Neutron组件底层实现原理
1 Linux底层虚拟化设备介绍
1.1 tun/tap
tun和tap是Linux操作系统内核中的虚拟网络设备,实现tun/tap设备的内核模块为tun。
tap等同于一个以太网设备(网卡),工作在数据链路层,tun模拟了网络层设备(点对点设备),工作在IP层,利用tun/tap驱动可以将tcp/ip协议处理好的网络分包传递给使用tun/tap的进程。
可以理解为用户空间程序可像向物理口发送报文那样向tun/tap口发送报文,tun/tap设备发送(或注入)报文到OS协议栈(这里是指虚拟机的OS协议栈),就像报文从物理端口收到一样。
在Linux内核中添加了一个tun/tap虚拟网络设备的驱动程序和一个与之相关的字符设备/dev/net/tun,字符设备tun作为用户空间(qemu进程运行的空间)和内核空间交换数据的接口。 用户空间中的应用程序比如qemu程序可以通过该字符设备来与内核中的tun/tap驱动程序进行交互。当内核将数据包发送到虚拟网络设备时,数据包被保存在设备相关的一个队列中,直到用户空间程序通过打开的字符设备tun的描述符读取时,它才会被拷贝到用户空间的缓冲区中,其效果就相当于,数据包直接发送到了用户空间(host的用户空间,不是虚拟机的用户空间)。
tun/tap驱动程序中包含两部分:字符设备驱动(用来在宿主机上用户空间和内核空间互相传递信息的)和网卡驱动(也在内核层)。利用网卡驱动部分接受来自tcp/ip协议栈的网络分包并发送或者反过来将接收到的网络分包传给协议栈处理。而字符设备驱动则将网络分包在内核与用户态之间传送,模拟物理链路的数据接收和发送。tun/tap驱动很好的实现了两种驱动的结合。
tap一般用于作为虚拟机的虚拟网卡设备,tun一般用以vpn隧道。
tap/tun 通过实现相应的网卡驱动程序来和网络协议栈通信,可以把tun/tap看成数据管道,它一端连接主机协议栈,另一端连接用户程序,可以把用户层程序看做是网络上另一台主机,他们通过tap虚拟网卡相连。一般的流程和物理网卡和协议栈的交互流程是一样的,不同的是物理网卡一端是连接物理网络,而 tap/tun 虚拟网卡一般连接到用户空间。
TUN和TAP设备区别在于他们工作的协议栈层次不同,TAP等同于一个以太网设备,用户层程序向tap设备读写的是二层数据包如以太网数据帧,tap设备最常用的就是作为虚拟机网卡。TUN则模拟了网络层设备,操作第三层数据包比如IP数据包,openvpn使用TUN设备在C/S间建立VPN隧道
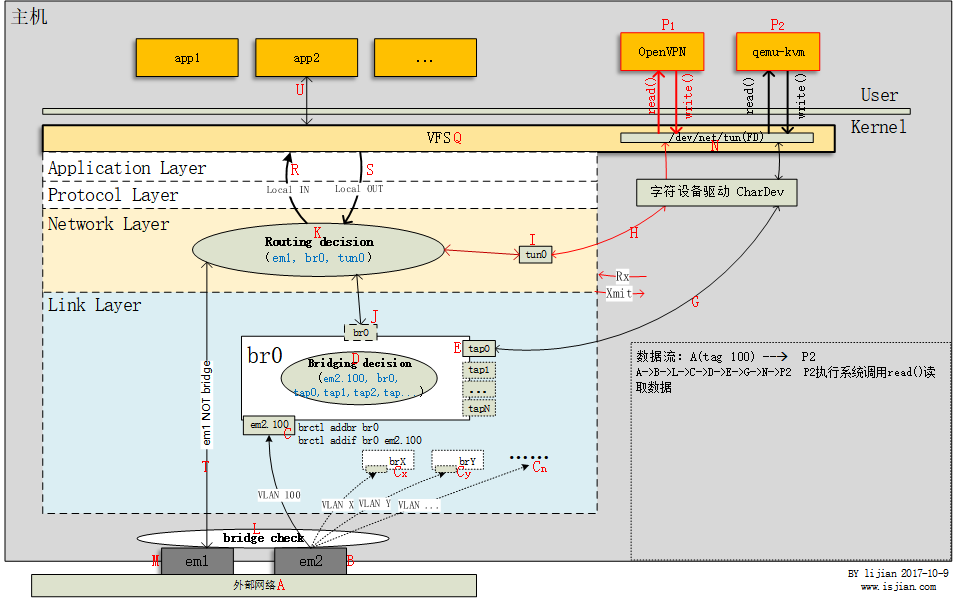
虚拟机通过虚拟网卡与向外网发送数据例子:
(1)虚拟机通过其网卡eth0向外发送数据,从主机角度看,就是用户层程序qemu-kvm进程使用文件描述符(FD)26向字符设备/dev/net/tun写入数据 P2 --> write(fd,...) --> N
(2)文件描述符26与虚拟网卡tap0关联,也就是说主机从tap0网卡收到数据 N --> E
(3)tap0为网桥br0上一个接口,需要进行Bridging decision以决定数据包如何转发 E --> D
(4)P2是与外部网络其它主机通信,因此br0转发该数据到em2.100,最后从物理网卡em2发出 D --> C --> B -- > A
可以看出在这个过程中,虚拟机发出的数据通过tap0虚拟网卡直接注入主机链路层网桥处理逻辑中,然后被转发到外部网络,数据包没有穿过主机协议栈上层,因此主机上工作在内核协议栈IP层的iptables是无法过滤虚拟机数据包的
