
Redis
什么是Redis???
Redis的全称是 远程字典服务(Remote dictionary server ),Redis是一个开源的,使用C语言的编写的,支持网络交互的,可基于内存
也可持久化的key-value数据库(不仅仅是一个数据库)
为什么要使用Redis???
1.redis是基于内存的,内存的读写速度非常快(纯内存); 数据存在内存中,数据结构用HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)。
2.redis是单线程的,省去了很多上下文切换线程的时间(避免线程切换和竞态消耗)。
3.redis使用IO多路复用技术(IO multiplexing, 解决对多个I/O监听时,一个I/O阻塞影响其他I/O的问题),可以处理并发的连接(非阻塞IO)。
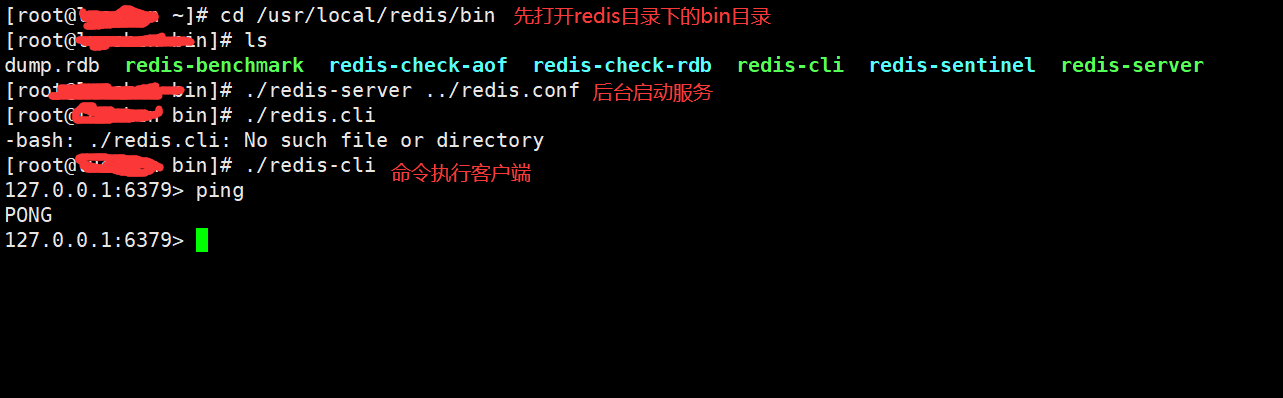
1.先安装好Redis(网上有详细教程)
2.启动Redis服务(建议使用后台启动Redis)
五大基本结构
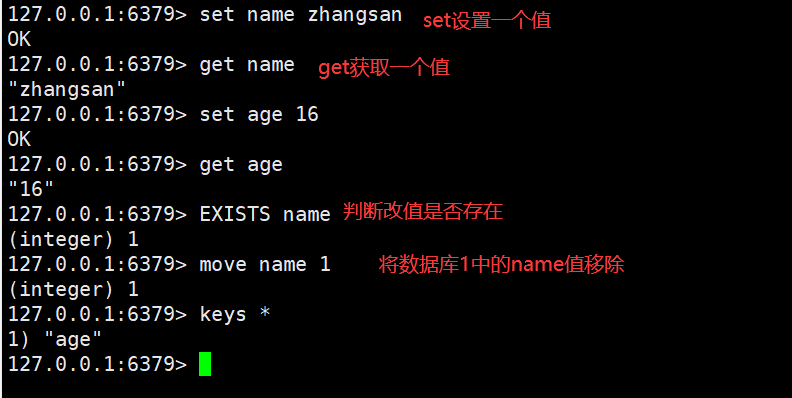
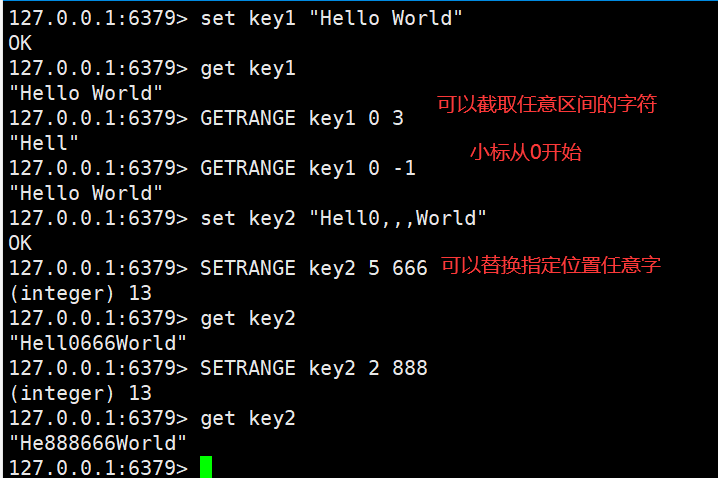
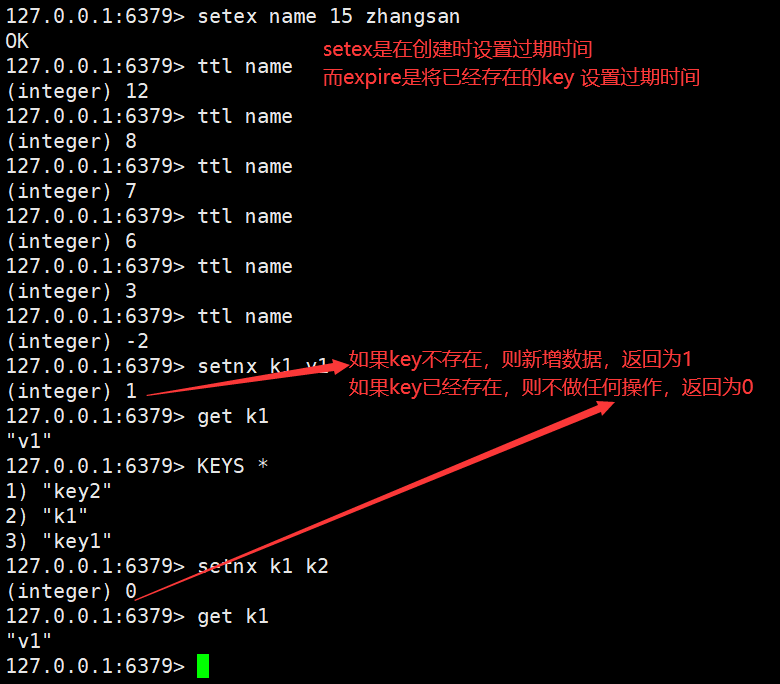
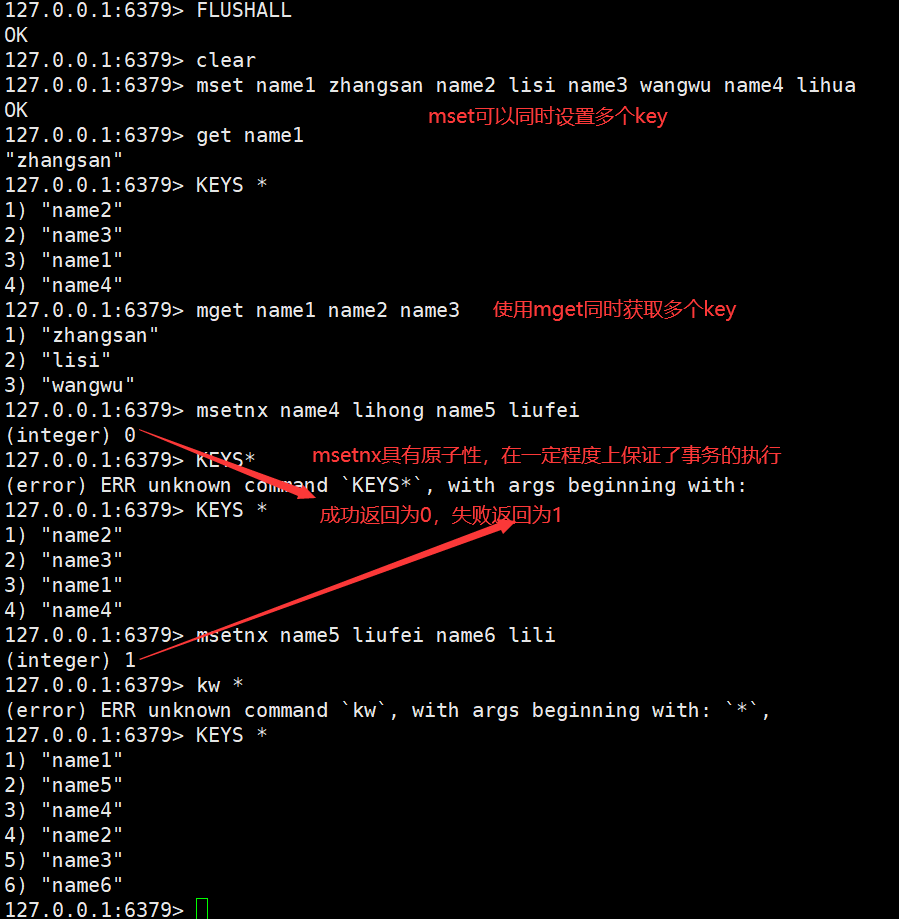
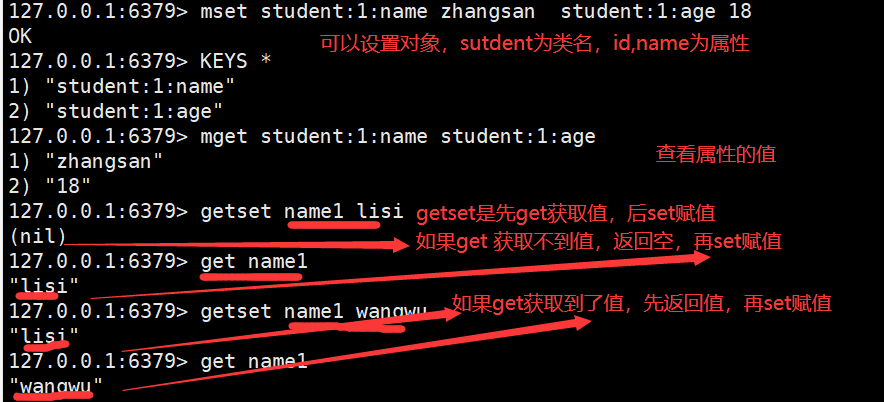
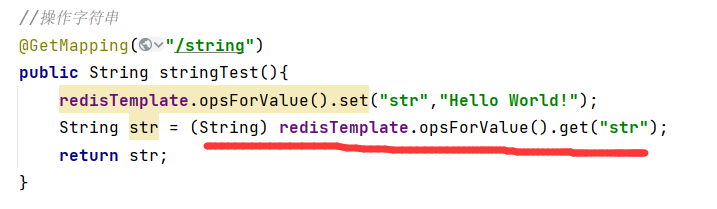
