1. Raft简介
raft是一个管理复制式日志的共识算法,它是通过复制日志的方式来保持状态机里的数据是最终一致的。
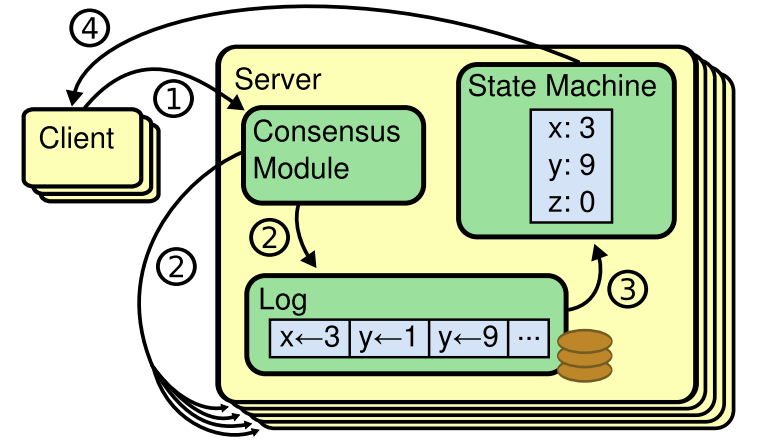
整体的一个运行描述图:
从图中可以看到由几部分组成,共识模块、日志模块和状态机。当client端发送一个请求过来时,首先经过共识模块产生日志并复制到大多数节点,然后将日志应用到状态机中,只要保证每个节点的日志序列是一致的,那么当状态机应用完所有日志时得到的状态机数据肯定也是一致的,所以关键是要保持日志序列的一致性,这个则是由共识算法模块来进行保证的。
为了便于实现,raft在设计上将功能拆分为几个独立的模块来处理,分别是Leader选举、日志复制、配置变更和safety等模块。
Leader选举:一个集群中保证只会产生一个Leader,也就是赢得了大多数投票的节点才能成为Leader,被选为Leader的节点是包含了最多有效entry的节点,因为只有当它拥有了最多有效entry,才会赢得大多数节点的投票;
除了Leader节点,还有Follower节点和Candidate节点,在集群正常运行的情况下,通常的模式就是1个Leader+多个Follower节点;当Leader由于网络原因不能与其它节点通信或宕机时,选举累计超时后就会有Follower节点变更为Candidate节点,这种节点会进行Leader选举,当获得大多数节点的成功投票时就表示选举成功了,该Candidate节点就成为新的Leader节点了。
日志复制:只有Leader节点才有权利向其它节点复制日志,并负责解决与其它节点的日志冲突,让其它节点的日志序列保持和Leader节点的日志序列一致;
每个节点都会有一份本地日志,全部日志可以看成是一个日志列表,每个日志都会有个Index表示它的序号,Index序号是递增的,日志的data可以认为是一个命令行,描述了状态机要执行的动作,比如set a=1就是把key a的值设置为1;
配置变更:配置变更是指进行节点的新增或者移除,但由于所有节点的配置变更不可能保证在同一时间完成,所以如果不采取措施控制就可能会产生2个Leader(新旧集群配置各自选出1个Leader),所以为了解决这个问题raft也提出了两个解决方案:
方案一:单次变更只变更一个节点;
方案二:联合共识;
这两种方案都能保证在集群数量增加或减少阶段保证只会有一个Leader,详细实现介绍在下文中提到。
safety模块:安全性,通过选举安全(只会存在一个Leader)、提交安全(被提交的日志是不能被覆盖的)来保证状态机最终是保持一致的,保证数据是安全的。
相比paxos,它的优点是更简单更容易理解且比较好应用于工程上,效率也与paxos算法相当。易于理解主要体现在raft进行了具体的模块划分和状态空间简化(相比于 Paxos,Raft 中不确定性程度和节点不一致的场景数量都变少了)。
paxos虽然从理论上证明了算法的正确性,但其很难理解且很难用代码准确的实现它,目前实现了pasox的工程虽然有比如chubby(Google设计的提供粗粒度锁服务的文件系统),但其也并没有完全按照paxos实现,做了比较多修改,最终实现的系统是建立在一个未经理论证明的协议基础上实现的。
2. Etcd的Raft结构和关键数据结构分析
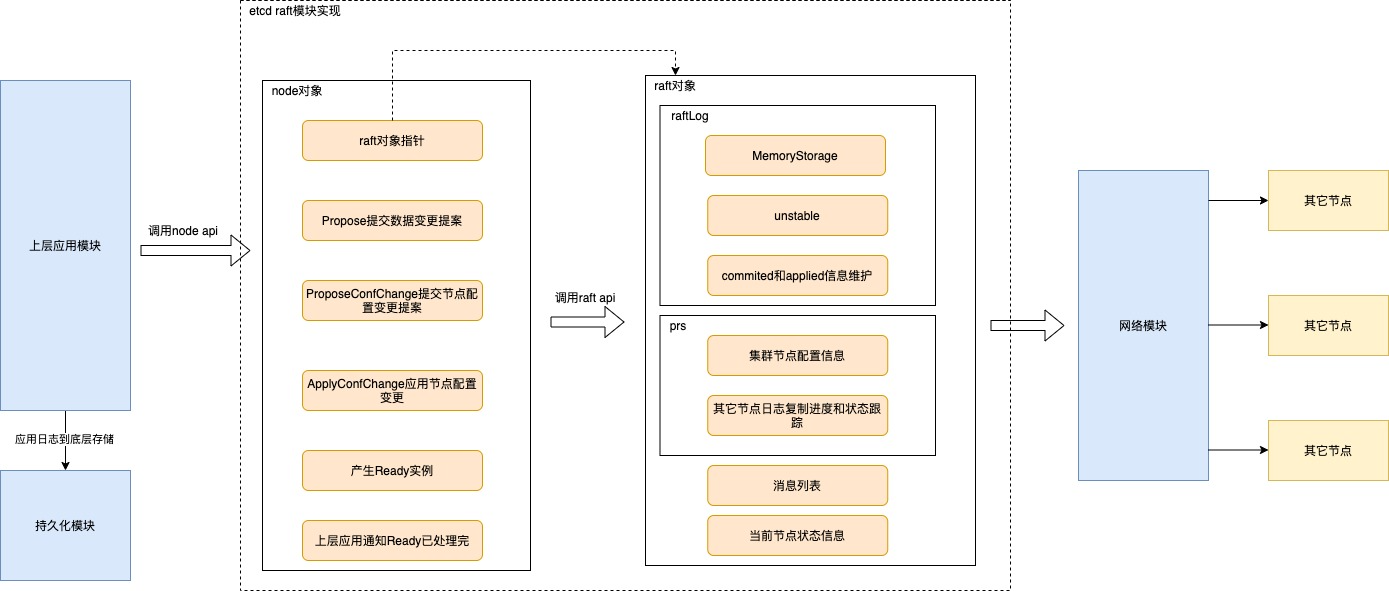
