最短路径算法
最短路问题
最短路问题
在带权图中,每条边都有一个权值,就是边的长度。路径的长度等于经过所有边权之和,求最小值。

如上图,从 \(1\) 到 \(4\) 的最短路径为 1->2->3->4,长度为 5。
对于无权图或者边权相同的图,我们显然可以使用 bfs 求解。
但是对于带权图,就不能通过 bfs 求得了。
Floyd 多源最短路算法
概述
所谓多源则是它可以求出以每个点为起点到其它每个点的最短路。
有一种特殊情况是求不出最短路的,就是存在负环。每次经过这段路之后最短路长度就会减少,算法便会得到错误的答案,一些算法甚至会有死循环。但是 Floyd 无法判断是否出现这种情况,所以就只能在没有负环的情况下使用。
Floyd 算法是一种利用动态规划的思想、计算给定的带权图中任意两个顶点之间最短路径的算法。无权图可以直接把边权看作 \(1\) 。
Floyd 写法最为简单。但是一定要切记中间点 \(k\) 的枚举一定要放在最外层。
int g[maxn][maxn];
for (int k = 1;k <= n;k++) {
for (int i = 1;i <= n;i++) {
for (int j = 1;j <= n;j++) {
g[i][j] = min(g[i][k] + g[k][j], g[i][j]);
}
}
}
时间复杂度为 \(\mathcal{O}(n^3)\)。
代码实现
#include <iostream>
#include <cmath>
#include <cstring>
using namespace std;
const int N = 101;
int g[N][N];
void Floyd(int n) {
for (int k = 1;k <= n;k++) {
for (int i = 1;i <= n;i++) {
for (int j = 1;j <= n;j++) {
g[i][j] = min(g[i][j], g[i][k] + g[k][j]);
}
}
}
}
int main() {
memset(g, 0x3f, sizeof(g));
for (int i = 0; i < N; i++) {
g[i][i] = 0;
}
int n, m;
int u, v, w;
cin >> n >> m;
for (int i = 0; i < m; i++) {
cin >> u >> v >> w;
g[u][v] = g[v][u] = w;
}
Floyd(n);
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << g[i][j] << " ";
}
cout << endl;
}
return 0;
}
例题:城市
题目描述
一个国家中有 \(n\) 个城市,\(m\) 条道路,每条道路都是单向的。国王想知道以每座城市为起点可以到达那些城市?
输入格式
第一行输入 \(n(1\le n\le 100),m(1\le m\le 1000)\),表示城市和道路数量。
接下来 \(m\) 行,每行两个整数 \(u,v(1\le u,v\le n)\) 表示有一条从 \(u\) 城市到 \(v\) 城市的一条道路。
输出格式
输出 \(n\) 行,每行 \(n\) 个数,用空格隔开。
第 \(i\) 行第 \(j\) 个数表示城市 \(i\) 是否可以到达城市 \(j\)。如果可以输出 1,否则输出 0。
样例输入
3 2
1 2
1 3
样例输出
1 1 1
0 1 0
0 0 1
解析
可以直接套用 floyd 求解。
代码
#include <iostream>
using namespace std;
int g[105][105];
int main() {
int n, m, u, v;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
g[i][i] = 1;
}
for (int i = 0; i < m; i++) {
cin >> u >> v;
g[u][v] = 1;
}
for (int k = 1;k <= n;k++) {
for (int i = 1;i <= n;i++) {
for (int j = 1;j <= n;j++) {
if (!g[i][j]) {
if (g[i][k] && g[k][j]) {
g[i][j] = true;
}
}
}
}
}
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
cout << g[i][j] << " ";
}
cout << endl;
}
return 0;
}
朴素迪杰斯特拉最短路算法
单源最短路问题是指:从源点 \(s\) 到图中其余各顶点的最短路径。
算法流程