Tun设备举例:
TUN设备连接的是主机内核协议栈IP层
(1)客户端使用openvpn访问web服务(图中没有画出客户端,在外部网络里)
(2)客户端启动openvpn client进程连接openvpn server
(3)server下发路由条目到客户端机器路由表中,同时生成虚拟网卡tun1(tun设备,openvpn client进程与openvpn server一样会注册tun虚拟网卡,server中则注册的是tun0虚拟网卡)
(4)客户端通过浏览器访问web服务
(5)浏览器生成的数据包在协议栈IP层进行路由选择,决定通过虚拟网卡tun1发出
(6)虚拟网卡tun1另一端连接用户层openvpn client进程
(7)openvpn client进程收到原始请求数据包
(8)openvpn client封装原始请求数据包,通过udp协议发送vpn封包到openvpn server上的9112端口 A -- > T --> K --> R --> P1
(9)openvpn server上的openvpn进程收到vpn封包,解包,使用文件描述符6写数据到/dev/net/tun P1 --> write(fd,...) --> N
(10)文件描述符6与虚拟网卡tun0关联,主机从tun0网卡收到数据包 N --> H ---> I
(11)主机进行Routing decision,根据数据包目的IP(用户访问web网站IP地址)从相应网卡发出 I --> K --> T --> M --> A
可以看出其实就是两端的服务进程对一个数据包封包解包过程,达到一个中间人的功能,服务端的web收到的包已经是经过解压的了,所以经常看到用此种技术来给公司分部访问总部内网服务,同时因为加了路由条目,以此让通道独立且数据流方向确定,加上SSL协议实现对数据包进行加密从而使得数据传输安全,传包则使用了常见的udp或tcp协议来传输。
1.2 LinuxBridge
Bridge是工作在Linux内核协议层二层的虚拟交换机,模拟了物理交换机的功能,可以添加若干个网络设备到Bridge的接口上,添加到Bridge上的设备被设置为只接收二层数据帧并且转发所有收到的数据包到Bridge中,Bridge内部维护了一个MAC表,从而可以将数据包转发到其它接口上或者发往上层协议(或者丢弃和广播)。
被添加到Bridge上的网卡是不能配置IP的,工作在数据链路层,对路由系统是不可见的,但可以给网桥配置IP地址。网桥只有设置了IP才能作为路由接口设备,参与IP层的路由选择,才有可能将数据包发往上层协议栈。
举例说明Bridge处理数据包流程,外部网络(A)发往虚拟机qemu-kvm (P2)过程数据流向:
(1)首先数据包从em2(B)物理网卡进入,之后em2将数据包转发给其vlan子设备em2.100
(2)经过Bridge check(L)发现子设备em2.100属于网桥接口设备,因此数据包不会发往协议栈上层(T),而是进入bridge代码处理逻辑,从而数据包从em2.100接口(C)进入br0
(3)经过Bridging decision(D)发现数据包应当从tap0(E)接口发出,此时数据包离开主机网络协议栈(G),通过用户空间进程qemu-kvm打开的字符设备/dev/net/tun(N)将数据包发往用户空间
(4)qemu-kvm进程执行系统调用read从字符设备读取内核层发送过来的数据包
