


本文转自知乎
作者:苏格兰折耳喵
—————————————————————————————————————————————————————
大家在做某个领域的舆情口碑监测时,非常关键的一步就是制作舆情模型(也叫关键词方案,一般通过“或”“与”“非”等布尔逻辑连接起来,另外还附带排除词方案,用于过滤垃圾信息),因为购置舆情系统只是一个“空壳”,需要用舆情模型注入灵魂,检索到符合业务需求且相关性极强的信息,这是监测和分析的前提条件。
根据我的日常实践,以“汽车行业”的舆情模型的构建为例,粗略步骤如下:
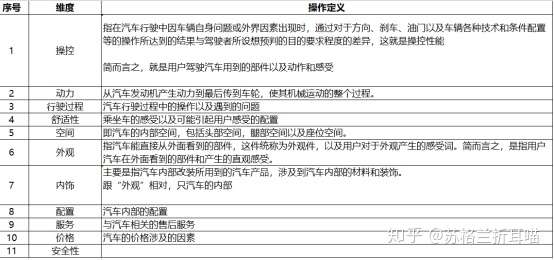
1. 定维度。通过调研垂直领域网站,发现该领域的结构/体系,并遵从咨询界的黄金法则---MECE原则,即“不重复、无遗漏”,主要针对消费者/用户关心的方面,并在桌面调研中建立起符合业务需求的维度,并明确每个维度的概念、范围和操作性定义(如下表所示)“。这一步是非常关键的,决定下面的各个维度词汇的选择。
2. 充词汇。爬虫垂直网站上的用户评论语料或者专业评测文章,分词后进行检索、词向量模型训练,用来探索领域内专有词汇,这一步是发散,要尽可能用检索到的词汇来丰富各维度。另:可采用业界开源的词向量模型,如腾讯AI lab近期开源的16g包含各领域语料的词向量模型。举个例子,通过词向量模型,找到“动力”相关的词汇,其中有很多是其下位词。

3. 精筛选。这一步要进行收敛,尽可能的保证各维度下的词汇具有“领域专有性”,也就是能独立代表各个维度。具体方法可以是人工挑拣,或者是利用机器学习的词聚类,最好是人机相辅的做法。
4. 做校验。将各维度的词向量通过或与非的布尔逻辑整理成关键词方案后,放置到舆情监测系统中进行测试,通过检测到的结果对监测方案进行校正,并查找到各维度对应的排除词,保证检索结果的准确性。
5. 重复-复盘-更新。以上流程是一个循环往复的闭环,需要不断更新迭代。
注:
(1)在不超过监测方案字数的情况下,最好最大限度的保留具有“语义独立性”的长词/领域专有词,这通常是在该维度方案字数较少的情况。
(2)在精简方案、合并关键词的时候,需要注意以下两种情形:
1)形容词+名词,可分离,提取核心主体词的情形,如从“多功能行车电脑”中可以抽离出“行车电脑”这个核心主体词,“多功能”是对后者的修饰。
2)不可分离,已经是最小语义单位,如“刹车片”和“刹车”,一个是“配置”里的,另一个是“行驶过程”里的。

