

[深度学习] 深度学习优化器选择学习笔记
本文主要展示各类深度学习优化器Optimizer的效果。所有结果基于pytorch实现,参考github项目pytorch-optimizer(仓库地址)的结果。pytorch-optimizer基于pytorch实现了常用的optimizer,非常推荐使用并加星该仓库。
文章目录
- 1 简介
- 2 结果
- A2GradExp(2018)
- A2GradInc(2018)
- A2GradUni(2018)
- AccSGD(2019)
- AdaBelief(2020)
- AdaBound(2019)
- AdaMod(2019)
- Adafactor(2018)
- AdamP(2020)
- AggMo(2019)
- Apollo(2020)
- DiffGrad*(2019)
- Lamb(2019)
- Lookahead*(2019)
- NovoGrad(2019)
- PID(2018)
- QHAdam(2019)
- QHM(2019)
- RAdam*(2019)
- Ranger(2019)
- RangerQH(2019)
- RangerVA(2019)
- SGDP(2020)
- SGDW(2017)
- SWATS(2017)
- Shampoo(2018)
- Yogi*(2018)
- Adam
- SGD
- 3 评价
- 4 参考
1 简介
pytorch-optimizer中所实现的optimizer及其文章主要如下所示。关于optimizer的优化研究非常多,但是不同任务,不同数据集所使用的optimizer效果都不一样,看看研究结果就行了。
为了评估不同optimizer的效果,pytorch-optimizer使用可视化方法来评估optimizer。可视化帮助我们了解不同的算法如何处理简单的情况,例如:鞍点,局部极小值,最低值等,并可能为算法的内部工作提供有趣的见解。pytorch-optimizer选择了Rosenbrock和Rastrigin 函数来进行可视化。具体如下:
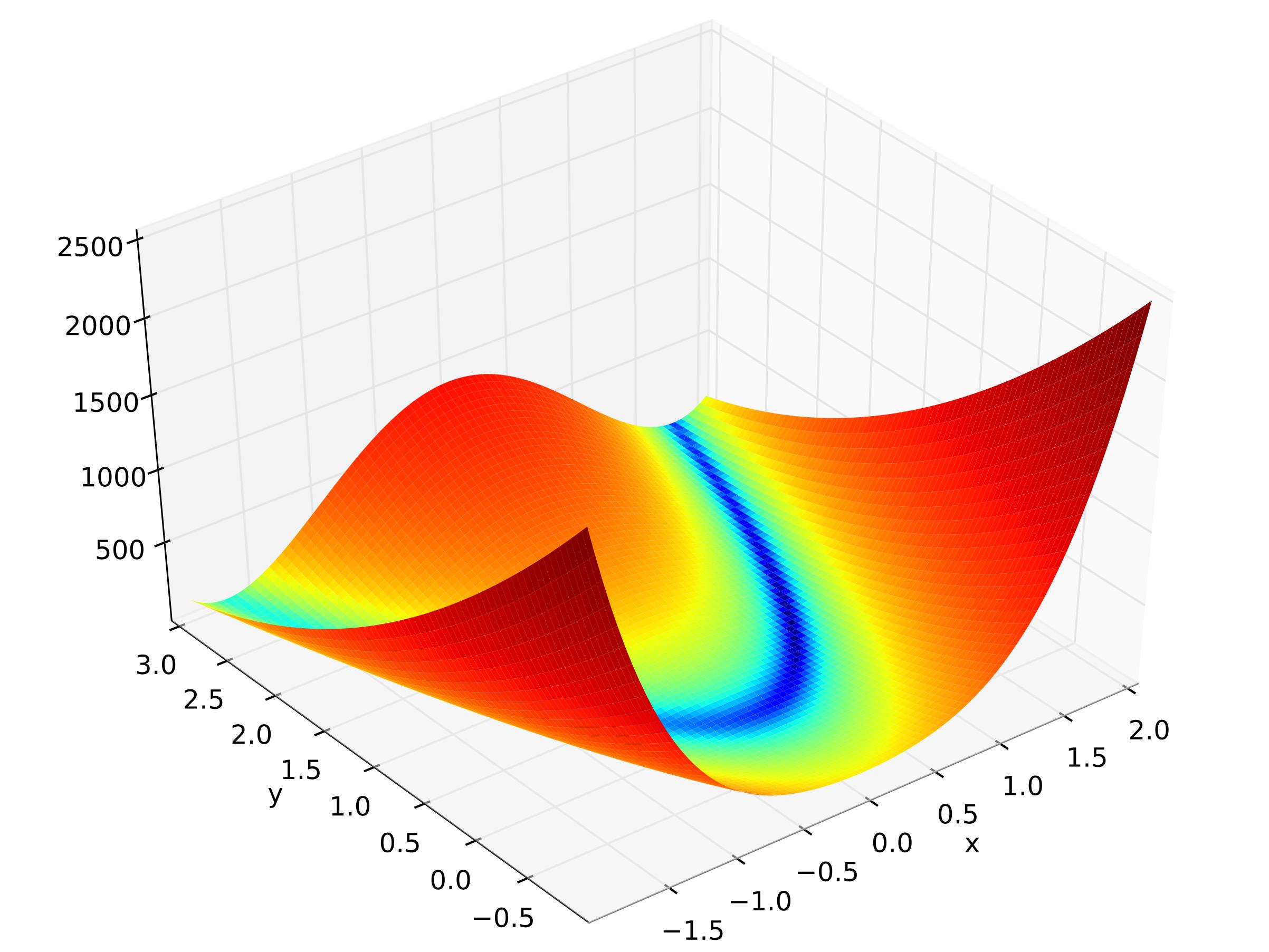
- Rosenbrock(也称为香蕉函数)是具有一个全局最小值(1.0,1.0)的非凸函数。整体最小值位于一个细长的,抛物线形的平坦山谷内。寻找山谷是微不足道的。但是,要收敛到全局最小值(1.0,1.0)是很困难的。优化算法可能会陷入局部最小值。
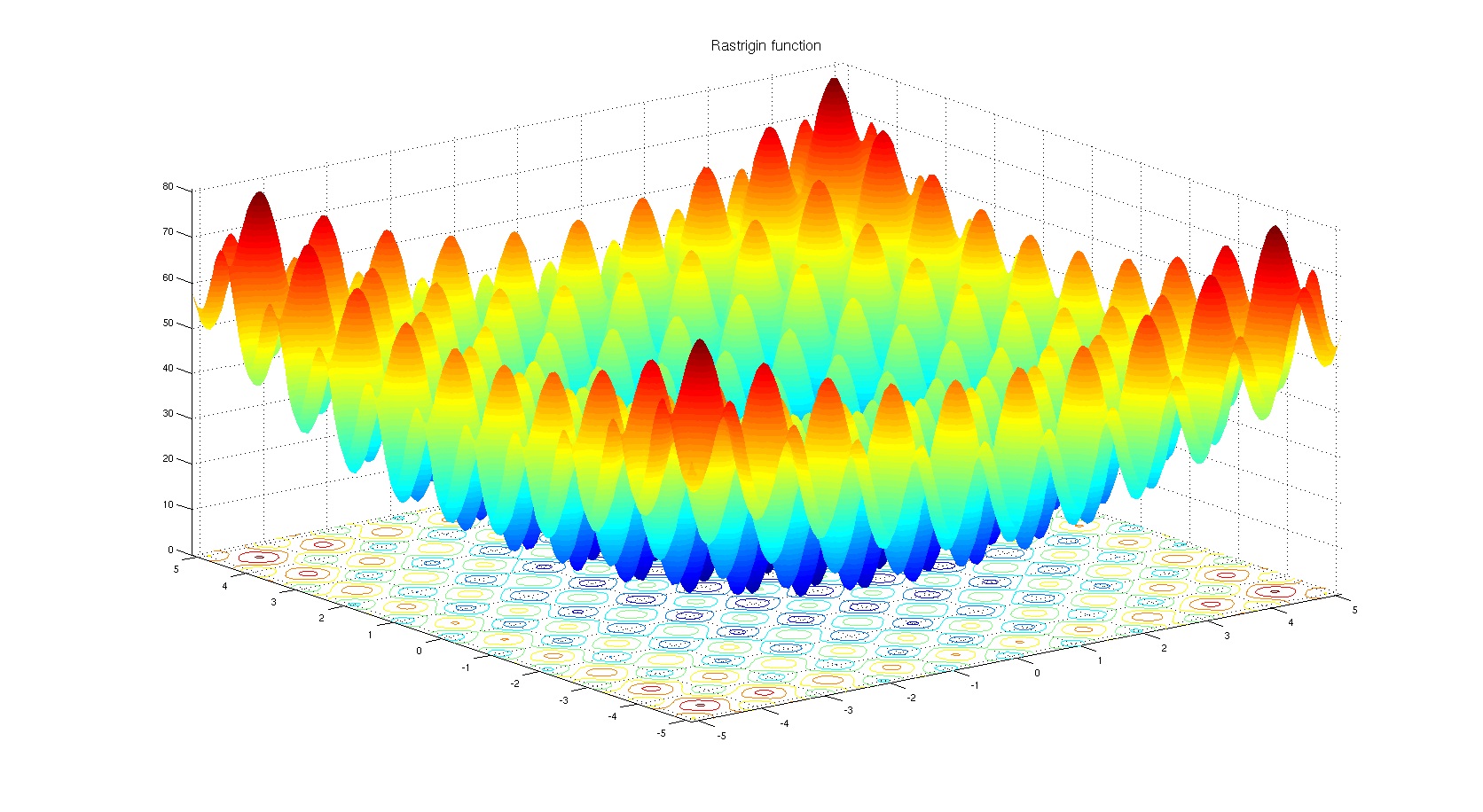
- Rastrigin函数是非凸函数,并且在(0.0,0.0)中具有一个全局最小值。由于此函数的搜索空间很大且局部最小值很大,因此找到该函数的最小值是一个相当困难的工作。
2 结果
下面分别显示不同年份算法在Rastrigin和Rosenbrock函数下的结果,结果显示为Rastrigin和Rosenbroc从上往下的投影图,其中绿色点表示最优点,结果坐标越接近绿色点表示optimizer效果越好。个人觉得效果较好的方法会在方法标题后加*。
A2GradExp(2018)
Paper: Optimal Adaptive and Accelerated Stochastic Gradient Descent (2018)
| rastrigin | rosenbrock |
|---|---|
 |  |
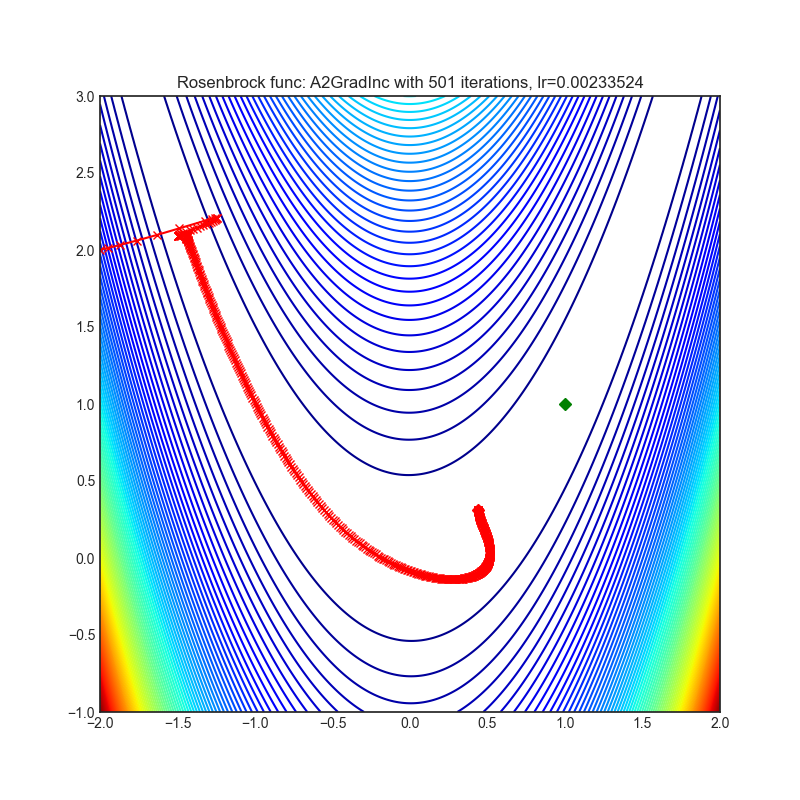
A2GradInc(2018)
Paper: Optimal Adaptive and Accelerated Stochastic Gradient Descent (2018)
| rastrigin | rosenbrock |
|---|---|
 |  |
A2GradUni(2018)
Paper: Optimal Adaptive and Accelerated Stochastic Gradient Descent (2018)
| rastrigin | rosenbrock |
|---|---|
 |  |