(5)数据流走向A –>B –>C –>E –>G –>N –>P2
如果是从网卡em1(M)进入主机的数据包,经过Bridge check(L)后,发现em1非网桥接口,则数据包会直接发往(T)协议栈IP层,从而在Routing decision环节决定数据包的去向(A –> M –> T –> K)
上面第(3)步有一个Bridging decision的操作,这是根据数据包MAC地址来作出一些决策:
(1)包目的MAC为Bridge本身MAC地址(当br0设置有IP地址),从MAC地址这一层来看,收到发往主机自身的数据包,交给上层协议栈(D –> J)
(2)广播包(目的地址是广播地址),转发到Bridge上的所有接口(br0,tap0,tap1,tap…)
(3)单播&&存在于MAC端口映射表,查表直接转发到对应接口(比如 D –> E)
(4)单播&&不存在于MAC端口映射表,泛洪到Bridge连接的所有接口(br0,tap0,tap1,tap…)
(5)数据包目的地址接口不是网桥接口(连接到网桥的接口没有一个是目的地址的就会出现这情况了,比如广播泛洪没人回应),桥不处理,交给上层协议栈(D –> J)
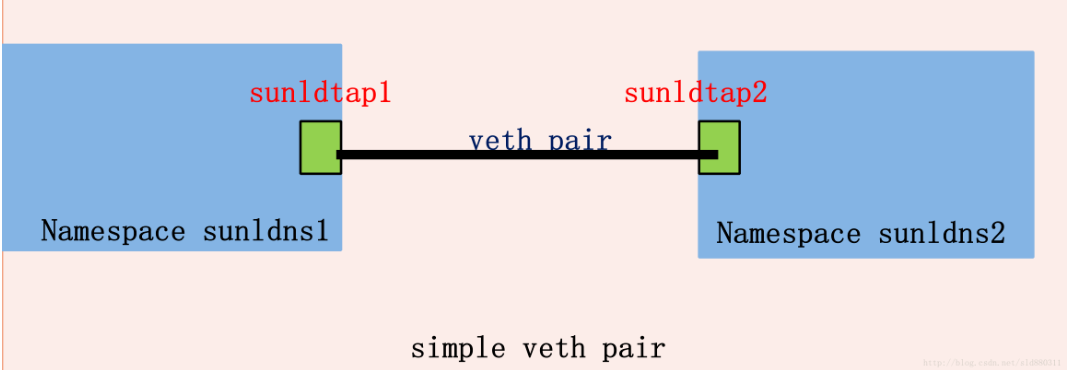
1.3 Veth-pair
首先了解下Linux网络命名空间概念,Linux内核提供了6种类型的命名空间:pid,net(网络命名空间),mnt,uts,ipc和user,Linux网络命名空间只是Linux命令空间中的一种,网络命名空间有自己独立的网络资源,比如网卡接口、路由表、iptables规则等。
命名空间将全局系统资源包装到一个抽象中,该抽象只会与命名空间中的进程绑定,从而提供资源隔离(命名空间和cgroups(一种计量和限制机制,可以理解为类似配额管理的东西)是软件集装箱化(Docker)的大部分新趋势的主要内核技术之一)。
可以使用ip netns命令创建网络命名空间:
ip netns add ns1
VETH设备总是成对出现,送到一端请求发送的数据总是从另一端以请求接收的形式出现。veth工作在L2数据链路层,veth-pair设备在转发数据包过程中并不篡改数据包内容。
veth的工作原理是:VETH会改变数据的方向并将其送入内核网络子系统,完成数据的注入,而在另一端则能读到此数据,有点类似于管道。
veth-pair常常用来连接两个网络命名空间
疑问:
(1)Openstack是怎么给的mac和ip地址
Openstack定义了port概念,并记录在数据库里,port可以看做是虚拟交换机上的一个端口,port上定义了MAC地址(虚拟机里显示的mac地址,不是宿主机上tap里显示的地址(这个tap只有在虚拟机启动时才创建挂载,关闭后就删除掉的))和IP地址,当instance的VIF(虚拟网卡)绑定到port时,port就将MAC地址和IP地址分配给VIF,内核根据port提供的信息来创建tap,
一般看到网桥创建后,如果上面就创建了一个tap设备,该tap设备是dhcp的(计算节点上没有dhcp服务,所以计算节点上执行brctl show会没有dhcp对应的tap设备)
2 Neutron的网络模式介绍
网络模式有local模式、flat模式、vlan模式、vxlan模式和gre模式
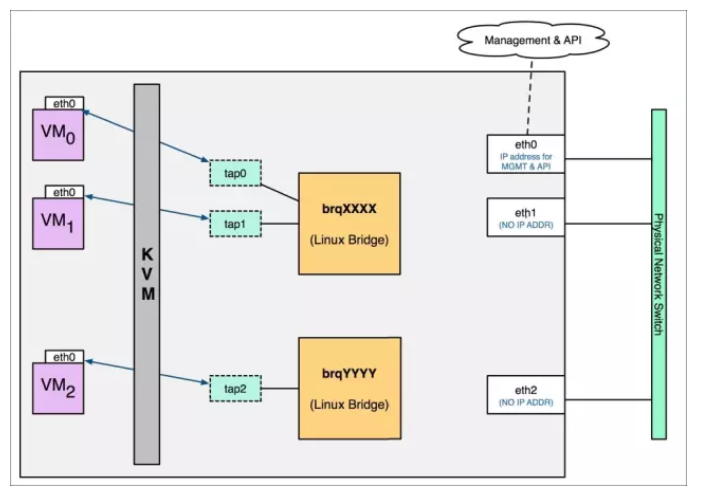
2.1 Local网络模式
