

TiKV读写流程浅析
1.TiKV框架图和模块说明
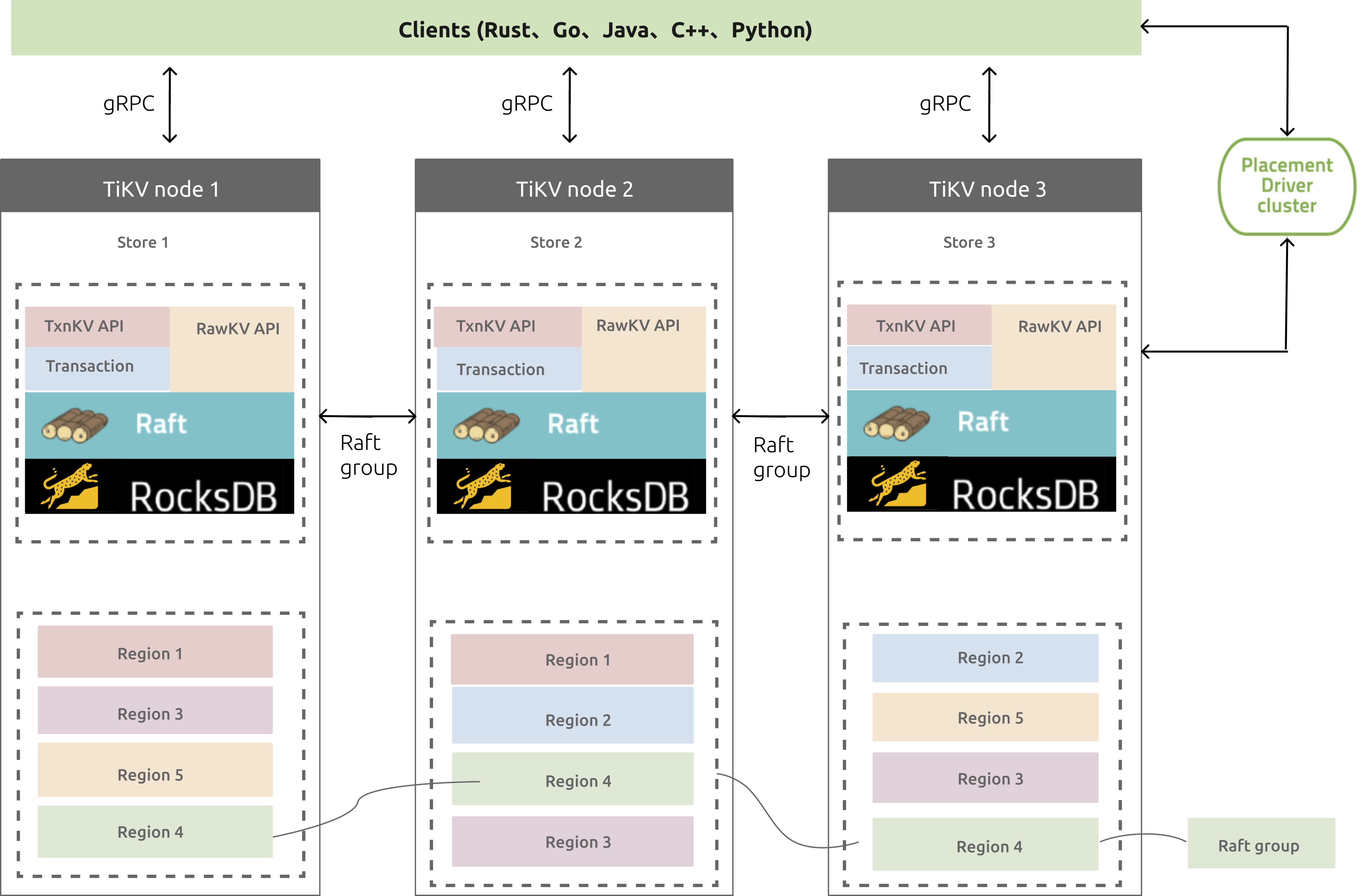
图1 TiKV整体架构图
1.1.各模块说明
PD Cluster:它是由多个PD节点组成的etcd集群,PD是具有“上帝视角”的管理组件,负责存储元数据和进行负载均衡,比如Region对应的range段信息、调度Region切分和合并等;
gRPC:开源远程过程调用系统,客户端服务端可基于该协议进行请求通信;
Placement Driver:管理TiKV集群,管理着整个集群的元数据信息,负责检查数据一致性和数据自动平衡迁移;
TiKV node:用来存储键值对的节点;
TxnKV API:支持事务操作的API;
RawKV API:不保证事务的的API;
Raft:一致性算法,TiKV集群使用了该算法来同步节点数据;
RocksDB:TiKV的真实后端存储组件,RocksDB本身是个开源的键值对存储系统;
Region:键值对数据移动的基本单位,每个region被复制到多个Nodes;
Raft group:多个同Region就组成一个Raft group,比如图中不同颜色的Region,同颜色的就组成一个Raft group;
Leader:每个Raft gorup会有个Leader,负责处理客户端的请求读或写,请求会先到Leader节点,再由Leader节点通知从节点修改。
1.2.功能特性
(1)多副本数据和数据自动均衡;
(2)容错和数据恢复;
(3)支持设置key的过期时间;
(4)支持原子性的CAS(compare-and-swap);
(5)支持分布式事务;
2.TiKV工作流程原理
2.1. 分布式事务
