
创建进程的多种方式、join方法、进程对象相关操作、进程间数据默认隔离、生产者与消费者模型
创建进程的多种方式
1.双击桌面程序图标
2.1代码创建进程
创建进程的代码在不同的操作系统中,底层原理有区别:在windows中, 创建进程类似于导入模块,需要启动脚本(if name == 'main'😃,没有启动脚本,就相当于进入了死循环;在mac、linux中,创建进程类似于直接拷贝,不需要启动脚本,但是为了兼容性,也可以使用
from multiprocessing import Process
import time
def task(name):
print(f"{name}在子进程中运行开始")
time.sleep(2)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p = Process(target=task,args=('nana',))
p.start()
print("进程")
结果:
进程
nana在子进程中运行开始
nana在子进程中运行结束
知识补充:
1.p = Process(target=task,args=('nana',)) 创建一个进程对象,其中args就是通过元组的形式给函数传参,也可以是通过kwargs={'name':'nana'}
2.p.start() 相当于告诉操作系统创建一个进程(异步操作),普通的函数调用是同步操作
2.2 代码创建进程
from multiprocessing import Process
import time
class My_Process(Process):
def __init__(self,name):
super(My_Process, self).__init__()
self.name = name
def run(self):
print(f"{self.name}在子进程中运行开始")
time.sleep(2)
print(f"{self.name}在子进程中运行结束")
if __name__ == '__main__':
obj = My_Process('nana')
obj.start()
print("主进程")
结果:
主进程
nana在子进程中运行开始
nana在子进程中运行结束
join()方法
join()方法的作用是使主进程等待子进程运行结束之后再运行
需求:让子进程执行完了再执行主进程
方式一、在主进程代码中添加time.sleep()
在主进程代码中添加time.sleep()的这个方法不合理,原因是无法准确把握子进程执行的时间
from multiprocessing import Process
import time
def task(name):
print(f"{name}在子进程中运行开始")
time.sleep(2)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p = Process(target=task,args=('nana',))
p.start()
time.sleep(3)
print("进程")
结果:
nana在子进程中运行开始
nana在子进程中运行结束
进程
方式二、join()方法
from multiprocessing import Process
import time
def task(name):
print(f"{name}在子进程中运行开始")
time.sleep(2)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p = Process(target=task,args=('nana',))
p.start()
p.join()
print("进程")
结果:
nana在子进程中运行开始
nana在子进程中运行结束
进程
join()方法进阶练习
需求:计算下列程序运行的时间
from multiprocessing import Process
import time
def task(name,n):
print(f"{name}在子进程中运行开始")
time.sleep(n)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p1= Process(target=task,args=('nana',1))
p2= Process(target=task, args=('jason', 2))
p3 = Process(target=task, args=('kevin', 3))
start_time = time.time()
p1.start()
p1.join()
p2.start()
p2.join()
p3.start()
p3.join()
end_time = time.time()
print('总耗时:%s'%(end_time-start_time))
print("主进程")
print("进程")
结果:
nana在子进程中运行开始
nana在子进程中运行结束
jason在子进程中运行开始
jason在子进程中运行结束
kevin在子进程中运行开始
kevin在子进程中运行结束
总耗时:6.896258115768433
主进程
进程
from multiprocessing import Process
import time
def task(name,n):
print(f"{name}在子进程中运行开始")
time.sleep(n)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p1= Process(target=task,args=('nana',1))
p2= Process(target=task, args=('jason', 2))
p3 = Process(target=task, args=('kevin', 3))
start_time = time.time()
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
end_time = time.time()
print('总耗时:%s'%(end_time-start_time))
print("主进程")
print("进程")
结果:
nana在子进程中运行开始
jason在子进程中运行开始
kevin在子进程中运行开始
nana在子进程中运行结束
jason在子进程中运行结束
kevin在子进程中运行结束
总耗时:3.4667296409606934
主进程
进程
进程间数据默认隔离
多个进程数据彼此之间默认是相互隔离的,如果真的想交互,需要借助于'管道'或者'队列'
from multiprocessing import Process
money = 100
def task():
global money
money = 666
print('子进程中的Money:',money)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print('主进程中的money:',money)
结果:
子进程中的Money: 666
主进程中的money: 100
知识补充:Queue模块
队列:先进先出
1.创建队列对象
q = Queue(),括号内填写指定队列可以容纳的数据个数,默认是:2147483647
from multiprocessing import Queue
q = Queue(3)
2.往队列添加数据
obj.put() 如果超出数据存放极限,那么程序一直处于阻塞态,直到队列中有数据被取出
q.put(1)
q.put(2)
q.put(3)
q.put(4) # 超出了数据存放极限
3.从队列中取数据