该网络模式不会与宿主机的任何物理网卡相连,每个local网络都会维护一个bridge,同一个local网络下的虚拟机的网卡都会连接到同一个bridge下,所以只有同宿主机的同local网络下的虚拟机之间能够相互通信,其它都是隔离的。
2.2 Flat网络模式
Flat网络是不带tag的网络,要求宿主机的物理网卡直接与网桥连接,这也就是说每个flat网络需要独占一个物理网卡。
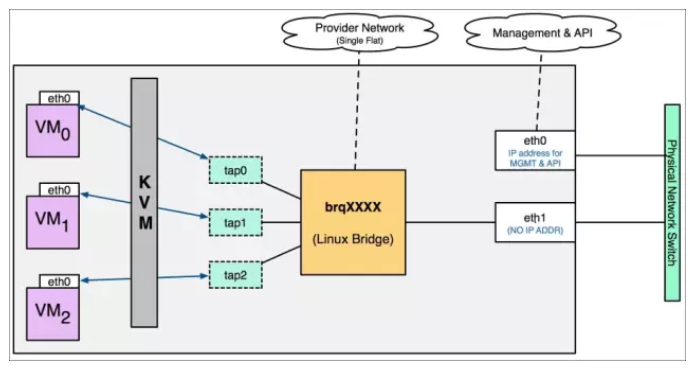
Openstack创建一个网络后通常都需要创建一个子网,即指明该网络的IP池和网关,并且设置是否要支持dhcp服务等。如果支持dhcp服务那么也会有一个tap接口连接到网桥中用以数据包通信来提供dhcp服务。比如刚创建的flat网络如果勾选了dhcp服务,那么brctl里就能看到该flat网络对应的网桥里除了物理网卡设备连接外,还有一个tap也连接着,它就是dhcp服务的tap。

![]()
计算节点是没有dhcp服务的,所以它是没有多一个设备连接到计算节点的网桥上的,但是在计算节点上的虚拟机在获取IP和MAC时,它可以通过控制节点上的dhcp服务来获取,因为他们在同一个network上,计算节点上发出的dhcp请求广播包在控制节点的网桥上也是可以收到的,然后由控制节点的网桥上的dhcp服务的设备接收并处理。
控制节点和计算节点各一个虚拟机分别连接到同一个flat网络时:
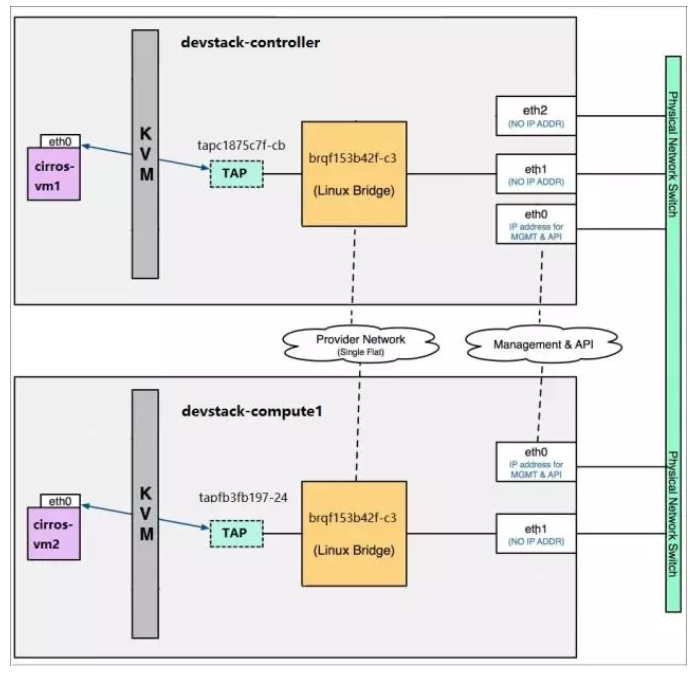
可以看到这两个虚拟机通信时是通过了物理网卡之间的连接进行的通信,假设是计算节点的虚拟机ping控制节点的虚拟机,首先数据包在计算节点的网桥里没找到目的端口由eth1将数据包发出去,计算节点的eth1和控制节点的eth1假设是在同一个交换机上(如果不是,则会走路由由网关进行数据包转发),该数据包会进行广播,控制节点的eth1收到该数据包发现目的IP有在自己网桥上,并将该数据包发给网桥上对应的接口即控制节点的虚拟机的tap。
疑问:
(1)为啥flat网络的物理网卡没有设置ip,怎么出外网的?
物理网卡连接到了网桥接口中,连接的口相当于是交换机的trunk口,通向外网的包会从这个物理网口出去。这里还是二层的数据包转发,不用设置IP。
2.3 Vlan网络模式
Vlan network是带tag的网络,是实际应用最广泛的网络类型。
直接看下图:
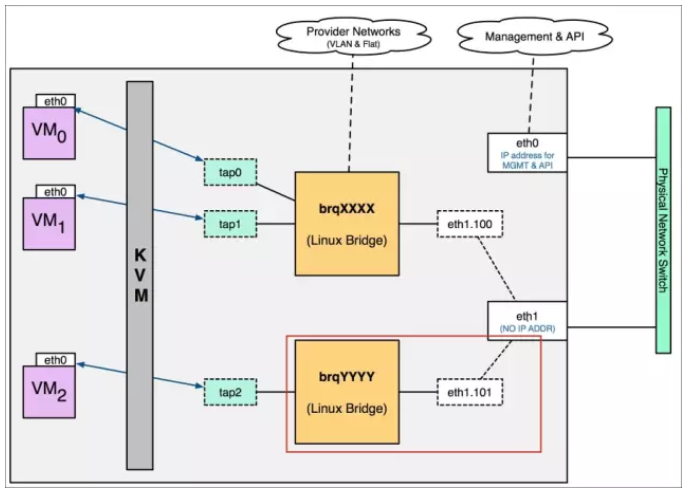
可以看到我们创建了两个vlan,100和101,一端连接到网桥接口上,另外一端连接到物理网卡eth1上,以eth1.100举例,VM0和VM1的数据包从eth1出去时是带着tag为100的标签的,同理VM2的则是带着tag为101的标签,这些标签是在经过eth1.100(或eth1.101)时打上的标签。因为物理网口eth1经过了两个vlan段,所以它所连接的交换机的口应该设置成trunk口,而不是Access口。
创建eth1.100和eth1.101可以使用vconfig来创建,
看下两个物理主机下的情况:

可以看见计算节点和控制节点的网桥名是一致的,表明是同一个私有网络。但因为vlan的隔离,vlan100和vlan101的虚拟机是不能相互通信的,如果需要通信需要三层的转发,也就是可以通过虚拟路由来实现。
疑问:
(1)为啥在某台机器网络是8网段,网关是8.1,要在一个交换机上设置了vlan 8才可以通外网呢?