TiKV的事务模型是使用Percolator Transaction model。
该事务模型依赖于一个时间戳服务,我们称它为timestamp oracle,它会定时预先分配一个范围时间戳,并且会将最大的那个时间戳保存到磁盘上,然后即可在内存中递增产生范围内的时间戳给请求,这样即使该时间戳服务宕机了,下一次它预分配的也会从之前在磁盘上保存的那个最高时间戳后开始进行预分配,保证分配的时间戳永远是不会回退的。该时间戳服务是嵌入到PD服务里的,由PD leader进行服务。
Percolator最先是应用在google的BigTable项目上的,它是一个支持单行事务的分布式存储系统。
Percolator有CF(column family )的概念,类似于Rocksdb中的CF,每个CF会对应一个LSM Tree,但共享与一个WAL。
Percolator有5个CF,分别是lock、data、write、notify和ack;
Tikv里只涉及到前面3个,这里只讲述前面3个。
当开启一个事务写入一个 key-value 的时候:
Prewrite阶段(两阶段中的第一阶段):
lock CF:将该key的lock放到lock CF;
data CF:将该key对应的value放到data CF;
Commit阶段(两阶段中的第二阶段):
write CF:将相对应的commit信息放到write CF;
写数据过程:
在提交数据时采用两阶段提交。
Prewrite阶段:
(1)获取事务的开始时间戳start_ts;
(2)将事务涉及到的多个数据在lock CF中进行写入,写入时会检查是否该数据是否已经被其它事务锁住,如果是则进行回滚;并且从多个数据中选择一个作为primary lock,其它的使用secondary lock,secondary lock里包含了primary对应数据的信息;