2.1. 整体结构图
node对象封装了raft节点的操作,为上层应用模块提供了更友好的api接口,上层应用模块通过调用node的api来进行数据变更,node则将变更信息封装为entry log,然后调用raft的api来进行日志添加和复制;
日志相关的操作由raftLog来进行管理,同时Leader节点需要跟踪集群其它节点的日志同步情况和当前集群节点配置,这个则通过prs数据结构来进行管理;
由于etcd的raft模块并没有实现网络模块,所以要发送的消息都会先保存在消息列表中,待网络模块进行发送。
当日志经过了commit后就可以应用到状态机了,这个操作是由上层应用做的,raft模块只保证日志提交了则表示大多数节点都收到了这份日志,node节点会将commit了的日志封装到Ready实例中,上层应用读取到时将其进行应用,状态机一般是个KV存储系统,比如etcd里的是boltdb存储。
2.2. 关键数据结构分析
这里介绍下相对应比较重点的数据结构,其它的可以对照着图上对应字段的注释和对应代码来理解。
node结构体:node是上层与raft进行交互的中间接口层,node层提供了更友好的接口给上层调用,比如Propose接口用来发起数据更改的提案。
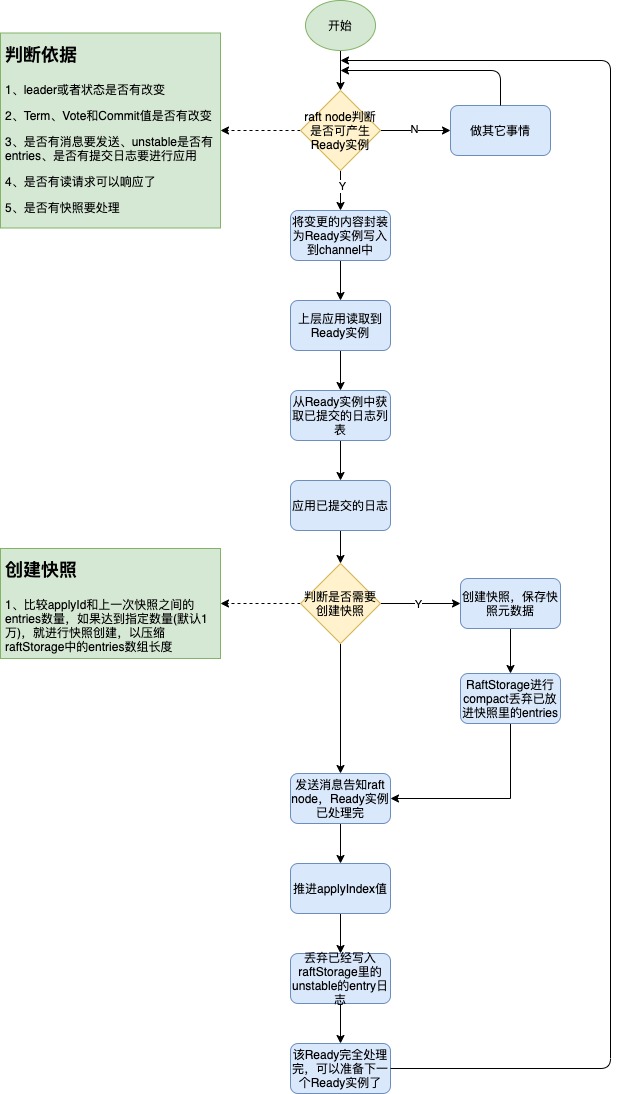
node中有一个核心方法run方法,该方法使用独立协程运行,run方法里会检测raft节点的变化并进行处理,比如生成Ready实例,往channel里写入让应用层去读取处理;同时也会监听一些channel来知道应用层的处理情况然后反馈给raft节点来进行下一步的动作处理。
Ready结构体:它是让应用层感知raft节点状态变化的传递对象,是由node生成传递给上层应用的,里面封装了raft节点状态的变化、待写入WAL和写入MemoryStorage的Entry日志、commit了待应用的日志、快照数据和待发送的消息等信息,当这些有一个有更改时node就会检测到并生成Ready实例写到一个channel中,上层应用会调用node的api方法读取出来进行处理,每次只能进行一个Ready对象的处理,Ready对象如果上层还没处理完,不会产生下一个Ready对象,当上层应用处理完了,会通过调用node节点Advance方法来告知Ready实例已经应用完了。
Entry结构体:它其实就是日志的数据结构表示了,复制日志说的就是复制这些Entry了,里面包含了4个字段,分别是Term、Index、Type和Data;
Term:产生这个日志时Leader节点当前的任期号,任期号是单调递增的;
Index:日志序号,单调递增的;
Type:日志类型,有正常日志、配置变更日志V1版本(单节点添加实现)和配置变更日志V2版本(联合共识方式添加节点实现);
Data:表示需要执行的动作或命令,比如set a=1;
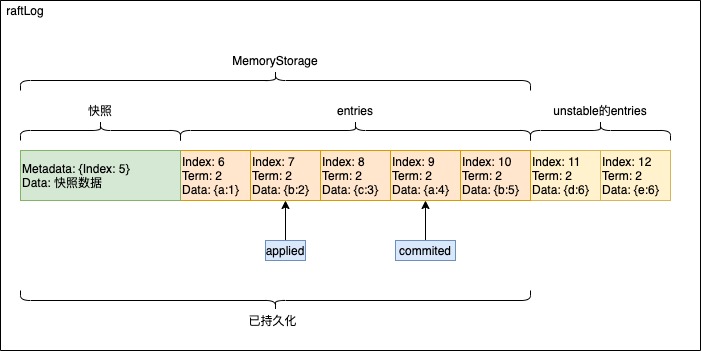
raftLog结构体:它是日志管理的关键数据结构,它包含Storage和unstable和一些关键字段信息。
Storage:目前的实现是MemoryStorage,它可以看做是日志的缓存存储对象;
unstable:它是不可靠存储,一开始append日志都是先append到unstable中,然后写入到WAL和缓存到MemoryStorage,最后应用时写入到后端存储中;