我觉得应该是在交换机上设置的一个约定,比如你的数据包从这个端口出(假设一开始所有端口都是vlan 1的),那么它会检查你的ip是不是符合它设置的1网段的,如果不是那么直接丢弃,所以通不了外网。
举例:
交换机有2个vlan
int vlan10
ip add 10.1.1.2 255.255.255.0
ip default-gateway 10.1.1.1
int vlan 20
ip add 20.1.1.2 255.255.255.0
ip default-gateway 20.1.1.1
看个实际的操作截图例子:

可以看到对于每一个vlan其都有设定对应的网络地址。且还有设置网关,这里设置一个网关不用说是要在交换机上配置成这个网关,它只需简单的比如增加一条路由项:ip route 192.168.8.1 192.168.1.1,那么它出外网是就是把它路由到了192.168.1.1上去处理了(简单理解就是这里设置网关只是为了告诉交换机怎么转发这个数据包出去)。
所以上面的vlan 8和ip是不是8网段是没有绝对关系的,一切都要看交换机里的设置,是它判断vlan 8里的设定(比如设定可能是ip addr 192.168.8.2 255.255.255.0)是不是跟你包的ip在同一网段。如果vlan 8里的设定是ip addr 192.168.9.2 255.255.255.0,那你的ip是192.168.8.100/24是出不了的。
(2)为啥两个网卡设置了相同网段后,有一个网络会不通了?
我们观察到的现象就是后面的那个是可以ping通的,原因在于路由表
你用route命令查看路由变,可以看到类似以下这样的表项:
192.168.8.0 0.0.0.0 255.255.255.0 U 0 0 0 eth2
192.168.8.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
当外面ping eth1对应的IP的时候,当一个ping包到达后要回应时,它总是从eth2出去的(但其实我们是要eth1出去的),但eth2的IP并不是我们ping的包了
解决方法可以是改路由表项,比如专门为eth1建一个路由表项:
192.168.8.100 0.0.0.0 255.255.255.0 U 0 0 0 eth1
或者给每个网卡分配单独的路由表。并且通过 ip rule 来指定:
(3)具体tag记录在哪个位置
记录在以太网帧上,是数据链路层的概念
以太网帧格式:
|-----------------------------------------------------------------------------|
| DMAC(6bytes) | SMAC(6bytes) | Ether-Type(2bytes) | DATA |
|-----------------------------------------------------------------------------|
802.1Q VLAN定义了有tag的数据帧的封装格式,即在以太网帧头中插入了4个字节的VLAN字段。
带VLAN TAG的以太网帧格式 :
|------------------------------------------------------------------------------------------ --- --- ---|
| DMAC(6bytes) | SMAC(6bytes) | Ether-Type(0x8100) | VLAN(4bytes) | DATA |
|------------------------------------------------------------------------------------------ --- --- ---|
VLAN TAG的格式 :