(3)将新数据写入到data CF中,同时在写入时也需要检查该数据是否有大于start_ts时间戳的事务更新提交,如果有则表示有冲突,需要进行回滚
如果Prewrite阶段没有冲突,则Prewrite阶段成功,进入Commit阶段。
Commit阶段:
(1)获取commit时间戳commit_ts;
(2)对primary的数据进行写入,将commit信息写入到write CF中,从lock CF中移除该数据的primary lock;
(3)对Secondary的数据进行写入,类似primary一样的操作;
注意:commit阶段当完成了第(2)步的primary数据的commit后就表示这个事务已经成功了,即使第(3)步的Secondary的数据commit失败了也不影响整个事务表示成功,所以commit阶段当完成了前两步就向客户端表示事务成功,第(3)是使用异步步的方式进行commit的。原因是Prewrite阶段上锁成功表示commit阶段不会有冲突问题,所以一般都会成功,但有一种情况会失败,那就是比如发生了类似宕机这样的事情,那么此时Secondary锁还会在lock CF里,所以其它事务在检测该数据锁时是判断不了该数据事务是否已提交的,它可以通过Secondary lock获取到之前Primary的信息,然后去查找对应的Primary数据是否commit成功,如果是则表示该事务已经提交成功了,继续执行,如果Primary lock也还存在还未提交则上锁失败。
举例:
假设Bob有10元,Joe有2元,现在Bob要转7元给Joe。