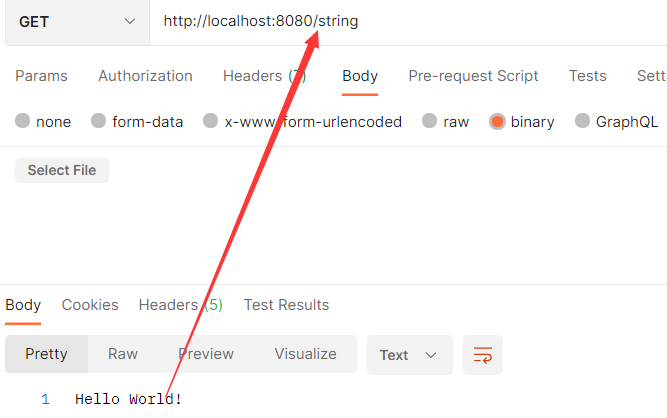
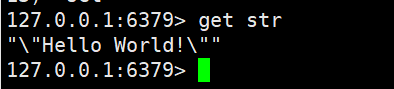
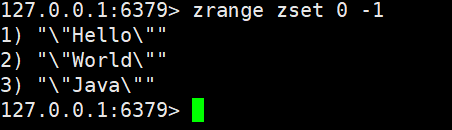
String(字符串是我们最常用的数据结构)
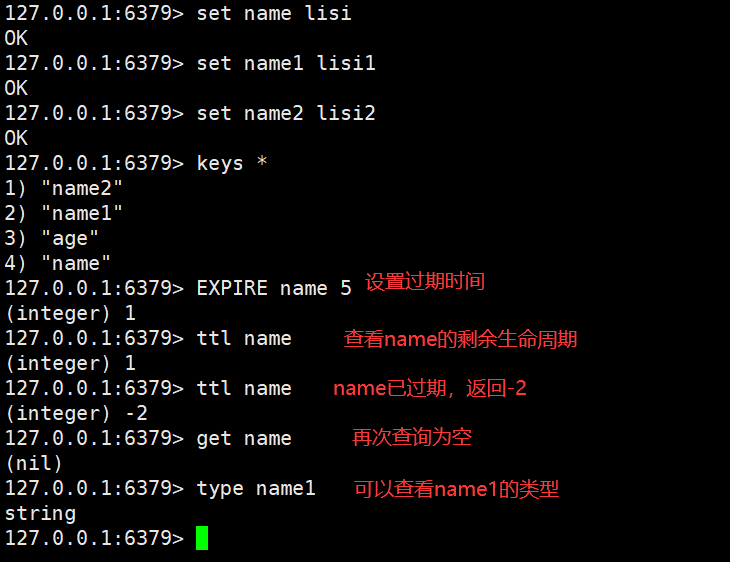
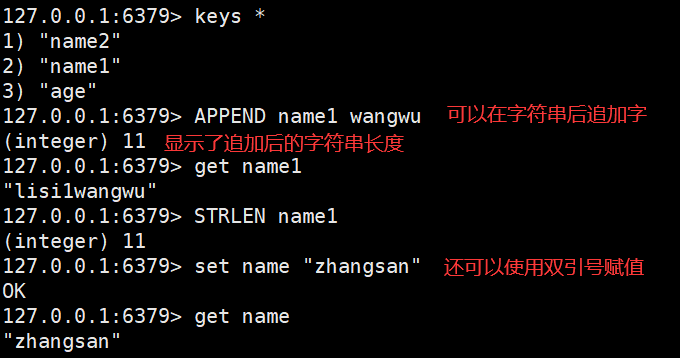
注意使用双引号赋值时可以有空格,但必须在双引号里面,不然会报错

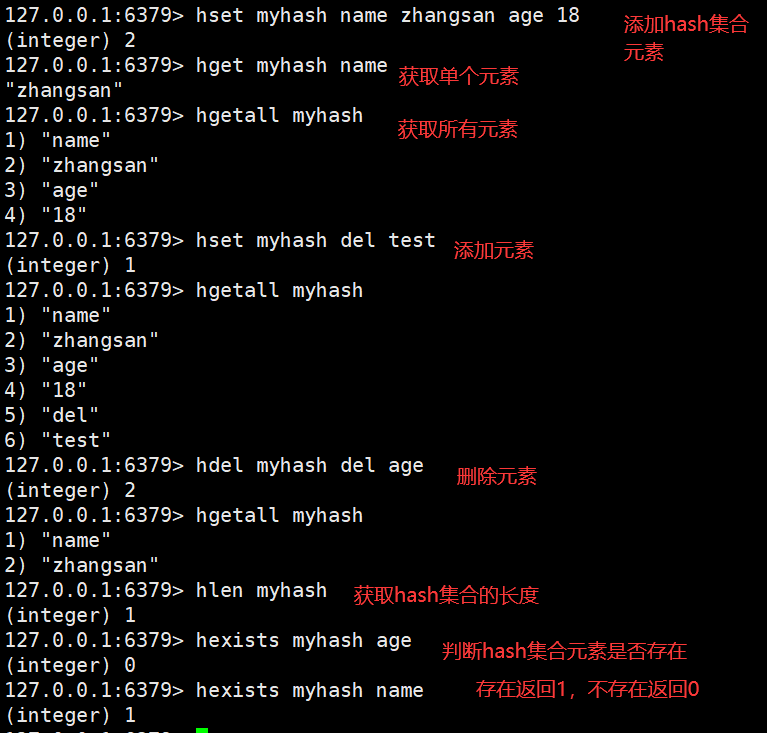
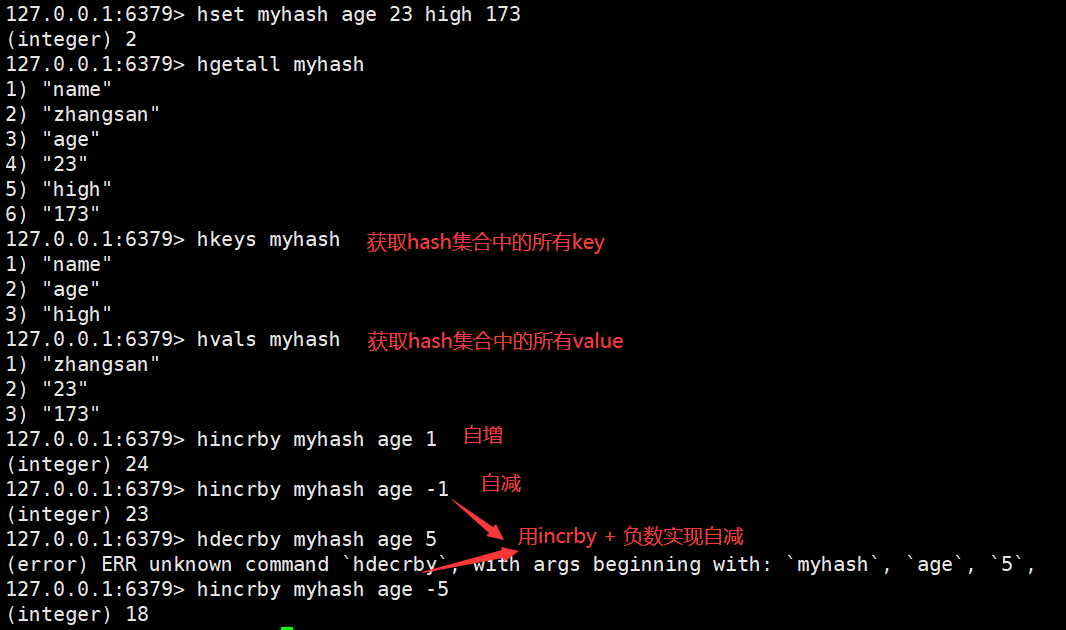
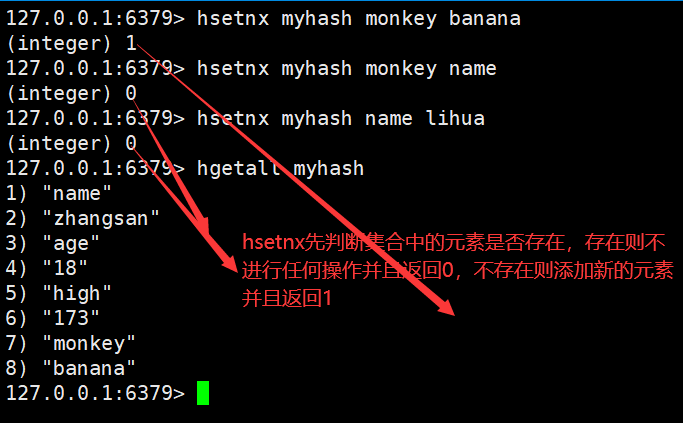
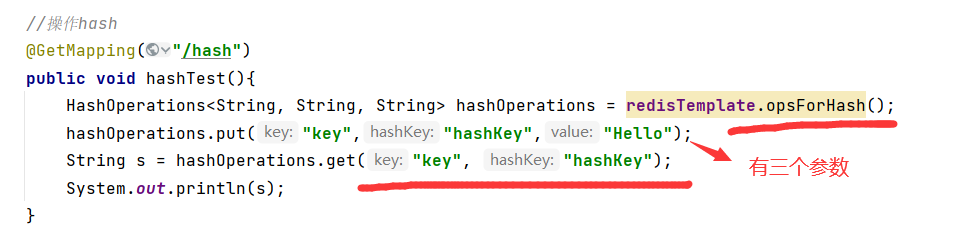
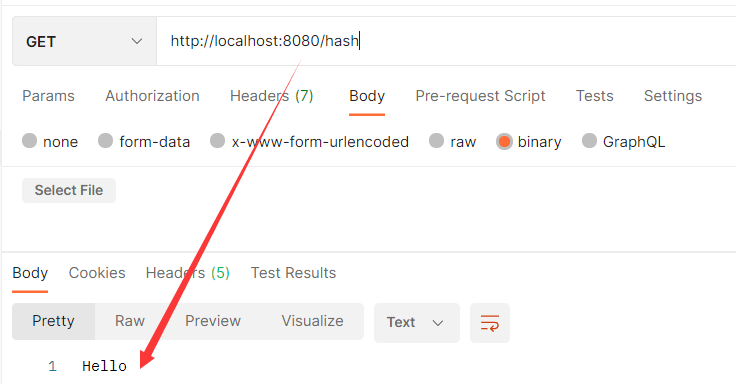
Hash(哈希散列)
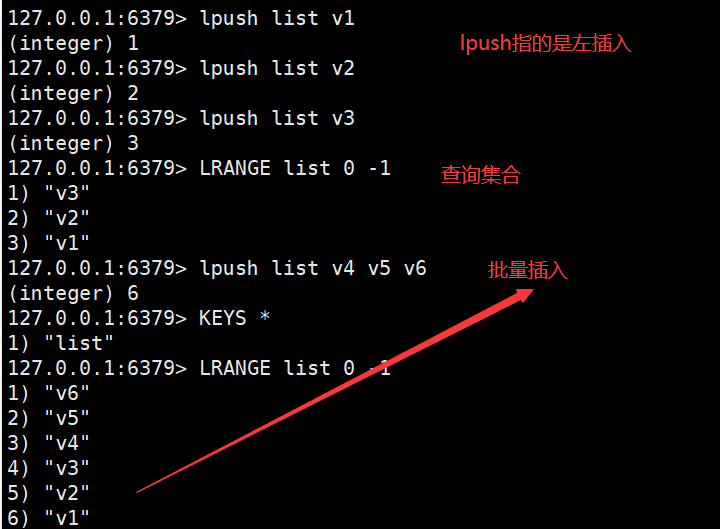
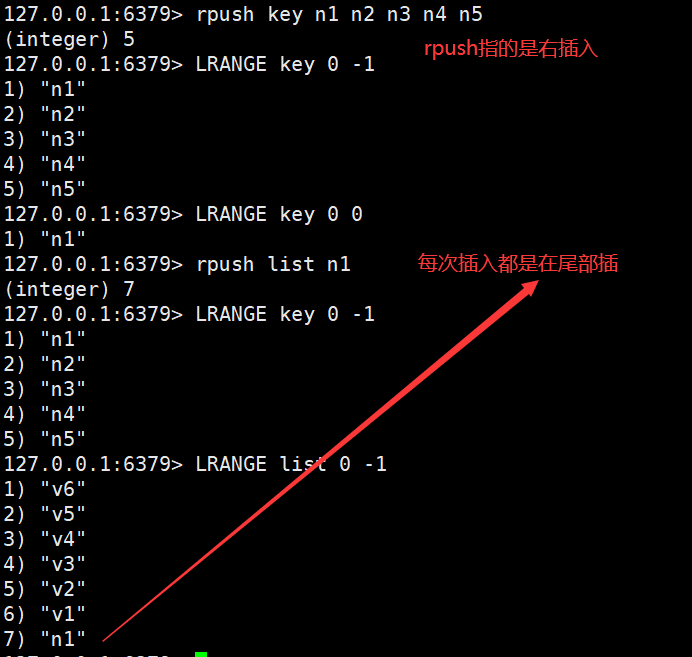
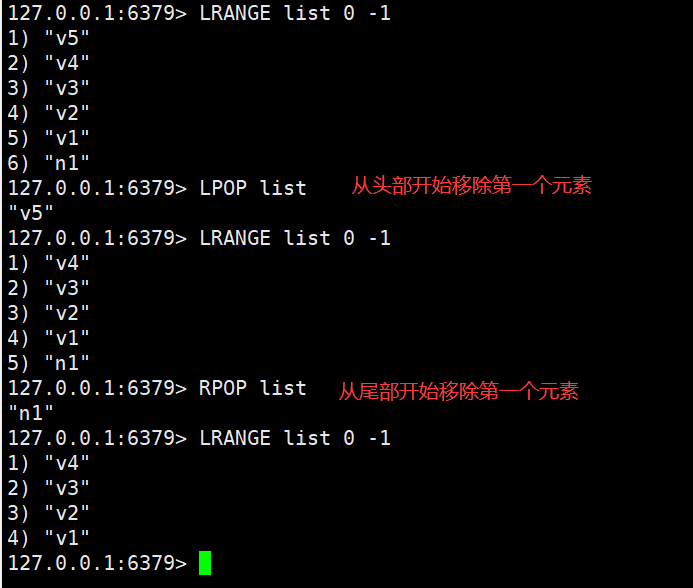
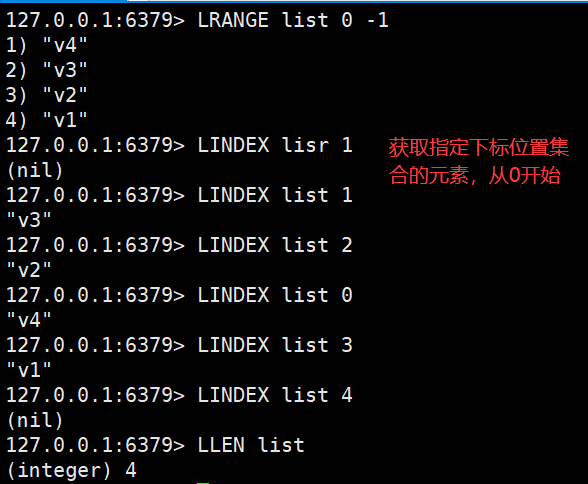
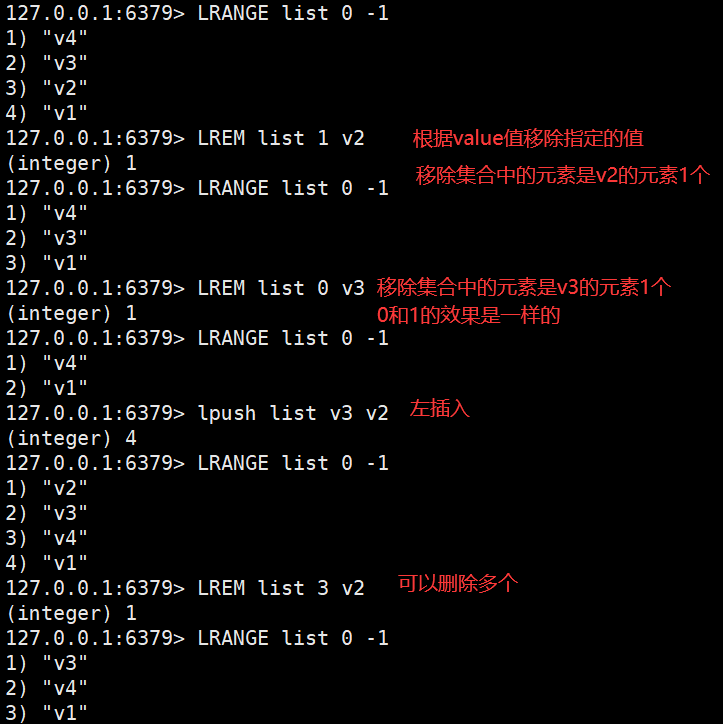
