

t-io 学习笔记(一)
基础介绍理解篇
序:本文也是在t-io官网学习的基础上写的理解学习笔记;1.什么是t-io?
t-io是基于JVM的网络编程框架,和netty属同类,所以netty能做的t-io都能做,考虑到t-io是从项目抽象出来的框架,所以t-io提供了更多的和业务相关的API,大体上t-io具有如下特点和能力.
- 内置完备的监控和流控能力
- 内置半包粘包处理
- 一骑绝尘的资源管理能力
- 内置心跳检查和心跳发送能力
- 内置IP拉黑
- 一流性能和稳定性(第三方权威平台TFB提供性能测试和稳定性服务)
- 极其稳定的表现(很多用户还是停在t-io 1.x版本,就是因为太过稳定,不想变动)
- 内置慢攻击防御
- 唯一一个内置异步发送、阻塞发送、同步发送的网络框架
- 唯一内置集群分发消息的能力
- 独创的多端口资源共享能力(譬如一个端口是websocket协议,一个端口是私有的im协议,这两个端口的资源可以共享,这对协议适配极其有用)
- 独创协议适配转换能力(让基于websocket和基于socket的应用看起来像是同一个协议)
- 独一档的资源和业务绑定能力:绑定group、绑定userid、绑定token、绑定bsId,这些绑定几乎囊括了所有业务需求

1. tio-utils
- tio-utils是他的作者在项目开发中积累的部分工具类
- 里面有少部分代码是在开源许可范围内摘自第三方开源项目代码的,还有部分代码是其它开源作者提供的,譬如hutool的作者路神就提供了许多类,在此也是表示感谢!笔者这么做,仅仅是因为广大用户强力要求tio减少第三方依赖!
- 当然笔者更愿意使第三方工具类,譬如hutool,毕竟和hutool的作者是基友
- 在tio-utils中目前鄙人用得最多的Cache
- 首先这个Cache是个门面——把市面上的各路Cache统一成了ICache,操作方法统一了,
- 其次它内置了一级cache,两级cache,并且性能极好、操作省心、稳定性也在大量项目中得到了考验
- 哦,这么说,其实就是想挑战J2cache,不过tio-utils也把J2cache门面化了^_^
2. tio-core
- 大家口中的t-io或tio指的就是tio-core,这个一定要记住,要不然会混掉
- tio-core是依赖tio-utils的
- tio-core是基于java aio的网络编程框架(很多人说t-io是基于netty,大家不要听信这样不负责任的言论)
- 如果你知道netty是啥,那理解tio-core就很容易了,因为tio-core是和netty类似的框架
3. tio-http-common
- 一个给tio-http-server和tio-http-client共用的工程,大家可以略过
4. tio-http-server
- 基于tio-core(为啥不说是基于tio-http-common?怎么说都可以)实现的http服务器
- 内置了极易使用的MVC框架
- 内置了流控、拉黑、forward、拦截器等常用能力
- 性能优秀,前面已经有地方描述了它在TFB上的性能表现,在TFB上tio-mvc的性能远超使用人群最多的springmvc,当然这不是说springmvc不优秀,而是说性能到这份上了,再说性能没啥意义!
5. tio-websocket-common
- 一个给tio-websocket-server和tio-websocket-client共用的工程,大家可以略过
6. tio-webpack-core
- 笔者在tio-http-server的基础之上依赖freemarker实现的类似nodejs webpack的功能,现在还没完全封装到位,就笔者一人在用
- 你现在正在浏览的网页就是基于tio-webpack-core的,不信你用右键点击查看源代码,全TM压缩或加密的^_^
- API设计易懂,尽量避免引入自创概念——最大限度降低学习成本
t-io的最大优势
- 内置了丰富的易用的API,开发人员一个方法就能搞定很多业务事情
- 提供了生产级别的showcase示范工程
- 有经验的开发人员稍事修改即可用在生产环境
- 没经验的开发人员可以当作入门的示范代码
- 文档集中在官网,用户不需要到处学习无用的、错误的文档——进一步降低学习成本和试错成本
netty的最大优势
- 大量公有协议的实现
- 大量基于netty的高层框架
官网 提供了大量的,netty 和t-io的比较,这里不再描述;
基础知识:
TCP/IP协议分层模型:
以下是TCP协议模型: 分为7层,t-io官网上说是可以理解四层,这个知识点知道就行了,记了很多次,都没记住;
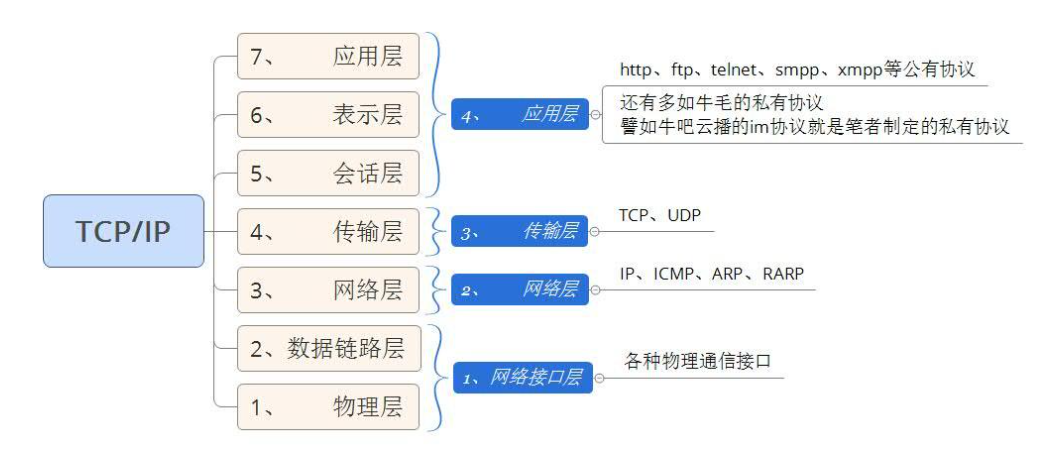
应用层是啥?
- 你想用java写一个网络程序,你写的这个程序就是应用层
- 所以QQ、微信、以及你正在使用的浏览器,都是应用层
传输层是啥
- 传输层要么走TCP协议,要么走UDP协议,没有第三种协议
- TCP协议的通信双方,需要知道彼此都在家呆着,且由客户端主动发起连接
- UDP协议,客户端知道服务器家住在哪,但并不知道服务器在不在家,扔条消息去服务器家,如果服务器不在家这条消息就被丢了
- 应用层把数据丢给传输层后,传输层把数据进行一下包装,包装纸上面写着“源端口、目的端口、序号、确认序号、检验和等TCP自身的数据”
- 传输层把数据给应用层时,会拆开对方的包装纸,应用层只看得到对方应用层发的数据
传输层在往应用层传递数据时,并不保证每次传递的数据是一个完整的应用层数据包(以http协议为例,就是并不保证应用层收到的数据刚好可以组成一个http包),这就是我们经常提到的半包和粘包。传输层只负责传递byte[]数据,应用层需要自己对byte[]数据进行解码,以http协议为例,就是把byte[]解码成http协议格式的字符串。
-
ByteBuffer是nio/aio编程所必须掌握的一个数据结构,也是掌握tio所必须要学会的基础知识。
-
设想你不懂Map,不懂List,不懂Set,那么你在编程领域将会一事无成,同样的道理,如果你不懂ByteBuffer,你无法在nio/aio编程领域立足
ByteBuffer的理解:
ByteBuffer的属性
byte[] buff //buff即内部用于缓存的数组。
position //当前读取的位置。
mark //为某一读过的位置做标记,便于某些时候回退到该位置。
capacity //初始化时候的容量。
limit //当写数据到buffer中时,limit一般和capacity相等,当读数据时,limit代表buffer中有效数据的长度。我们可以把bytebuffer理解成如下几个属性组成的一个数据结构
- byte[] bytes: 用来存储数据
- int capacity: 用来表示bytes的容量,那么可以想像capacity就等于bytes.size(),此值在初始化bytes后,是不可变的。
- int limit: 用来表示bytes实际装了多少数据,可以容易想像得到limit <= capacity,此值是可灵活变动的
- int position: 用来表示在哪个位置开始往bytes写数据或是读数据,此值是可灵活变动的

