
软件架构阅读笔记4
业务:从数据中挖掘出真正的商业价值,进而帮助淘宝、商家进行企业的数据化运营,帮助消费者进行理性的购物决策。
存在问题:数据“海量”,数据产品的计算、存储和检索难度陡然上升。
淘宝海量数据产品技术架构:
数据产品的特点是数据的非实时写入,在一定的时间段内,整个系统的数据是只读的(设计缓存的基础)。
先分层:
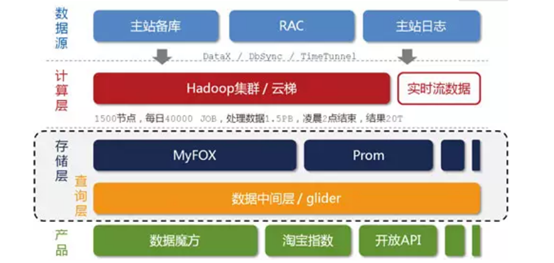
问题:“云梯”只能离线计算(MapReduce计算),无法支持较高的性能和并发需求,但是存在一些实效性要求很高的数据,希望能尽快推送到数据产品前端。
解决方法:银河”分布式系统。它接收来自TimeTunnel的实时消息,在内存中做实时计算,并把计算结果在尽可能短的时间内刷新到NoSQL存储设备中,供前端产品调用。
问题:存储层异构模块的增多,对前端产品的使用带来了挑战。
使用数据中间层glider来屏蔽这个影响。
解决方法:glider以HTTP协议对外提供restful方式的接口。数据产品可以通过一个唯一的URL获取到它想要的数据。
问题:海量数据
解决方法:设计了分布式MySQL集群的查询代理层——MyFOX,使得分区对前端应用透明。它想要的数据。
问题:数据节点多,成本高。
解决方法:“热节点”和“冷节点”。数据产品的用户更多地只关心“最近几天”的数据,越早的数据,越容易被冷落。将冷热数据进行分离的另外一个好处是可以有效降低内存磁盘比。

问题:全属性选择器。数据的筛选性非常差。
解决方法:
穷举所有可能的过滤条件组合,在“云梯”上进行预先计算,存入数据库供查询;(穷举不可行)
存储原始数据,在用户查询时根据过滤条件筛选出相应的记录进行现场计算。创建定制化的存储、现场计算并提供查询服务的引擎
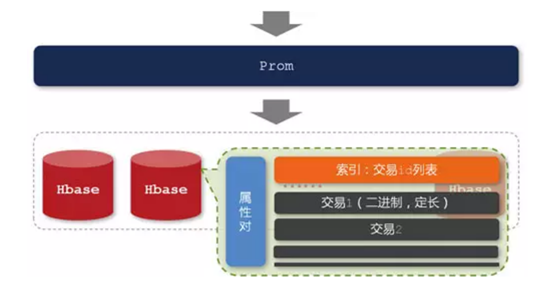
选择了HBase作为Prom的底层存储引擎。之所以选择HBase,主要是因为它是建立在HDFS之上的,并且对于MapReduce有良好的编程接口。
原理:
这里的原始数据是前一天在淘宝上的交易明细,在HBase集群中,以属性对(属性与属性值的组合)作为row-key进行存储。而row-key 对应的值,设计了两个column-family,即存放交易ID列表的index字段和原始交易明细的data字段。在存储的时候,让每个字段中的每一个元素都是定长的,这是为了支持通过偏移量快速地找到相应记录,避免复杂的查找算法和磁盘的大量随机读取请求。在现场计算方面,对Hbase进行了扩展,Prom要求每个节点返回的数据是已经经过“本地计算”的局部最优解,最终的全局最优解只是各个节点返回的局部最优解的一个简单汇总。很显然,这样的设计思路是要充分利用各个节点的并行计算能力,并且避免大量明细数据的网络传输开销。
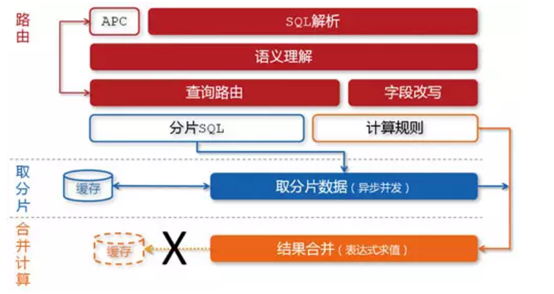
问题:
各种异构的存储模块给前端产品的使用带来了很大的挑战,前端产品的一个请求所需要的数据往往不可能只从一个模块获取。
解决办法:在存储层与前端产品之间增加一个中间层,它负责各个异构“表”之间的数据JOIN和UNION等计算,并且隔离前端产品和后端存储,提供统一的数据查询服务。
缓存基础(在特定的时间段内,数据产品中的数据是只读的)
glider中存在两层缓存,分别是基于各个异构“表”(datasource)的二级缓存和整合之后基于独立请求的一级缓存。
MyFOX的缓存设计:针对每个分片进行缓存,其目的在于提高缓存的命中率,并且降低数据的冗余度。
一致性:除了返回各自的数据之外,还会返回各自的数据缓存过期时间(ttl),而glider最终输出的过期时间是各个异构“表”过期时间的最小值。这一过期时间 也一定是从底层存储层层传递,最终通过HTTP头返回给用户浏览器的。
穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
解决方法:
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉
雪崩效应解决方法:设计的缓存过期机制理论上能够将各个客户端的数据失效时间均 匀地分布在时间轴上,一定程度上能够避免缓存同时失效带来的雪崩效应。
正是基于本文所描述的架构特点,数据魔方目前已经能够提供压缩前80TB的数据存储空间,数据中间层glider支持每天4000万的查询请求,平均响应时间在28毫秒(6月1日数据),足以满足未来一段时间内的业务增长需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号