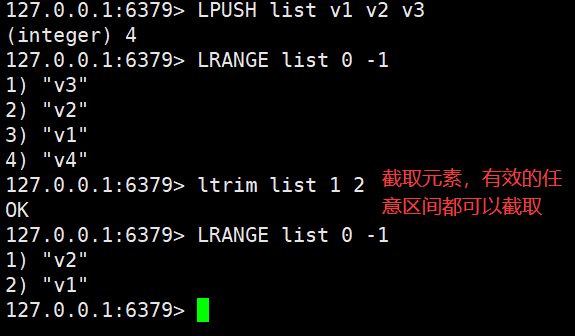
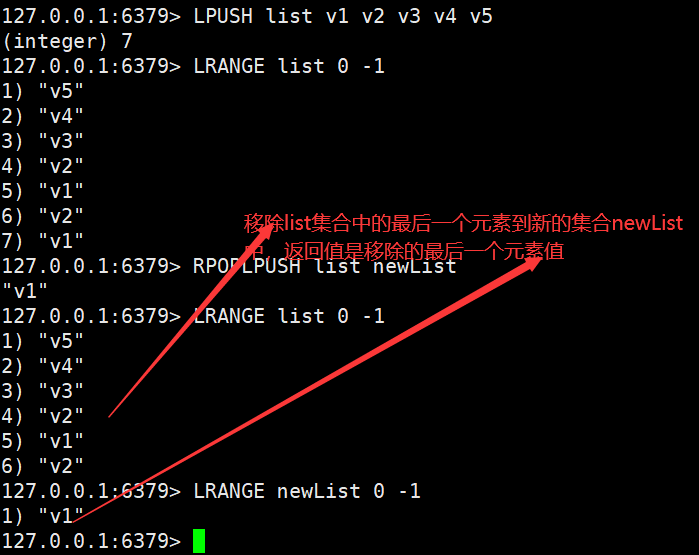
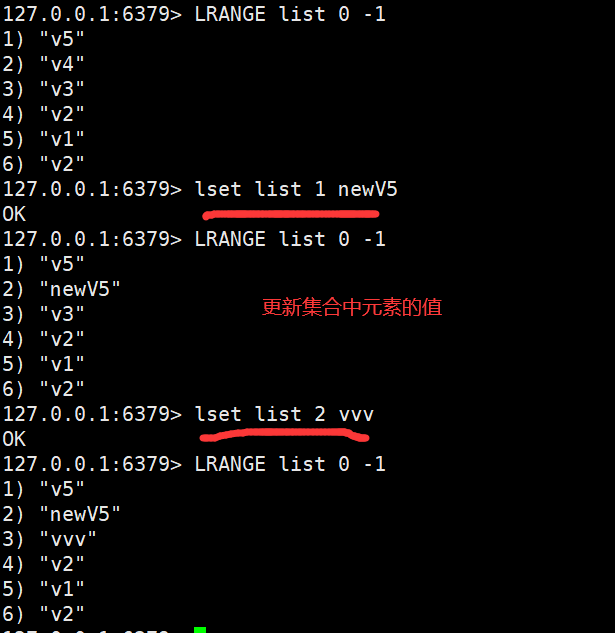
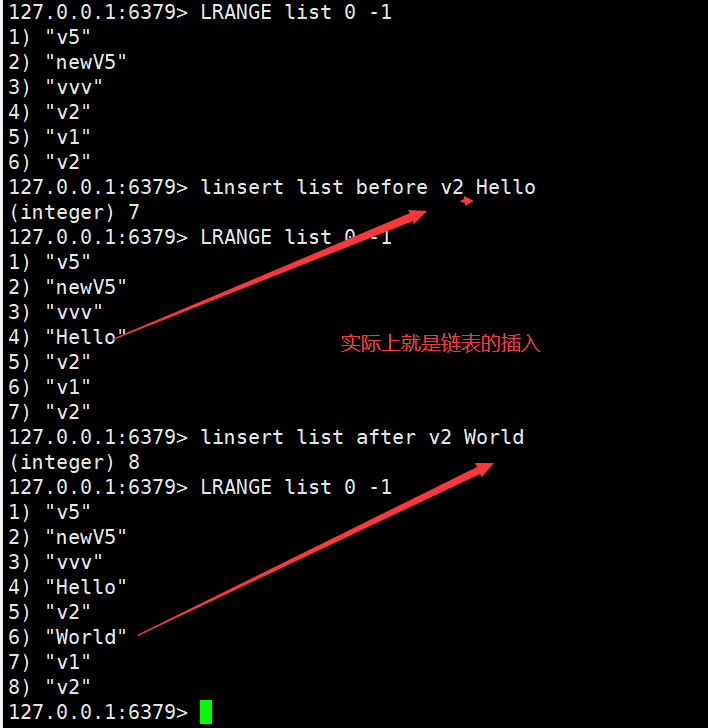
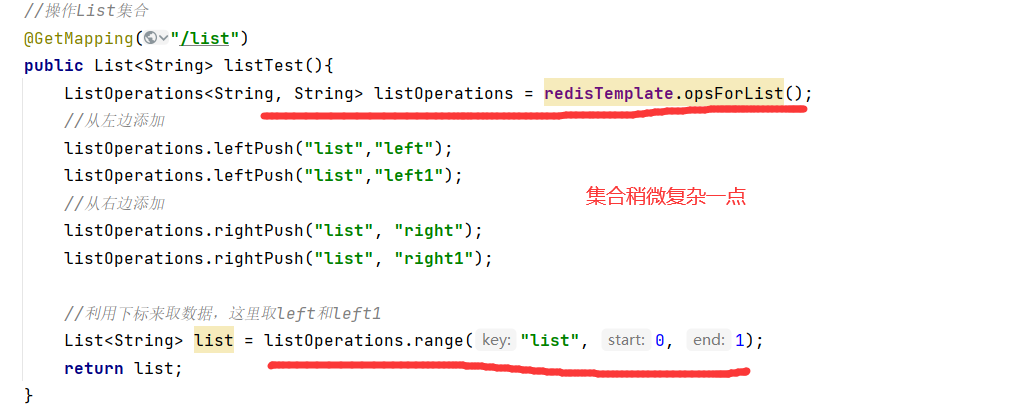
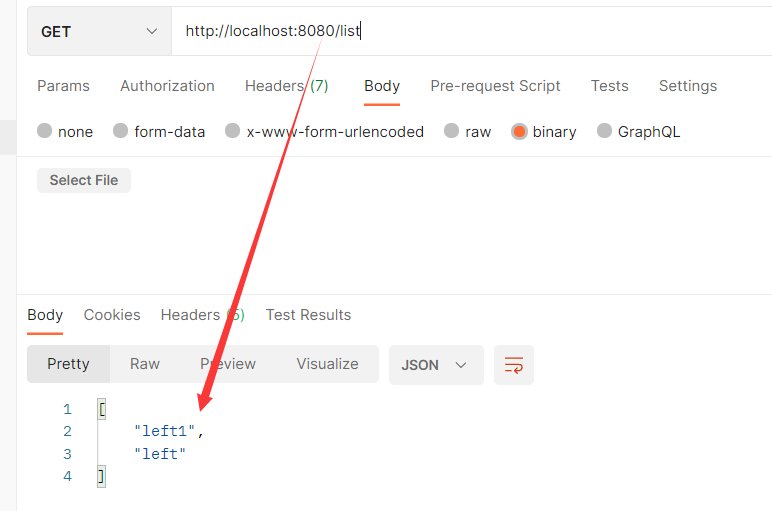
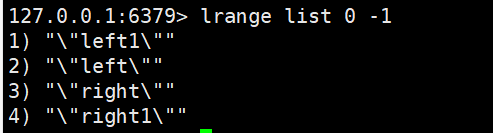
List
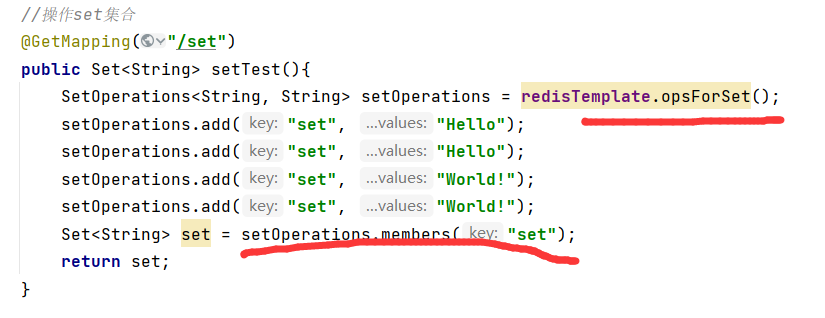
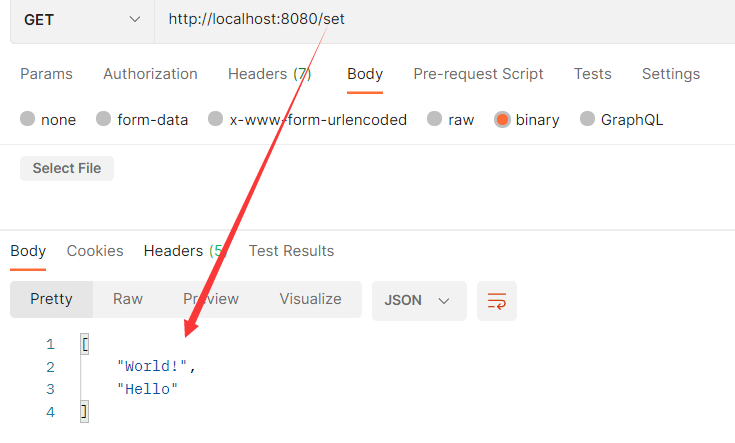
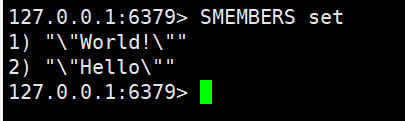
Set(跟List集合类似,但Set集合中的所有元素都是唯一的,不重复)
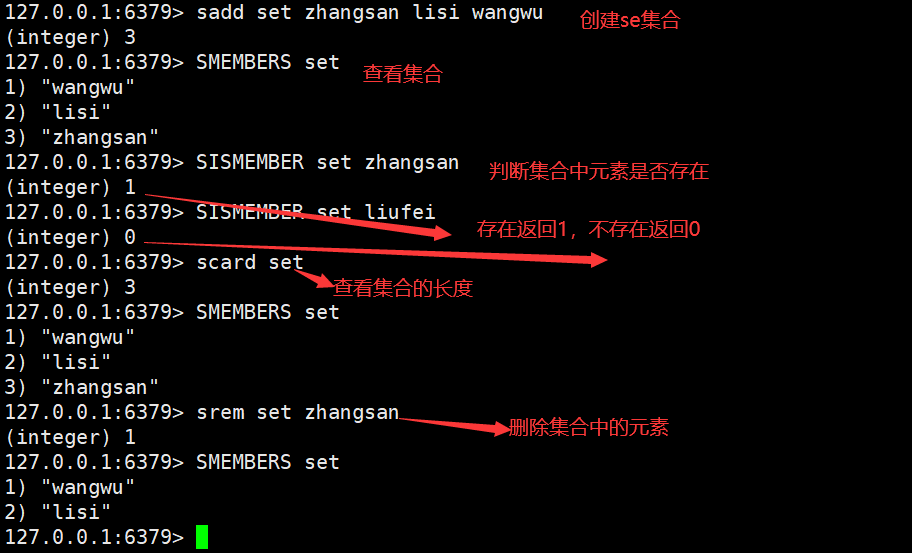
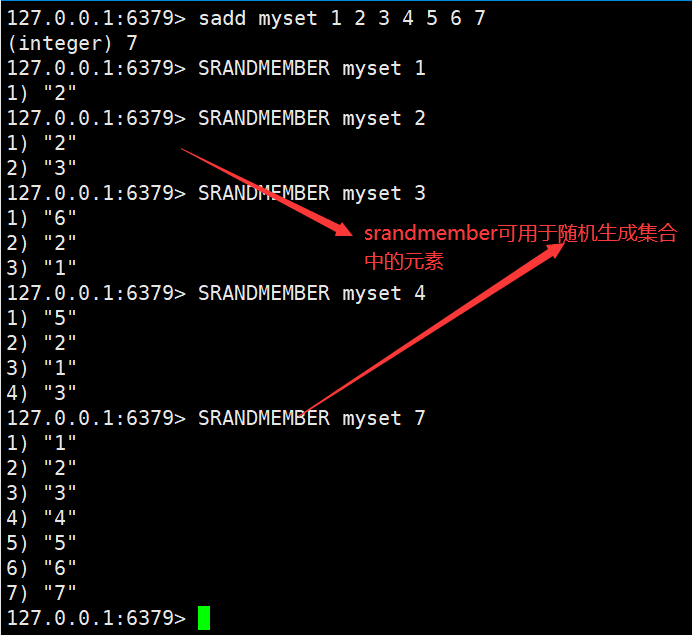
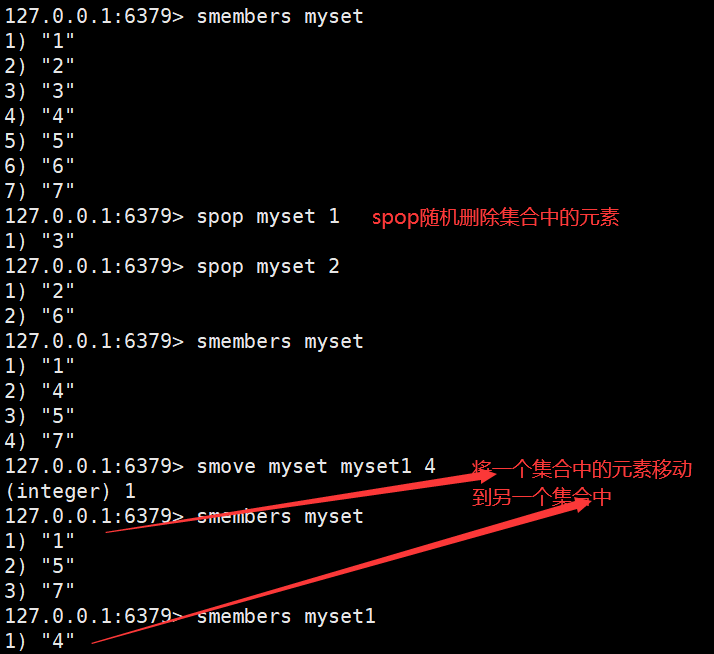
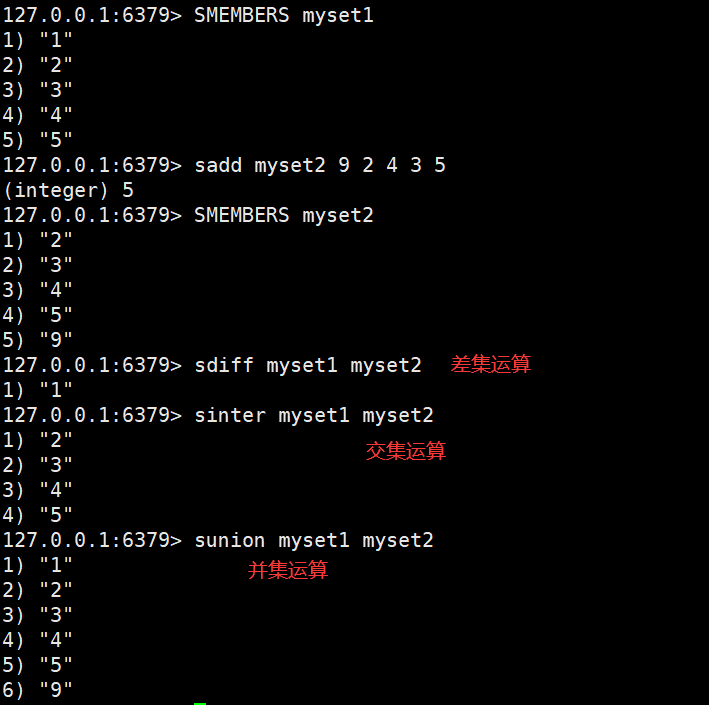
所以使用Set集合可实现共同好友,共同关注等需求。
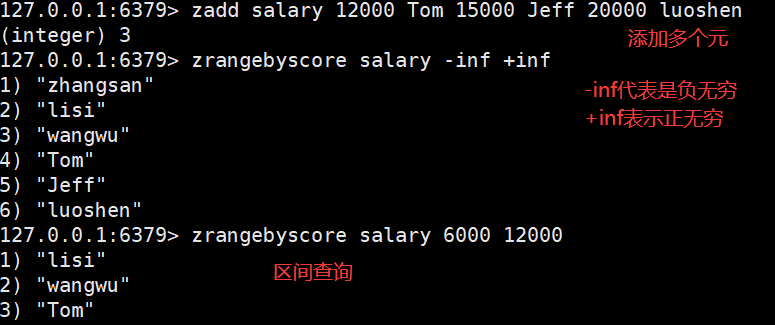
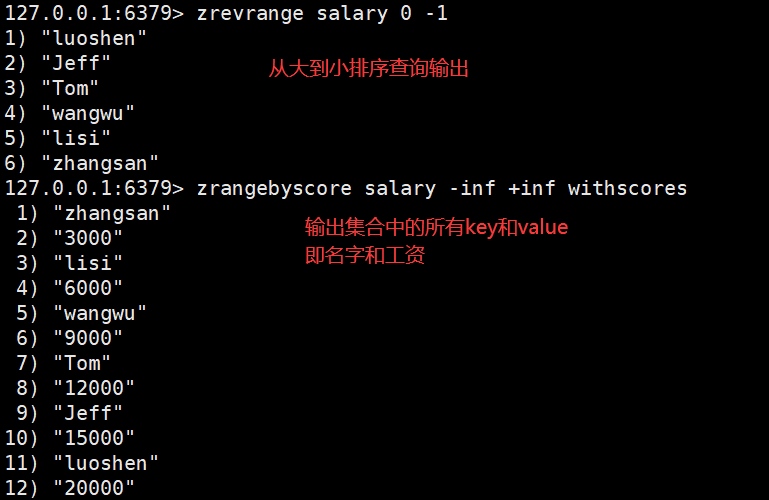