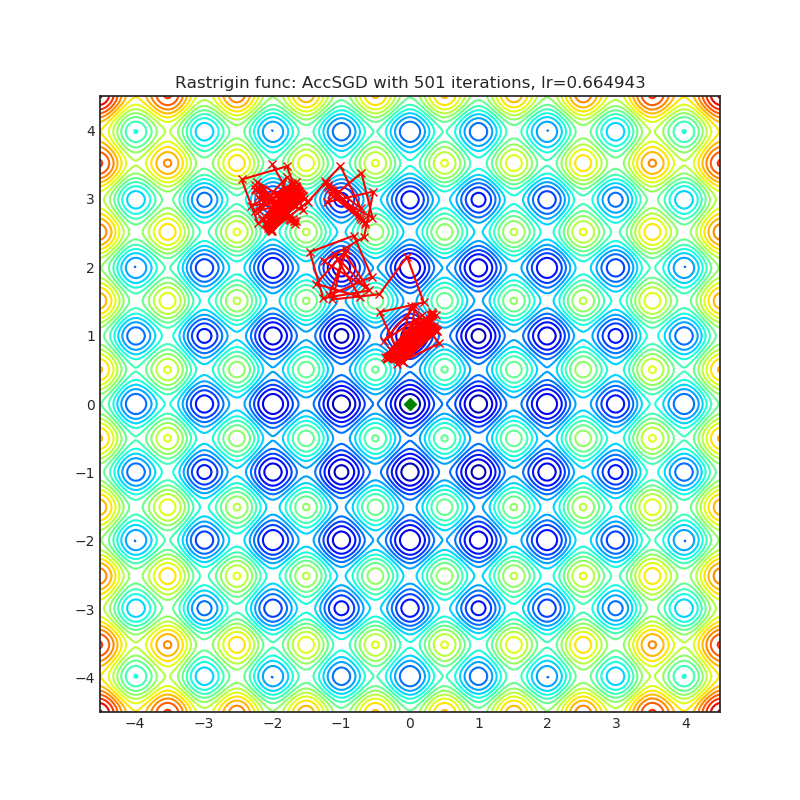
AccSGD(2019)
Paper: On the insufficiency of existing momentum schemes for Stochastic Optimization (2019)
| rastrigin | rosenbrock |
|---|---|
 | 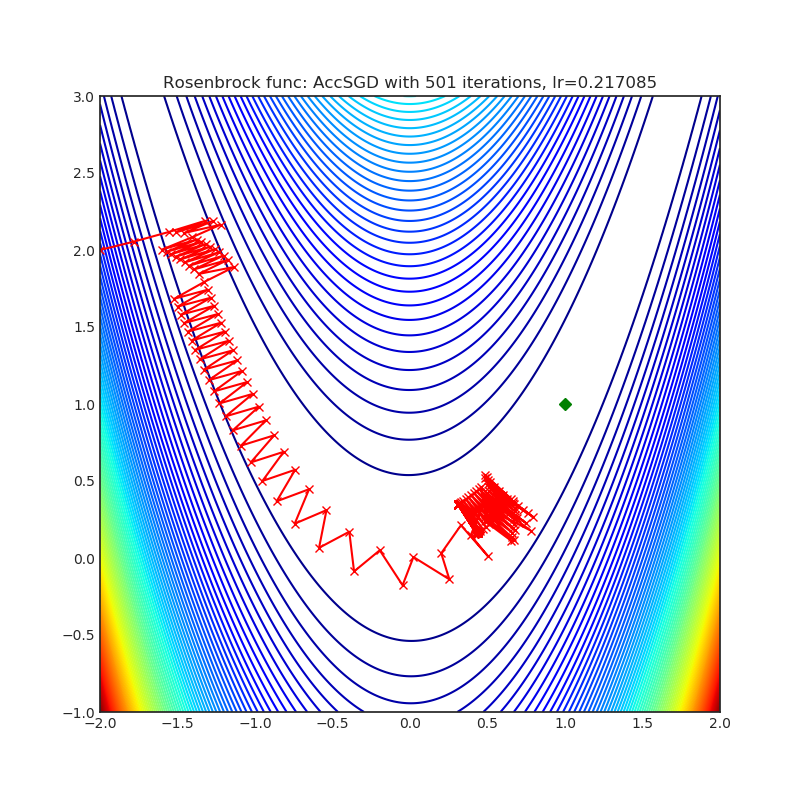 |
AdaBelief(2020)
Paper: AdaBelief Optimizer, adapting stepsizes by the belief in observed gradients (2020)
| rastrigin | rosenbrock |
|---|---|
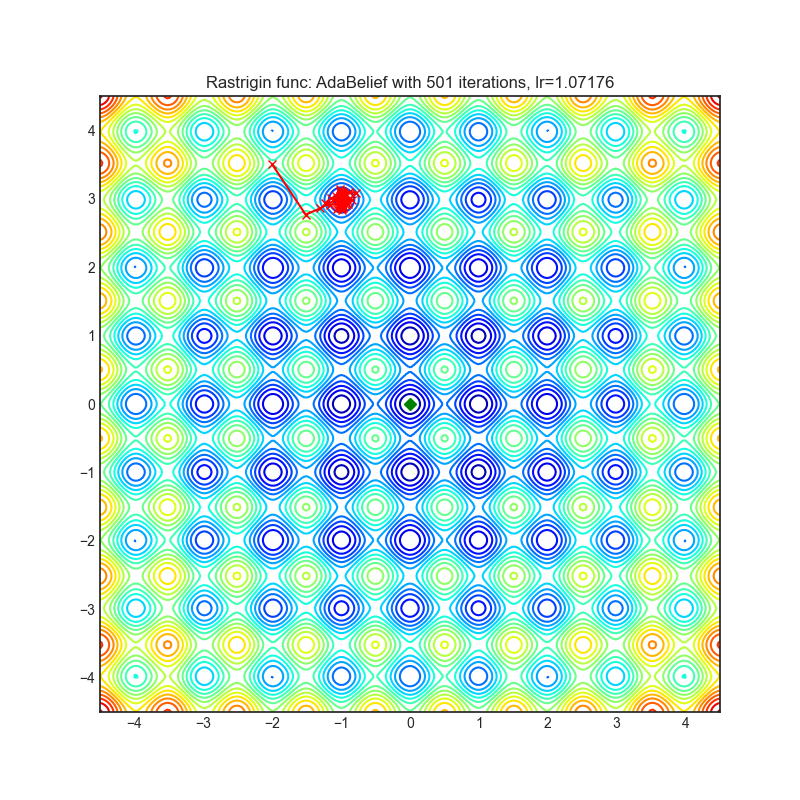 |  |
AdaBound(2019)
Paper: An Adaptive and Momental Bound Method for Stochastic Learning. (2019)
| rastrigin | rosenbrock |
|---|---|
 |  |
AdaMod(2019)
Paper: An Adaptive and Momental Bound Method for Stochastic Learning. (2019)
| rastrigin | rosenbrock |
|---|---|
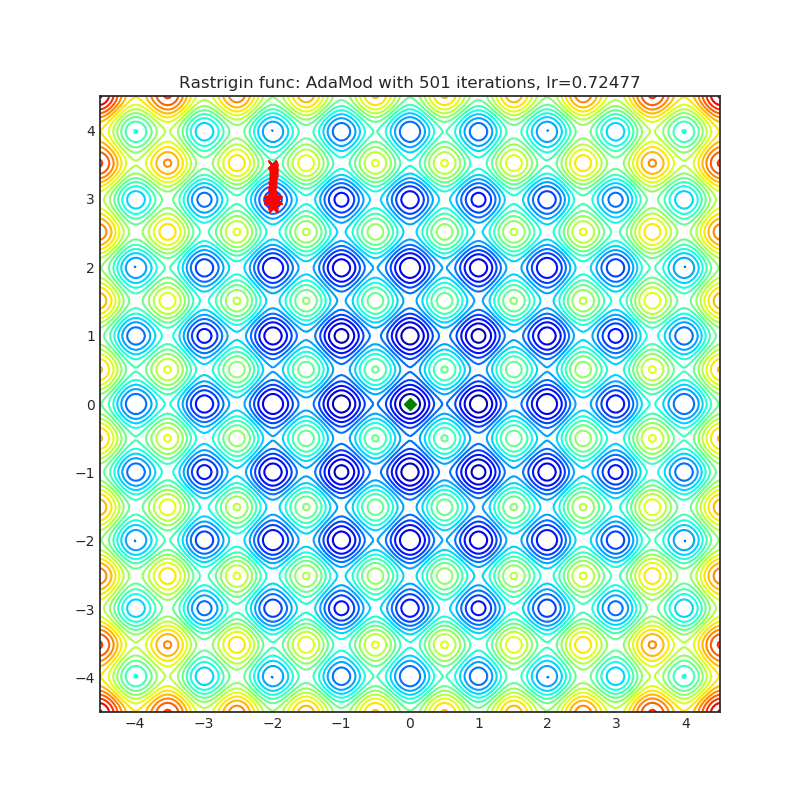 | 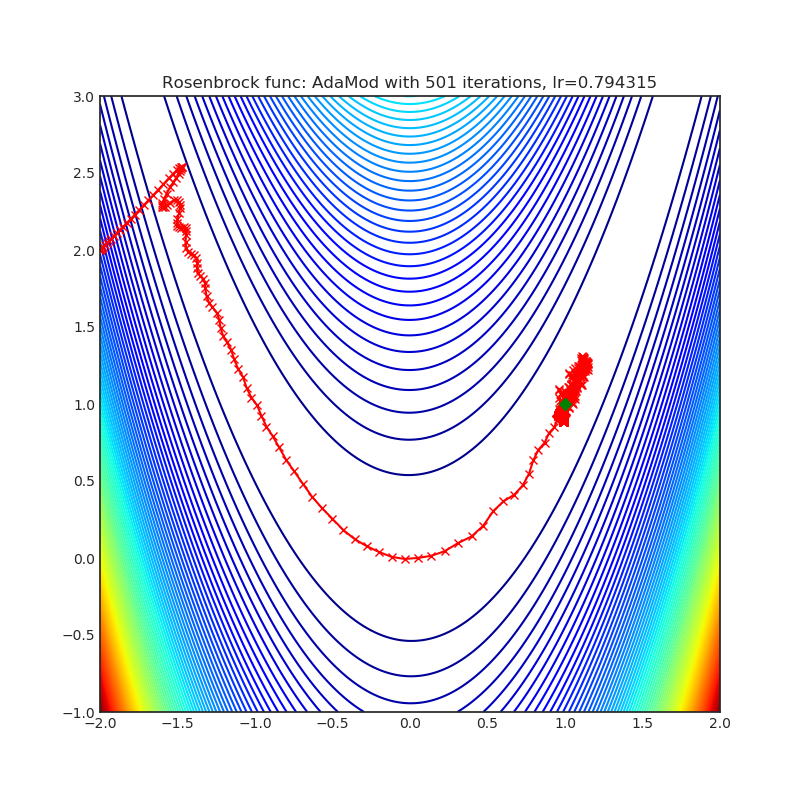 |
Adafactor(2018)
Paper: Adafactor: Adaptive Learning Rates with Sublinear Memory Cost. (2018)
| rastrigin | rosenbrock |
