

HDFS辅助工具-文件归档工具archive
HDFS辅助工具-文件归档工具archive
1、背景:
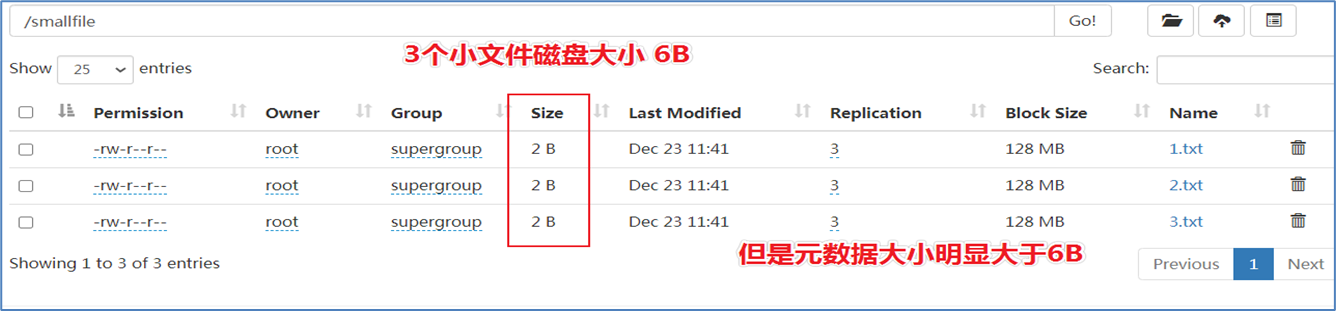
- HDFS并不擅长存储小文件,因为每个文件最少一个block,每个block的元数据都会在NameNode占用内存
- 如果存在大量的小文件,它们会吃掉NameNode节点的大量内存。如下所示,模拟小文件场景:
2、概述:
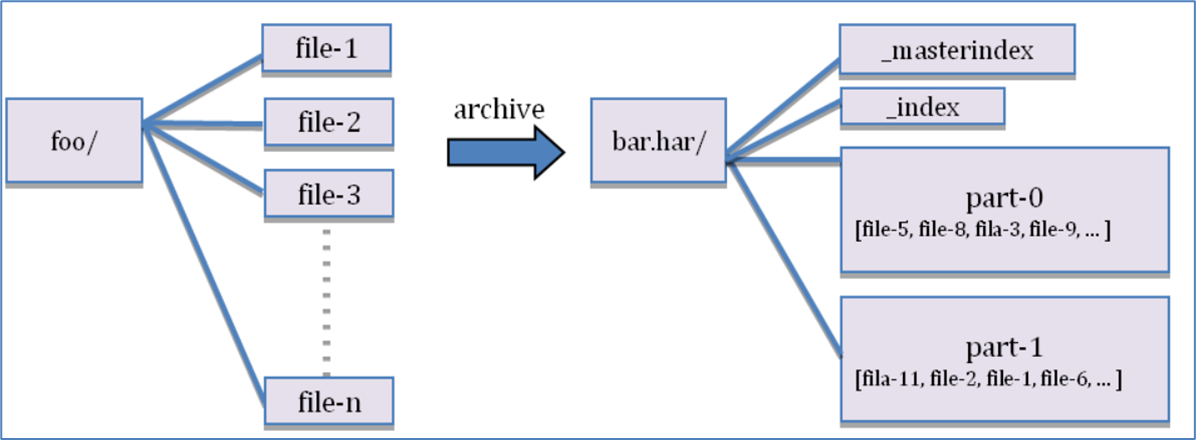
- Hadoop Archive可以有效的处理以上问题,它可以把多个文件归档成为一个文件;
- 归档成一个文件后还可以透明的访问之前的每一个文件
3、创建档案
Usage: hadoop archive -archiveName name -p <parent> <src>* <dest>- -archiveName 指要创建的存档的名称。扩展名应该是*.har
- -p 指定文件档案文件src的相对路径。
比如:-p /foo/bar a/b/c e/f/g,这里的/foo/bar是a/b/c与e/f/g的父路径,所以完整路径为/foo/bar/a/b/c与/foo/bar/e/f/g。
案例:存档一个目录 /smallfile下的所有文件:
hadoop archive -archiveName test.har -p /smallfile /outputdir
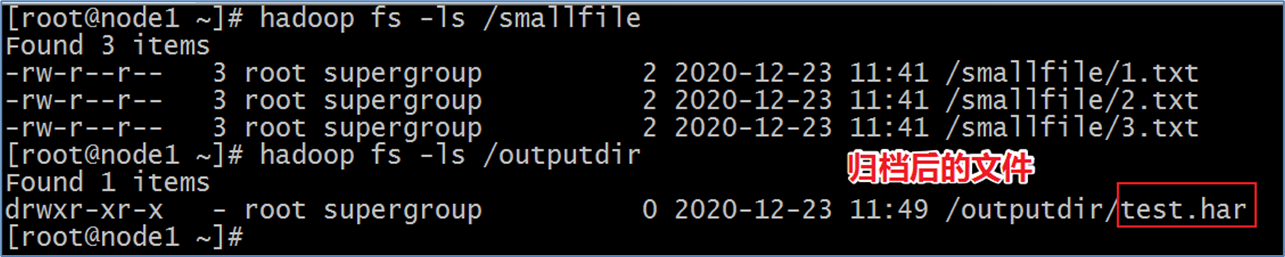
- 这样就会在/outputdir目录下创建一个名为test.har的存档文件。
- 注意:Archive归档是通过MapReduce程序完成的,需要启动YARN集群。
4、查看归档之前的样子
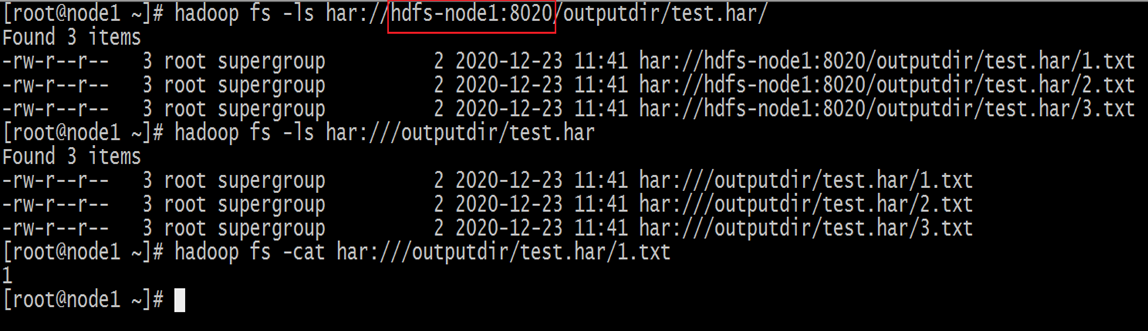
- 在查看har文件的时候,如果没有指定访问协议,默认使用的是hdfs:// ,此时所能看到的就是归档之后的样子
- 此外,Archive还提供了自己的har uri访问协议。如果用har uri去访问的话,索引、标识等文件就会隐藏起来,只显示创建档案之前的原文件:
Hadoop Archives的URI是:har://scheme-hostname:port/archivepath/fileinarchive
- lscheme-hostname格式为 hdfs-域名:端口
5、提取档案
- 按顺序解压存档(串行)
hadoop fs -cp har:///outputdir/test.har/* /smallfile1
- 要并行解压存档,请使用DistCp,对应大的归档文件可以提高效率:
hadoop distcp har:///outputdir/test.har/* /smallfile2

6、使用注意事项
- Hadoop archive是特殊的档案格式。一个Hadoop archive对应一个文件系统目录。archive的扩展名是*.har;
- 创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群上运行创建档案的命令;
- 创建archive文件要消耗和原文件一样多的硬盘空间;
- archive文件不支持压缩,尽管archive文件看起来像已经被压缩过;
- archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件。事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日;
- 当创建archive时,源文件不会被更改或删除;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现