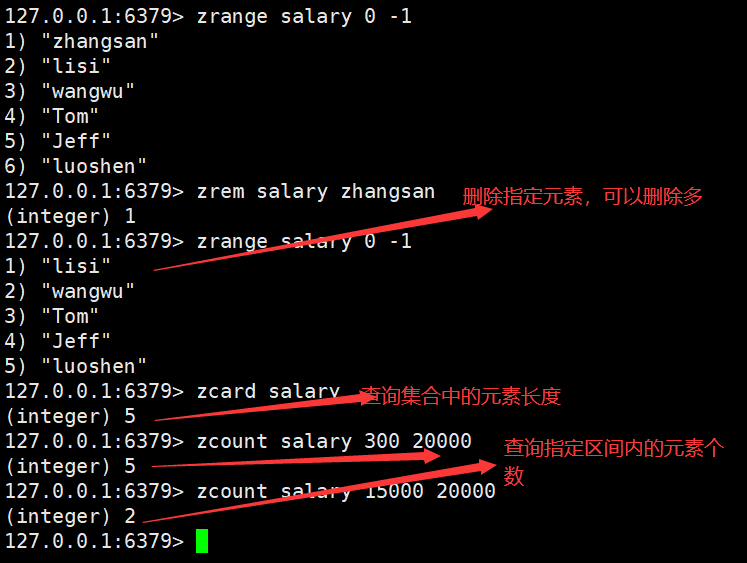
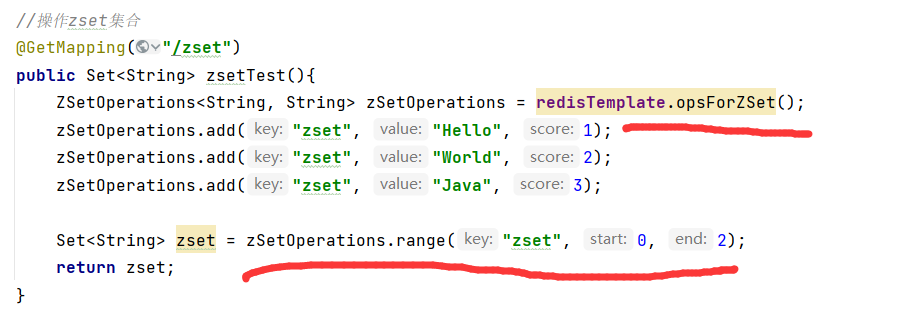
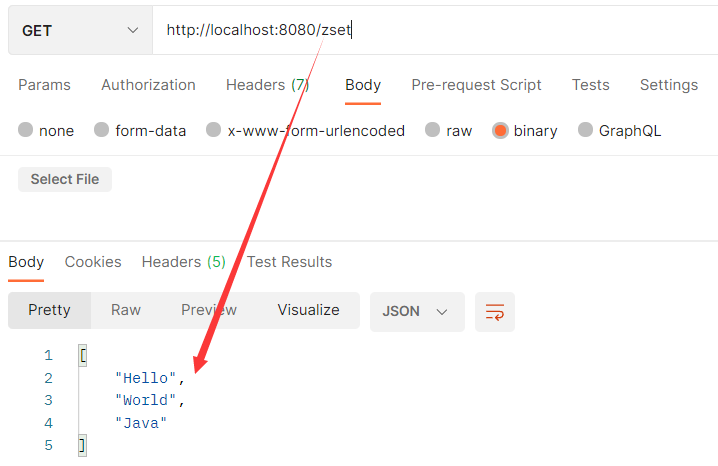
zSet(有序集合)
顾名思义,Redis zset(有序集合)中的成员是有序排列的,它和 set 集合的相同之处在于,集合中的每一个成员都是字符串类型,并且不允许重复;而它们最大区别是,
有序集合是有序的,set 是无序的,这是因为有序集合中每个成员都会关联一个 double(双精度浮点数)类型的 score (分数值),Redis 正是通过 score 实现了对集合成员的排序。
zset 是 Redis 常用数据类型之一,它适用于排行榜类型的业务场景,比如 QQ 音乐排行榜、用户贡献榜等。在音乐排行榜单中,我们可以将歌曲的点击次数作为 score 值,把歌曲的名字作为 value 值,通过对 score 排序就可以得出歌曲“热度榜单”。

二 大特殊结构
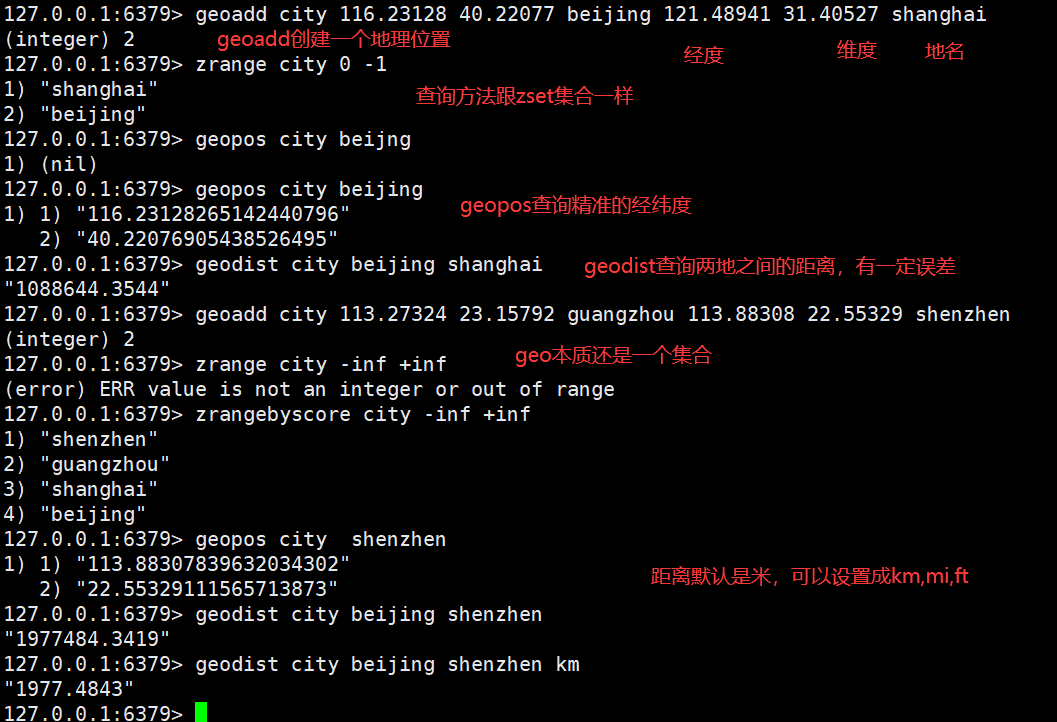
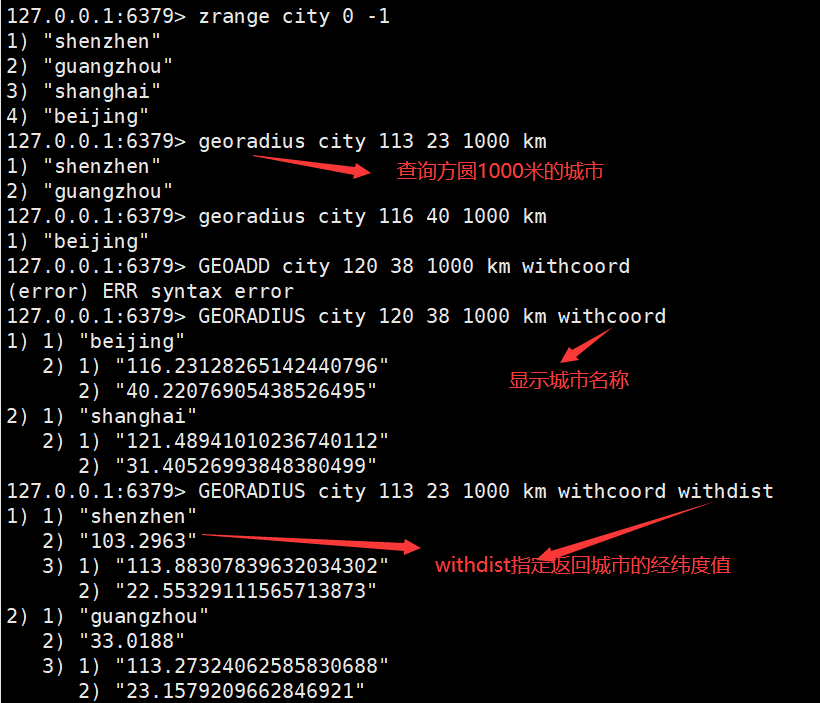
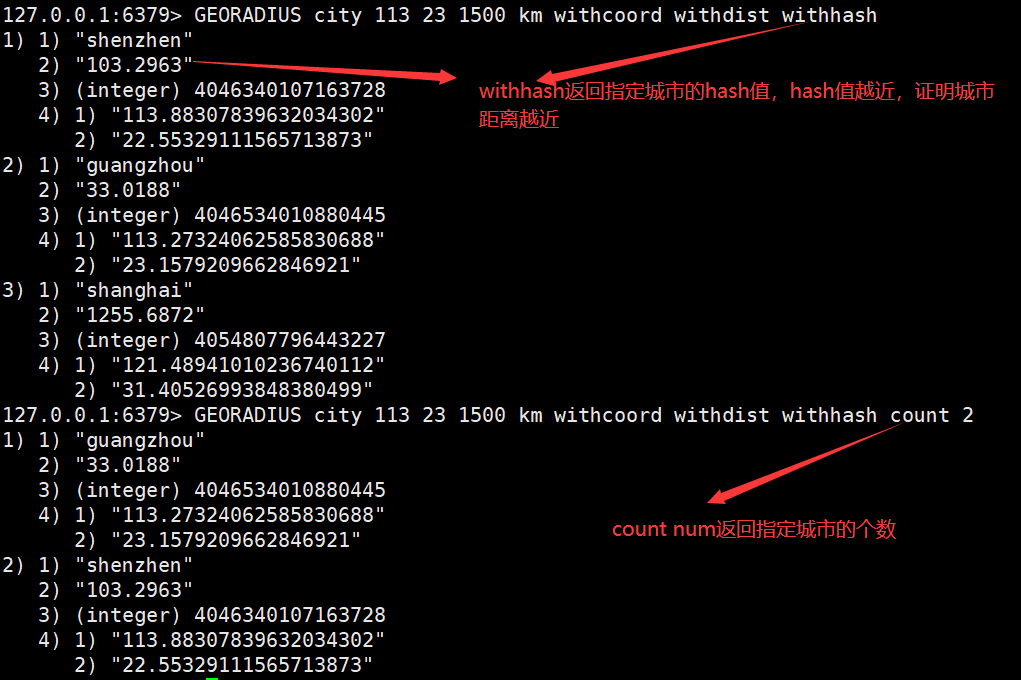
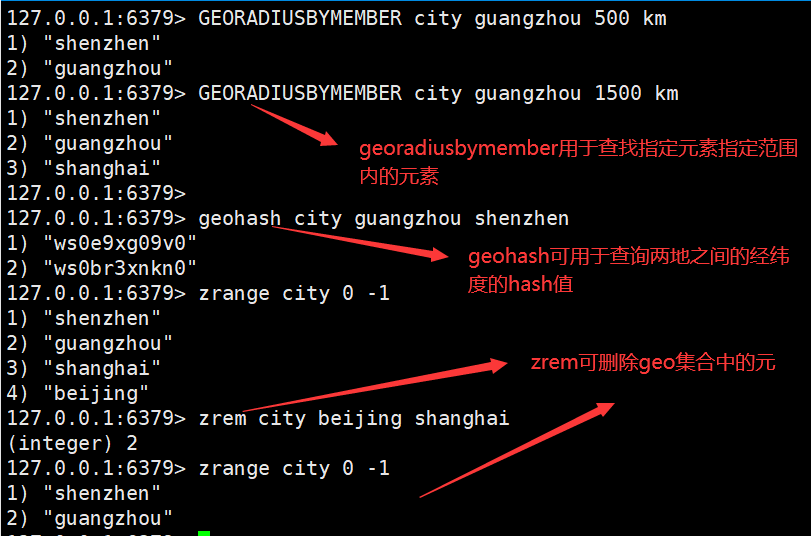
1.Geospatial(地理位置 ):(经纬度查询)
可用于实现附近位置,摇一摇等功能。
2.HyperLogLogs(基数统计)
