JuiceFS框架介绍和读写流程解析
1.基本组件介绍
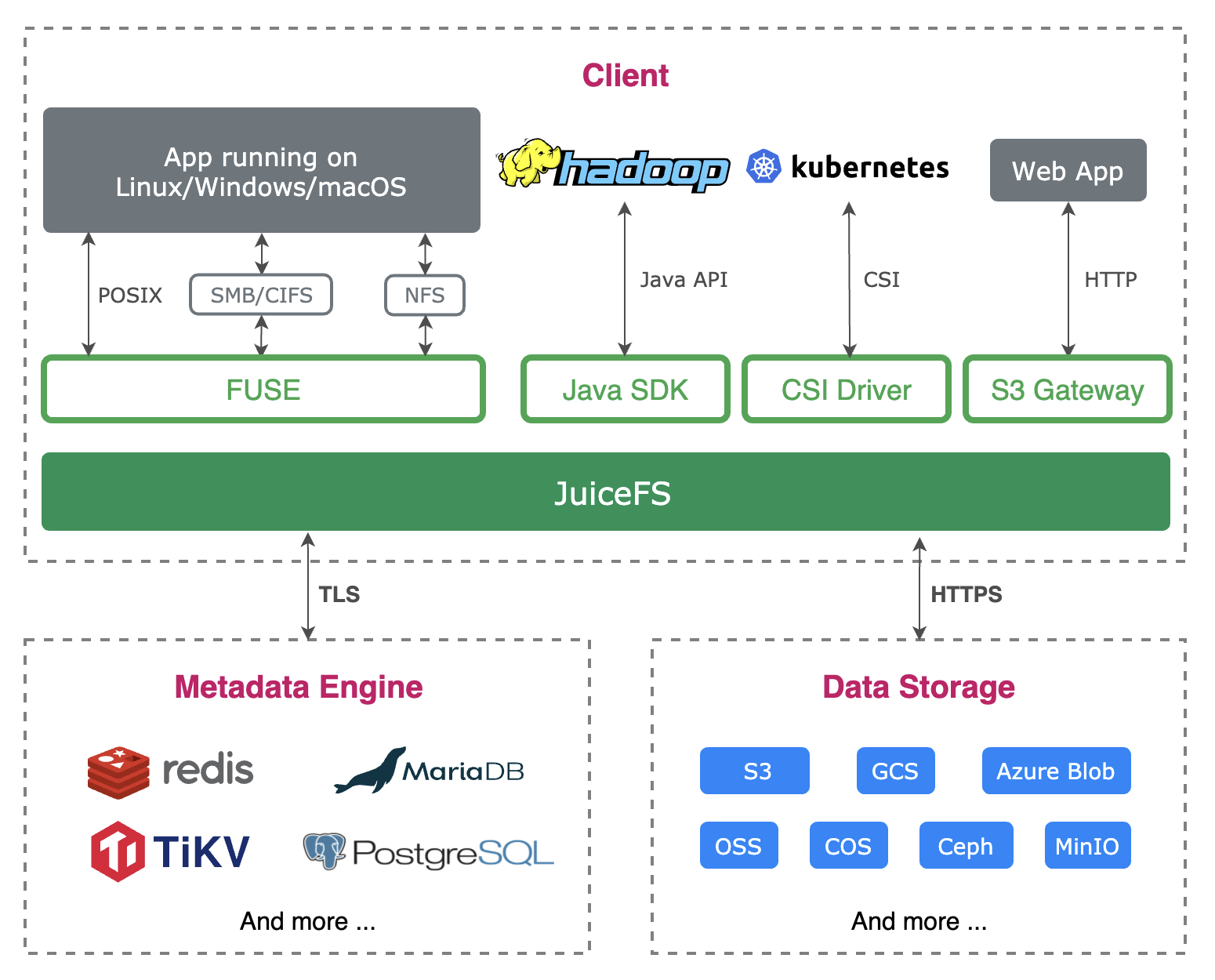
JuiceFS Client:支持多种Client端的接口,比如兼容POSIX文件系统的接口,以此你可以将它挂载到系统上当文件系统使用,且可以为k8s提供存储使用,用ks8s的csi driver进行接入。同时也支持S3协议,开发了对应的S3网关进行支持;
Data Storage:对象存储服务,用以存储具体数据的,可以类比文件系统里的block数据保存,支持多种后端存储;
Metadata Engine:元数据服务,用以存储文件元数据信息的,比如文件名、目录信息、文件inode等信息,可以类比文件系统里的inode数据管理,支持多种元数据存储;
2.快速部署
我们使用docker部署一个minio作为对象存储服务,用docker部署一个redis作为元数据服务。
git下载juicefs代码并进行编译生成juicefs二进制可执行文件:
git clone https://github.com/juicedata/juicefs.git
cd juicefs && make
安装docker和下载redis和minio/minio镜像。
部署元数据服务和对象存储服务:
sudo docker run -d --name redis -v /data/redis-data:/data -p 6379:6379 --restart unless-stopped redis redis-server --appendonly yes
sudo docker run -d --name minio -v /data/minio-data:/data -p 9000:9000 --restart unless-stopped minio/minio server /data
进行format和挂载:
mkdir /data/ussfs
./juicefs format --storage minio --bucket http://127.0.0.1:9000/test123 --access-key minioadmin --secret-key minioadmin redis://127.0.0.1:6379/10 test123
./juicefs mount -d redis://127.0.0.1:6379/10 /data/ussfs
3.挂载过程分析
format过程:
format的作用是将一些元数据信息先注册好,在mount时进行获取作为配置参数,比如对象存储的相关信息,bucket的相关信息等。