committed:提交日志的Index值,在该Index值之前的日志都是已经被提交的,commited的日志是不能被覆盖的;
applied:应用日志的Index值,在该Index值之前的日志都是已经被应用了的;
ProgressTracker结构体:它是Leader用来跟踪集群配置信息和所有节点当前状态的,它的核心是Config和Progress。
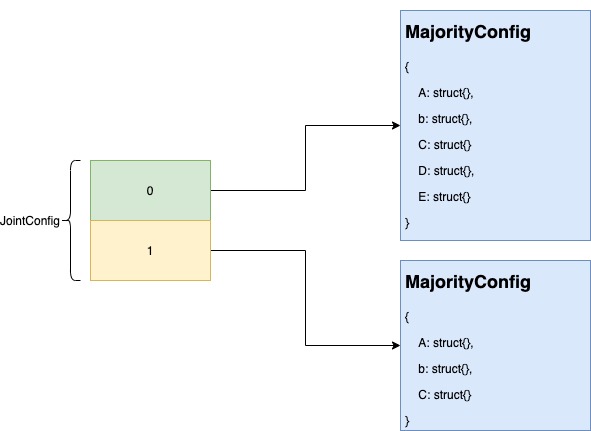
Config:记录了当前的集群节点的信息,比如可用来投票的节点有哪些,learner的节点有哪些,联合状态下的新旧集群的投票节点信息等,在选主投票统计和确定集群当前commit index值里起着关键作用;
![]()
JointConfig是Config的主要成员变量,它是个长度为2的数组,数组index为0指向的配置可以看做是新配置,数组index为1指向的配置可以看做是旧配置暂存,只有当处于联合共识场景下,index为1的指向才不是nil。
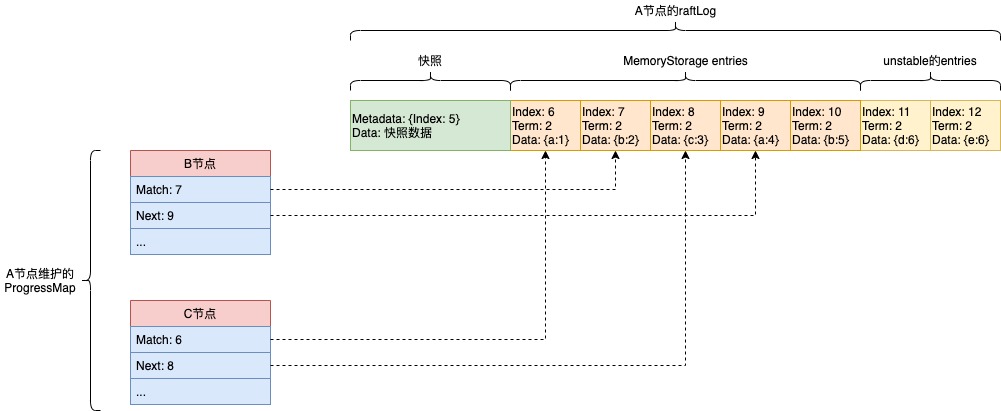
Progress:使用该数据结构来记录其它节点当前的日志复制进度,比如它的Next和Match字段,Next字段的值表示Leader下次要发的entry日志位置,Match字段的值表示该节点明确回应了对应位置的entry日志已经收到了。
![]()
这里以A、B和C三个节点组成为例,A为leader,上图为A节点维护的ProgressMap,它记录的B节点的Next值为9,表示下次发送日志复制是从Index为9的日志开始复制,Match为7表示B节点回复过A节点Index为7的这个日志它已经收到了。
3. Etcd的Raft操作流程
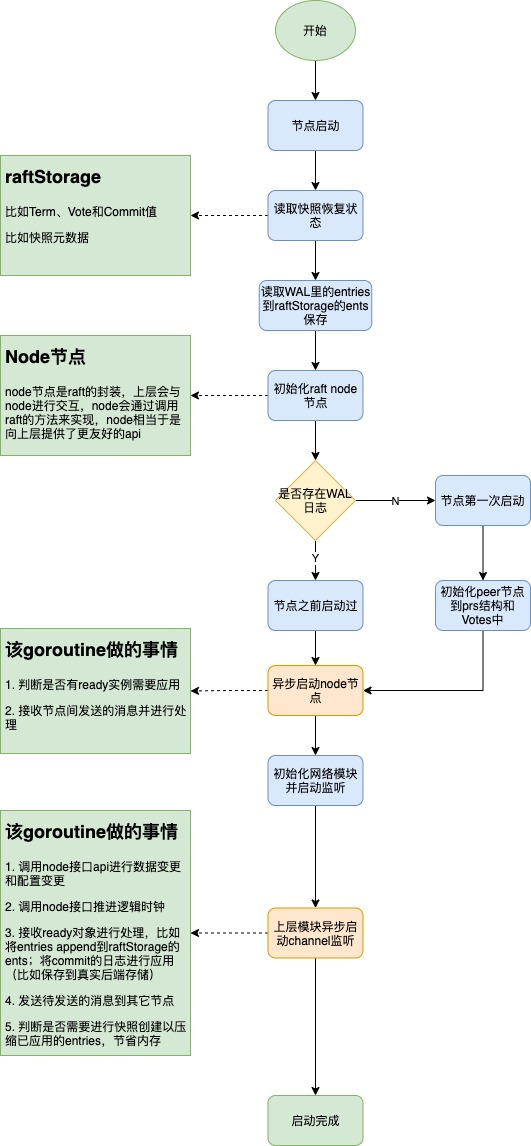
3.1. 节点启动
备注:这里主要是根据raftExample里(源码目录:etcd/contrib/raftexample)的启动流程来介绍的。
在启动时进行快照数据的读取和WAL日志文件的读取,对WAL日志和快照数据进行校验,然后读取WAL里快照之后的entries,设置快照数据到raftStorage(保存entries的Storage,不是状态机的Storage)中,将entries添加到raftStorage的ents字段中。
根据传参配置参数初始化raft node节点对象,里面包含raftStorage和raft的必要参数,比如选举超时时间、是否需要预选举等,并且会将该raft节点设置为Follower状态。
根据是否有WAL日志来判断是第一次启动(之前从来没启动过,比如集群刚刚创建的时候)还是非第一次启动,如果是第一次启动的,则此时会进行节点添加,会产生EntryConfChange类型的消息,接着进行提交和应用,并且给其它节点发送Entries消息。
当一个节点经过超时后就会发起选举,得到超半数票后会成为leader。
如果是之前启动过,那么这次启动不需要进行节点添加,它会将快照数据保存的状态恢复到状态机中,设置快照元数据,设置commitId和appliedId,同时能从WAL日志中恢复unstable的entries。
3.2. 选主流程
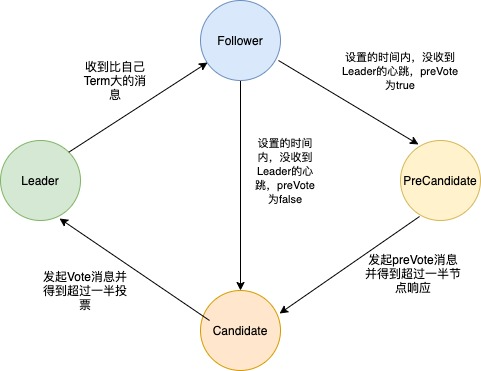