|---|---|
 | 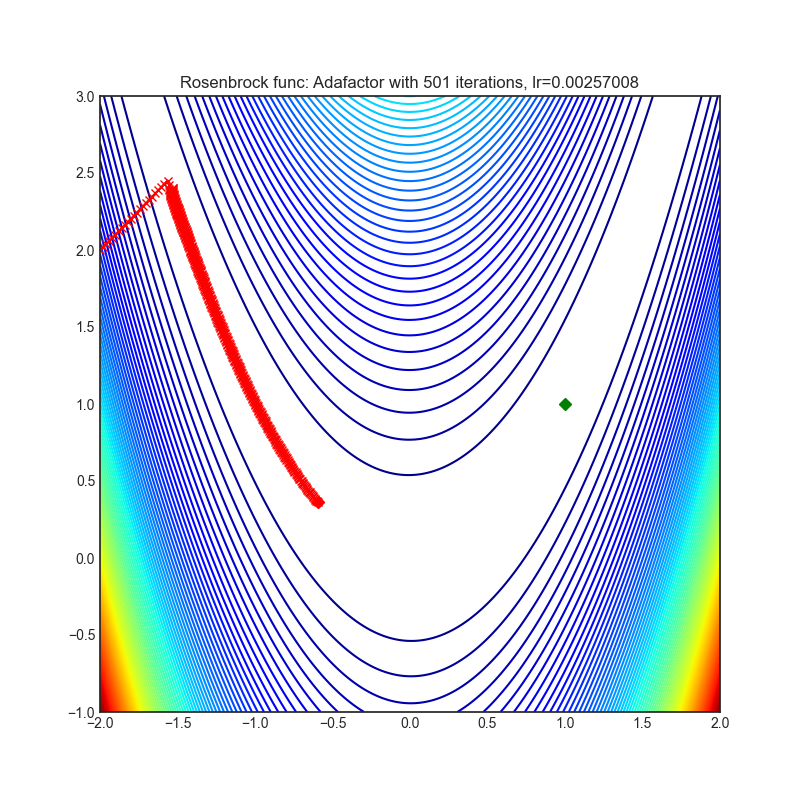 |
AdamP(2020)
Paper: Slowing Down the Weight Norm Increase in Momentum-based Optimizers. (2020)
| rastrigin | rosenbrock |
|---|---|
 | 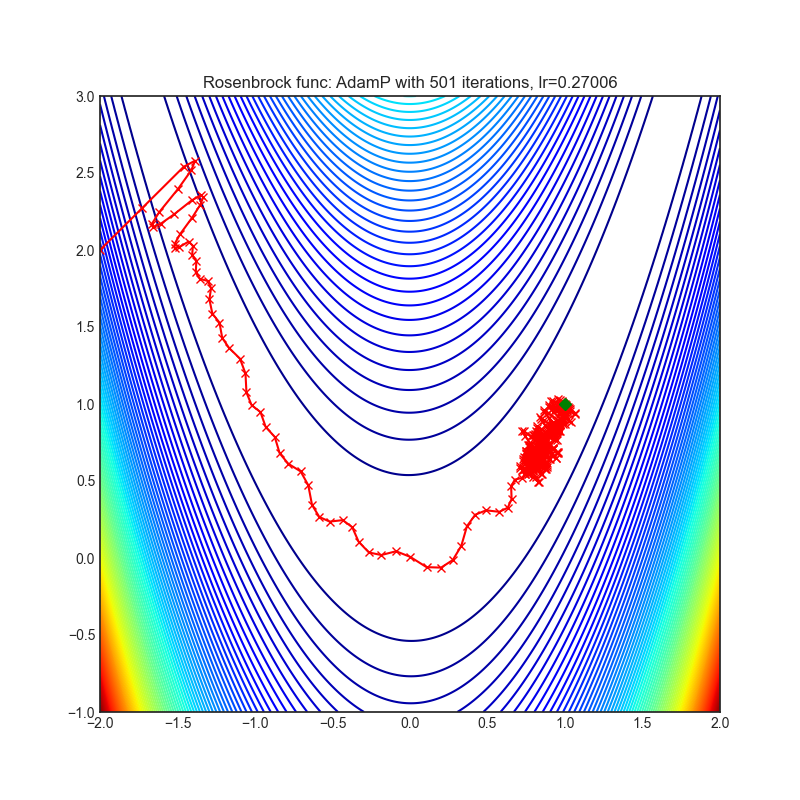 |
AggMo(2019)
Paper: Aggregated Momentum: Stability Through Passive Damping. (2019)
| rastrigin | rosenbrock |
|---|---|
 |  |
Apollo(2020)
Paper: Apollo: An Adaptive Parameter-wise Diagonal Quasi-Newton Method for Nonconvex Stochastic Optimization. (2020)
| rastrigin | rosenbrock |
|---|---|
 | 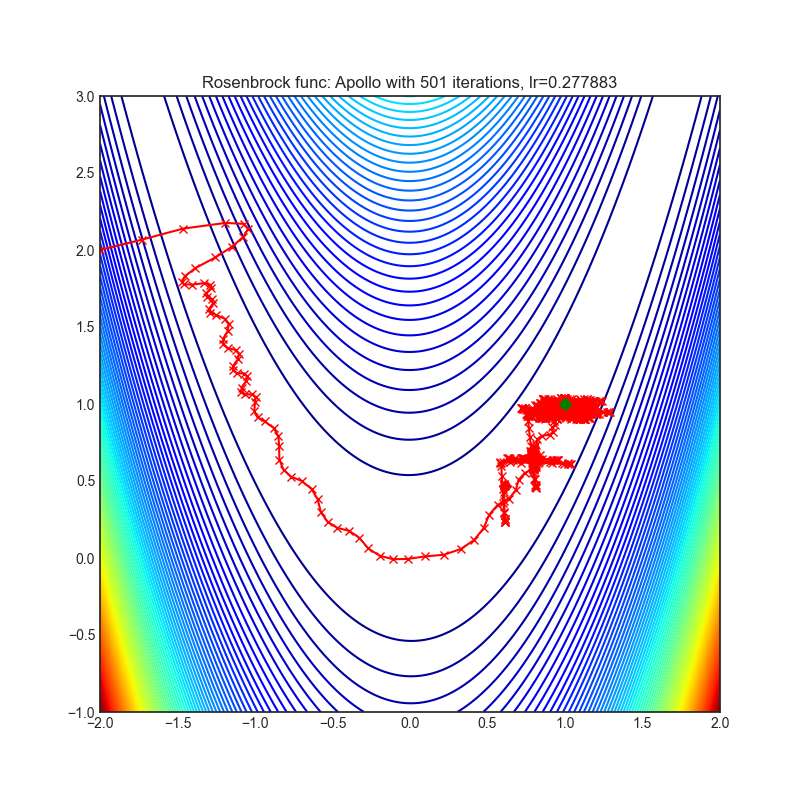 |
DiffGrad*(2019)
Paper: diffGrad: An Optimization Method for Convolutional Neural Networks. (2019)
Reference Code: https://github.com/shivram1987/diffGrad
| rastrigin | rosenbrock |
|---|---|
 |  |
Lamb(2019)
Paper: Large Batch Optimization for Deep Learning: Training BERT in 76 minutes (2019)
| rastrigin | rosenbrock |
