有的网络设备、IP协议栈、端口套接字、IP路由表、防火墙等等与网络相关的模块。
Docker 网络架构源自一种叫作容器网络模型(CNM)的方案,该方案是开源的并且支持插接式连接。
Libnetwork 是 Docker 对 CNM 的一种实现,提供了 Docker 核心网络架构的全部功能。不同的驱动可以通过插拔的方式接入 Libnetwork 来提供定制化的网络拓扑。
一般情况下,Docker创建一个容器的时候,会具体执行如下操作:
1.创建一对虚拟接口,分别放到本地主机和新容器的命名空间中;
2.本地主机一端的虚拟接口连接到默认的docker0网桥或指定网桥上,并具有一个以veth开头的唯一名字,如vethxxxx;
3.容器一端的虚拟接口将放到新创建的容器中,并修改名字作为eth0。这个接口只在容器的命名空间可见;
4.从网桥可用地址段中获取一个空闲地址分配给容器的eth0(例如172.17.0.2/16),并配置默认路由网关为docker0网卡的内部接口docker0的IP地址(例如172.17.42.1/16)。
完成这些之后,容器就可以使用它所能看到的eth0虚拟网卡来连接其他容器和访问外部网络。用户也可以通过docker network命令来手动管理网络。
# 启动一个容器,默认就使用的bridge
docker run -itd --rm --name=shbox docker.io/busybox sh
#
docker network inspect bridge -f '{{json .Containers}}' |jq
{
"1b2a0d7c9c867c6727551312174f441d20ec808f74d7547eced9ec94073a9f48": {
"Name": "shbox",
"EndpointID": "fbf53032d57bfab60add074154a2e6748a3c474d0a3ddb0b7e9c10e5cf872ce3",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
}
容器互联解决方案
1 通过反向代理
容器通过bridge/nat模式默认可以访问外部网络,通过端口映射服务也可以被外部访问,举例
Docker容器资源控制(操作对象是容器)
一个Docker主机上会运行若干容器,每个容器都需要 CPU、内存、IO资源。对于 KVM,VMware等虚拟化技术,用户可以控制分配多少CPU、内存资源给每个虚拟机。
对于容器,Docker 也提供了类似的机制避免某个容器因占用太多资源而影响其他容器乃至整个 host 的性能。
常用的就是:
- 限制容器使用最大CPU核数为2.5核 --cpus 2.5 (docker 1.13后新增,简单直观,比cpu share强,一眼就知道它用几个CPU)
- 限制容器使用最打内存大小为3G -m 3G
下面的看下有印象,用到的时候知道在哪里找就成
CPU资源限制
默认设置下,所有容器可以平等地使用 host CPU 资源并且没有限制。
| 选项 | 描述 | 例子 |
|---|---|---|
| --cpus | 容器可以使用最大CPU数docker1.13新增更简单直接,取值范围根据实际机器上使用不能超过主机CPU数 | --cpus=8 |
| --cpuset-cpus | 设定容器在那个CPU上运行取值范围根据机器上CPU数量 | --cpuset-cpus=0-3,4,7 |
| -c,--cpu-shares | 容器使用CPU权重,默认值为1024数字越大权重越高 | -c=512 |
| --cpu-period and --cpu-quota | 这俩一般一起用限制 CPU CFS 配额 | --cpu-period=100000 --cpu-quota=50000 |
--cpus
在之前使用--cpu-shares 或者 --cpu-period and --cpu-quota 一眼看过去根本不知道它到底使用了多少CPU资源,docker1.13新增了--cpus就改观很多了
指定一个容器可以使用多少可用的CPU资源。例如,如果主机有两个CPU,并且您设置了--cpus =“ 1.5”,则该容器最多可保证有一半CPU。这等效于设置--cpu-period =“ 100000”和--cpu-quota =“ 150000”。
--cpuset-cpus
设定容器在那个CPU上运行取值范围根据机器上CPU数量
-c,--cpu-shares CPU 资源的相对限制
--cpu-shares,默认情况下所有容器的权重是相同的(1024),也就是所有容器有相同的权重,在所有容器一起竞争资源时,最终得到的资源是相同的。
这个share是一个相对的值,那么这个值的意义就不能单纯的通过一个容器的share值来看,而是多个在一起对比,比如A和B两个容器,A配置的是1024,B配置的是512,那么A最大可以使用的CPU资源是B的两倍。还有一点要注意的是这种配置是有弹性的,如果A容器一直闲着,那B容器是可以使用空闲资源的。
--cpu-period and --cpu-quota (CPU 资源的绝对限制)
Linux 通过 CFS(Completely Fair Scheduler,完全公平调度器)来调度各个进程对 CPU 的使用。CFS 默认的调度周期是 100ms。
--cpu-period and --cpu-quota 和 --cpu-shares 取前面的绝对值,因为--cpu-shares是相对的,当资源空闲的时候还是会使用空闲资源
MEM资源限制
默认情况下如果容器程序内存溢出的话会吃掉主机的所有的内存,所以有必要对它进行容量的限制
| 选项 | 描述 | 例子 |
|---|---|---|
| -m or --memory= | 设置容器最大使用内存最小值是4M | -m=4m |
| --memory-swap | 设置容器使用的swap大小 | --memory-swap=1g |
| --memory-reservation | 内存软限制,正常情况下没啥用,只有内存紧张的时候有用 | -memory-reservation=800m |
| --oom-kill-disable | 阻止容器杀死容器 | --oom-kill-disable=true or --oom-kill-disable |
-m or --memory=
设置容器使用内存最大为多少,它的最小值是4M最大值根据实际的主机内存大小
--memory-swap=
swap的计算公式是 (--memory-swap)值减去(-m or --memory=)的值
比如: -m=300m --memory-swap=1g 那么swap的空间为1g-300m=700M
如果设置了-m=300m 没有设置--memory-swap=那么,容器将会使用600m空间,没错swap的大小和-m的值一样
--memory-reservation
docker run -itd --name=web1 -p 8080:80 -m 1g --memory-reservation=800m web
如上比如设定了最大内存为1g,正常情况下可以使用1g的内存,但是内存紧张的时候,系统会尝试回收内存,尝试回收web1的内存让它只是用800m,这个是尝试能回收就回收不能回收还是可以使用1g内存
--oom-kill-disable
注意使用这个参数必须使用-m,否则会把docker本身的dameon进程干掉,也会有提示
[@xxxx ~]# docker run -itd --name=web1 --oom-kill-disable=true aa68ec85d109
WARNING: Disabling the OOM killer on containers without setting a '-m/--memory' limit may be dangerous.