目前etcd的节点角色分为4种,分别是Follow、PreCandidate、Candidate和Leader。
它们之间的变换关系如下:
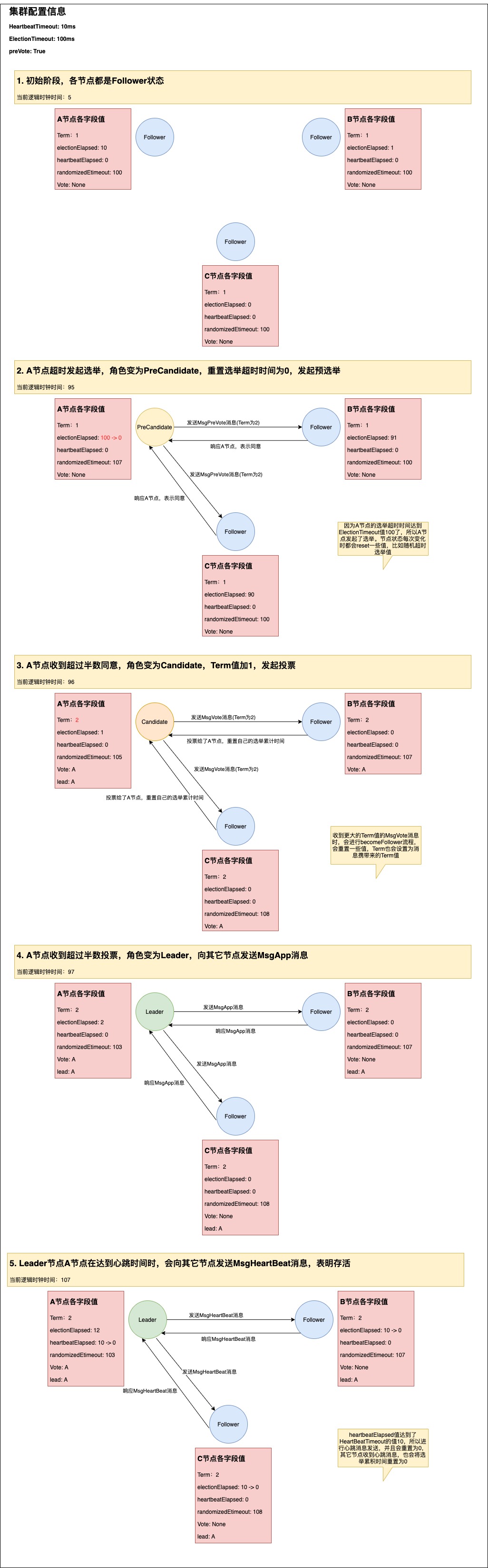
raft里的逻辑时钟:不是具体的现实时间,它只是一个数字,是由上层去推动进行加1,比如上层会设置一个ticket,每过10ms就会让逻辑时钟进行加1;
HeartbeatTimeout:发起心跳的逻辑时钟间隔时间,leader节点会使用,当累加的心跳逻辑时钟(一个变量去维护)超过这个值时就会向其它节点进行心跳发送;
ElectionTimeout:选举超时时间,当节点的选举逻辑时钟(一个变量去维护)超过该值时就会发起选举,但是如果在达到该值之前收到心跳消息,就会重置为0。该参数在初始化raft节点时传参设置的,为了避免在同一时间发起选举,所以真正使用时会使用randomizedElectionTimeout变量,该变量值的区间在[electiontimeout, 2 * electiontimeout - 1],这个变量会在每次状态变化时就会重新设置该值。
官方设置建议:ElectionTimeout = 10 * HeartbeatTimeout。
PreVote参数设计的意义:
PreVote参数:因为当发生网络分区时,处于少部分节点分区的节点会收不到leader心跳,然后导致它选举累计时间超时发起选举,每发起一次选举,Term就要加1,然后选举失败,然后一直重复这个过程,就会导致这个节点的Term值不断变大;当网络分区恢复后,它又发起选举就会导致leader节点变成Folower(因为收到了更大的Term值的消息),从而导致这个集群在短时间内没有leader节点,导致读写延迟,因此引起延时波动。
解决这个问题的方法就是在发起选举前先与大多数节点进行通信,看能否收到大多数节点的响应消息,如果不能则表示自己可能处于网络分区,联系不上大多数节点,那肯定是会选举失败的,因此就没必要进行Candidate状态了,因此引入了PreCandidate状态,切换为该状态Term是不会加1的,但发出去的消息的Term是加了1的。
举例Leader选举过程图:
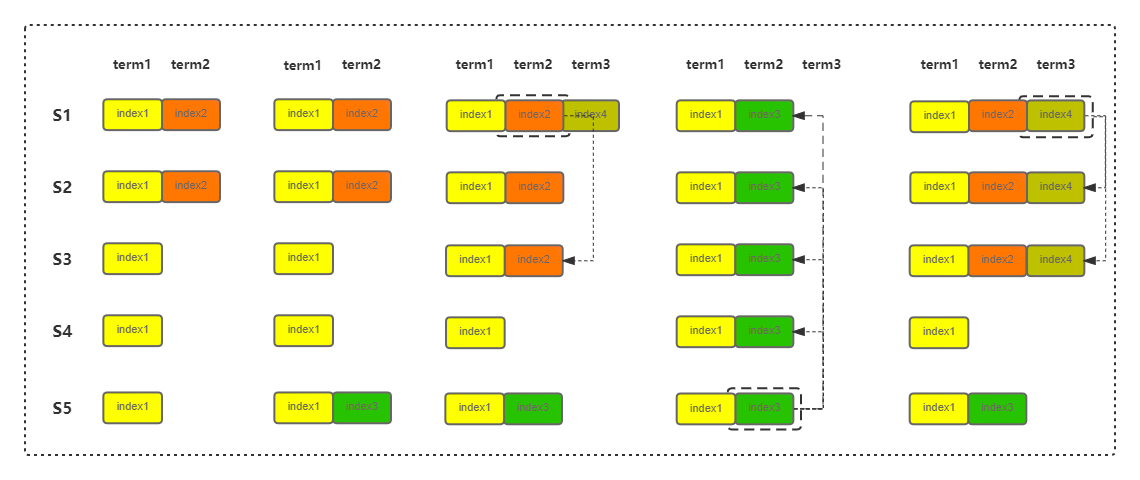
当节点被选举为Leader的时候,它会append一个空日志,这样做的理由:
(1)在线性读时,Leader发生转移时,在确定CommitIndex时判断当前commit日志的Term是否当前节点的任期,这样就保证了上一个任期的Commit日志在这个节点也是被commit了的;线性读在下文中会讲述到。
(2)raft规定Leader只允许提交当前Term的日志,这样规定的原因在于避免下面这种情况。所以新Leader要想提交之前Leader的commit log就先自己append一个空日志进行提交,只要自己append的空日志提交了,那么在自己这个日志之前的commit日志肯定也提交了。
假设允许提交不是当前Term的日志:
(1)S1作为Leader时,插入了index2日志,复制到了S2节点;
(2)S1宕机,S5成为Leader,插入了Index3日志,没有复制给其它节点;
(3)S5宕机了,S1重新成为Leader,继续将index2日志复制到S3,达到了大多数,commit了index2日志,并插入index 4日志;