|---------------------------------------------------------------------------------|
| PRI(3bits) | CFI(1bit) | TAG(12bits) | Ether-Type(2bytes) | DATA |
|---------------------------------------------------------------------------------|
PRI:帧优先级,就是通常所说的802.1p。
CFI:规范标识位,0为规范格式,用于802.3或EthII。
TAG:就是我们通常说的VLAN ID
Ether-Type:标识紧随其后的数据类型。
2.4 Vxlan网络模式
vxlan是overlay网络,overlay网络是指建立在其它网络上的网络。
目前linux-bridge只支持vxlan,open vswitch则可支持vxlan和gre网络。
Vxlan的全称是Virtual eXtensible Local Area Network,它也是提供以太网二层服务的。
相比Vlan,Vxlan的优势:
(1)支持更多的二层网段:VLAN使用12bit标记vlan id(最多支持4094个),Vxlan使用24bit标记vxlan id(vnid,支持16777216个)
(2)能更好利用已有网络路径:VLAN为了避免环路使用了Spanning Tree Protocol导致有一半网络路径不可用,vxlan则利用UDP包通过三层传输,可以使用所有路径。
(3)避免物理交换机MAC表耗尽:由于采用隧道机制,交换机无需在MAC表中记录虚拟机的信息
Vxlan的包格式是在链路层包前面加上8字节的Vxlan Header(vnid占24位):

通过UDP的传输,Vxlan能够在三层网络上建立一条二层的隧道。
Vxlan使用VTEP进行Vxlan的解包和封包,每个VTEP都会有一个IP接口,配置一个IP地址,VTEP使用该IP来封装链路帧包且通过该IP传输和接收Vxlan数据包。
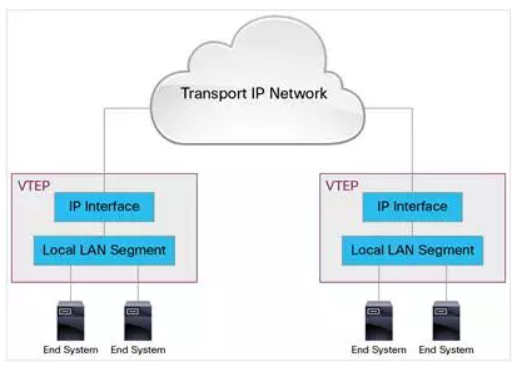
两端的 VTEP IP 作为源和目标 IP
VTEP的实现可以是硬件的,也可以是软件的,软件方面的实现:
(1)带Vxlan内核模块的Linux
(2)Open vSwitch

实现方式:
(1)Vxlan内核模块创建一个监听端口为8472的UDP Socket
(2)在Socket上接收到Vxlan包后进行解包并根据vxlan id转发到对应的vxlan interface上,比如vxlan-34(也是连接到网桥上的一个设备),由它把包传给网桥,网桥再发送给虚拟机。

(3)在Socket上接收到要发出去的数据包时则将其封装为UDP包并从网卡发出
Vxlan数据包转发流程:
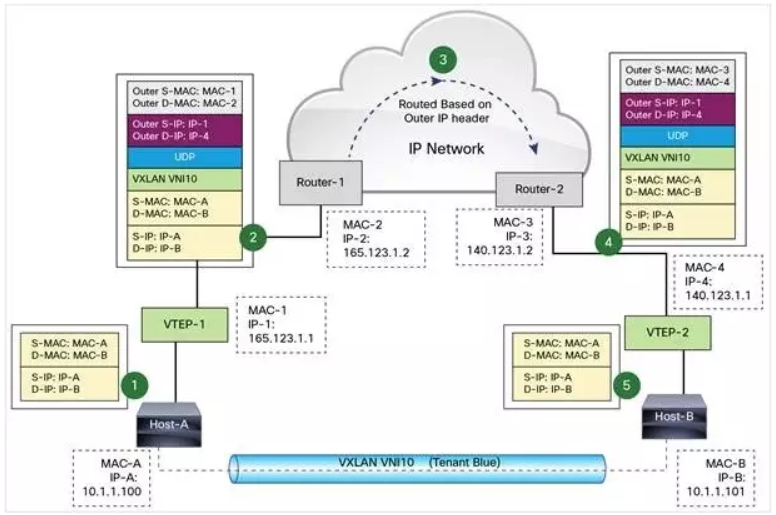
Host-A和Host-B可以看作是两个Host上的虚拟机和vxlan-id设备的结合体,VTEP-1和VTEP-2是Vxlan内核模,vxlan-id设备一端连接网桥,一端与内核模块的VTEP通信。
(1)虚拟机A向虚拟机B发送数据时,数据经过VTEP-1时,VTEP-1从自己的映射表中找到MAC-B对应的VTEP-2设备,以该设备的IP和MAC作为目标IP和MAC来封装,并且加上Vxlan头部。
(2)数据经过路由到达VTEP-2之后进行解包,依次去掉外层MAC头,外层 IP 头,UDP 头 和VXLAN头。VTEP-2 依据目标 MAC 地址将数据包发送给虚拟机B(这里其实是先转发到网桥上,然后网桥转发给对应的虚拟机)
两个主机间同vxlan id间通信图:
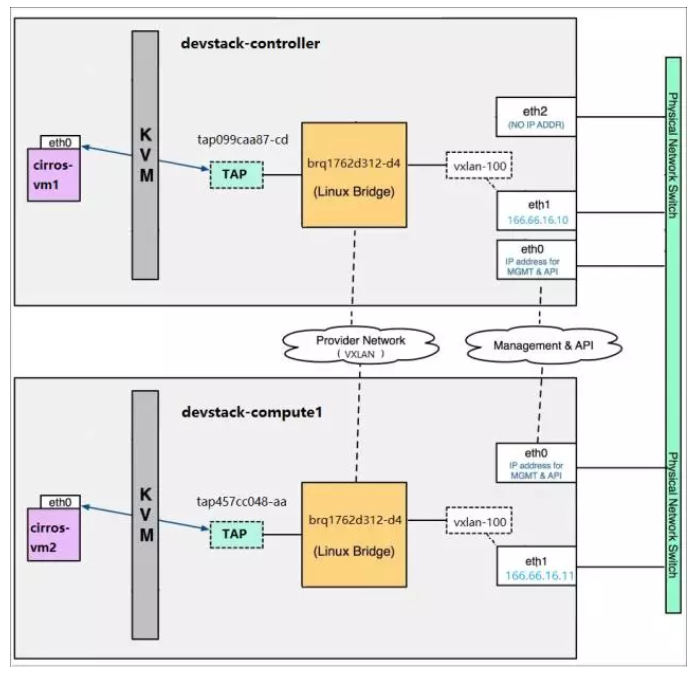