一般一个容器只有一个进程,这个唯一进程被杀死,容器也就被杀死了。我们可以通过--oom-score-adj选项来设置在系统内存不够时,容器被杀死的优先级。负值更教不可能被杀死,而正值更有可能被杀死。
不过建议还是慎用--oom-kill-disable和--oom-score-adj选项,异常的程序应该是被系统干掉,在去优化它
--kernel-memory
内核内存从根本上不同于用户内存,因为内核内存无法交换出去。无法交换使得容器可以通过消耗过多的内核内存来阻止系统服务。内核内存包括:
- stack pages
- slab pages
- sockets memory pressure
- tcp memory pressure
可以通过设置核心内存限制来约束这些内存。例如,每个进程都要消耗一些栈页面,通过限制核心内存,可以在核心内存使用过多时阻止新进程被创建。
核心内存,进程创建管理都需要申请核心内存
场景一:如果程序只设置了核心内存限制的话
docker run -itd —name=web1 —kernel-memory=1g web
当你创建的子进程太多的话就不让你创建子进程了
那什么时候回使用-m 和 —kernel-memory呢,一般是调试的时候使用的更多一些
* 如果同时定义了-m=3g —kernel-memory=2g 当前K<U ,这时候如果使用内核空间太多的话就会触发OOM
* 如果-m=3g —kernel—memory=4g的话 K>U 只有-m会触发oom
一般情况下用不到了解下就成
磁盘I/O限制
相对于CPU和内存的配额控制,docker对磁盘IO的控制相对不成熟,大多数都必须在有宿主机设备的情况下使用。主要包括以下参数:
–device-read-bps:限制此设备上的读速度(bytes per second),单位可以是kb、mb或者gb。
–device-read-iops:通过每秒读IO次数来限制指定设备的读速度。
–device-write-bps :限制此设备上的写速度(bytes per second),单位可以是kb、mb或者gb。
–device-write-iops:通过每秒写IO次数来限制指定设备的写速度。
–blkio-weight:容器默认磁盘IO的加权值,有效值范围为10-100。
–blkio-weight-device: 针对特定设备的IO加权控制。其格式为DEVICE_NAME:WEIGHT
例子:
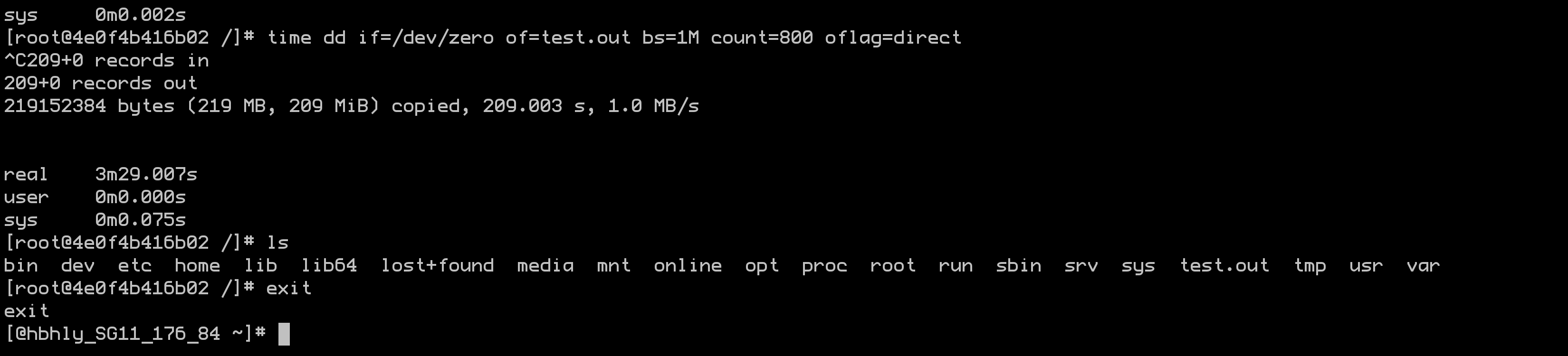
docker run -tid --name=d1 --device-write-bps=/dev/vda:1mb web
测试:
time dd if=/dev/zero of=test.out bs=1m count=800 oflag=direct
官方文档:https://docs.docker.com/engine/reference/commandline/run/