(4)S1又宕机了,S5成为Leader,它将index3复制到其它节点,导致覆盖掉了index2,导致之前被提交的index2被覆盖了,按照raft的原则,被提交的日志是不能被覆盖的。
3.3. 处理写请求
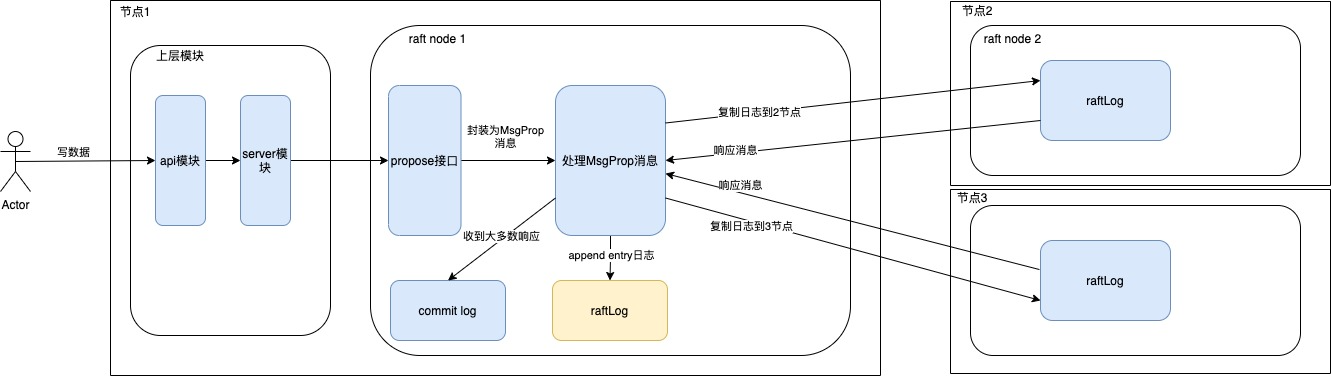
整体流程:
一般来说写入key只能在leader节点进行处理,如果客户端直接发到了Follower节点,当配置参数disableProposalForwarding为false的话,会将该消息转发给Leader节点进行处理,处理完再转发回来响应客户端。
写入key其实是一个两阶段提交的过程+上层Apply的过程。
第一阶段:Propose阶段
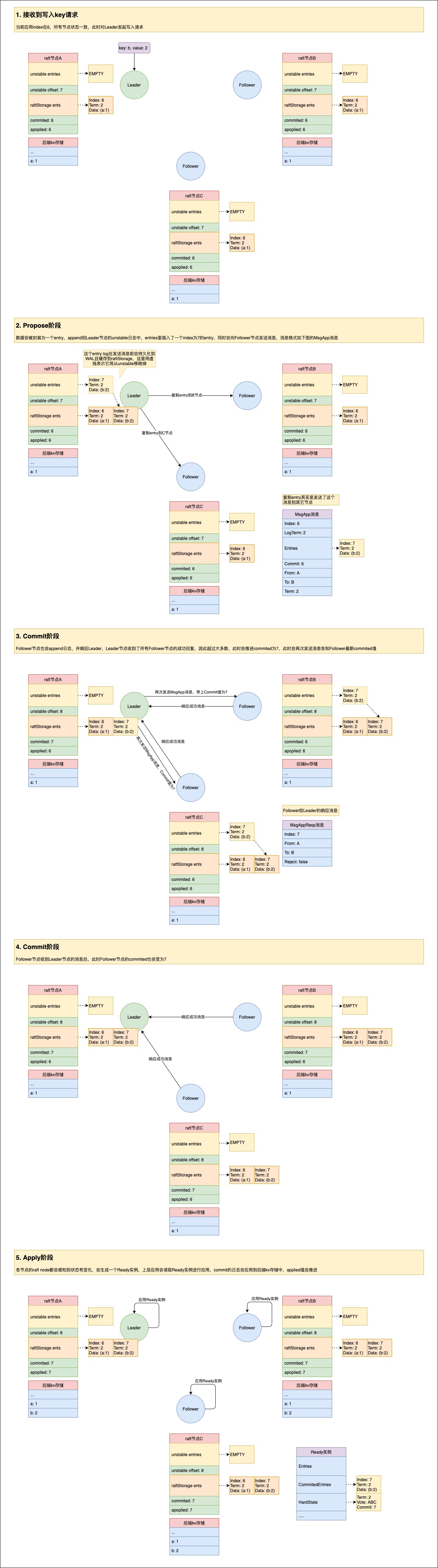
Propose也就是提案的过程,在raft的表现上来说就是先会append日志到自己的raftLog里,再把日志复制到其它节点,这个阶段完成不保证所有节点有收到这个日志。
第二阶段:Commit阶段
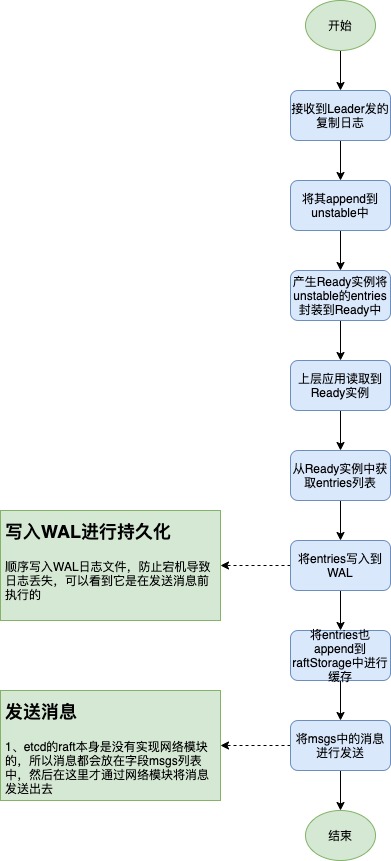
将日志发送给其它节点后,当其它节点收到并处理后会进行消息响应。Follower节点收到复制Entry进行append后,并不是直接进行消息响应发送的,它是先将要发送的消息放在msgs列表中,真正发送是在生成Ready实例让上层处理时发送的,其中在发送消息前,Ready实例肯定也包含了刚append到unstable中的entries,所以过程是先将entries写入到WAL,然后发送消息,总结来说就是Leader收到了某个节点的成功回复也就表示这个节点也已经将entries持久化到WAL了。
Follower节点收到复制日志并响应流程如下:
Leader在接收到消息响应时会尝试进行判断看是否收到了超过一半的复制日志成功的响应,如果是则推进commitId的值,并向其它节点进行广播。
Apply阶段:
应用阶段也是发生在Ready实例处理过程中,node会不断轮询是否可以产生Ready实例,如果可以,则会将已经commit的日志赋值到Ready实例的CommittedEntries字段中,上层应用会通过Channel读取到该Ready实例并进行应用,已经提交的日志会被应用到后端存储中(一般是持久化的存储)。
举例一个key写入时各个raft node节点的状态变化图:
问题1:怎么才算是成功写入了?
在raftExample里,当一个key返回时,其实它并不代表成功了,因为只是propose,只是提案流程走完,至于其它节点是否收到,其实并不知道,所以如果真的写入,应该是等commitId到达put时的那个index才认为是成功了。在etcd里KVServer模块会等待写请求应用到状态机了才认为写成功了,默认是等待7s,如果还没告知commit成功,则超时返回。
问题2:MsgApp里的LogTerm的作用是什么?
MsgApp消息里也会携带一个Index值,在Follower append消息之前会先检测下该Index在Follower这里的Term值是否与LogTerm一致,如果不一致就是有冲突,那么就会reject掉,并进行冲突检测,方便下一次找到正确的位置进行覆盖。
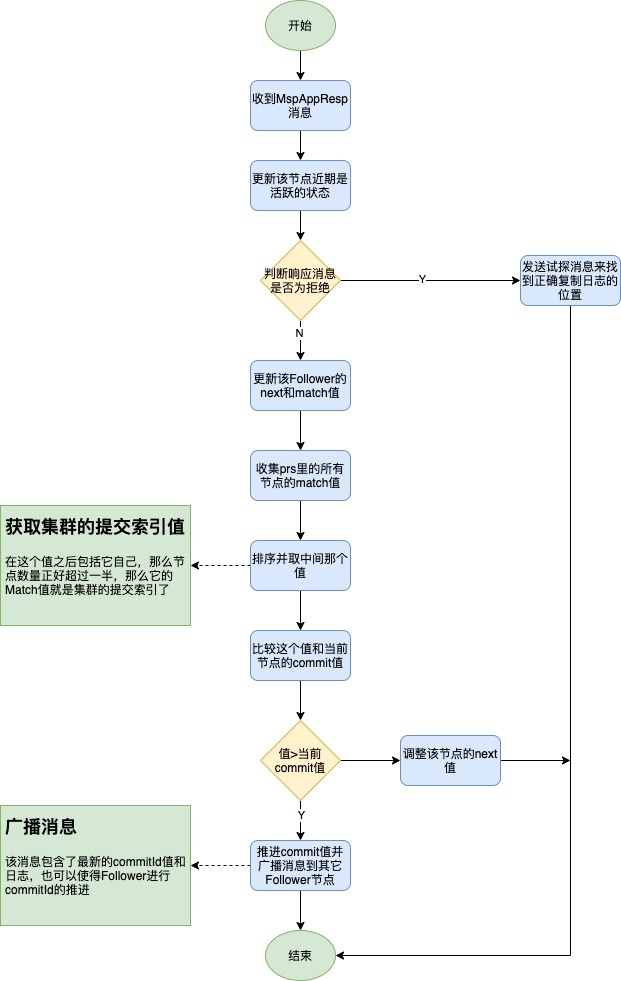
问题3:leader的commitId是怎么推进的?