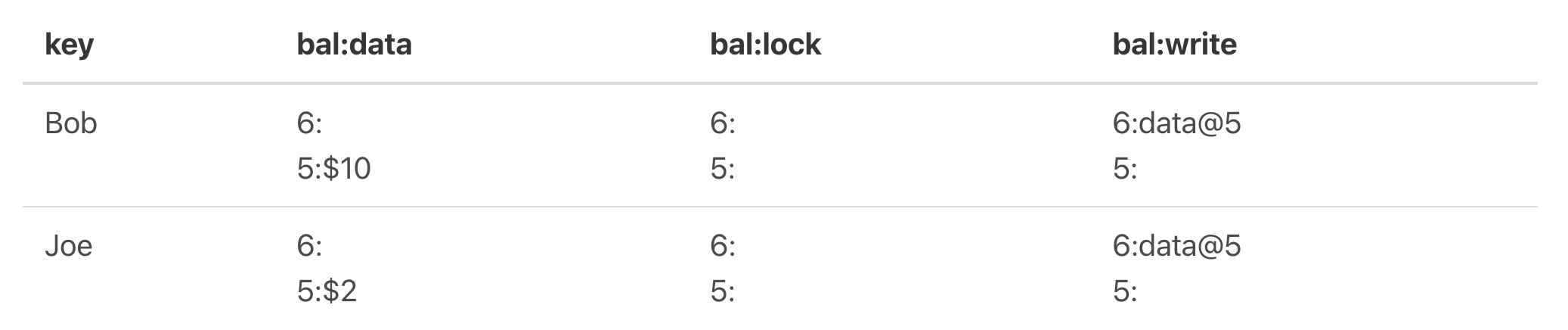
图2
如上图,这里涉及到两个key,Bob和Joe,它们目前key情况是最新提交是6,对应的data值是10和2。
现在进行转账操作,进行数据提交,那么在Prewrite阶段,就要进行lock CF写入和data CF写入,写入后如下图:
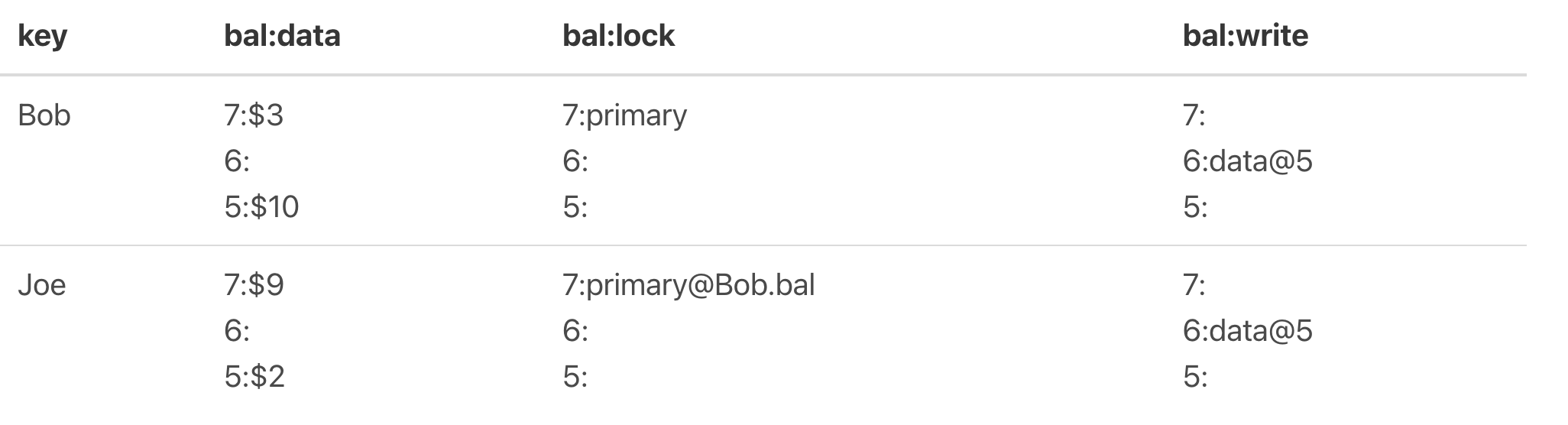
图3
可以看到Bob该key被选中为Primary,并且data里都写上了经过转账后的值,分别为3和9,并且前面的7为申请的start_ts。
Prewrite阶段顺利,进入commit阶段,先primary的key进行commit,commit后的情况如下图:
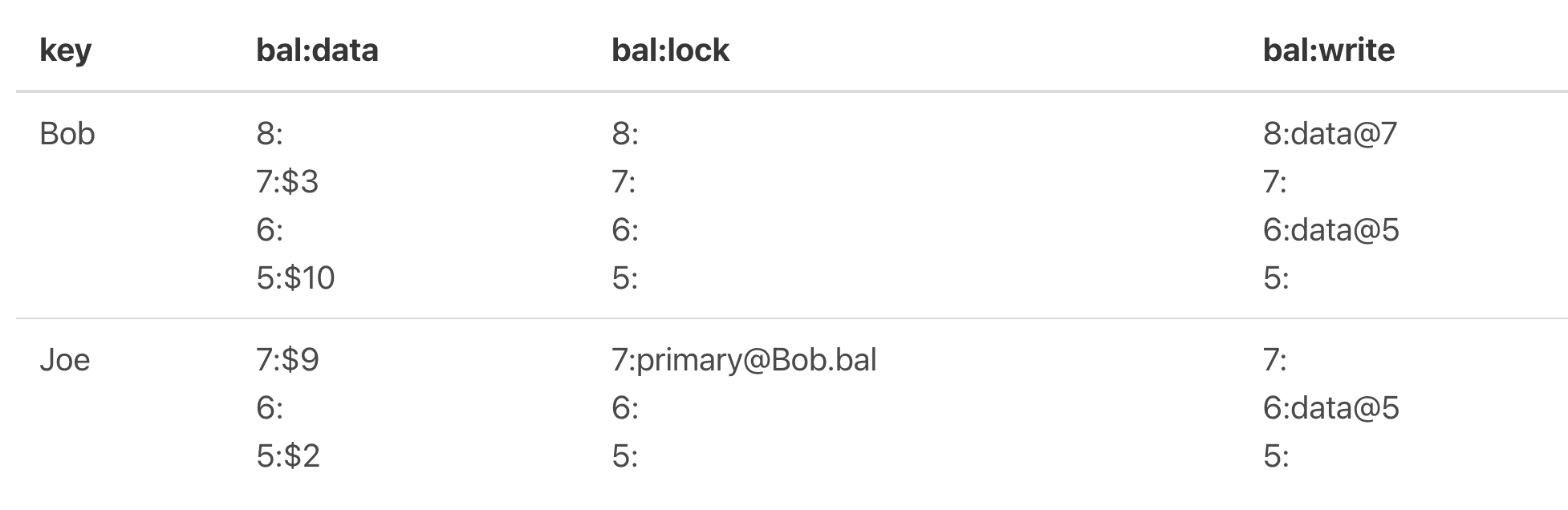
图4
可以看到Bob的primary lock已经移除,Joe的还没commit。
Joe的也进行commit得到如下图所示:
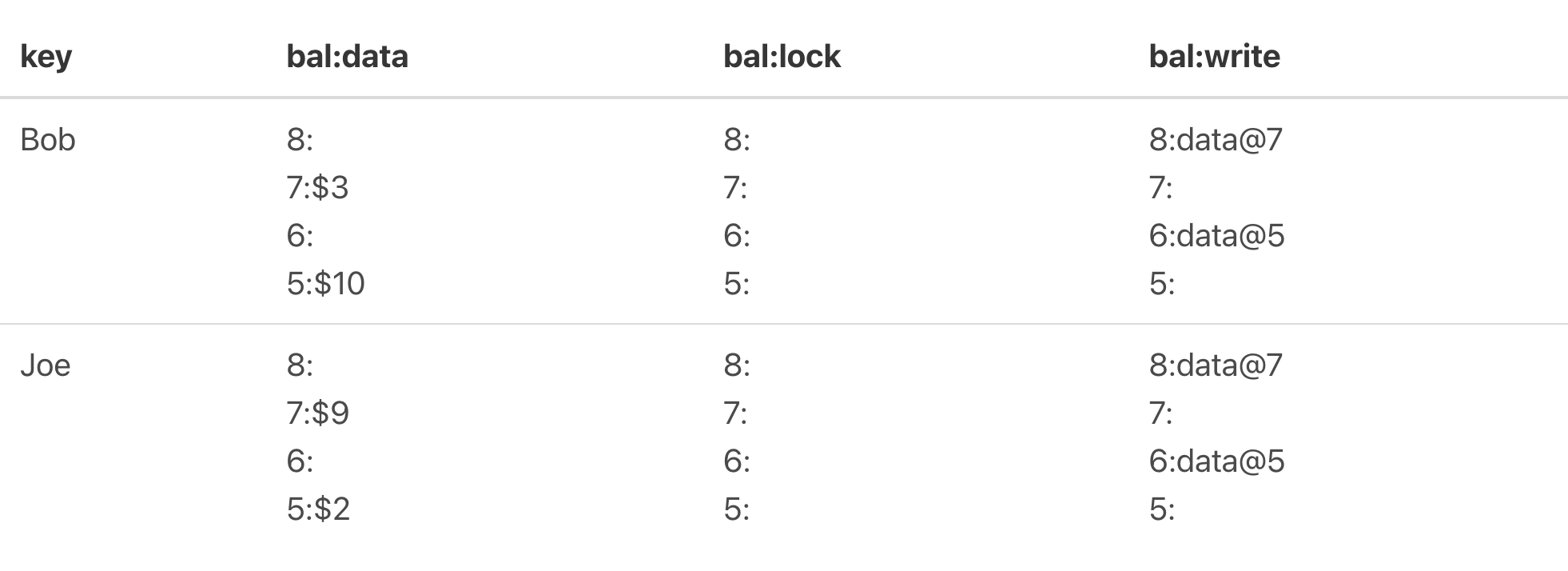
图5
读过程:
假设以图5为例,读取Bob key的值。
(1)首先也需要申请一个start_ts;
(2)然后在lock CF上搜索Bob key在[0, start_ts]上有没有被上锁,如果有则读取失败待会进行重试,可以看到Bob key上是没有锁的;
(3)从write中获取[0, start_ts]最新的写事务提交值,取到了该key最新写事务的start_ts,从图中可以看到是7;
(4)通过7去获取data CF上的start_ts为7时的值,从图中可知是3,获取成功并返回。