流程说明:
(1)接收客户端执行的命令,如果是mount的命令,则进入mount逻辑;
(2)通过format给定的url来判断是哪种元数据服务,并初始化元数据服务对象;
(3)构建format结构体对象,结构体里包含对象存储服务信息,block size等信息;
(4)根据format的信息初始化对象存储服务并测试对象存储服务是否可增删改操作,确保对象存储服务可用;
(5)持久化format信息,在redis为元数据服务时,即是将格式化后的format数据保存到redis的setting这个key中;
(6)创建inode号为1的第一个文件,文件类型为目录,作为后续创建文件的父目录,并持久化到元数据中。
mount过程:
mount就是将自定义的文件系统挂载到指定目录下,可供符合POSIX的接口进行调用,由mount中开启的server服务进行文件操作请求接收并处理。

流程说明:
(1)获取mount中的命令行参数,获取到元数据信息url;
(2)创建元数据服务连接实例,从元数据服务中获取之前保存的format信息;
(3)根据format信息创建对象存储服务连接实例storage,创建store对象,store对象是对对象存储数据进行管理,store对象属性里包含了storage对象和对cache的管理;
(4)初始化vfs对象,vfs是一层虚拟文件系统对象,它包含了对meta和storage的管理,创建了读写对象和文件句柄管理;
(5)如果命令行参数中是有用-d指定了mount进程后台运行,则调用makeDaemon函数将fork出一个进程作为daemon进程后台运行;
(6)通过读取挂载目录文件属性来检查挂载目录是否可进行挂载;
(7)创建本次挂载session,生成session信息保存到元数据服务中;
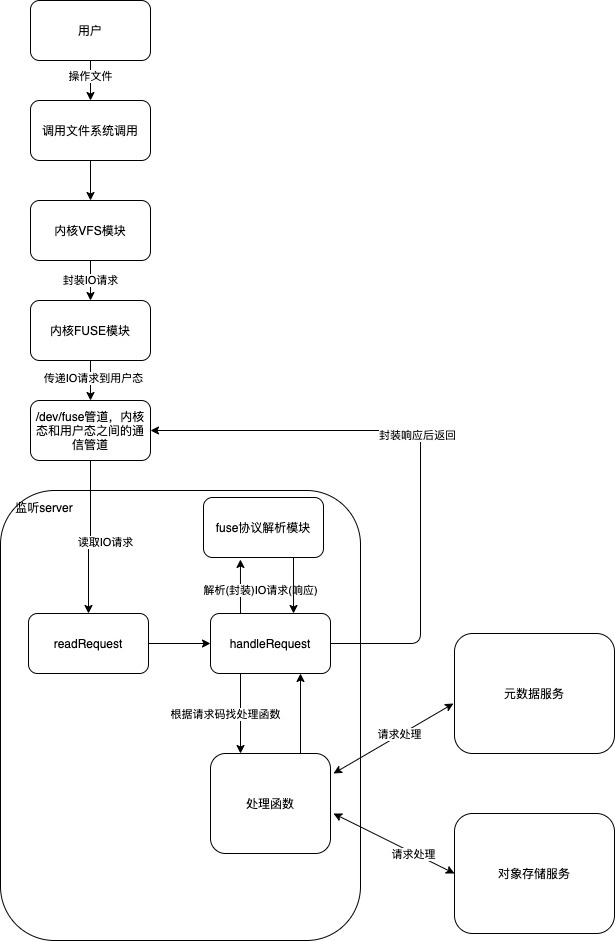
(8)创建自定义的文件系统类型,通过用户态fuse(用户空间实现文件系统)库来进行实现,启动服务来接收fuse的请求信息并封装成request,解析request找到对应的处理函数进行处理并返回。
启动的server接收fuse请求大致流程图:
4.元数据保存key含义解析
主要介绍在redis为元数据服务时,保存的各个key的含义,方便下面讲解读写流程。
这里我们先列出redis中保存的所有key:

可以看到,大概分成好几种key,有i开头的,有d开头的,有c开头的,还有其它的一些固定字符串的key。
setting:保存的format信息的key,对应的结构体:
type Format struct {
Name string
UUID string
Storage string
Bucket string
AccessKey string