在node节点的run方法里收到entry的回复,比如是MsgAppResp类型消息的回复,然后会调用stepLeader里进行处理,进行该follower的match和next的更新,接着就是尝试更新commitId了,因为可能已经达到复制到半数以上节点的要求了,调用的是maybeCommit方法,该方法实现就是先获取所有节点的commitId值(这个值不用说再发网络去获取,只需从维护的prs里拿就行,这里取的其实就是match的值,详细看matchAckIndexer类型的AckedIndex的实现),然后排序,然后取大于一半的数就是集群中的commitId值,然后跟当前节点的commitId进行比较,如果大于当前节点的则进行更新,如果更新成功会进行readIndex的回复(这是一个触发读请求的时机),同时会发送MspApp消息到其它follower节点,根据具体节点的pr的next来进行entries发送,同时也带上自己的commitId,接着更新该节点的next值。
问题4:follower节点的commitId是怎么推进的?
当leader的commitId前进了时,follower节点是会收到leader节点的MsgApp消息的,对应的就是在stepFollower流程中调用maybeAppend函数,然后如果发现有日志需要append则append到unstable中,接着进行commitTo的调用来推进commitId的,然后回复给leader。
问题5:节点的applied是怎么推进的?
在commitId推进了后,node中就会发现有rd(即Ready实例,包含unstable里的entries和commit了的entries)进行处理,将rd写入到channel中,然后raftExample里会从channel中收到rd进行处理,然后unstable的entries就会append到raftStorage里去,commit了的entries则会写入到一个channel中等待上层应用到底层存储中,应用成功则会将applyId进行推进。
问题6:当propose后,收到大多数节点的回应后commit日志,然后进行应用,但此时其它节点都没commit该日志,还存在于unstable中,这时机房断电(意味着unstable里的那条log也丢了),恢复后,选举了其它节点作为Leader,此时刚刚那个日志是不是丢了,且状态机是不是不一致了?而且这个节点再也加不进去了,因为append日志时会检测到冲突然后panic。
首先有这个误解是因为我们以为消息是在raft模块就发出去了,其实不是,发送消息也是在Ready实例处理时进行的,entry的WAL写入也是在Ready实例处理时进行的,且unstable的entry的WAL写入是在发送消息之前的,所以消息发送出去了也就代表unstable里的日志一定是WAL持久化了的,因此也就不会出现问题中说的unstable的日志断电丢失问题,也就不会有问题中说的不一致问题。
3.4. 处理读请求
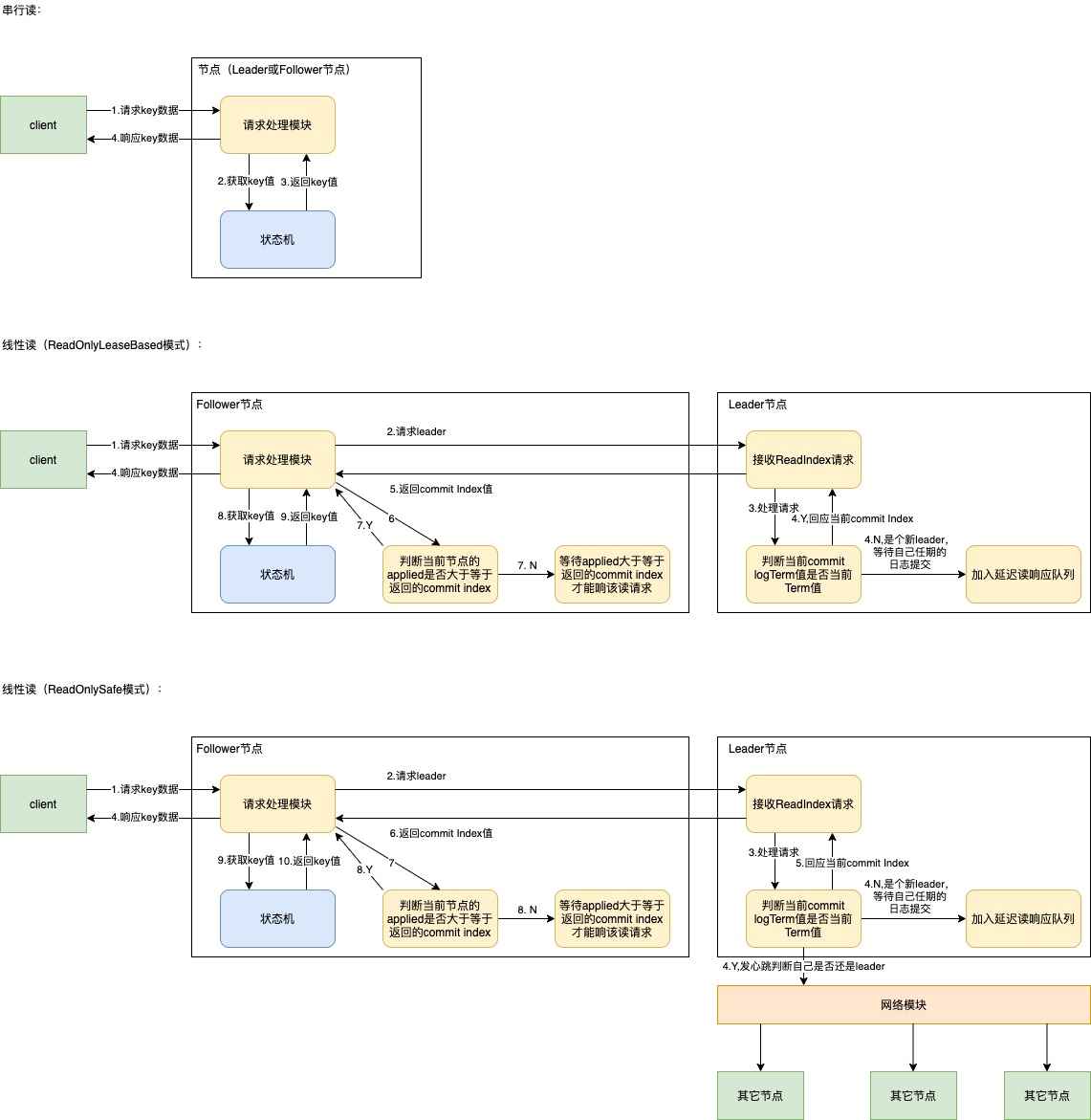
读操作有两种模式,分别是串行读和线性读。etcd里默认的读模式是线性读。
串行读比较简单,就是直接从状态机里获取这个key对应的值,但存在一致性风险,因为该节点可能还未应用这个key,串行读适用于在数据敏感度比较低的场景,比如监控面板类的,因为它要求的是最终一致性,具有低时延,高吞吐的特点。