这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数,共同好友数等。
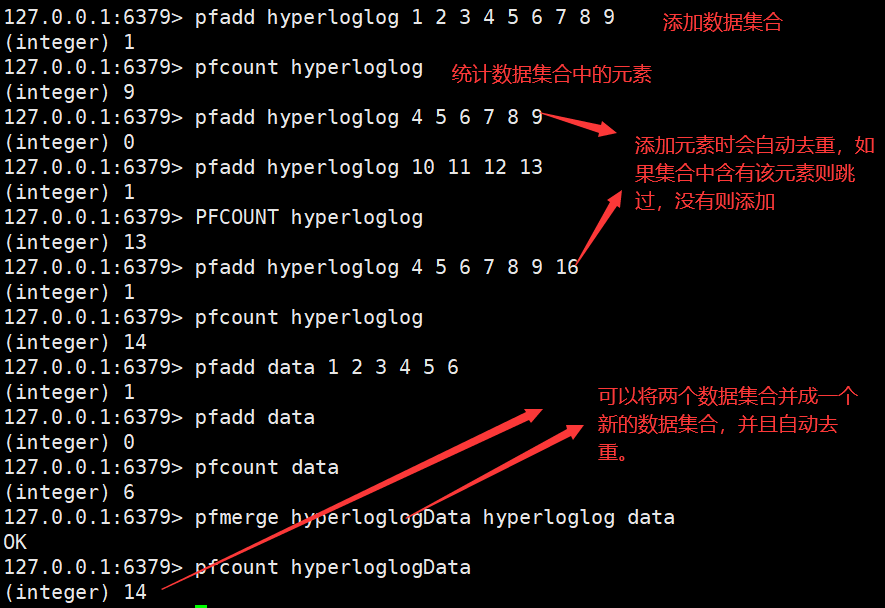
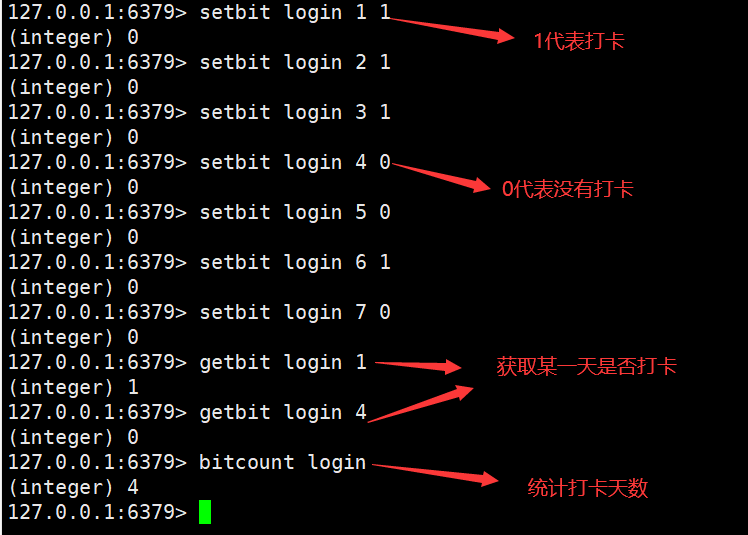
3.Bitmaps(位图)
统计用户信息,活跃,不活跃! 登录,未登录! 打卡,不打卡! 两个状态的,都可以使用 Bitmaps!
三 事务
事务的四个基本元素(跟MySQL数据库的事务类似)
1.原子性:要么都成功,要不都失败,在Redis中单条命令保证原子性,但是事务不能保证原子性
2.一致性:事务必须是一个状态到另一个状态,没有中间状态。
3.隔离性:一个事务的执行不能被另一个事务干扰,即事务内部的操作及使用的数据对并发的其他事务不能互相干扰。
但在Redis中,事务没有隔离级别的概念,因为Redis是单线程的。
4.持久性:事务一旦提交,数据库里的数据将保持不变,不受任何其他因素的干扰。
1.开启事务
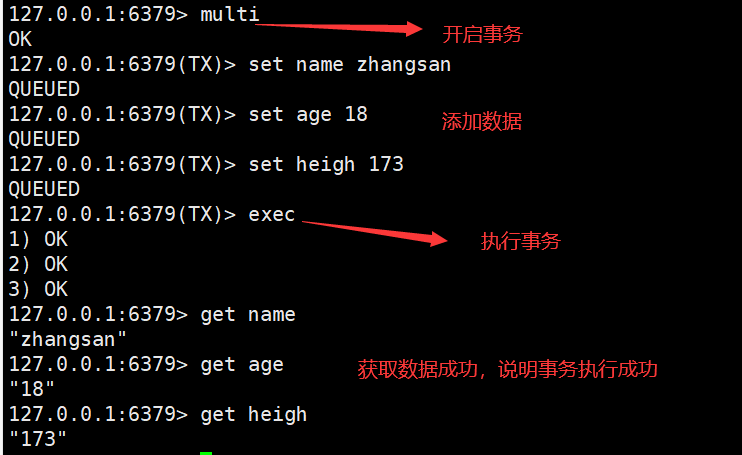
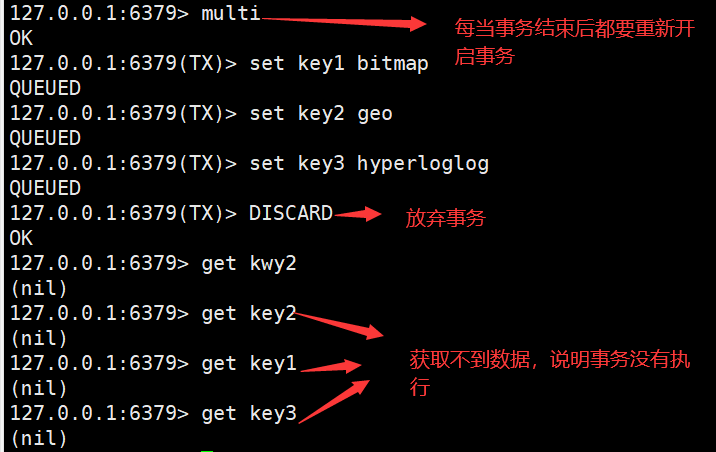
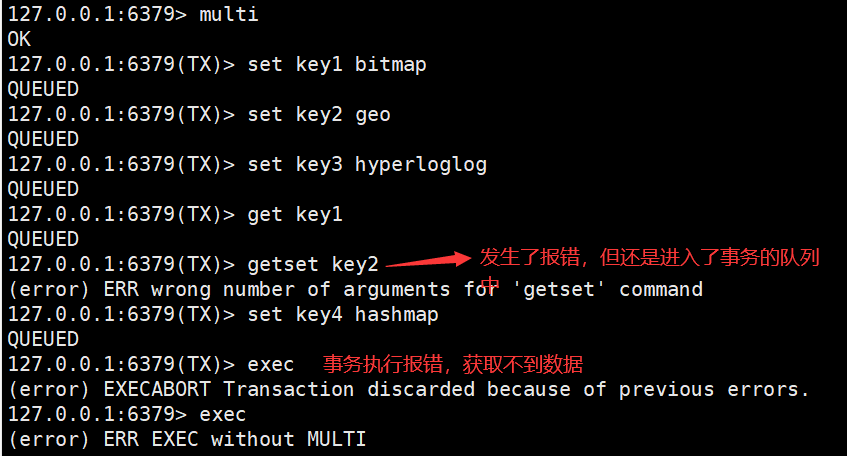
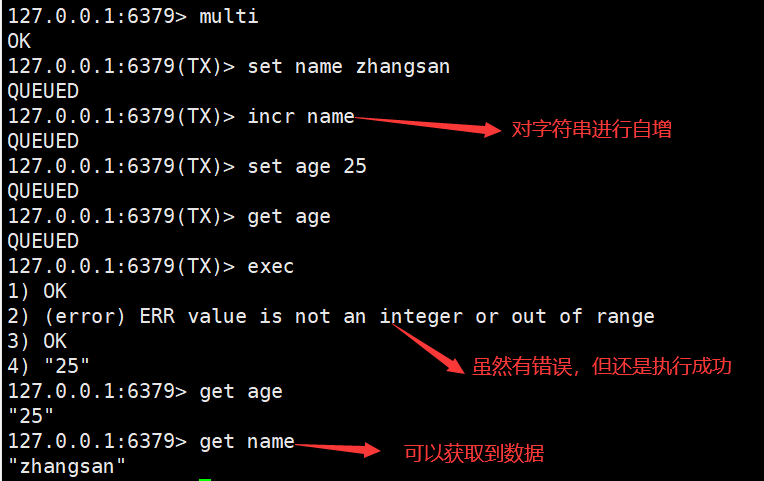
说明在Redis数据库中,不保证事务的原子性。
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
乐观锁和悲观锁的区别???