2.5 配置文件的配置参数值对应的意义解释
配置文件:/etc/neutron/plugins/ml2/ml2_conf.ini
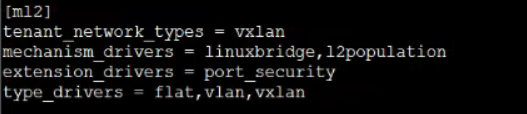
tenant_network_types:指明租户允许创建的网络类型为vxlan类型
mechanism_drivers:指明支持的策略驱动类型,比如除了linuxbridge,还可以是openvswitch,l2population是用来提升vxlan网络模式效率的,其实就是让各主机的VTEP能记录虚拟机的MAC对应的是哪个主机上的VTEP,这样就不用广播arp找虚拟机的MAC了。
type_drivers:指明支持的网络模式类型,用来在服务启动时加载对应的网络模式driver的代码。
配置文件:/etc/neutron/plugins/ml2/linuxbridge_agent.ini
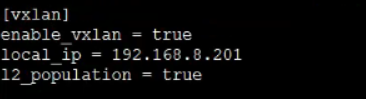
enable_vxlan:是否开启vxlan模式
local_ip:指明VTEP设备的IP
l2_population:是否开启该策略优化


这里是指明用eth2来作为provider network的网口
3 Neutron中的dhcp服务的工作原理
Neutron的dhcp服务是通过dhcp agent服务实现的,它部署在网络节点上,该服务使用了开源的dnsmasq来实现dhcp功能的,dnsmasq是一个提供DHCP和DNS服务的开源软件。
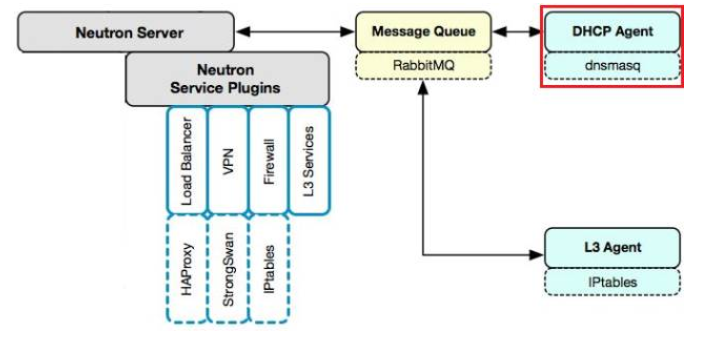
Dnsmasq和openstack里的network是一对一的关系,一个dnsmasq可以为一个network里的多个subnet提供服务。
查看我们系统里的dnsmasq服务:

红框中的--dhcp-hostsfile选项指定的是记录了已分配的虚拟机的IP和对应的MAC地址,其内容如下:

红框中的--interface选项指定的是提供DHCP服务的interface,用来监听虚拟机发来的请求。
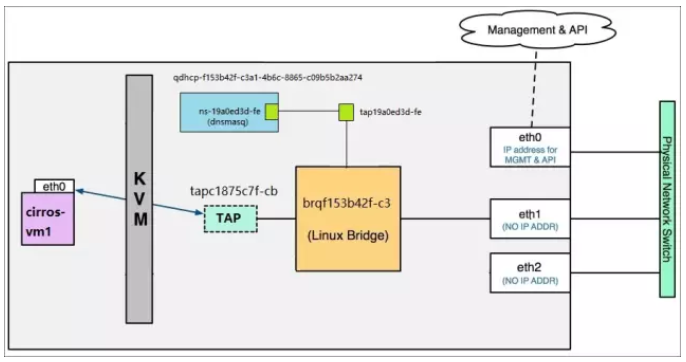
我们可以看到它的interface名是ns-de2b2a68-ac,使用ip addr好像没有看到有该设备的存在,那是因为该设备是在其它namespace里,不在宿主机的namespace里(root namespace),但网桥是在root namespace里,dhcp的设备在另外一个namespace里,该怎么连通呢,答案是使用veth-pair来联通,就是又一对接口,一个在dhcp的namespace,一个在root namespace,这样就连通起来了。
可以使用ip netns list命令查看所有namespaces(红框里的就是我们的dhcp的interface所在的namespace):
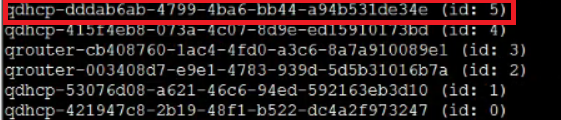
列出该namespace下的网络设备:
ip netns exec qdhcp-dddab6ab-4799-4ba6-bb44-a94b531de34e ip addr:
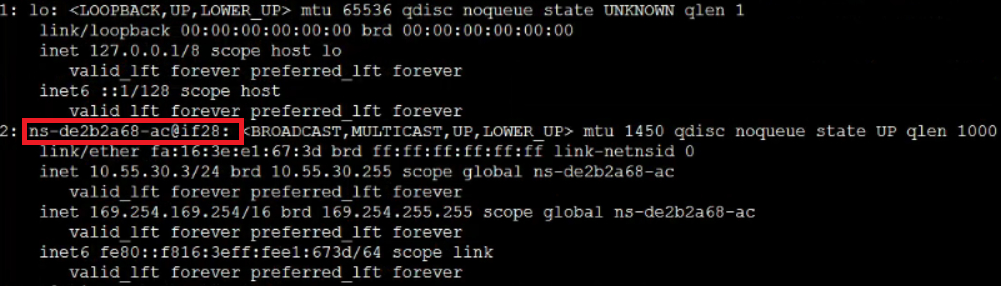
这里怎么看ns-de2b2a68-ac对应的另外一个veth是谁呢,可以这样看:
从上图的红框中我们看到该设备名后面还有@if28,这个28是该设备接口的index,我们还看倒这个设备的前面还有个”2:”,代表它的另外一个veth是设备接口index为2的,我们可以使用如下命令过滤获取:
ip link show | grep 28
![]()
可以知道对应的设备名是tapde2b2a68-ac
可以看到该设备另一端是连在网桥上的:

疑问:为啥需要这么麻烦搞多一个namespace呢?