|---|---|
 | 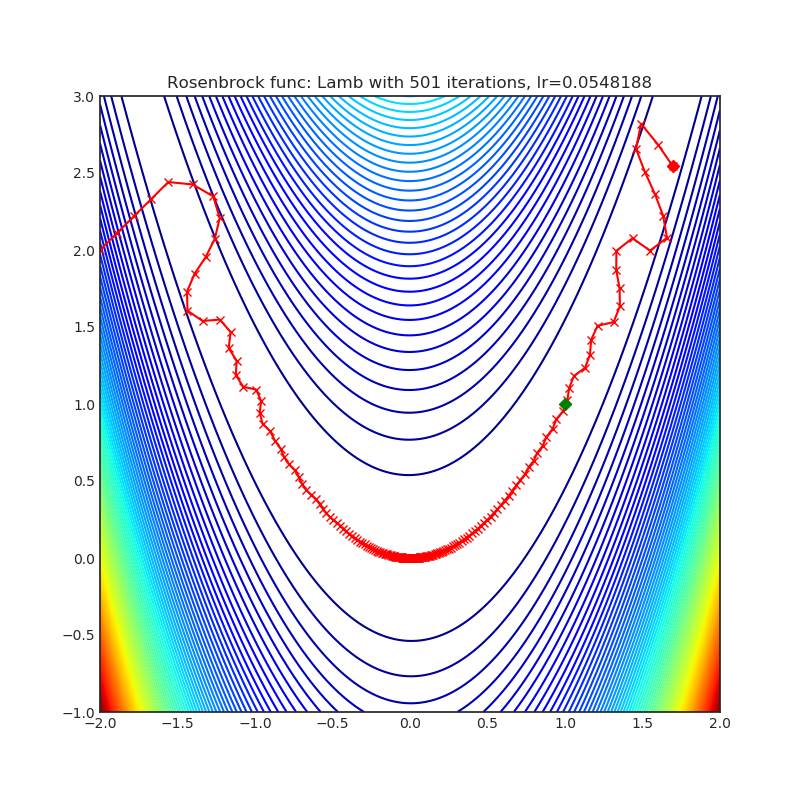 |
Lookahead*(2019)
Paper: Lookahead Optimizer: k steps forward, 1 step back (2019)
Reference Code: https://github.com/alphadl/lookahead.pytorch
非常需要注意的是Lookahead严格来说不算一种优化器,Lookahead需要一种其他优化器搭配工作,这里Lookahead搭配Yogi进行优化
| rastrigin | rosenbrock |
|---|---|
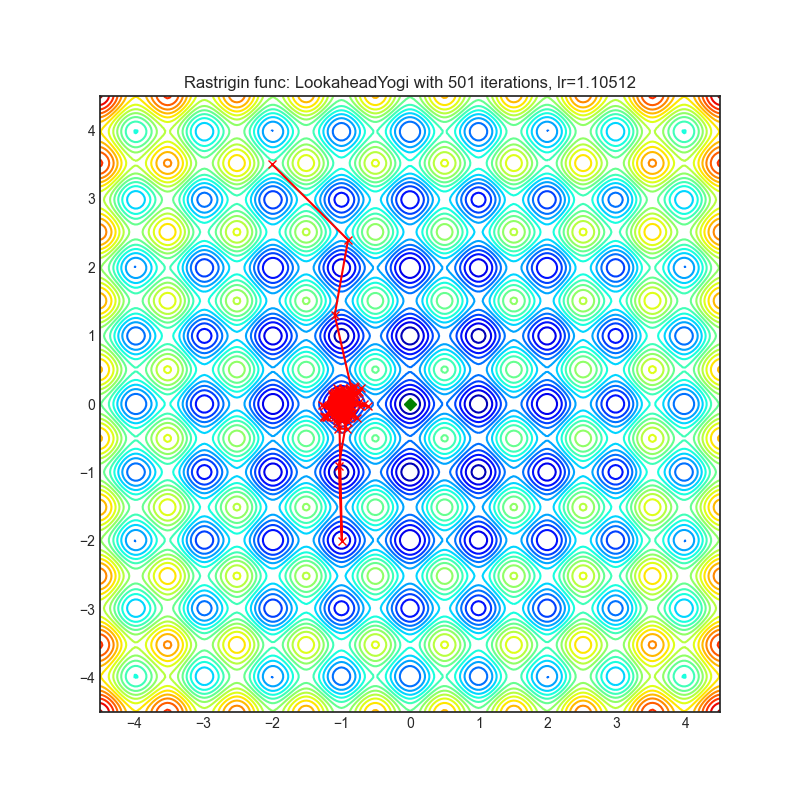 | 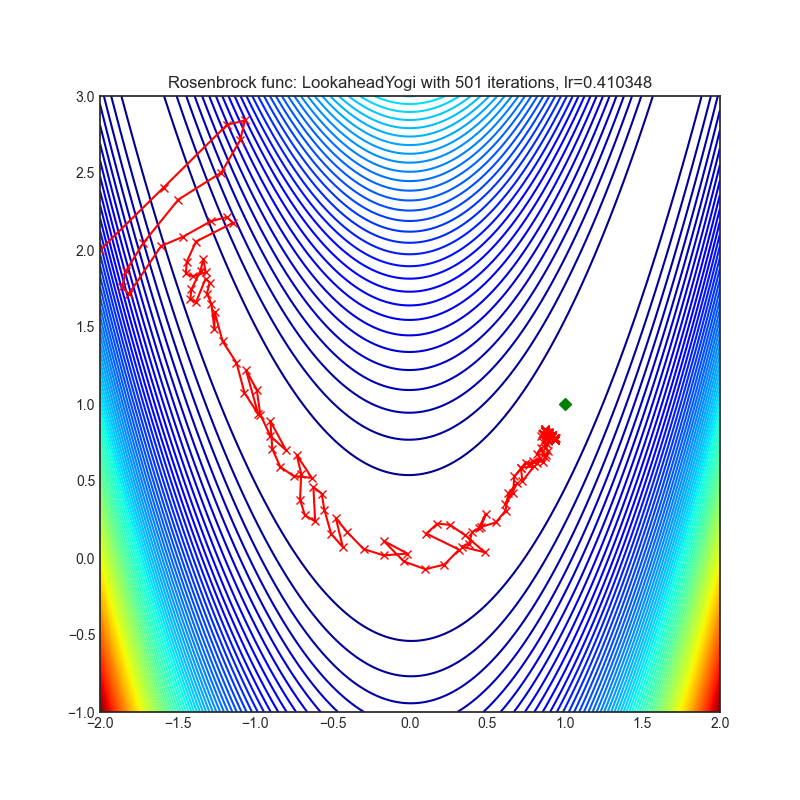 |
NovoGrad(2019)
Paper: Stochastic Gradient Methods with Layer-wise Adaptive Moments for Training of Deep Networks (2019)
| rastrigin | rosenbrock |
|---|---|
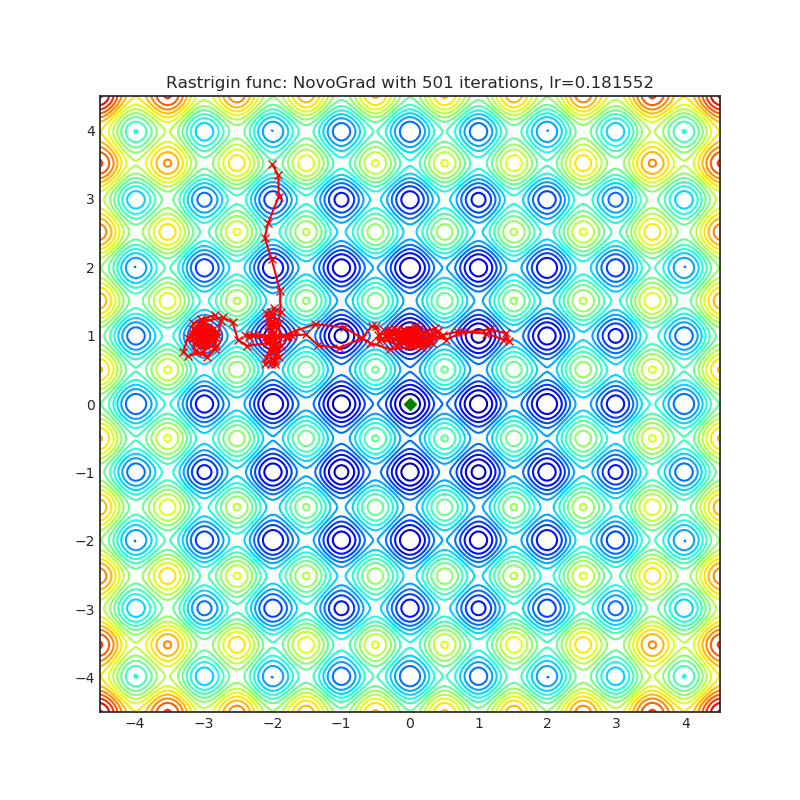 |  |
PID(2018)
Paper: A PID Controller Approach for Stochastic Optimization of Deep Networks (2018)
| rastrigin | rosenbrock |
|---|---|
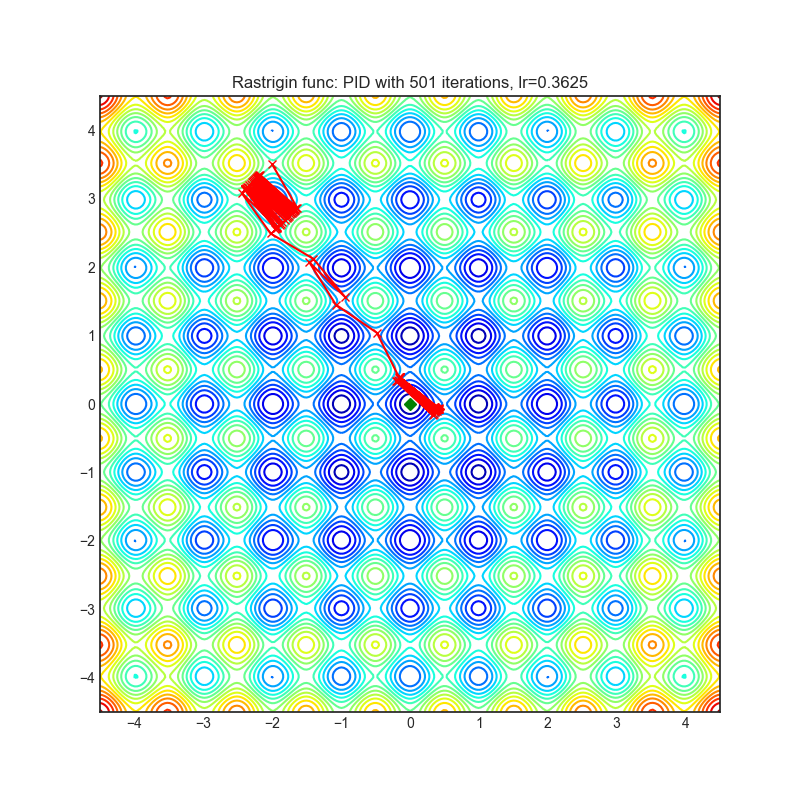 |  |
QHAdam(2019)
Paper: Quasi-hyperbolic momentum and Adam for deep learning (2019)
| rastrigin | rosenbrock |
|---|---|