悲观锁:认为什么时候都会出现问题,所以一直监视着,没有执行当前步骤完成前,不会让任何线程执行,十分浪费性能!!现在一般很少用。
乐观锁:认为什么时候都不会出新问题,所以只有在更新数据的时候去判断一下,判断在此期间是否有人修改过被监视的这个数据,没有的话正常执行事务,反之之心失败。
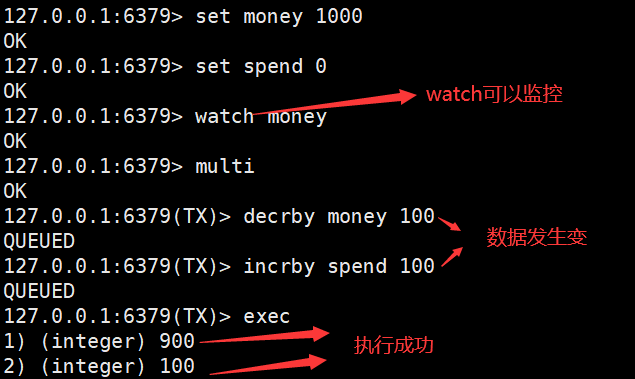
多个线程操控
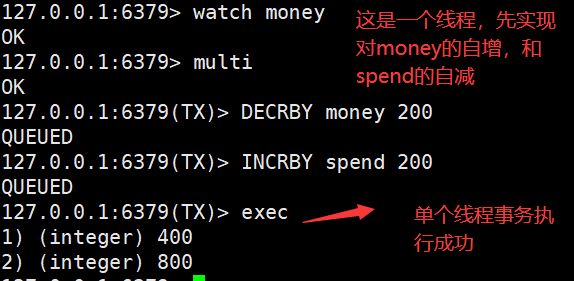
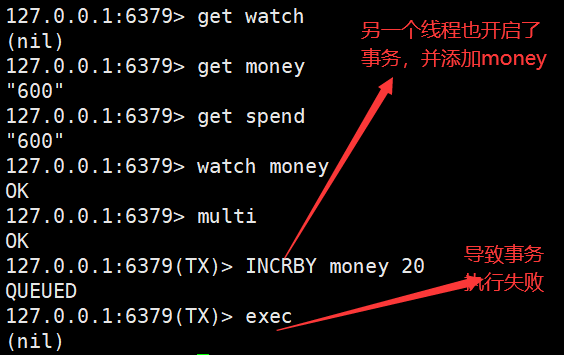
如果多个线程操控事务执行失败,该怎么办???

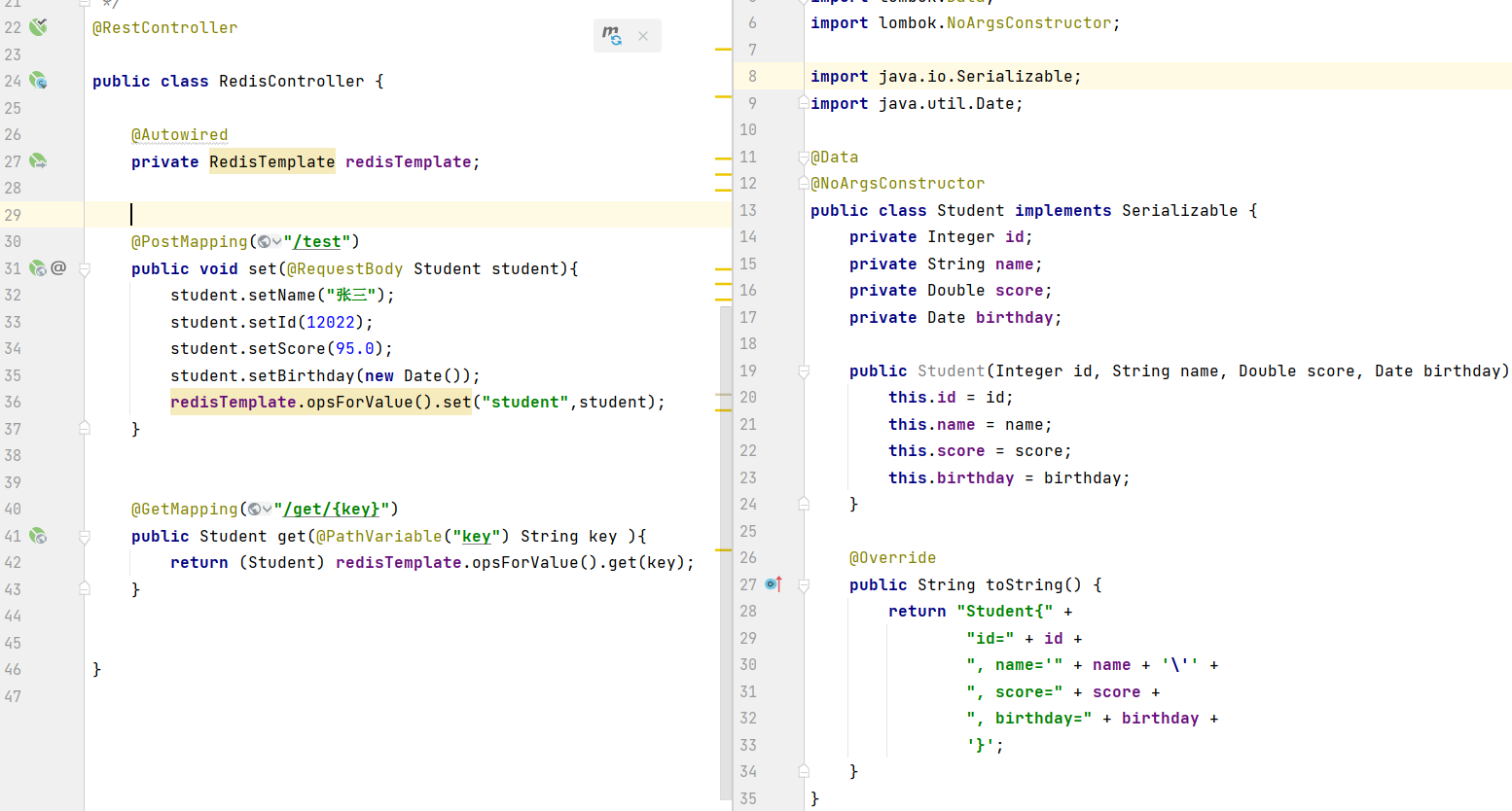
四 SpringBoot 整合 Redis
1.创建好SpringBoot项目,导入所需要的依赖
2.在application.yaml文件中配置好所需要的信息

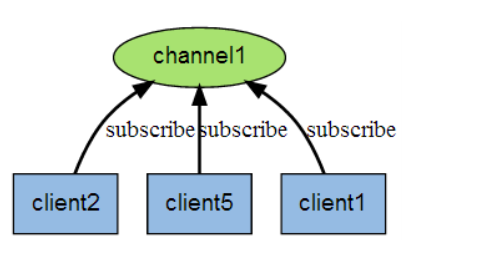
五 发布订阅功能
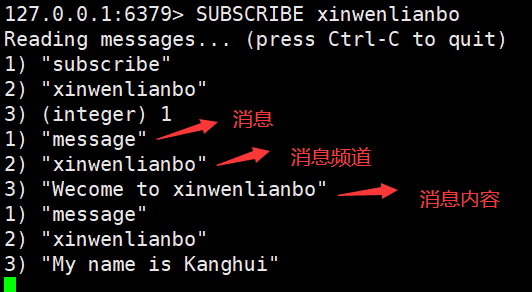
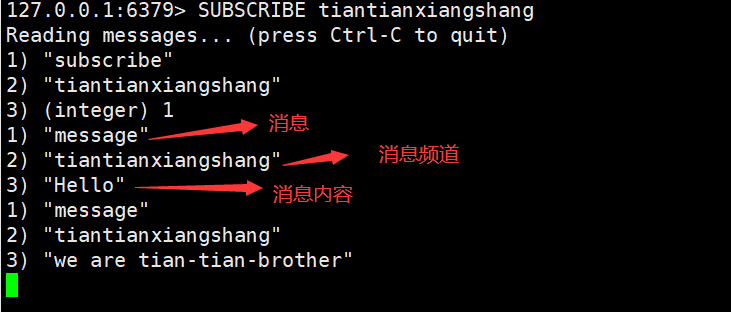
Redis 发布订阅(pub/sub)是一个消息通信模式:发送者发送消息,订阅者接受消息
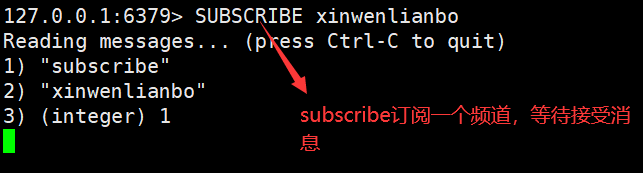
客户端订阅一个频道
服务端向一个频道(所有频道)发送消息
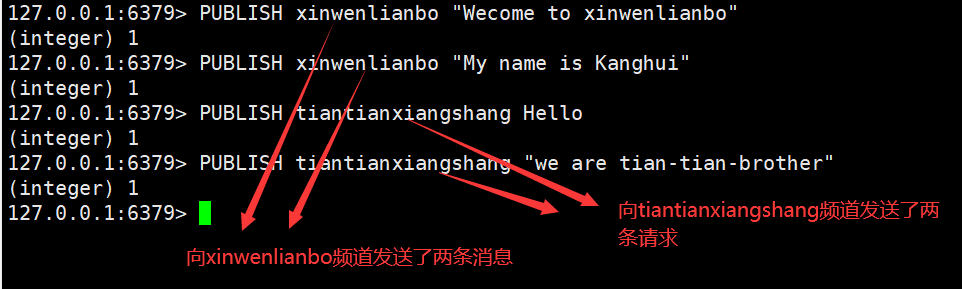
订阅该频道的所有客户端将收到消息

六 持久化技术
