

[图像处理] 基于图像哈希构建图像相似度对比算法
在基于OpenCV实现图像哈希算法一文中描述了如何通过OpenCV实现图像哈希算法。进一步我们可以基于图像哈希构建图像相似度对比算法(用图像哈希构建相似度对比算法精度不高,粗略筛选还是可以用的)。
1 介绍
基于图像哈希构建图像相似度对比算法本质就是根据两张图像的hash值距离来判断图像是否相似。具体步骤如下:
- 计算需要检测图像的hash值,存入本地。
- 从本地读取各个图像的hash值,计算图像间的hash值距离。
- 图像间的hash值距离小于某个阈值,就是相似图像。
本文通过Python实现图像相似度对比算法,C++版本直接按流程重构代码即可。此外需要OpenCV4 contrib 版本,关于OpenCV-Contrib安装见OpenCV_contrib库在windows下编译使用指南。
下面代码展示4张测试图像,img1和img2是相似的,其他两两不相似。
import cv2,os
from matplotlib import pyplot as plt
# opencv版本
print("current opencv-contrib version is : {}".format(cv2.__version__))
# 图像路径
imgpath = 'img'
for filename in os.listdir(imgpath):
print(filename)
filepath= os.path.join(imgpath,filename)
img = cv2.imread(filepath)
img = img[:,:,::-1]
plt.imshow(img)
plt.axis('off')
plt.show()
current opencv-contrib version is : 4.5.3
img1.jpg

img2.jpg

img3.jpg

img4.jpg

2 读取图像计算hash值
以下代码用于多线程读取图像计算hash值,这里用的PHash,可以换成其他hash计算算法。因为计算hash值很费时,所以用了生产者消费者模型。1个生产者线程用于读取图像,4个消费者模型计算图像的hash值。计算hash值后,将各个图像的hash用numpy文件的方式存入本地。下次再计算图像hash值,可以跳过已经计算过hash值的图像从而加快运算速度,但是这里把跳过代码放在了消费者函数中,最好放在生产者函数中。
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 4 18:25:51 2021
读取图像计算hash值
@author: luohenyueji
"""
import threading
import queue
import cv2
import os
import numpy as np
# 计算图像hash值
def consume(threadName, q, result):
while True:
fileName, img = q.get()
# 图像不存在已有结果中就重新计算
# 判断图像是否有hash记录可以读取图像函数中,执行更高效。
# 放在这里主要是担心图像出问题
if str(fileName) not in result.keys():
phashValue = cv2.img_hash.PHash_create().compute(img)
result[str(fileName)] = phashValue
print('{} processing img: {}'.format(threadName, fileName))
q.task_done()
# 读取图像
def produce(threadName, q, imgPath):
for i in os.listdir(imgPath):
if i.split('.')[-1].lower() in ['jpg', 'png']:
fileName = os.path.join(imgPath, i)
img = cv2.imread(fileName)
if img is None:
continue
q.put([fileName, img])
print('{} reading img: {}'.format(threadName, fileName))
q.join()
def main(imgPath, savePath):
# 结果
result = {}
# 读取已有结果加快速度
if os.path.exists(savePath):
result = np.load(savePath, allow_pickle=True).item()
q = queue.Queue()
# 1个读图线程
p = threading.Thread(target=produce, args=("producer", q, imgPath))
# 4个计算线程
c1 = threading.Thread(target=consume, args=("consumer1", q, result))
c2 = threading.Thread(target=consume, args=("consumer2", q, result))
c3 = threading.Thread(target=consume, args=("consumer3", q, result))
c4 = threading.Thread(target=consume, args=("consumer4", q, result))
c1.setDaemon(True)
c2.setDaemon(True)
c3.setDaemon(True)
c4.setDaemon(True)
# 启线程
p.start()
c1.start()
c2.start()
c3.start()
c4.start()
p.join()
# 保存结果
np.save(savePath, result)
if __name__ == '__main__':
# 检测文件夹
imgPath = "img"
# 结果保存路径
savePath = "hash_result.npy"
main(imgPath, savePath)
producer reading img: img\img1.jpg
consumer1 processing img: img\img1.jpg
producer reading img: img\img2.jpg
consumer2 processing img: img\img2.jpg
producer reading img: img\img3.jpgconsumer3 processing img: img\img3.jpg
producer reading img: img\img4.jpg
consumer4 processing img: img\img4.jpg
3 获得相似图像
获得相似图像就是读取图像hash值,循环遍历计算距离,距离小于给定阈值就是相似图像。这里阈值设置为5。最后相似的图像移动或复制到指定文件夹similarImg。
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 4 19:15:19 2021
获得相似图像
@author: luohenyueji
"""
import cv2
import shutil
import numpy as np
import os
def main(hashPath, savePath, pashThre):
# 读取图像哈希列表数据
hashList = np.load(hashPath, allow_pickle=True).item()
# 创建图像结果保存文件夹
os.makedirs(savePath, exist_ok=True)
# pash计算结构
phashStruct = cv2.img_hash.PHash_create()
while len(hashList):
# 取keys
now_keys = list(hashList.keys())[0]
# 还剩多少图像
print("待处理图像{}张".format(len(hashList.keys())))
nowKeyValue = hashList.pop(now_keys)
# 相同图像存储
similarFilename = []
# 循环计算值
for keys in hashList:
pashValue = phashStruct.compare(nowKeyValue, hashList[keys])
if pashValue <= pashThre:
similarFilename.append(keys)
try:
# 移动图像
if len(similarFilename) > 0:
# 获得关键key名字
nowKeyFilename = os.path.basename(now_keys)
# 创建的保存文件路径
saveFilePath = os.path.join(savePath, nowKeyFilename[:-4])
os.makedirs(saveFilePath, exist_ok=True)
# 移动关键keys图像
# shutil.move(now_keys,os.path.join(saveFilePath,nowKeyFilename))
# 从字典中移除值,并移动或者复制图像
for i in similarFilename:
hashList.pop(i)
# 获得key名字
keyFilename = os.path.basename(i)
# 复制图像,移动图像就把copy改为move
shutil.copy(i, os.path.join(saveFilePath, keyFilename))
except:
continue
if __name__ == '__main__':
# hash文件路径
hashPath = "hash_result.npy"
savePath = "similarImg"
# hash距离低于该值的都判定为相似图像
pashThre = 5
main(hashPath, savePath, pashThre)
待处理图像4张
待处理图像2张
待处理图像1张
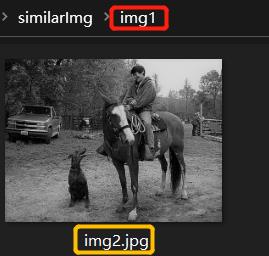
运行代码结果如下图所示。第一张图像表示similarImg文件夹中最后结果只有img1图像有相似图像。第二张图像表示与img1相似的图像只有img2。

4 参考
本文来自博客园,作者:落痕的寒假,转载请注明原文链接:https://www.cnblogs.com/luohenyueji/p/16970203.html