TiKV中的Percolator跟上述讲的类似,不过它的CF是defautl、lock和write,default对应的是上面所描述的data。同时也做了一些优化。
从上面过程中,我们看到在写入data时,是将key和start_ts一起写入的,start_ts是一个8bytes的值,会将它用大端序表示并进行取反(最新事务start_ts比旧事务start_ts大,取反后就会比旧start_ts小了),这样做的目的是因为rocksdb存储的LSM Tree的key是按序存放的,所以相同的key的不同版本会是相邻的且最新的事务的key排在前面,这样在查找最新事务提交时就会最先找到。
优化点:
(1)一个事务多个keys的Prewrite会分发到多个tikv节点进行并发预写,当有一个失败时,则进行回滚;
(2)对于比较小的value,在两阶段提交时,数据最后不放入data CF里,而是直接存放到write CF里,这样就不用先在write CF找,然后再在data CF里找,只需要一个LSM Tree的查找;
(3)如果事务只读取单个key,没必要获取start_ts,直接从write CF里读取最新版本的提交;
(4)由于单个Region的多个key的写入是原子方式写入的,所以对于一个事务,如果涉及的写入的key都是在同一个Region的话,就可以不使用两阶段提交方式写入了,直接1阶段提交写入。
2.2. 写入流程
在TiKV中,Region是保存key的基本单元,client端在读写数据时,都会先从pd中获取指定key对应的Region信息,比如Region对应的leader tikv节点,然后向该节点发起请求,同时该Region的信息也会被缓存下来可用来加速后续的同样在该Region的key的读写。