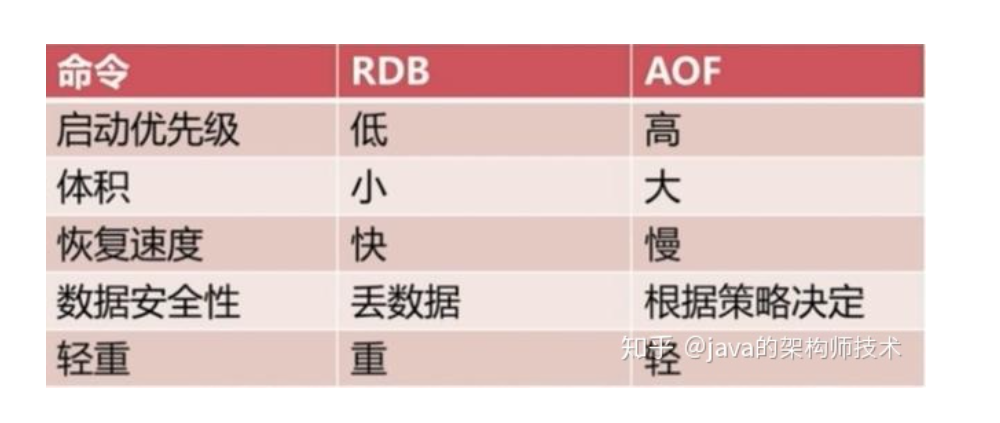
RDB(Redis DataBase):也叫快照方式,将某一时刻的内存数据,以二进制的形式写入磁盘
AOF(Append Only File):文件追加方式,记录所有的操作命令,并以文本的形式追加到文件中。
RDB和AOF混合方式:Redis 4.0 之后新增的⽅式,混合持久化是结合了 RDB 和 AOF 的优点,在写⼊的时候,先把当前的数据以RDB 的形式写⼊⽂件的开头,
再将后续的操作命令以 AOF 的格式存⼊⽂件,这样既能保证 Redis 重启时的速度,⼜能简单数据丢失的⻛险。
RDB提供了三种机制:save、bgsave、自动化
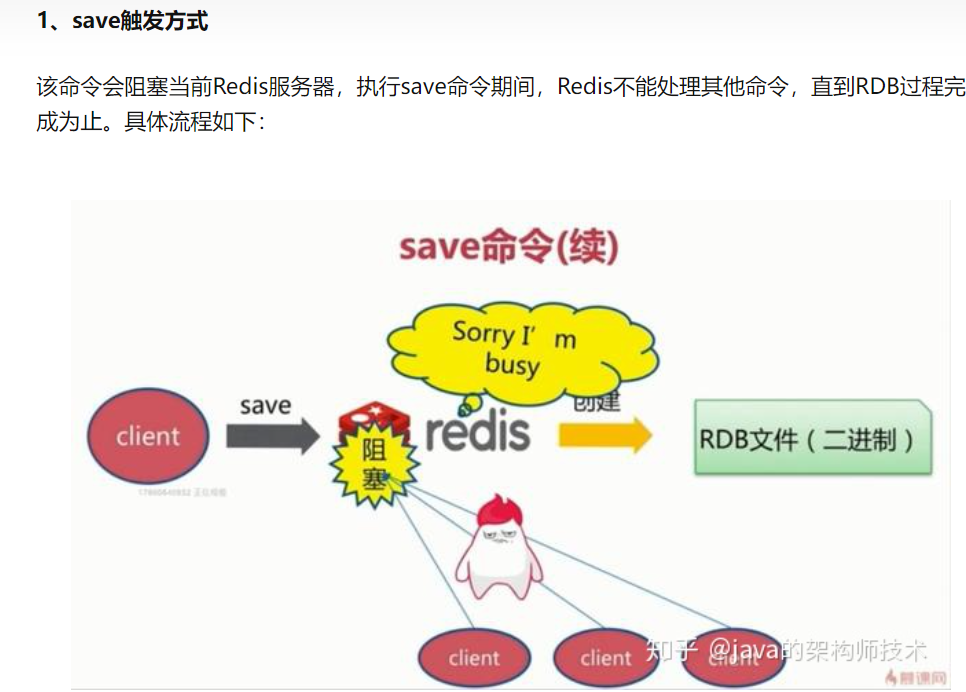
执行完成时候如果存在老的RDB文件,就把新的替代掉旧的。我们的客户端可能都是几万或者是几十万,这种方式显然不可取。
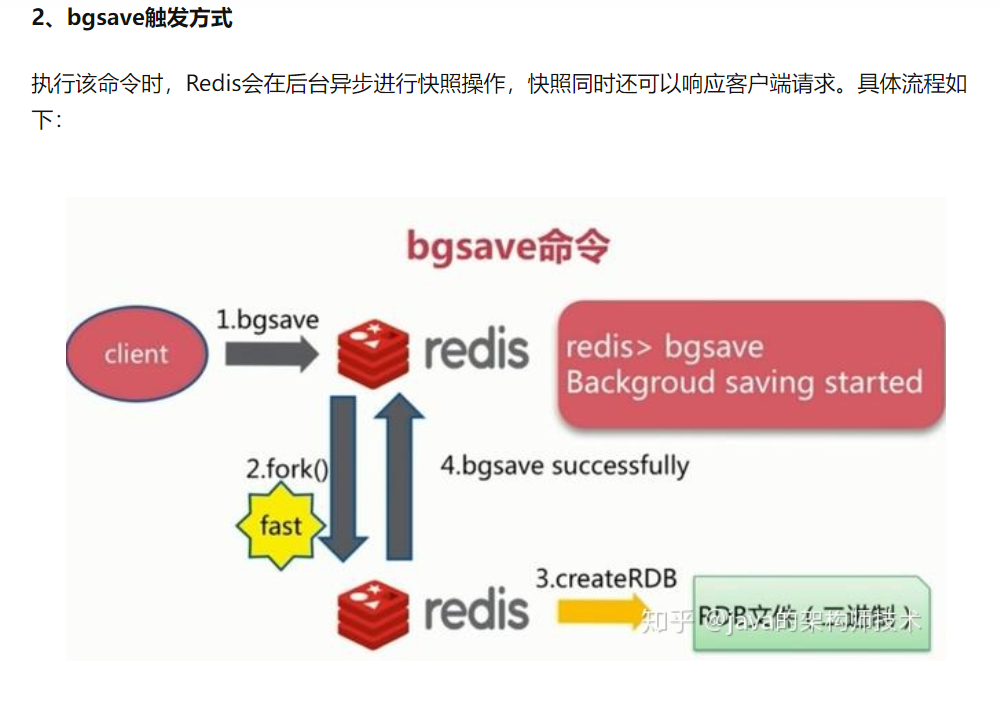
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
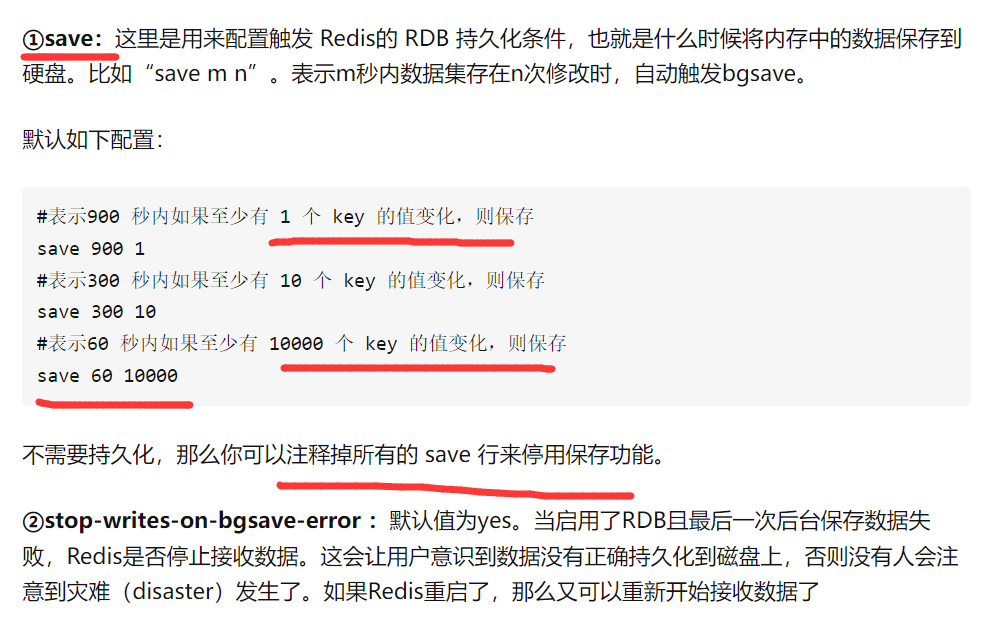
3、自动触发
自动触发是由我们的配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
AOF文件实现原理
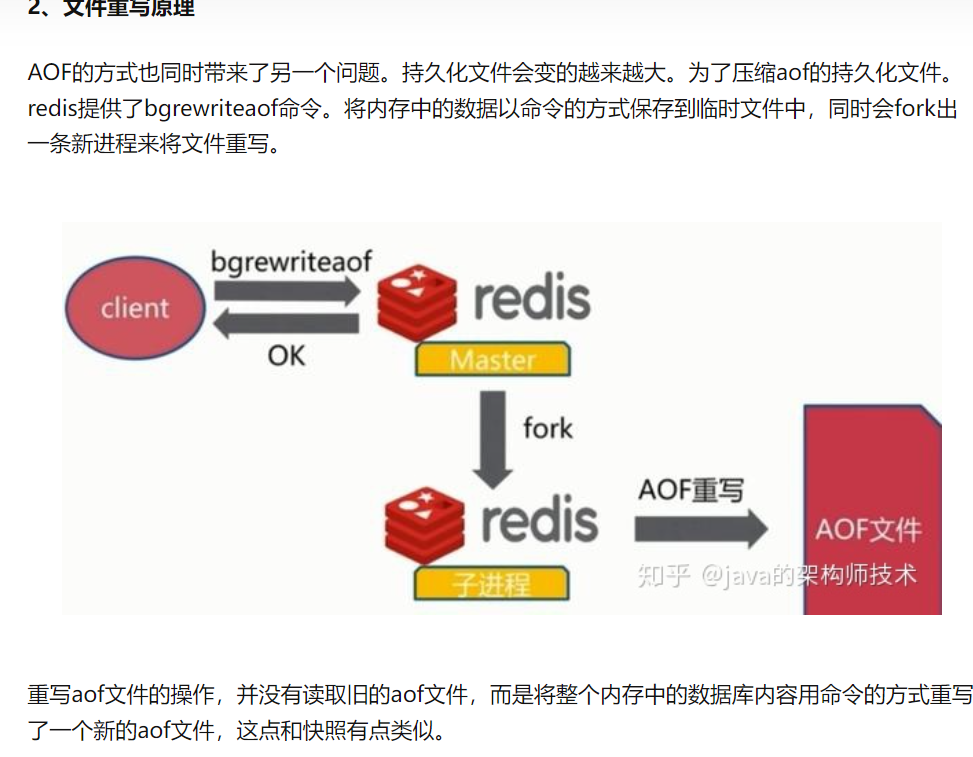
AOF也提供了三种机制
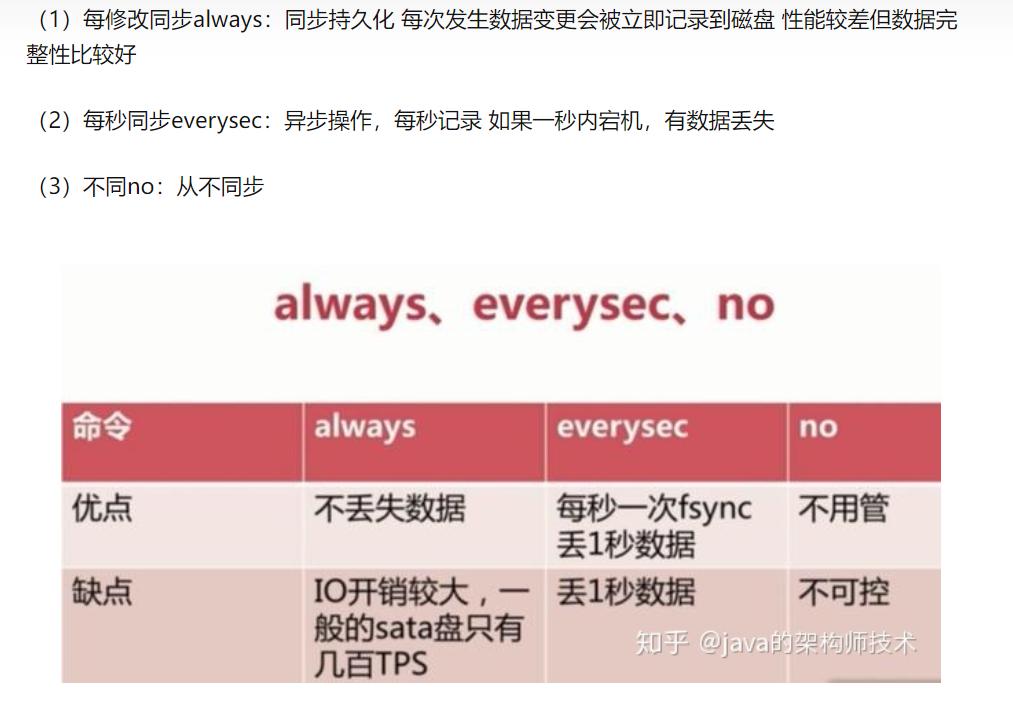
AOF和RDB的优缺点???