线性读则能够保证读到的数据是一致的,不管是从哪个节点进行读,只要返回给客户端是写入成功了,那么读取是可以读到刚插入的数据的,这个一般使用在对数据一致性要求比较高的场景,因为它需要经过raft协议,所以它延时也会比串行读高。
在etcd的raft协议实现里,线性读也分为两种模式,分别是ReadOnlySafe和ReadOnlyLeaseBased。
ReadOnlySafe:它是需要经过心跳广播确认自己还是Leader的,所以数据的一致性是没问题的;
ReadOnlyLeaseBased:它依赖于Leader租约,就是只要我的状态是Leader,那么我就认为我肯定还是Leader(但其实它可能已经不是了),这种的缺点就是会受到时钟的干扰,因为时钟漂移的可能性,租约可能比预期的长,当前节点还没没感知到自己已经不是Leader了,但还是响应了ReadIndex,会导致节点确认到一个错误的commit index,从而返回了一个脏数据,所以它是不安全的。
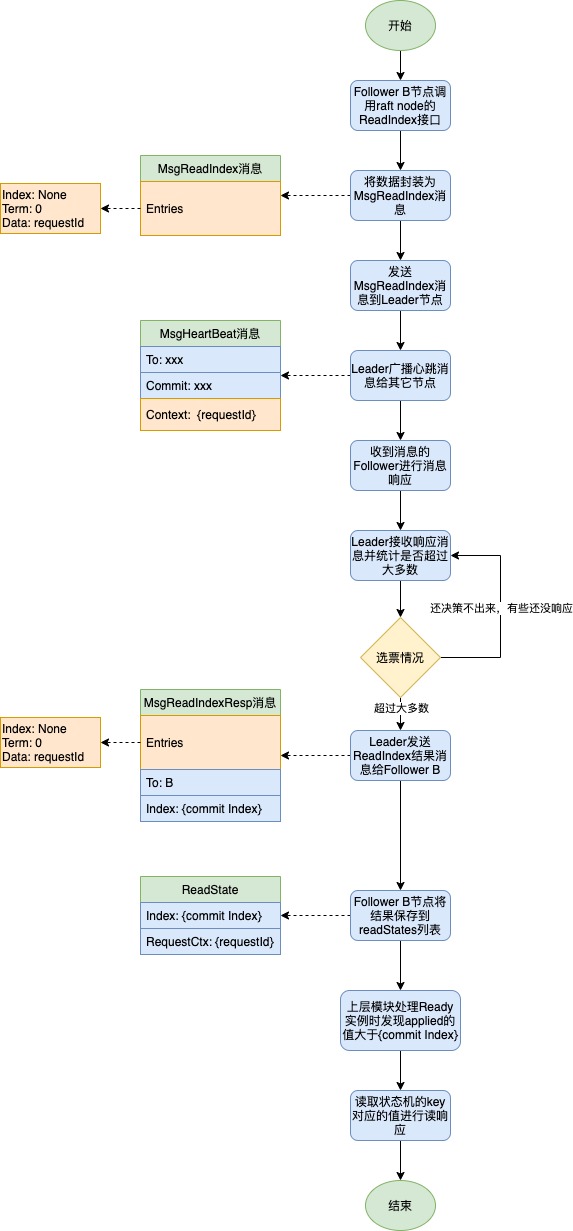
raft模块做的只是让Leader节点去确认一个commit index值(这个要读取的key肯定是在这个index之前或刚好是这个index被commit的)作为回复,当节点的上层模块发现自身节点的applied Index大于等于这个commit index,那么也就是说这个key肯定被我的状态机应用了,此时就可以直接从自己节点的状态机获取值了,等同于从leader里去获取值,它的好处就是读请求不用必须都让Leader进行响应,这样很容易使得Leader节点的带宽成为瓶颈。
以下流程以一个Follower节点的视角去处理一个ReadIndex的请求,且ReadIndex模式是ReadOnlySafe模式:
问题1:当一个节点commit了后,宕机了,此时客户端发起ReadIndex,新的Leader是否可能还没commit之前的leader的日志,会不会导致脏数据读?
对于这种,代码里其实有处理(pendingReadIndexMessages变量记录需要延迟处理的读请求,会等到新leader的commit log的Term值是当前任期值),那就是会检测新上任的leader是否有在它自己的任期内commit过任何日志,检测方式就是判断当前commited的log的Term是否跟当前的Term值一致。如果它commit过了,则之前leader提交的commit肯定也会被commit掉,因此当一个节点刚被选举为Leader时都会append一个空日志,当该日志被commit后也就能pass刚刚那个检查限制了,且也表示在这个空日志之前的日志肯定也是提交了的,即之前leader提交过的log肯定也被提交了。
3.5. 日志复制的多种场景分析
场景1:刚好往后增的情况
场景2:会覆盖已有的部分的情况
由于Follower的Index=4的entry跟Leader的Index=4的entry产生了冲突,所以直接从Index=4的地方开始截断,覆盖为Leader传过来的Entries。
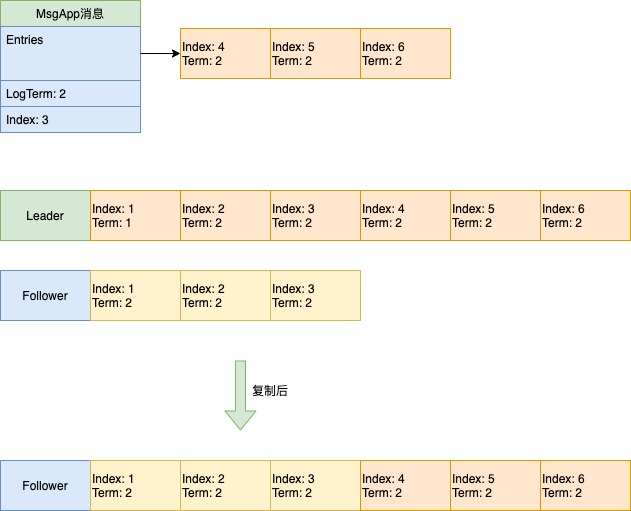
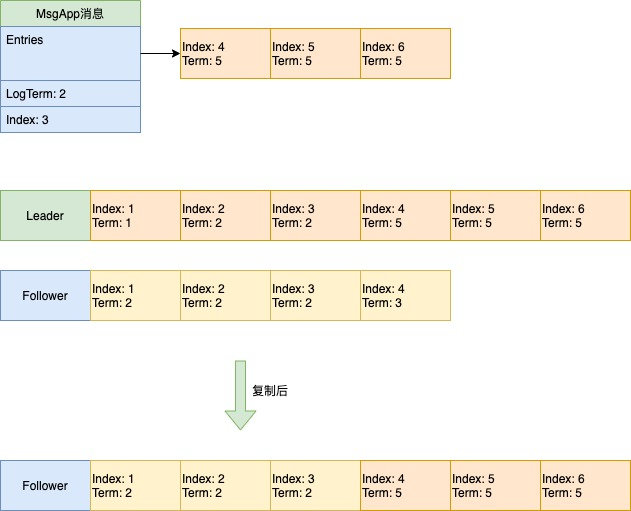
场景3:LogTerm对不上的情况
问题1:刚成为leader时,follower节点的next和match设置为多少?