非事务的写入流程图:
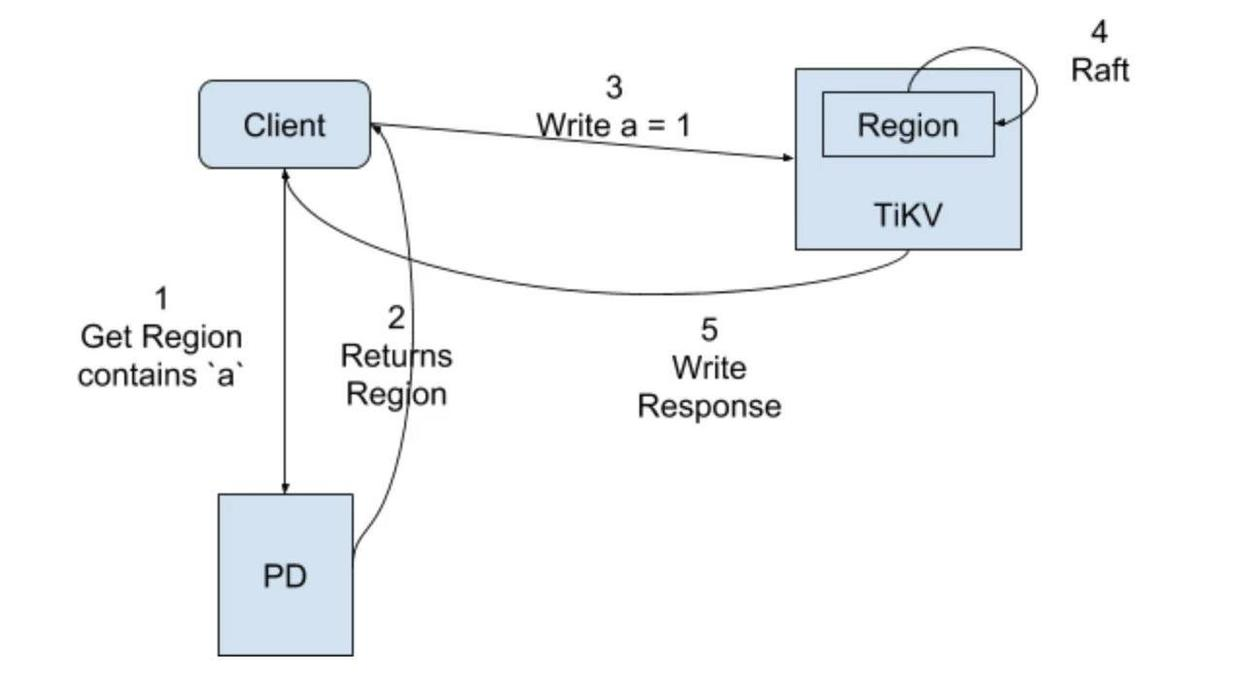
非事务写入流程:
(1)client端获取操作的key所在的Region信息;
(2)PD返回该key所在Region的信息,包括Region对应的TiKV Leader节点信息等;
(3)向TiKV服务发起写请求;
(4)由于Region是一个Raft group,这期间会进行一个Raft协议共识,会让该Region的followers节点也收到该操作日志(把操作当做一个日志,进行日志复制,应用时解析该日志进行执行),收到半数以上回复时即Leader节点应用该日志并回复客户端,且在下一次心跳时告诉客户端应用该日志;
(5)回复处理结果。
非事务的读取流程图:
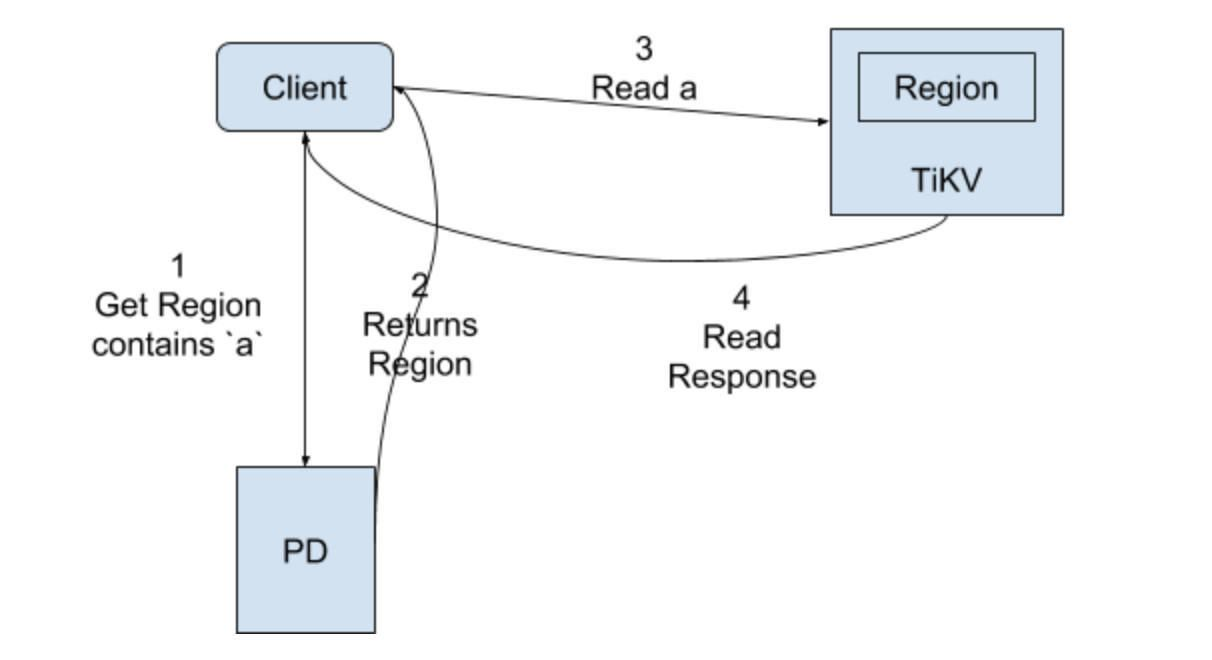
非事务读取流程:
(1)向PD获取Region的信息;
(2)返回Region信息;
(3)请求TiKV节点读取key值;
(4)返回key值信息;
事务写请求图:
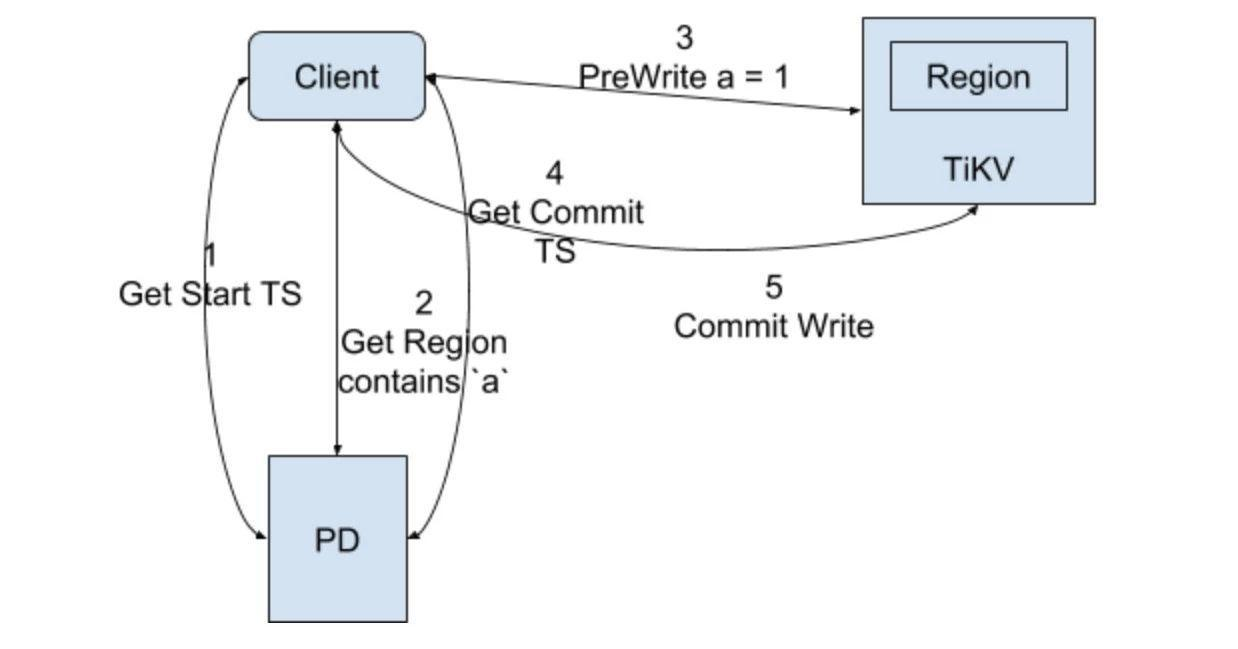
事务写请求流程:
注意,这里图中只写了事务中只有一个key更改的情况,没有代表性,流程里讲时会加入b也更改,且与a在不同的Region。
(1)开启事务获取事务start_ts;
(2)client端获取a和b的Region信息,假设a对应Region1,b对应Region2,那么在Prewrite阶段,client端会并行分别向这两个Region节点发送写请求进行预写,同时参数里会带上start_ts和Primary或Secondary,预写入的过程就类似于上面写的Percolator的Prewrite的过程,这里以key