Ceph osd故障恢复
1 调高osd的日志等级

加上红框那一行就可以了
osd的日志路径:/var/log/ceph/ceph-osd.3.log
注意:加上了这一行后日志会刷很多,所以要特别注意日志容量的变化,以防把var目录写满了
2 缺少osdmap或者错误的osdmap


从osd日志中发现这两种错误都是属于osdmap不正常,可以从其它正常osd上拷贝osdmap到对应启动错误的osd上,假设不正常的osdmap序号是816,上图的是27601和671651
如以下图:

在一个正常osd上如osd.4上用find命令查找816的osdmap
接着用scp命令将对应的文件拷贝到对应的启动错误的osd对应的目录下
3 修复leveldb文件

这种错误属于缺少omap的sst文件,可尝试用leveldb自带的修复工具来修复
安装leveldb模块:
yum install epel-release -y
yum install python-pip python-devel gcc gcc-c++ -y
pip install --upgrade pip
pip install leveldb
注意:用pip命令时可能出现这样的超时错误,如果出现则重新执行pip命令即可
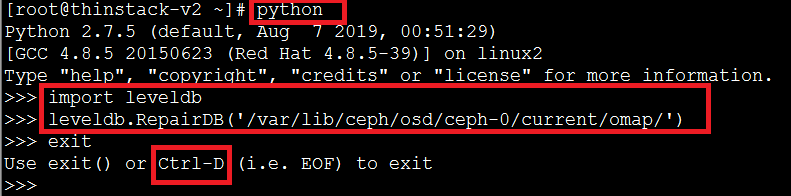
修复命令执行(假设是修复osd.0):
按下图红框所示执行:
修复完后可查看下修复的目录下是否有多出来的ldb后缀的文件,如果有则通过mv改名将后缀改为sst

mv /var/lib/ceph/osd/ceph-0/current/omap/000009.ldb /var/lib/ceph/osd/ceph-0/current/omap/000009.sst
改文件名后再重启该osd.0看看。
如果会报下面这样的错,则像第2点一样的步骤拷贝对应的osdmap过来然后重新启动
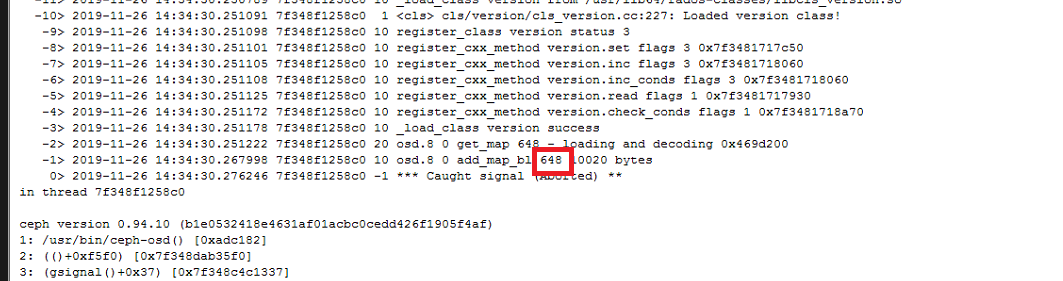
4 元数据校验错误

该错误是由于遍历加载pg的omap时出错导致osd起不来,如上图的报错是1.13这个pg报错导致的,如果只是单个pg有问题,在其它osd上有存储,那大可去除该pg,但我们遇到的在客户那里的情况是每个pg都有问题,那就感觉不是某个pg的问题了,是一个osd的共性问题,很有可能是leveldb的问题,但用leveldb修复却不能修复好,还未有解决方法
5 Inconsistent的pg
有这种pg出现在ceph -s命令的输出中应该可以看到有类似1 pgs inconsistent这样的描述,使用命令:
ceph health detail | grep inconsistent
找出inconsistent的pg,比如是pg 1.1
一般情况下使用以下命令即可修复不一致的pg:
ceph pg repair 1.1
执行完后等待一段时间可能会自动修复好
如果一段时间后也没修复好,则可以尝试再执行一遍,如果还没修复好则需要找出不一致的object来处理了
首先从osd的日志里找到inconsistent的obj

列出该object:

如果是3副本,则可以通过md5计算下哪个是不一致的,从而删除掉该object让其同步另外两个的即可,但这里的错误其实并不是object文件内容上的不一致,而是缺少object文件的一些文件属性,查看正常的:

异常的则没有红框里的属性且用object-ceph-tool查看时会报这样的错:

可以将正常的object拷贝覆盖异常的object:

注意:这里要用rsync来拷贝,这样文件属性也才能拷贝过去
6 pg down的处理
可先通过ceph pg query x.x来看某pg的情况,翻到最后面的recover项会有说明该pg为什么down且建议你如何恢复的说明
pg down的意思是含有最新数据pg的对应的osd没起来,最简单的做法就是将该osd拉起来,但如果该osd实在拉不起来且已经把它移出集群了,则可以告诉集群那个主pg的osd已经丢失了,让其它副本的pg作为主osd,比如osd.5已经起不来了则:
ceph osd lost 5 --yes-i-really-mean-it
当然这样也意味着主pg上有一些数据副pg是没有的,可能会有一些数据丢失,如果想要保险,则可以通过object-ceph-tool工具将pg从挂掉的那个osd上先导出来,然后再通过该工具导入到正常的有该副本的osd上即可
注意:如果确实想把某osd标记为lost,则应该那个osd从osd crush中remove出去才有效
7 Journal问题

由日志可比较明显的看出是在加载journal数据的时候crash了,可以通过给osd替换journal的方式来恢复osd,但这样做也就意味到需要丢弃掉journal里的数据
恢复方法(以osd.0为例):
(1)停止服务
/etc/init.d/ceph stop osd.0
(2)替换journal
# 这行--flush-journal很有可能报错,因为本身就是因journal而crash的,报错可以不用管它,继续下一条命令
ceph-osd -i 0 --flush-journal
rm -rf /var/lib/ceph/osd/ceph-0/journal
touch /var/lib/ceph/osd/ceph-0/journal
ceph-osd -i 0 --mkjournal
(3)启动服务
/etc/init.d/ceph start osd.0
8 终极恢复方法
假设很不幸,你的osd挂了很多,横跨了多个故障域,超出了你的副本数设置,通过数据均衡方式已经恢复不了你的数据了,则可以尝试使用这种方法,它就算你的全部osd挂掉也能恢复,但前提是你的osd能够挂载并能访问到osd的current目录里面的object数据文件,且存储引擎用的是filestore
该方法的原理是通过将一个rbd的所有object收集起来重新拼接成一个raw格式的文件,然后可将该文件导入到虚拟存储中重新成为一个rbd
脚本文件下载地址:https://github.com/luohaixiannz/ceph-recovery-master
情景假设:
假设虚拟存储中一共有3个osd,osd.0、osd.1和osd.2
使用方法:
(1)找一个空间大一点的目录,需要比ceph df中显示的容量要大

比如这里显示的是103M,则我们选的目录的存放的空间应该大于这个容量的2倍以上,因为我们拼接后输出的文件也存放到该目录下
解压脚本文件到该目录
(2)创建目录
cd ceph-recovery-master
mkdir outputs
mkdir osds
cd osds
mkdir osd0 osd1 osd2
cd ..
通过scp的方式将3个osd的current目录拷贝到对应的刚刚创建的osd目录下,比如osd0的(其它节点上的则用scp):
cp -r /var/lib/ceph/osd/ceph-0/current ceph-recovery-master/osds/osd0/
(3)运行脚本
a. 收集osd里的object数据
执行命令:
./collect_files.sh osds
b. 查找要恢复的rbd
找虚拟机的系统盘可按如下图的命令找对应关系:

如果是找数据盘的则按如下图的命令找对应关系:

如果是镜像的则:

上面列举了我们知道名字如何找到对应的uuid,这个uuid是用来下一步恢复rbd时使用
c. 恢复rbd为一个raw的文件
比如我们想恢复testooo这个虚拟机的系统盘,则按上图那些操作我们可以得知它对应的uuid是a4f0234a-e900-4d3c-a684-4d9fe4d1abc3
则执行如下命令:

获取到这个虚拟机系统盘对应的rbd的uuid
执行命令恢复这个rbd为一个raw格式的文件:

这里解释下该命令传递的参数含义:
(1)那个disk.id那一串就是我们上面找的rbd对应的uuid
(2)参数2表示2M,以M为单位,代表的含义是这个rbd的object是定义为2M的,这个可以通过rbd info pool_name/rbdname里可以看到
(3)参数5表示该磁盘的大小,以G为单位
命令执行完成后,脚本会将拼接后的raw文件放在outputs目录下:

d. 验证rbd是否正常
如果你当前的ceph环境是异常的,则很明显你不能用当前ceph环境来验证,可以通过其它ceph环境来验证该raw文件是否是正常的。
ceph环境下的验证方法,先导入该raw文件为一个rbd

查看是否导入进去了:

然后新创建一个虚拟机,然后找到它的rbd名字,然后通过rbd rename的方式交换两个rbd,然后开启这个虚拟机看是否正常即可
数据盘的方式也是用替换rbd的方式来验证的
上面说的是用ceph环境来验证到处的rbd是否是正常的,如果当前ceph不可用则可用本地存储来验证,本地存储使用的磁盘格式是qcow2的,所以我们先要将raw格式的磁盘转换为qcow2格式的:

然后新建一个本地虚拟机,用转换出来的qcow2文件替换掉它的qcow2文件,然后开启虚拟机检查下磁盘是否是正常的
6 pg down的处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号