SecretKey string `json:",omitempty"`
BlockSize int
Compression string
Shards int
Partitions int
Capacity uint64
Inodes uint64
EncryptKey string `json:",omitempty"`
}
i1:表示记录的inode号为1的文件的属性信息,同理i2为inode号为2的文件属性key,保存的值对应的结构体为:
// Attr represents attributes of a node.
type Attr struct {
Flags uint8 // reserved flags
Typ uint8 // type of a node
Mode uint16 // permission mode
Uid uint32 // owner id
Gid uint32 // group id of owner
Atime int64 // last access time
Mtime int64 // last modified time
Ctime int64 // last change time for meta
Atimensec uint32 // nanosecond part of atime
Mtimensec uint32 // nanosecond part of mtime
Ctimensec uint32 // nanosecond part of ctime
Nlink uint32 // number of links (sub-directories or hardlinks)
Length uint64 // length of regular file
Rdev uint32 // device number
Parent Ino // inode of parent, only for Directory
Full bool // the attributes are completed or not
KeepCache bool // whether to keep the cached page or not
}
d1:当文件为目录类型时,就会对应一个d开头的key,1表示该文件夹是inode号为1的,它是一个hash类型的键,它的每个field key是文件名字,field key对应的值是文件类型和对应的inode号,field key的值保存着文件类型和文件inode号。这样的话就可以方便的找到某个目录下的某个文件名的inode号及该文件的类型,同理d3就是inode号为3的文件夹记录着它文件夹下的文件元信息。
c14_0:c表示chunk的意思,我们先来看下这个数据结构图