a为例讲述具体写入CF的过程,假设申请的start_ts是10,key b也是一样的,如果两者有一个Prewrite阶段失败,那么就是失败,进行回滚操作;
首先是写lock CF:
lock CF:W a = Primary
然后是data CF:
data CF:a_10 = new_value
(3)当key a和b的Prewrite都成功的情况下进行Commit阶段;
(4)申请commit_ts,假设是11;
(5)此时client端只会先向key a的Region1发起commit请求(因为它是Primary lock),然后就是Percolator的commit阶段
写write CF,它的值是start_ts:
write CF:a_11 = 10
(6)key a的commit成功则向用户返回事务成功了,然后再异步提交key b的commit,这里key b就算失败也无碍的原因在Percolator里说过了,本质就是其实CF里都已经记录下最新值的修改了,只是Secondary的lock没有移除掉。
事务的读请求流程图:
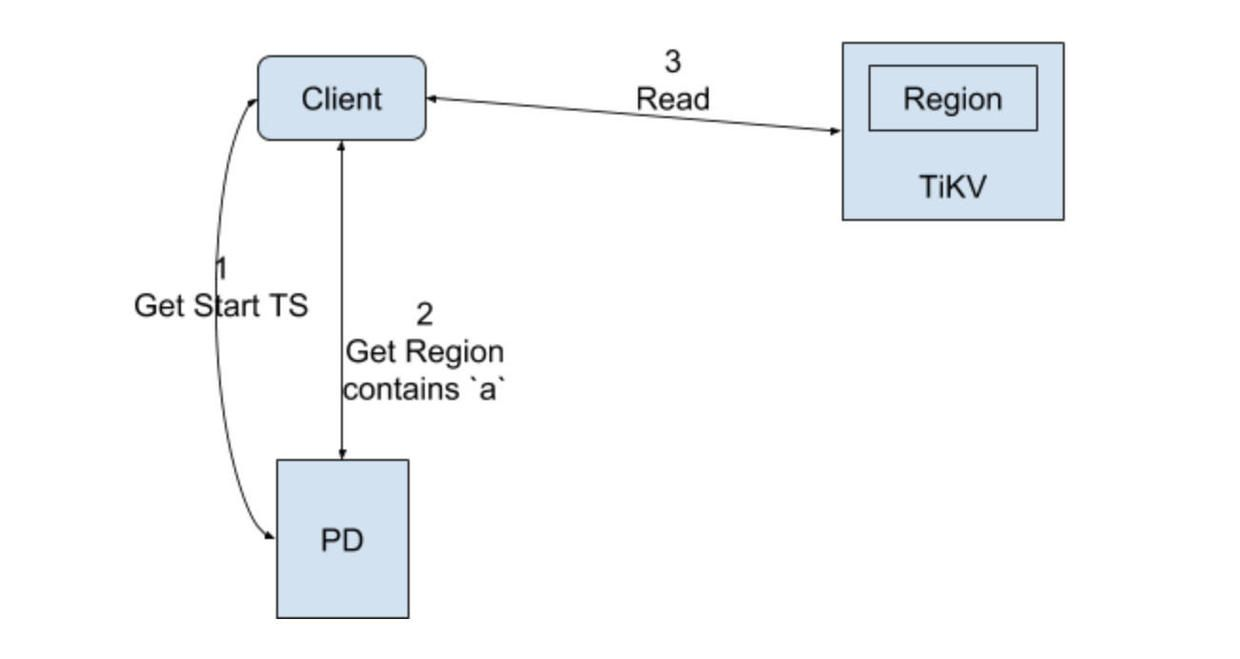
从Leader Region节点读取值。
2.3.Range划分
tikv的range是一种按照key字节序进行排序的可看做是无限的sorted map,如果将该range按指定的点进行切分成多段range,那么每段range就是一个region;
tikv初始只有一个region,可以记为["", ""),region遵循左闭右开,比如如果使用key为abc1对该region进行切分则会得到两个region:
region1:["", "abc")
region2:["abc", "")

默认配置下,一个Region的保存上限大小是96M,当Region保存的数据大于96M时,就会进行Region自动切分,分成均衡的两个Region。
配置参数:region-split-size
TiKV在4.0版本引入了Load Base Split特性,该特性是用来解决Region热点问题,当大量请求都打到一个Region时,由于一个Region的读写都是由一个节点上的Leader进行处理的,导致大部分请求由一个节点处理,会造成瓶颈,该功能特性的原理是基于统计的信息进行判断,如果某个Region 10s内的qps或流量超过了配置文件中指定的值,则会对其进行Region拆分,并被调度分配到不同的节点上以打散热点Region。
相关配置参数:
QPS阈值参数:split.qps-threshold
流量阈值参数:split.byte-threshold
除了分裂,Region也会进行合并操作,避免有大量的空Region存在,造成大量的通信和管理开销。
系统会定时的去轮询检测所有Region,如果Region的大小大于max-merge-region-size配置值(默认20M),则不会与相邻的Region进行合并;如果Region的key的数量大于max-merge-region-keys配置值(默认
200000个)则不会与相邻的Region进行合并;否则其它情况都会与相邻的Region进行合并。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!