RDB是Redis默认的持久化方式

AOF

如何选择AOF和RDB
主从复制+哨兵模式
主从复制:是指将一台主机上的数据复制到另一台主机上,前者称为主机(master),后者称为从机(slave)。
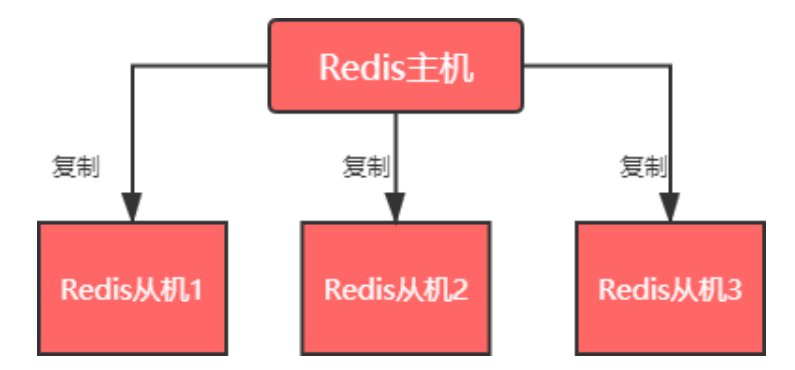
在这个过程中,只有 master 主机可执行写命令,其他 salve 从机只能只能执行读命令,这种读写分离的模式可以大大减轻 Redis 主机的数据读取压力,
从而提高了Redis 的效率,并同时提供了多个数据备份。主从模式是搭建 Redis Cluster 集群最简单的一种方式。
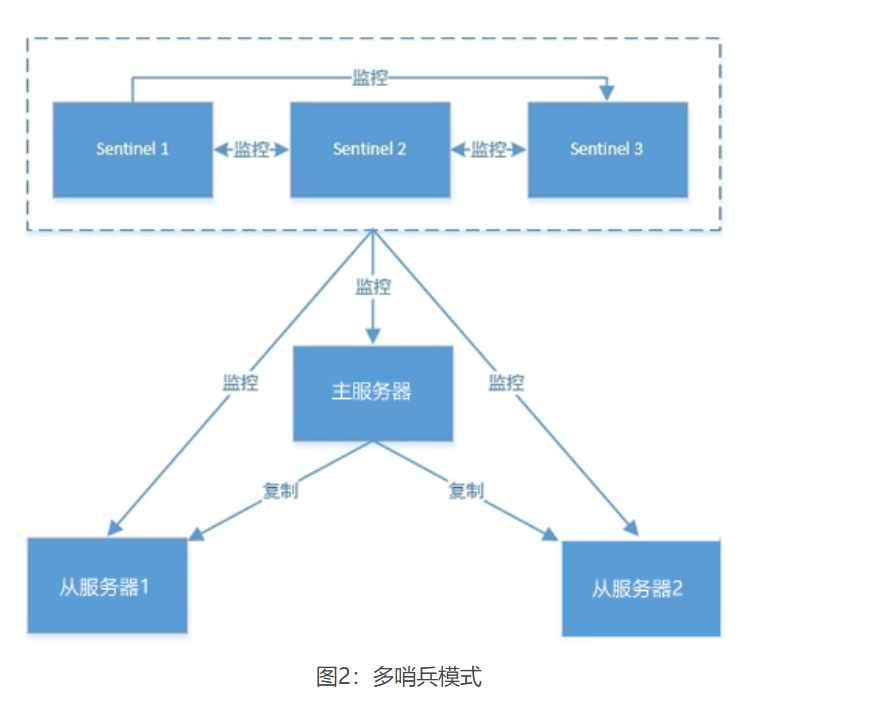
哨兵(Sentinel)模式:当一台服务器出现故障时,会有一台服务器成为新的主机,这就是哨兵模式。
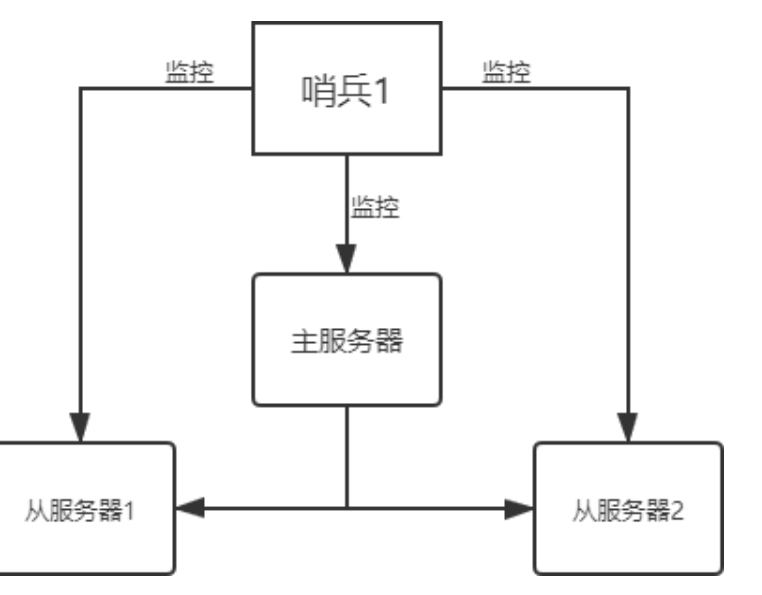
第一:哨兵节点会以每秒一次的频率对每个 Redis 节点发送PING命令,并通过 Redis 节点的回复来判断其运行状态。
第二:当哨兵监测到主服务器发生故障时,会自动在从节点中选择一台将机器,并其提升为主服务器,
然后使用 PubSub 发布订阅模式,通知其他的从节点,修改配置文件,跟随新的主服务器。
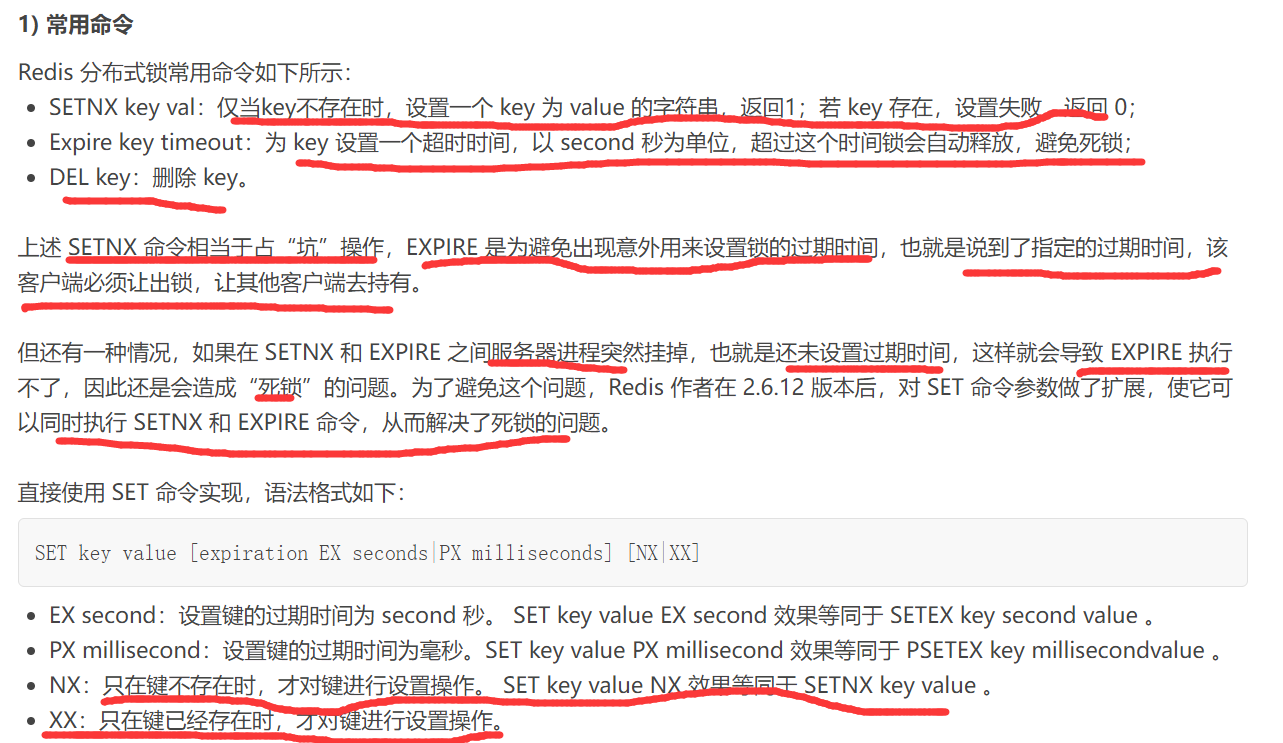
Redis分布式锁
分布式锁并非是 Redis 独有,比如 MySQL 关系型数据库,以及 Zookeeper 分布式服务应用,它们都实现分布式锁,只不过 Redis 是基于缓存实现的。
Redis 分布式锁有很对应用场景,举个简单的例子,比如春运时,您需要在 12306 上抢购回家火车票,但 Redis 数据库中只剩一张票了,
此时有多个用户来预订购买,那么这张票会被谁抢走呢?Redis 服务器又是如何处理这种情景的呢?在这个过程中就需要使用分布式锁。
Redis 分布式锁主要有以下特点:
第一:互斥性是分布式锁的重要特点,在任意时刻,只有一个线程能够持有锁;
第二:锁的超时时间,一个线程在持锁期间挂掉了而没主动释放锁,此时通过超时时间来保证该线程在超时后可以释放锁,这样其他线程才可以继续获取锁;
第三:加锁和解锁必须是由同一个线程来设置;
第四:Redis 是缓存型数据库,拥有很高的性能,因此加锁和释放锁开销较小,并且能够很轻易地实现分布式锁。
注意:一个线程代表一个客户端
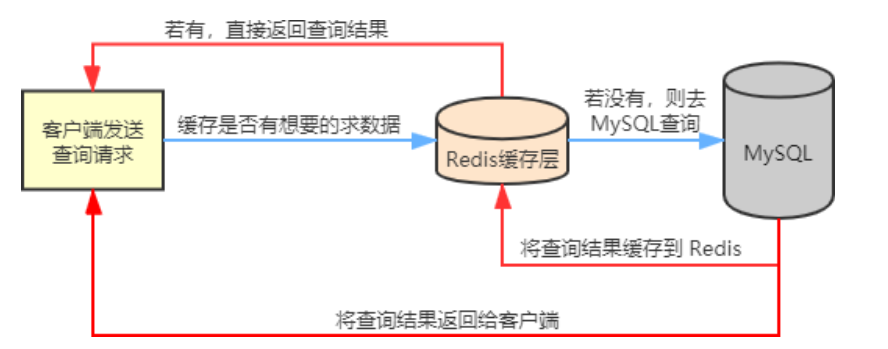
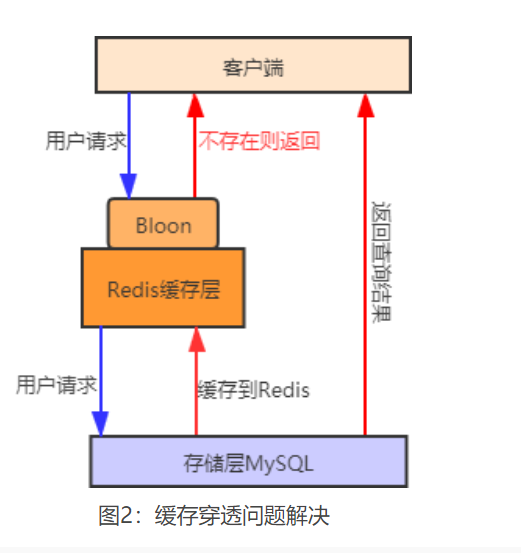
缓存穿透,缓存击穿和缓存雪崩
缓存穿透是指当用户查询某个数据时,Redis 中不存在该数据,也就是缓存没有命中,此时查询请求就会转向持久层数据库 MySQL,结果发现 MySQL 中也不存在该数据,
MySQL 只能返回一个空对象,代表此次查询失败。如果这种类请求非常多,或者用户利用这种请求进行恶意攻击,就会给 MySQL 数据库造成很大压力,甚至于崩溃,这种现象就叫缓存穿透。
解决方案:
1.缓存空对象。当 MySQL 返回空对象时, Redis 将该对象缓存起来,同时为其设置一个过期时间。当用户再次发起相同请求时,就会从缓存中拿到一个空对象,
用户的请求被阻断在了缓存层,从而保护了后端数据库,但是这种做法也存在一些问题,虽然请求进不了 MSQL,但是这种策略会占用 Redis 的缓存空间。
2.使用布隆过滤器。利用一种概率型数据结构,快速的判断某个key是否存在。如果不存在及直接返return,存在时才会去查询缓存和数据库。
首先将用户可能会访问的热点数据存储在布隆过滤器中(也称缓存预热),当有一个用户请求到来时会先经过布隆过滤器,如果请求的数据,布隆过滤器中不存在,
那么该请求将直接被拒绝,否则将继续执行查询。相较于第一种方法,用布隆过滤器方法更为高效、实用。
缓存击穿是指用户查询的数据缓存中不存在,但是后端数据库却存在,这种现象出现原因是一般是由缓存中 key 过期导致的。比如一个热点数据 key,
它无时无刻都在接受大量的并发访问,如果某一时刻这个 key 突然失效了,就致使大量的并发请求进入后端数据库,导致其压力瞬间增大。这种现象被称为缓存击穿。
有两种解决方案
第一种就是修改过期时间,比如设置热点时间永不过期
第二种就是使用分布式锁,重新设计缓存的使用方式
上锁:当我们通过 key 去查询数据时,首先查询缓存,如果没有,就通过分布式锁进行加锁,第一个获取锁的进程进入后端数据库查询,并将查询结果缓到Redis 中。
解锁:当其他进程发现锁被某个进程占用时,就进入等待状态,直至解锁后,其余进程再依次访问被缓存的 key。
缓存雪崩是指缓存中大批量的 key 同时过期,而此时数据访问量又非常大,从而导致后端数据库压力突然暴增,甚至会挂掉,这种现象被称为缓存雪崩。
它和缓存击穿不同,缓存击穿是在并发量特别大时,某一个热点 key 突然过期,而缓存雪崩则是大量的 key 同时过期,因此它们根本不是一个量级。
解决方案:
缓存雪崩和缓存击穿有相似之处,所以也可以(第一种)采用热点数据永不过期的方法,来减少大批量的 key 同时过期。
再者就是为(第二种) key 设置随机过期时间,避免 key 集中过期。