可以看到一个文件数据会被拆分成chunk来进行保存的,如果是大文件,那么会被按指定大小拆分成多个chunk,这个c14的14就表示这个chunk是归属于inode14这个文件的,c14_0的0则表示是第一个chunk,该key是列表类型的键,它的每个元素是一个slice,slice不是固定大小的,slice会根据block size大小拆分成多个block进行存储,比如block size是4M,如果slice是6M,则拆分成2个block来进行存储,计算出对应的两个key把键值往对象存储服务中存储。比如生成35_0_16384和35_1_8192,35是表示这个slice的id(Slice结构体中的Chunkid字段),0和1表示两个block,16384和8192分别表示block的大小,分别为4M和2M。
chunk的结构体:是slices列表的数据结构,[]meta.Slice
Slice结构体:
// Slice is a slice of a chunk.
// Multiple slices could be combined together as a chunk.
type Slice struct {
Chunkid uint64
Size uint32
Off uint32
Len uint32
}
nextinode:它是一个自增的key,作用是分配新的inode;
nextchunk:它也是自增的,用来分配给slice的chunkid的;
nextsession:它也是自增的,用来给session结构体分配session id的。
totalInodes和usedSpace是记录当前一共有多少个inode和当前空间已使用量的。
5.读写文件过程分析
5.1.创建文件夹
创建文件夹命令示例:mkdir /data/ussfs/testdir
流程图:

流程说明:
(1)先获取根文件属性信息,然后通过文件路径和文件名获取指定文件属性,获取的方式就是一层层获取,比如/a/b/c,先是在a目录下找b,然后在b目录下找c,这是通过调用doLookup函数来查询获取;
(2)如果要创建的文件夹不存在则进行创建,创建调用doMkdir函数进行创建,该函数又调用mknode函数来创建文件信息(文件夹也是一个文件);
(3)从元数据服务器中获取一个新的inode号,如果是redis元数据服务,则是由一个自增的nextinode来保存当前分配的inode号;
(4)设置新文件的文件属性信息,比如权限、创建时间等信息;
(5)向父目录中添加该新文件,当redis为元数据服务时,则是向d开头的key里比如d1里添加一条该新文件信息;
(6)更新父目录文件属性信息、新文件属性信息和文件系统的一些总体使用信息。
创建文件跟创建文件夹类似,先调用的doCreate,然后也会调用mknode来生成inode和保存文件属性信息。
5.2.写入数据到文件
写入文件命令示例:echo "123456789" > /data/ussfs/testdir/testfile
流程图:

流程说明:
(1)跟先前类似,先通过文件路径找到该文件,获取该文件属性信息,如果文件不存在先创建文件;
(2)调用doopen函数打开文件,主要是初始化文件handle,创建文件读写对象,返回文件描述符;
(3)调用dowrite,传入偏移位置和写入数据,通过偏移位置计算出要写入到第几个chunk中去,如果是跨chunk(一个chunk默认64M),则先写入一部分数据到一个chunk,然后再写剩下的数据到下一个chunk;
(4)在一个chunk中查找合适的slice进行写入,比如改变的数据是在中间部分的,那其实只要更新那一个slice数据即可,其它slice可以不变更,我们目前这场景是找不到一个合适的slice,它会创建一个slice,然后通过该slice进行数据上传;
(5)通过偏移量进行block的计算,每个block会生成对应的key,然后调用对象存储的put方法进行key value的上传来存储数据;
(6)保存slice元信息到元数据服务中。
5.3.读取文件数据
读取文件命令示例:cat /data/ussfs/testdir/testfile
流程图:

流程说明:
(1)跟先前类似,先通过文件路径找到该文件,获取该文件属性信息,如果文件不存在先创建文件;
(2)调用doopen函数打开文件,主要是初始化文件handle,创建文件读写对象,返回文件描述符;
(3)分配存储数据的page数据结构,从元数据服务获取所有slice列表;
(4)遍历每个slice,取出slice对应的所有block信息保存到page对象中;
(5)如果block有缓存则直接从缓冲中获取,否则从对象存储中重新获取,并进行缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号