在重置函数里,会将每个process的Next设置为lastIndex+1,Match设置为0(当前节点的Match则设置为lastIndex)。
3.6. 变更节点
在etcd3.5之前,添加节点是只支持一次添加一个节点的,这样做的目的是为了防止在变更集群配置过程中出现两个Leader节点的问题。
举例:
原先有ABC三个节点,A是Leader,然后新增DEFG四个节点,这时A宕机了,BC还未应用新增DEFG四个节点的配置,所以它们还认为当前集群只有3个节点,所以B可能当选为了Leader,然后DEFG又都投了D,所以D也获得了7票中的4票,所以它也成为了Leader,所以这时就出现了两个Leader的问题。
但如果每次变更都只变更一个节点,那么这个问题就不会存在,因为要想获得大于一半的节点,所以两个leader之间的势力范围务必会有一个节点进行相交,但一个节点只能给一个Leader投票,所以不可能产生两个Leader。
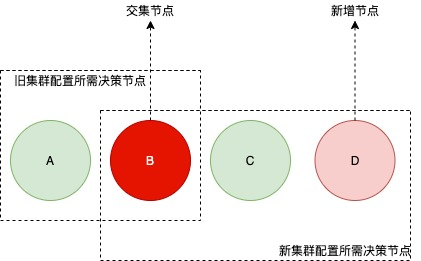
奇数个节点添加一个节点:
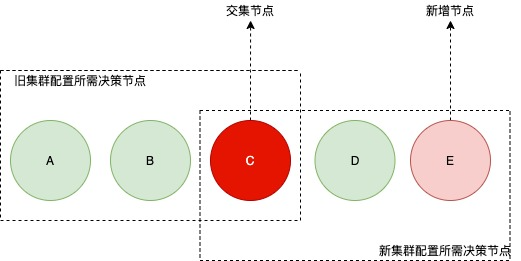
偶数个节点添加1个节点:
可知C节点是交集节点,C节点要么投票给旧集群,要么投票给新集群,不可能投票给两边,所以不会产生两个Leader。
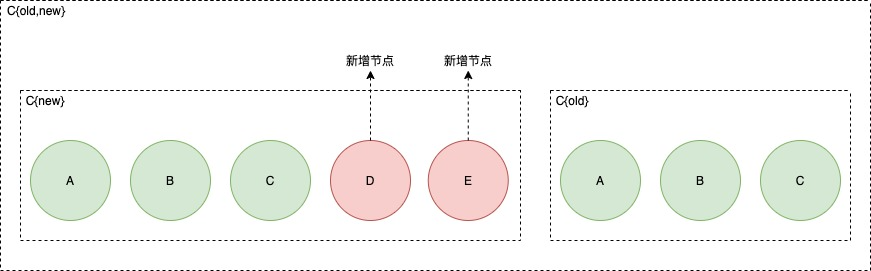
在etcd3.5之后引入了联合共识(joint consensus)的方式来支持一次性添加多个节点。
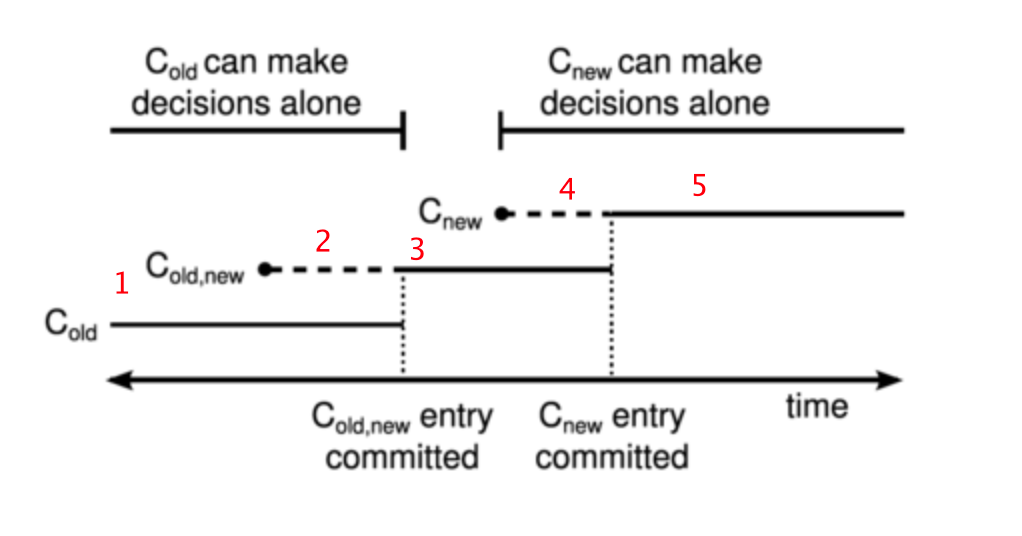
这里引入raft论文的一张图来解释(我标注了下阶段):
图中虽然是commited,但感觉把它理解为此时大多数节点都commited了该日志并应用了会比较好理解,因为commited的日志并不代表它已经应用了,没应用的话那么集群配置也就没有改变。
(1)C{old,new}日志还没被提交应用时,只有旧配置,只能是C{old}决定选出一个leader,即对应图中的1阶段;
(2)在C{old,new}日志被提交,部分节点应用时,这时原先Leader宕机,下一个选举的节点的集群配置要么是C{old},要么是C{old,new},不管是哪种情况都会兼容考虑C{old}的节点来产生Leader,没有节点会单纯基于C{new}来产生Leader,即对应图中的2阶段;
(3)在C{old,new}日志大多数节点commit并应用了,C{new}日志还未提交时,那么此时能发起Leader选举成功的都是C{old,new}的配置,只能是C{old,new}决定选出一个leader,即对应图中的3阶段;
(4)在C{old, new}日志大多数节点commit并应用了,C{new}日志被提交,部分节点应用时,这时原先的Leader宕机,下一个选举的节点的集群配置要么是C{old, new},要么是C{new},不管是哪种情况都会兼容考虑C{new}的节点来产生Leader,没有节点会单纯基于C{old}来产生Leader,即对应图中的4阶段;
(5)在C{new}日志大多数节点commit并应用了,那么此时能发起Leader选举成功的都是C{new}的配置,只能是C{new}决定选出一个leader,即对应图中的5阶段;
在etcd的实现里,其实没有这么复杂,它也是把配置变更分为了两个阶段来变更:
(1)EnterJoint阶段:此时会有两个配置,一个是C{new}配置,一个是C{old}配置,也就是对应到上文中的C{old,new},在进行决策时会需要C{new}和C{old}都会进行决策,比如在决策投票时,C{new}如果失败了,那么也算是失败,只有两个都成功才算是成功;
(2)LeaveJoint阶段:此时会把C{old}配置清理掉,只留下C{new}配置,这个应用完后就只有C{new}进行决策了。只有在EnterJoint执行完后才会执行这个阶段(会有参数配置是由raft自动执行这个阶段还是由调用者手动执行这个阶段)。
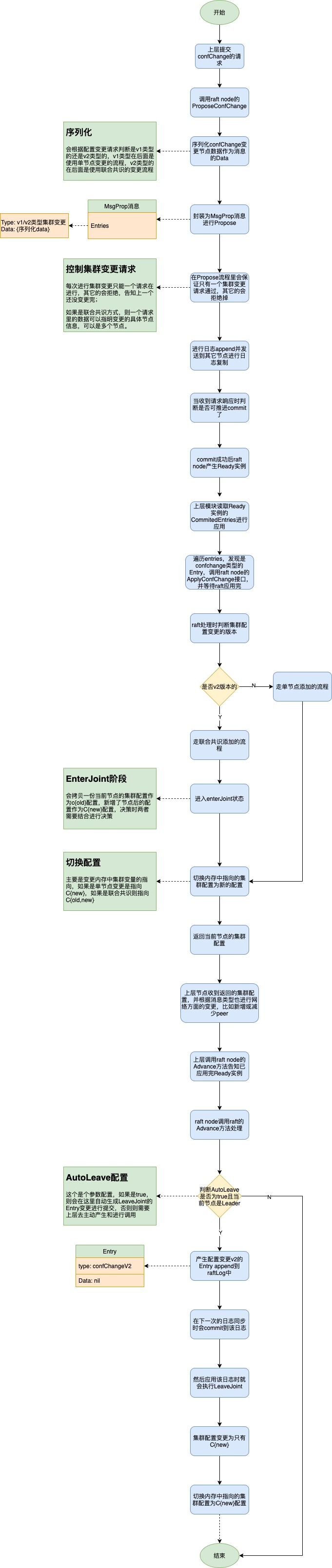
节点变更流程图:
在etcd raft中其实还存在Learner的概念,它在节点中是没有投票功能的,它的任务是进行raft日志的追赶,当追赶上了时就可以变更为Follower节点的状态,或者有要下线的节点也可以安排在LearnNext中,所以相比上面讲到的内容会新增了一些逻辑复杂度,会多了一些限制和条件检查,但变更逻辑保持只有一个Leader的原理实现还是一样。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号