 | 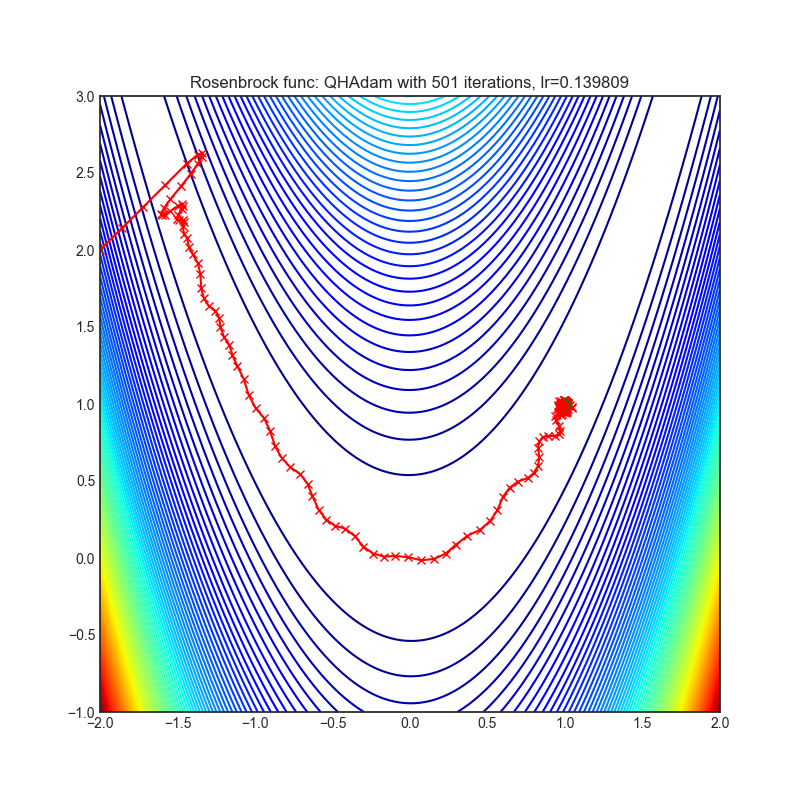 |
QHM(2019)
Paper: Quasi-hyperbolic momentum and Adam for deep learning (2019)
| rastrigin | rosenbrock |
|---|---|
 | 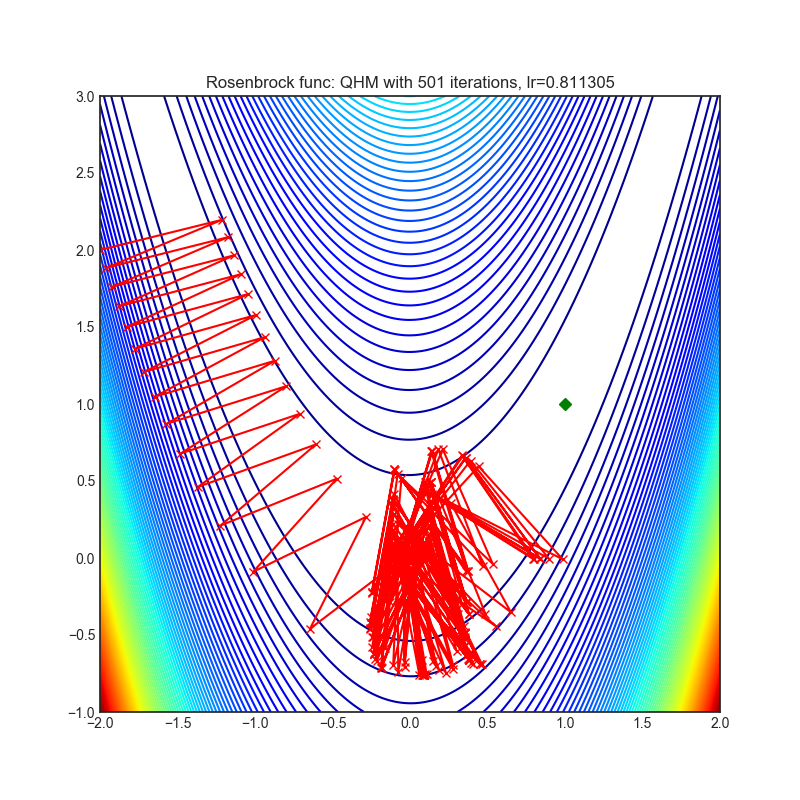 |
RAdam*(2019)
Paper: On the Variance of the Adaptive Learning Rate and Beyond (2019)
Reference Code: https://github.com/LiyuanLucasLiu/RAdam
| rastrigin | rosenbrock |
|---|---|
 |  |
Ranger(2019)
Paper: Calibrating the Adaptive Learning Rate to Improve Convergence of ADAM (2019)
| rastrigin | rosenbrock |
|---|---|
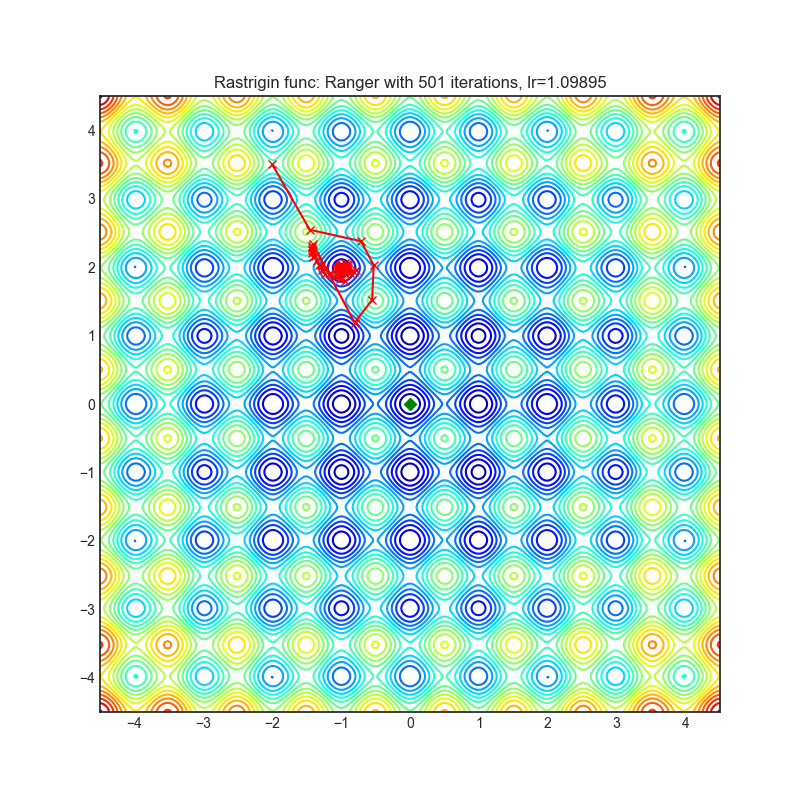 | 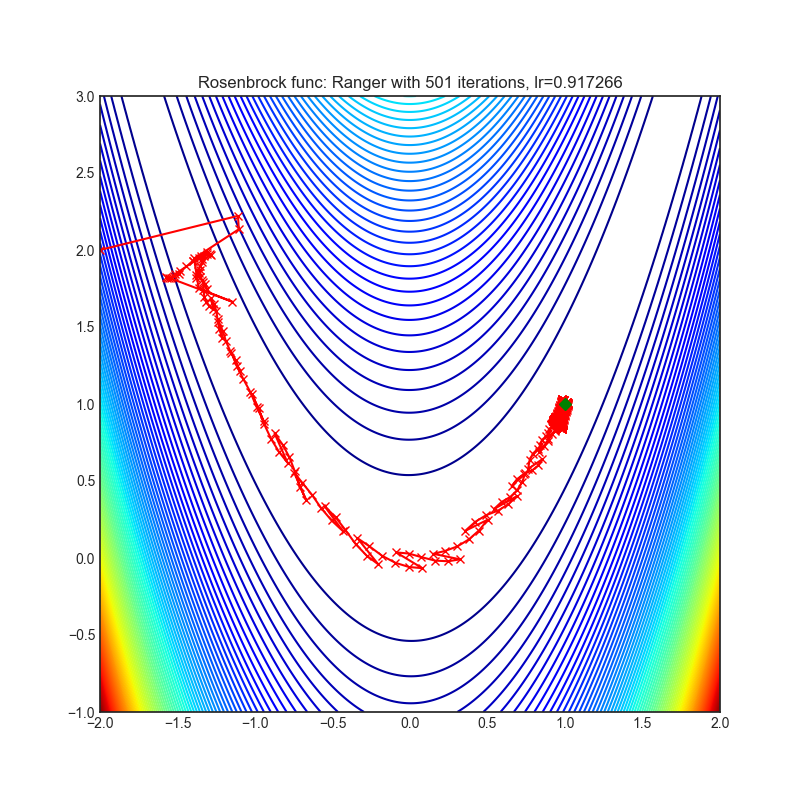 |
RangerQH(2019)
Paper: Calibrating the Adaptive Learning Rate to Improve Convergence of ADAM (2019)
| rastrigin | rosenbrock |
|---|---|
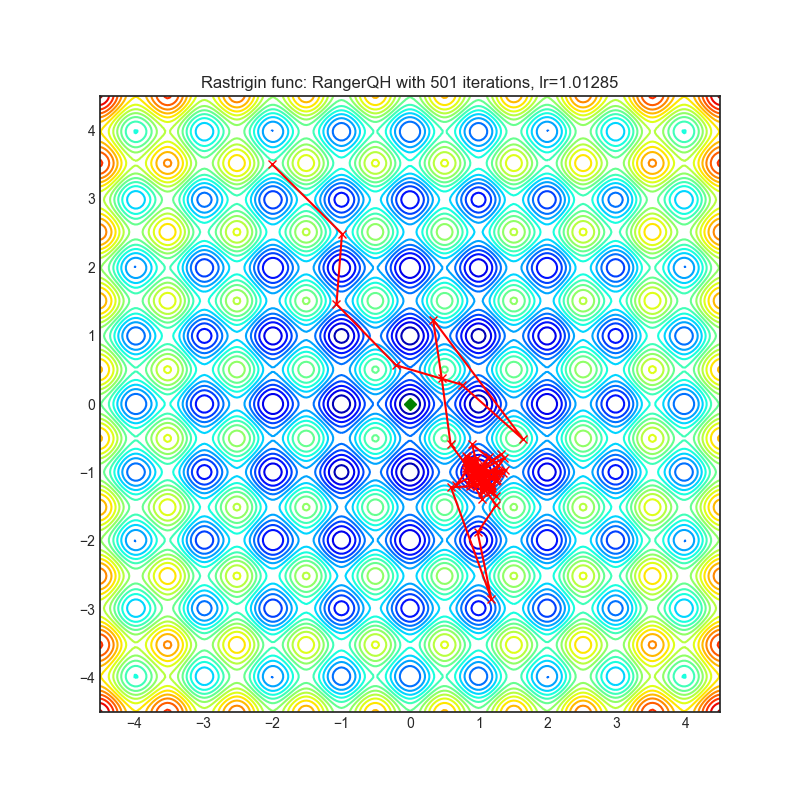 |  |
RangerVA(2019)
Paper: Calibrating the Adaptive Learning Rate to Improve Convergence of ADAM (2019)