这里不再过多描述这个了,可以baidu去查查;
半包和粘包:
1.半包:
顾名思义,就是收到了半个包,这个时候不足以组成一个应用层的包。就像你要对你喜欢的人说“我喜欢你”,但是因为喝水咽着了,第一次只说了“我”字,第二次说了个“喜”字,第三个次了个“欢你”,那么就发生了半包问题,对方只有等待你说完这4个字后才知道你是想说“我喜欢你”!

2.粘包
-
粘包与半包相反,就是把多个想说的话,一口气说完了,对方反应不过来,得把你的话拆开一条一条地理解
-
用http协议为例,展示粘包场景

说明:http协议是一来一回的,所以正常场景是不会有粘包的,但pipeline模式下是允许一方连续发多个请求的,所以会有粘包产生
为何坑人无数
-
初涉网络编程的同学,往往认为每次收到的数据刚好是一个完整的数据包
-
于是当网络不好,或是消息包过大时,半包的情况就发生了,而程序并没有考虑到半包的情况,结果就是解码失败,导致消息丢失
-
当通信的对方把多条业务数据包放在一个TCP包中发过来时,粘包就产生了,而程序没有考虑到一次TCP收包会收到多个业务包,从而解析到第一个业务包后把后面的业务包丢弃了
-
百度一下半包粘包,一定会搜到很多记录,这也证明这俩货确实坑人无数,所以看完本节内容,你还会继续犯半包粘包的错吗
半包、粘包所以在通讯的时候,可能会出现,有时候出错,或数据丢失的时候,要考虑到;

