

12.17
3.1 执行第一个 spark 程序
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/opt/module/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
100
参数说明:
--master spark://hadoop102:7077 指定 Master 的地址
--executor-memory 1G 指定每个 executor 可用内存为 1G
--total-executor-cores 2 指定每个 executor 使用的 cup 核数为 2 个
该算法是利用蒙特·卡罗算法求 PI,结果如下图:

网页上查看 History Server

3.2 Spark 应用提交
一旦打包好,就可以使用 bin/spark-submit 脚本启动应用了。 这个脚本负责设置 spark 使用的 classpath 和依赖,支持不同类型的集群管理器和发布模式:
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
一些常用选项:
1) --class: 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)。
2) --master: 集群的 master URL (如 spark://192.168.25.102:7077)。
3) --deploy-mode: 是否发布你的驱动到 Worker 节点(cluster) 或者作为一个本地客户端 client)(默认是 client)。
4) --conf: 任意的 Spark 配置属性, 格式 key=value,如果值包含空格,可以加引号 "key=value",缺省的 Spark 配置。
5) application-jar: 打包好的应用 jar,包含依赖,这个 URL 在集群中全局可见。 比如 hdfs://共享存储系统, 如果是 file://path, 那么所有的节点的 path 都包含同样的 jar。
6) application-arguments: 传给 main() 方法的参数。
--master 后面的 URL 可以是以下格式:

查看 Spark-submit 全部参数:

3.3 Spark shell
spark-shell 是 Spark 自带的交互式 Shell 程序,方便用户进行交互式编程,用户可以在该命令行下用 scala 编写 spark 程序。
3.3.1 启动 Spark shell
启动 spark shell 时没有指定 master 地址
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-shell
启动 spark shell 时指定 master 地址
$ /opt/module/spark-2.1.1-bin-hadoop2.7/bin/spark-shell \
--master spark://hadoop102:7077 \
--executor-memory 2G \
--total-executor-cores 2
注意1:如果启动 spark shell 时没有指定 master 地址,但是也可以正常启动 spark shell 和执行 spark shell 中的程序,其实是启动了 spark 的 cluster 模式,如果 spark 是单节点,并且没有指定 slave 文件,这个时候如果打开 spark-shell 默认是 local 模式。
Local 模式是 master 和 worker 在同同一进程内。
Cluster 模式是 master 和 worker 在不同进程内。注意2:Spark Shell 中已经默认将 SparkContext 类初始化为对象 sc。用户代码如果需要用到,则直接应用 sc 即可。

3.3.2 在 Spark shell 中编写 WordCount 程序
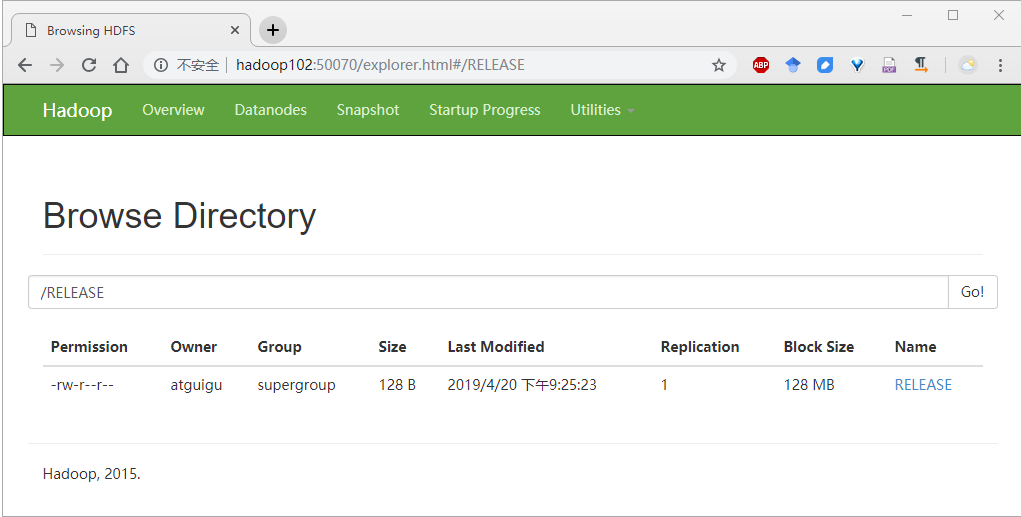
Step1、首先启动 HDFS,在 HDFS 上创建一个 /RELEASE 目录
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -mkdir -p /RELEASE
Step2、将 Spark 目录下的 RELEASE 文件上传一个文件到:hdfs://hadoop102:9000/RELEASE 上
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put /opt/module/spark-2.1.1-bin-hadoop2.7/RELEASE /RELEASE
如下图所示:
Step3、在 Spark shell 中用 scala 语言编写 spark 程序
scala> sc.textFile("hdfs://hadoop102:9000/RELEASE/RELEASE").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://hadoop102:9000/out")
如下图所示:

Step4、使用 hdfs 命令查看结果
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -cat hdfs://hadoop102:9000/out/p*
如下图所示:

说明:
sc 是 SparkContext 对象,该对象是提交 spark 程序的入口。
textFile(hdfs://hadoop102:9000/RELEASE/RELEASE) 是 hdfs 中读取数据
flatMap(_.split(" ")) 先 map 在压平
map((_,1)) 将单词和1构成元组
reduceByKey(_+_) 按照 key 进行 reduce,并将 value 累加
saveAsTextFile("hdfs://hadoop102:9000/out") 将结果写入到 hdfs 中
如下图所示:

3.4 在 IDEA 中编写 WordCount 程序
spark shell 仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在 IDE 中编制程序,然后打成 jar 包,然后提交到集群,最常用的是创建一个 Maven 项目,利用 Maven 来管理 jar 包的依赖。
Step1、创建一个项目
Step2、选择 Maven 项目,然后点击 next
Step3、填写 maven 的 GAV,然后点击 next
Step4、填写项目名称,然后点击 finish
Step5、创建好 maven 项目后,点击 Enable Auto-Import
Step6、配置 Maven 的 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu</groupId>
<artifactId>sparkdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.1.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<archive>
<manifest>
<mainClass>com.atguigu.sparkdemo.WordCountDemo</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
</project>
Step7、将 src/main/scala 设置成源代码目录。
Step8、添加 IDEA Scala(执行此操作后,pom 文件中不用添加 scala 依赖,因为已经以 lib 库的方式加入)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通