| rastrigin | rosenbrock |
|---|---|
 |  |
SGDP(2020)
Paper: Slowing Down the Weight Norm Increase in Momentum-based Optimizers. (2020)
| rastrigin | rosenbrock |
|---|---|
 | 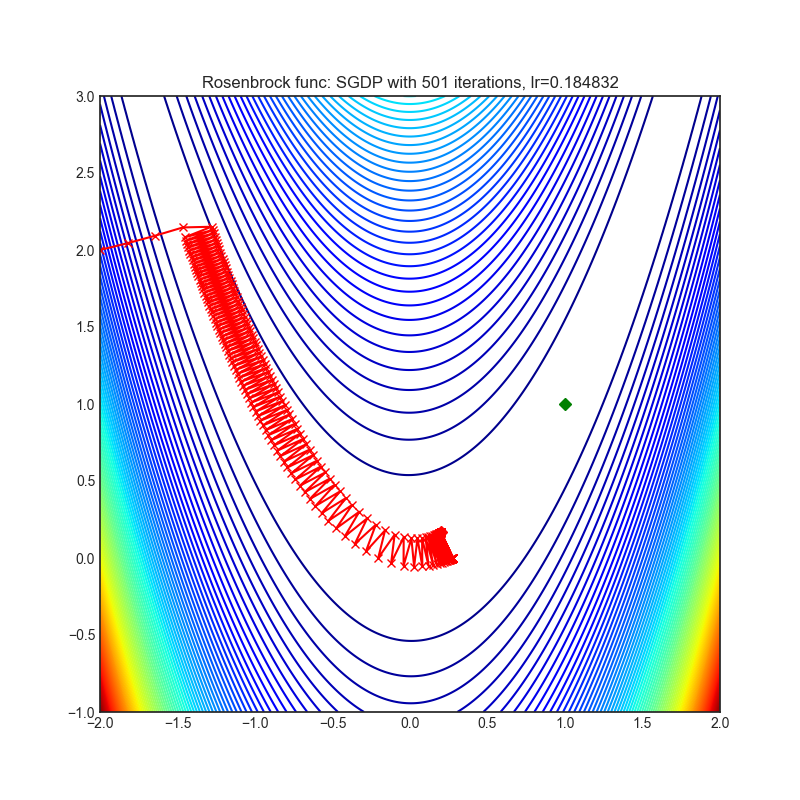 |
SGDW(2017)
Paper: SGDR: Stochastic Gradient Descent with Warm Restarts (2017)
| rastrigin | rosenbrock |
|---|---|
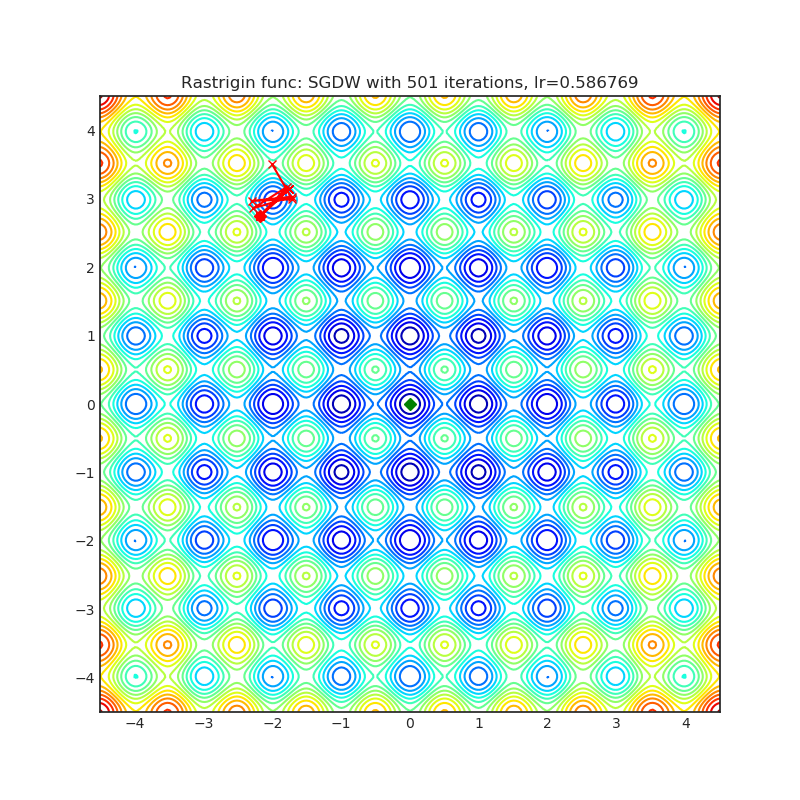 | 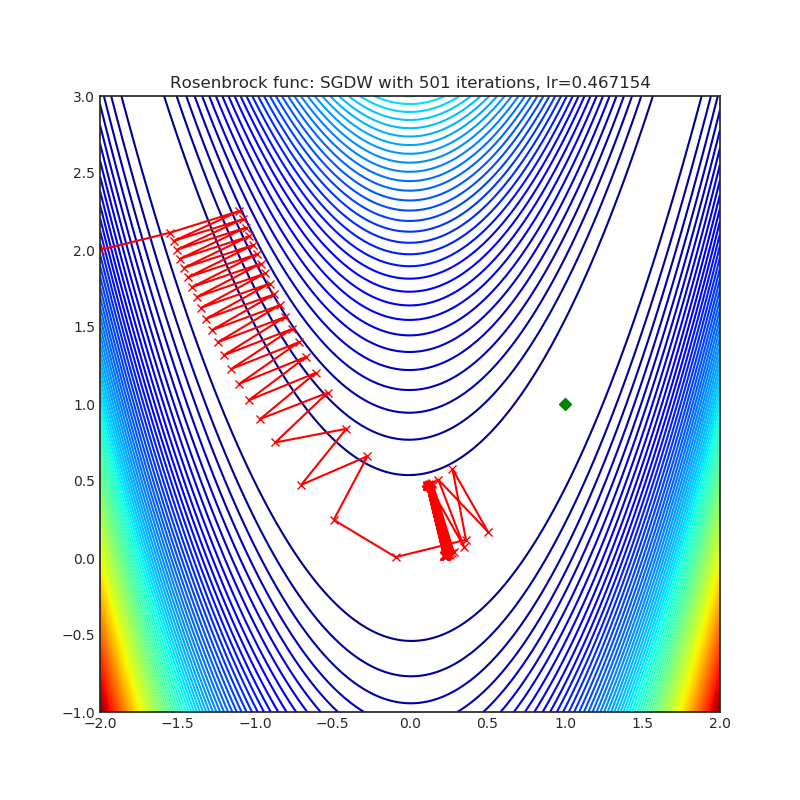 |
SWATS(2017)
Paper: Improving Generalization Performance by Switching from Adam to SGD (2017)
| rastrigin | rosenbrock |
|---|---|
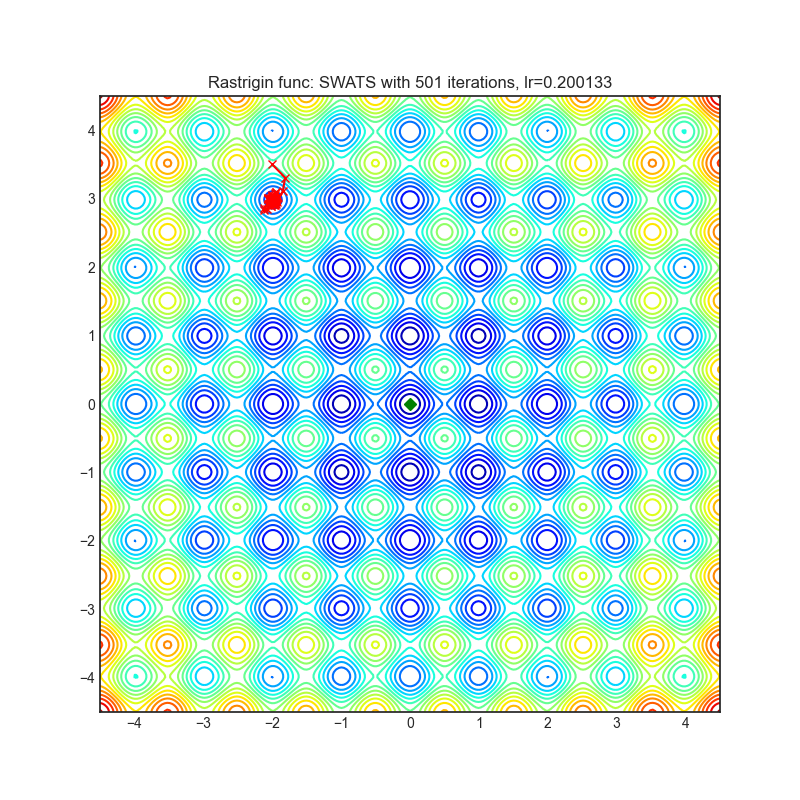 | 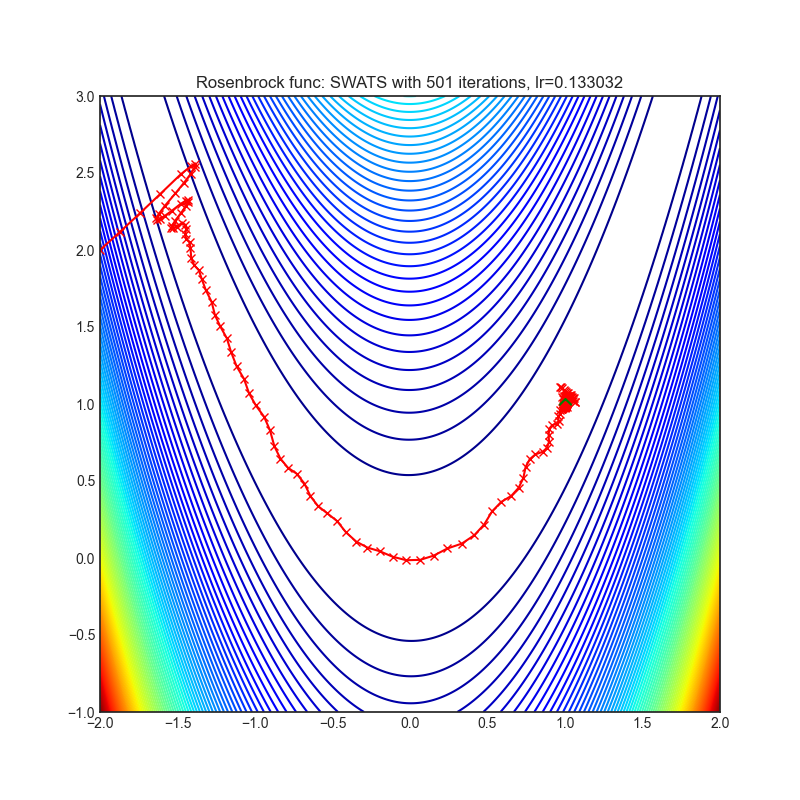 |
Shampoo(2018)
Paper: Shampoo: Preconditioned Stochastic Tensor Optimization (2018)
| rastrigin | rosenbrock |
|---|---|
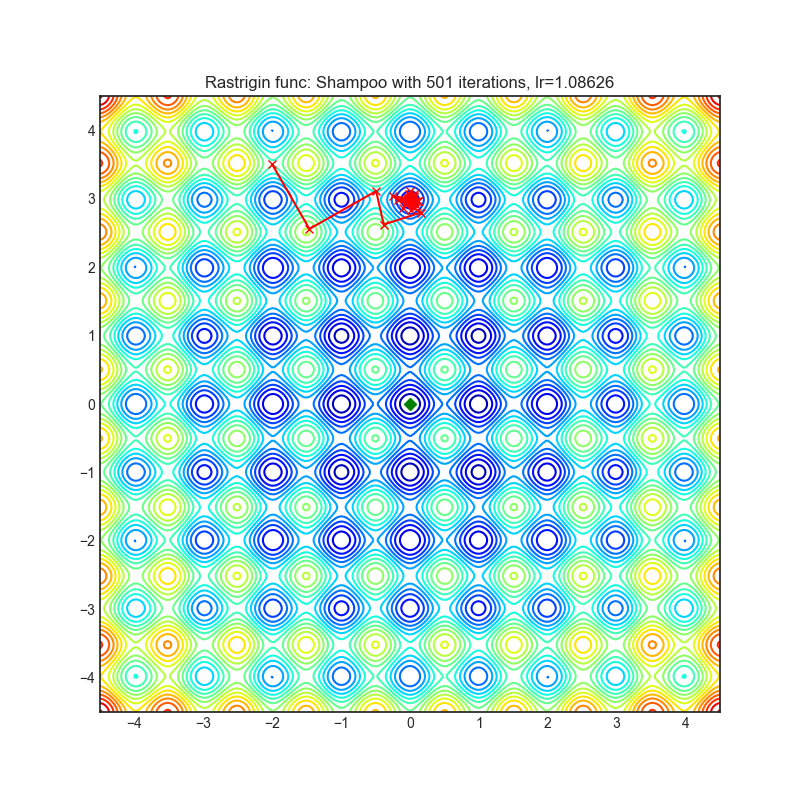 |  |
Yogi*(2018)
Paper: Adaptive Methods for Nonconvex Optimization (2018)