答案是因为这样才能让不同network的子网可以重叠,而每个dhcp服务的namespace的独立的网络栈就不会受到影响,因为dhcp服务们有自己的route table,firewall rule,network interface device等。
一个虚拟机获取其IP和MAC的过程举例:
(1)当为虚拟机分配一个网卡时,会为它创建一个port,该port会包含该网卡的MAC和IP(记录在数据库里),这些信息也会同步到dnsmasq的host配置文件里
(2)当虚拟机启动时,会发出DHCPDISCOVER广播,网桥上的tapde2b2a68-ac收到后通过veth pair传到dhcp的namespace中的ns-de2b2a68-ac设备上
(3)Dhcp服务在ns-de2b2a68-ac设备上监听到了该请求数据包,然后查它的host文件并把对应的网络信息比如IP和MAC等返回回去,以DHCPOFFER 消息的形式返回回去
(4)虚拟机收到该DHCPOFFER 消息后回复DHCPREQUEST 表示接受此DHCPOFFER
(5)Dnsmasq收到DHCPREQUEST 后发送DHCPACK确认消息,分配过程结束
拓扑图:
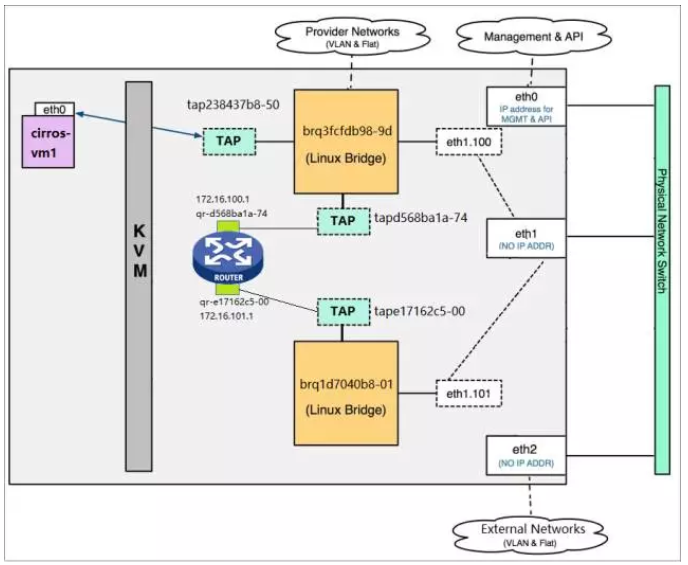
4 虚拟路由器原理
我们知道两个不同子网如果需要连通在二层上是不能实现的,那么就需要三层的介入,即数据包的路由,这个功能由路由器设备实现。可以使用物理的路由,也可以使用虚拟路由来实现。
虚拟路由的实现由L3 agent服务负责,它的实现原理是使用IPtables定义转发规则。
L3 agent服务运行在网络节点上。跟dhcp服务实现思想类似,为了让不同network的子网可以重叠,所以一个route也会创建一个namespace,然后创建一对veth-pair分别连接两个namespace来通信。因为一般是连接的两个子网,所以会有两个网关设备被创建在router的namespace里,所有会创建两对veth-pair,然后在router的namespace再设定路由规则,使得到达两个网关设备的数据包能够互相路由,这样数据包就能通了。
举例:
两个子网分别是172.16.100.0/24和172.16.101.0/24,网关分别是172.16.100.1和172.16.101.1
查看router里面的设备:
ip netns exec qrouter-1f9c082f-9d97-471f-a41b-afe90fd62c0d ip a
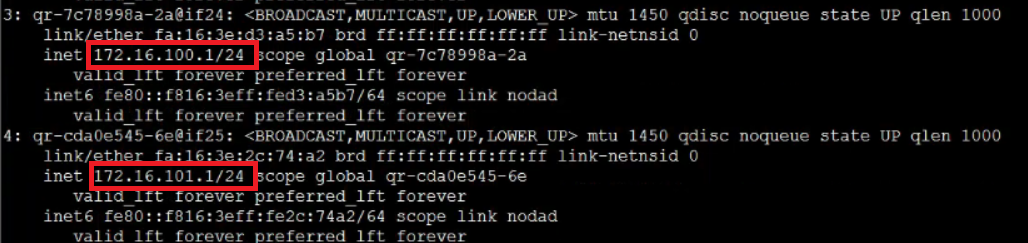
可以看到两个子网的网关IP都在这个network namespace里。
查看router里面的路由规则:
ip netns exec qrouter-1f9c082f-9d97-471f-a41b-afe90fd62c0d route -n

有上面两条红线标着的路由规则,这两个子网间的数据包就可相互路由了。
拓扑图:
因为浮动IP也是跟私有网络的子网的所连接的router有关的,这里扩展下浮动IP的工作原理:
浮动IP其实是依附于在router的namespace空间上的,浮动IP与私有网络的IP是一一对应的,假设虚拟机A的私有网络的IP是172.16.100.12,分配给它的浮动IP是192.168.100.236,则这两个IP在router的namespace里是有设定一些NAT转换规则的。如下:
ip netns exec qrouter-1f9c082f-9d97-471f-a41b-afe90fd62c0d iptables -t nat -S

可以看到这里设定了SNAT规则和DNAT规则,起到的作用就是:
(1)当router接收到从外网发来的包,如果目的地址是floating IP 192.168.100.236,将目的地址修改为虚拟机的的IP 172.16.100.12。这样外网的包就能送达到虚拟机了
(2)当虚拟机发送数据到外网,源地址 172.16.100.12 将被修改为 floating IP 192.168.100.236
所以浮动IP它并不是attach到虚拟机里去了,只是在虚拟路由器的namespace里做了一些NAT。
疑问:
(1)为什么还未指定路由器给交换机连接时,交换机设定的网关ip是不可用的
答案是这些元数据只是记录在数据库里,并没有真正配置到路由器上,待创建router后,这个网关地址就会配置到router的interface上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号