


2022 flag 150篇文章 - 63 - ES - elastic search
elastic search 是一个分布式搜索和数据分析引擎,基于lucene构建;
由一个或多个具有相同cluster.name的节点组成集群;分片:ES可以把一个大的索引分成多个分片;副本:索引的副本,提高容错性;
集群
- 索引
- 分片
- 副本
ES 默认会为每个索引创建5个分片;
- 集群
- 节点
- 索引 (与mysql的数据库实例相当,索引只是一个逻辑命名空间,指向一个或多个分片)
- 文档类型(相当于数据库中表的概念)
- 文档 (相当于数据库表的row)
- mapping
- 分片
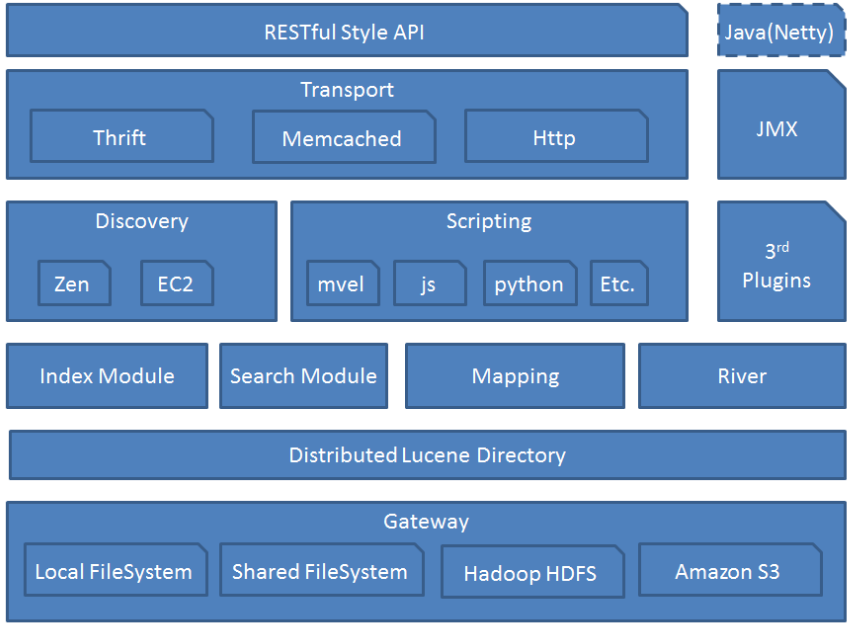
ES查询快的原因: 集群、分片、副本
在索引创建的时候, 确定主分片;路由算法:shard = hash(routing) % number_of_primary_shards
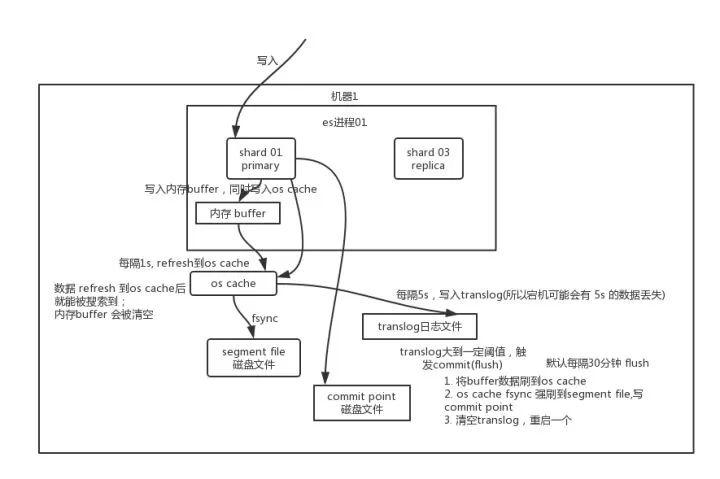
数据写入过程
数据写入到主分片, 然后同步到全部副本分片;
数据查询过程
1.查询请求发送到协调节点,协调节点把请求转发到全部分片;
2. 全部分片把查询结果(包含doc_id,排序值)返回到协调节点;协调节点合并、排序、分页;
3. 协调节点根据doc_id从各个分片获取实际数据并返回给客户端;
数据更新或删除?
删除:在提交的时候生成一个.del文件,把doc文档的状态更新为删除;
更新:doc文档的状态更新为删除; 再写新的doc; buffer每refresh一次,生成一个segment file. 要定期merge
ES的查询有2种;一种是query(计算每个文档得分、并排序), 一种是filter(仅过滤符合条件的数据并缓存);
bool查询 : must ,出现于查询结果中;filter,必须满足才出现;must_not:满足条件的数据不出现;
查询:指定索引 , 条件查询: term(精确查询)、range(范围查询),terms(多值匹配),match(分词查询)、ids(); exits(包含某个字段)、missing(不包含)
"ids": {
"type": "news",
"values": "2101"
}
分页滚动查询 scroll
"scroll":"1m",
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoAwAAAAAAADShFmpBMjJJY2F2U242RFU5UlAzUzA4YXZTbjZEVTlSUDNTMDgxZw=="
sort , 排序
"sort":[
{"user_id":{"order":"asc"}},
{"salary":{"order":"desc"}}
]
aggs,聚合
max,min, avg, sum, stats, terms(分组查询), cardina
size设置为0,返回聚合结果。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现