obj.get() 如果超出数据获取极限,那么程序一直处于阻塞态,直到队列中有数据被添加;obj.get_nowait() 如果队列中没有数据可取,直接报错
print(q.get()) # 1
print(q.get()) # 2
print(q.get()) # 3
print(q.get()) # 超出数据获取极限
print(q.get_nowait()) # 1
print(q.get_nowait()) # 2
print(q.get_nowait()) # 3
print(q.get_nowait()) # 报错
4.判断队列是否已经存满
obj.full()
q = Queue(3)
q.put(1)
q.put(2)
q.put(3)
print(q.full()) # True
5.判断队列是否为空
obj.empty()
print(q.get())
print(q.get())
print(q.get())
print(q.empty()) # True
注意:obj.full()、obj.empty()、obj.get_nowait()方法在多进程下不能准确使用
进程间通信(IPC机制)
想要进程间通信,就需要借助于'管道'或者'队列'
主进程与子进程通信
from multiprocessing import Queue,Process
def task1(q):
print("子进程从队列里获取了数据:",q.get())
if __name__ == '__main__':
q = Queue()
q.put('主进程向队列里放了数据')
p1 = Process(target=task1,args=(q,))
p1.start()
p1.join()
print("主进程")
结果:
子进程从队列里获取了数据: 主进程向队列里放了数据
主进程
子进程与子进程通信
from multiprocessing import Queue,Process
def task1(q):
q.put('子进程task1往队列里添加了数据')
def task2(q):
print("子进程task2从队列里获取了数据:",q.get())
if __name__ == '__main__':
q = Queue() # 在主进程中产生q对象 确保所有的子进程使用的是相同的q
p1 = Process(target=task1,args=(q,))
p2 = Process(target=task2, args=(q,))
p1.start()
p1.join()
p2.start()
p2.join()
print("主进程")
结果:
子进程task2从队列里获取了数据: 子进程task1往队列里添加了数据
主进程
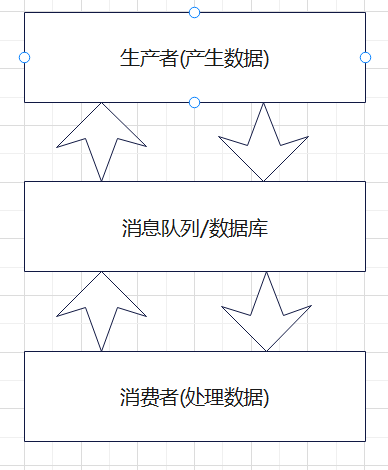
生产者消费者模型
生产者指产生数据,消费者指处理数据;完整的生产者消费者模型至少有三个部分:生产者、消息队列/数据库、消费者
进程相关方法
1.查看进程号
获取当前进程进程号:os.getpid()、current_process().pid;获取产生当前进程的父进程号:os.getppid()
from multiprocessing import Process,current_process
import os
def task():
print('子进程',os.getpid())
print('父进程',os.getppid())
print('子进程',current_process().pid)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print('父进程',os.getpid())
print('父进程',current_process().pid)
print("进程")
结果:
子进程 11204
父进程 18660
子进程 11204
父进程 18660
父进程 18660
进程
2.销毁子进程
obj.terminate()
from multiprocessing import Process
import time
def task(name):
print(f"{name}在子进程中运行开始")
time.sleep(2)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p = Process(target=task,args=('nana',))
p.start()
p.terminate()
3.判断进程是否存活
obj.is_alive()
from multiprocessing import Process
import time
def task(name):
print(f"{name}在子进程中运行开始")
time.sleep(2)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p = Process(target=task,args=('nana',))
p.start()
p.terminate()
time.sleep(0.1)
print(p.is_alive()) # False
守护进程
守护进程会随着主进程的结束而结束
用obj.daemon = True,将子进程设置为守护进程(当主进程代码结束,子进程立刻结束),需要注意的是obj.daemon = True要写在obj.start()前面
from multiprocessing import Process
import time
def task(name):
print(f"{name}在子进程中运行开始")
time.sleep(2)
print(f"{name}在子进程中运行结束")
if __name__ == '__main__':
p = Process(target=task,args=('nana',))
p.daemon = True
p.start()
print("主进程")
结果:
主进程
僵尸进程与孤儿进程
1.僵尸进程:子进程运行结束(僵尸),但是由子进程产生产生的相关资源没有完全清空,需要父进程参与回收
2.孤儿进程:父进程意外结束,子进程正常运行,该子进程就称之为孤儿进程。此时孤儿进程产生的相关资源,会被操作系统回收清理
模拟抢票系统--粗略版
from multiprocessing import Process
import json
import time
import random
def select_ticket(name):
with open(r'ticket.json','r',encoding='utf8')as f :
data = json.load(f)
print(name,f"余票:{data.get('ticket')}")
def buy_ticket(name):
time.sleep(random.randint(1,3))
with open(r'ticket.json', 'r', encoding='utf8')as f:
data = json.load(f)
if data.get('ticket') > 0:
data['ticket'] -= 1
print(name,"购买成功")
else:
print("没票了")
with open(r'ticket.json', 'w', encoding='utf8')as f:
json.dump(data,f)
def run(name):
select_ticket(name)
buy_ticket(name)
if __name__ == '__main__':
for i in range(10):
p = Process(target=run,args=(i,))
p.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号