

[机器学习] sklearn支持向量机
支持向量机SVM(Support Vector Machine)是一种用来进行模式识别、分类、回归的机器学习模型。
SVM原理描述
模型表示
以一个客户好坏分类为案例,客户信息如下所示:

客户信息数轴表示如下所示:

以数学表达式对上述信息进行描述,可以用下式进行表示:
然而该方法对于大型数据集容易发生拟合,且过于复杂。
因此可以忽略一些点,进行一刀切,如下所示:

但是该方法容易导致错分率高。因此SVM就是找一种方式正确的描述分类方程。
超平面

因此该超平面的公式可以用下式进行表示:
其中v是样本向量,在二维空间v=(x,y),在三维空间v=(x,y,z)。w是参数向量,在二维空间w=(A,B),在三维空间w=(A,B,C)。

因此上述距离公式可以表示为:
超平面确定
SVM目标是找到一个超平面,使得其在两个类中间分开。并使得该超平面到两边的距离最大,如下图所示:
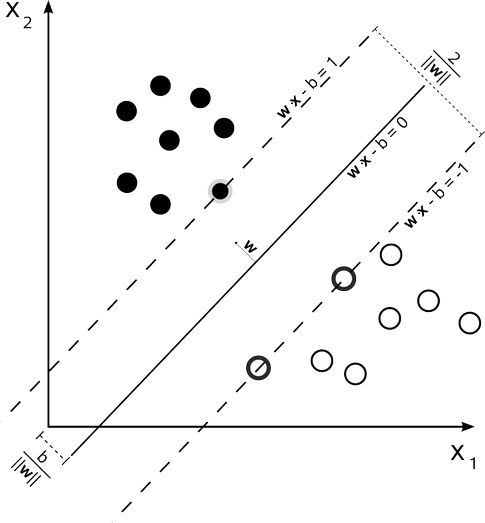
但是如果对于线性不可分的情况,如下图所示:
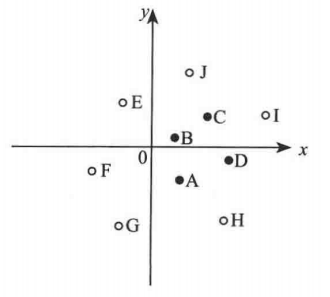
此时上述方式无法确定超平面。在SVM在则是通过升维的方式解决。例如:

因此SVM在一维空间上解决线性不可分割的问题是把函数映射到二维空间。同样在n维空间的线性不可分割问题映射到n+1维空间。而这种映射分类函数,在svm用核函数(kernel)进行构造。
因此支持向量机具体算法步骤为:
- 把所有的样本和其标记交给算法进行训练
- 如果线性可分则直接找出超平面
- 如果线性不可分,进行映射找出超平面
- 得到超平面表达式,进行分类回归
sklearn实现
在sklearn支持向量机主要用SVC类支持。SVC所支持的和函数有linear(线性和函数)、rbf(径向基核函数)、sigmoid(神经元激活函数)等,通常推荐使用rbf函数。以客户评价为例代码如下:
from sklearn import svm
import numpy as np
#年龄
X = np.array([[34, 33, 32, 31, 30, 30, 25, 23, 22, 18]])
X = X.T
#质量
y = [1, 0, 1, 0, 1, 1, 0, 1, 0, 1]
clf = svm.SVC(kernel='rbf').fit(X, y)
p = [[30]]
print(clf.predict(p)) #1
函数其他参数改动可参考官网文档:svm
本文来自博客园,作者:落痕的寒假,转载请注明原文链接:https://www.cnblogs.com/luohenyueji/p/16993307.html




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全网最简单!3分钟用满血DeepSeek R1开发一款AI智能客服,零代码轻松接入微信、公众号、小程
· .NET 10 首个预览版发布,跨平台开发与性能全面提升
· 《HelloGitHub》第 107 期
· 全程使用 AI 从 0 到 1 写了个小工具
· 从文本到图像:SSE 如何助力 AI 内容实时呈现?(Typescript篇)