Reference Code: https://github.com/4rtemi5/Yogi-Optimizer_Keras
| rastrigin | rosenbrock |
|---|---|
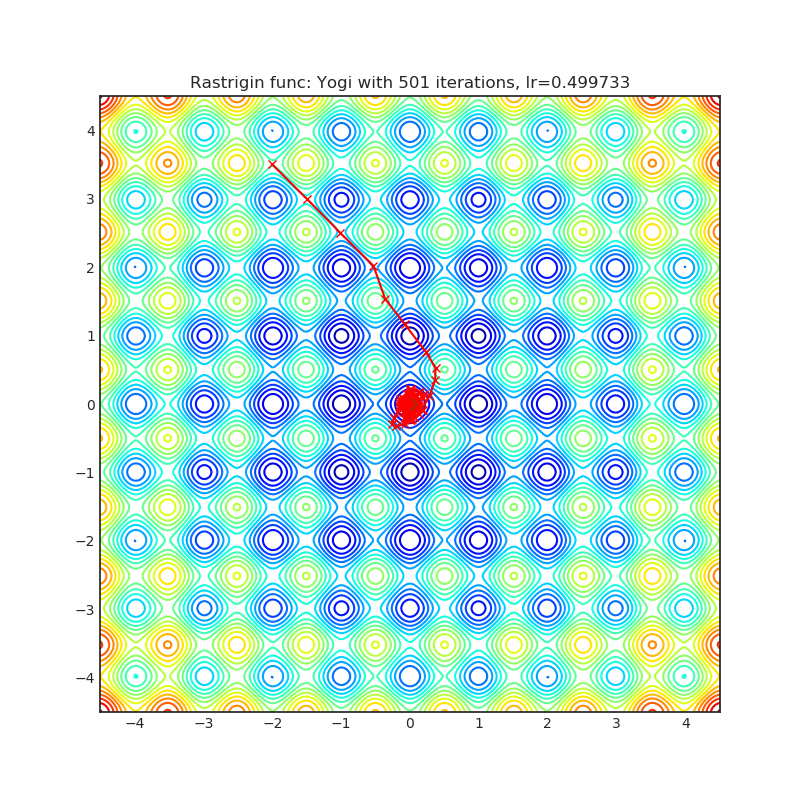 |  |
Adam
pytorch自带
| rastrigin | rosenbrock |
|---|---|
 |  |
SGD
pytorch自带
| rastrigin | rosenbrock |
|---|---|
 |  |
3 评价
看了第2节的结果,DiffGrad,Lookahead,RAdam,Yogi的结果应该还算不错。但是这种可视化结果并不完全正确,一方面训练的epoch太少,另外一方面数据不同以及学习率不同,结果也会大大不同。所以选择合适的优化器在实际调参中还是要具体应用。比如在这个可视化结果中,SGD和Adam效果一般,但是实际上SGD和Adam是广泛验证的优化器,各个任务都能获得不错的结果。SGD是著名的大后期选手,Adam无脑调参最优算法。RAdam很不错,但是并没有那么强,具体RAdam的评价见如何看待最新提出的Rectified Adam (RAdam)?。DiffGrad和Yogi某些任务不错,在某些任务可能效果更差,实际选择需要多次评估。Lookahead是Adam作者和Hinton联合推出的训练优化器,Lookahead可以配合多种优化器,好用是好用,可能没效果,但是一般都会有点提升,实际用Lookahead还是挺不错的。
结合可视化结果,实际下调参,先试试不同的学习率,然后再选择不同的优化器,如果不会调参,优化器个人推荐选择顺序如下:
- Adam
- Lookahead + (Adam or Yogi or RAdam)
- 带有动量的SGD
- RAdam,Yogi,DiffGrad
4 参考
本文来自博客园,作者:落痕的寒假,转载请注明原文链接:https://www.cnblogs.com/luohenyueji/p/16970240.html