我们定义带权图 \(G\) 所有顶点集合为 \(V\),接着我们再定义已确定从源点出发的最短路径的顶点集合为 \(U\)。初始集合 \(U\) 为空,记从源点 \(s\) 出发到每个顶点 \(v\) 的距离为 \(d_v\),初始 \(d_s=0\),接着执行如下操作:
- 从 \(V-U\) 中找出一个距离源点最近的顶点 \(v\),将 \(v\) 加入集合 \(U\)。
- 并用 \(d_v\) 和顶点 \(v\) 连出来的边来更新和 \(v\) 相邻的、不在集合 \(U\) 中的顶点 \(d\),这一步成为松弛操作。
- 重复 1 和 2,直到 \(V=U\) 或找不到一个从 \(s\) 出发有路径到达的顶点,算法结束。
迪杰斯特拉算法的时间复杂度为 \(\mathcal{O}(V^2)\),其中 \(V\) 表示顶点的个数。
图片演示
我们用一个例子来说明这个算法。
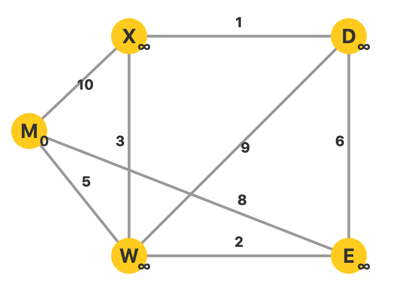
初始每个顶点的 \(d\) 设置为无穷大 \(\inf\),源点 \(M\) 的 \(d_M\) 设置为 \(0\)。当前 \(U=\emptyset\),\(V-U\) 中的 \(d\) 最小的顶点为 \(M\)。从顶点 \(M\) 出发,更新相邻点的 \(d\)。
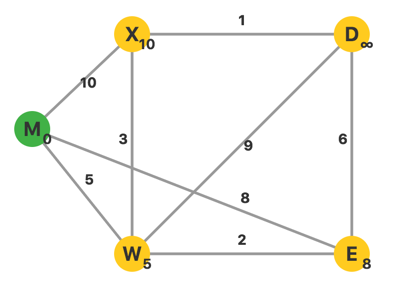
更新完毕,此时 \(U=\{M\}\),\(V-U\) 中 \(d\) 最小的顶点是 \(W\)。从 \(W\) 出发,更新相邻点的 \(d\)。
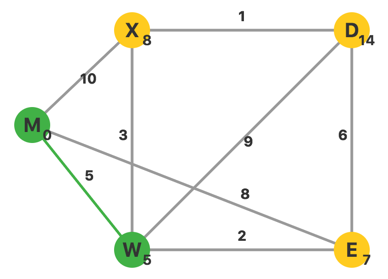
更新完毕,此时 \(U=\{M,W\}\),\(V-U\) 中 \(d\) 最小的顶点是 \(E\)。从 \(E\) 出发,更新相邻顶点的 \(d\)。
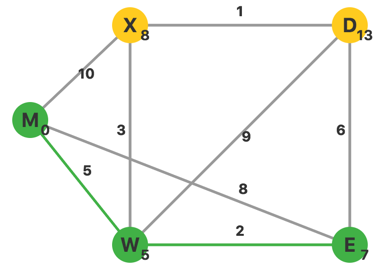
更新完毕,此时 \(U=\{M,W,E\}\),\(V-U\) 中 \(d\) 最小的顶点是 \(X\)。从 \(X\) 出发,更新相邻顶点的 \(d\)。
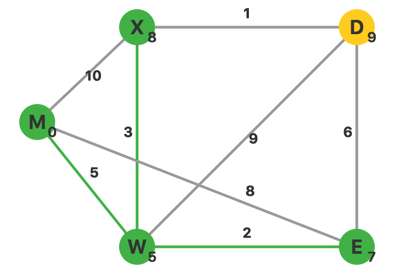
更新完毕,此时 \(U=\{M,W,E,X\}\),\(V-U\) 中 \(d\) 最小的顶点是 \(D\)。从 \(D\) 出发,没有其他不在集合 \(U\) 中的顶点。
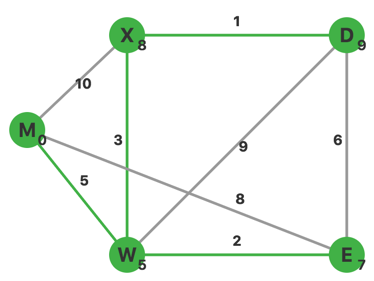
此时 \(U=V\),算法结束。
示例代码
for (int i = 1;i <= n;i++) {
int mind = inf;
int v = 0;
for (int j = 1;j <= n;j++) {
if (d[j] < mind && !vis[j]) {
mind = d[j];
v = j;
}
}
if (mind == inf) {
break;
}
vis[v] = true;
for (int j = 0;j < g[v].size();j++) {
d[g[v][j].v] = min(d[g[v][j].v], d[v] + g[v][j].w);
}
}
代码实现
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 1001;
const int inf = 0x3f3f3f3f;
struct node {
int v, w;
node() {
}
node(int vv, int ww) {
v = vv;
w = ww;
}
};
vector<node> g[N];
int n, m, s;
int d[N];
bool vis[N];
int main() {
cin >> n >> m >> s;
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
g[u].push_back(node(v, w));
g[v].push_back(node(u, w));
}
memset(d, 0x3f, sizeof(d));
d[s] = 0;
for (int i = 1;i <= n;i++) {
int mind = inf;
int v = 0;
for (int j = 1;j <= n;j++) {
if (!vis[j] && d[j] < mind) {
mind = d[j];
v = j;
}
}
if (mind == inf) {
break;
}
vis[v] = true;
for (int j = 0;j < g[v].size();j++) {
d[g[v][j].v] = min(d[g[v][j].v], d[v] + g[v][j].w);
}
}
for (int i = 1; i <= n; i++) {
cout << d[i] << " ";
}
return 0;
}
堆优化迪杰斯特拉算法
在朴素算法中,每次使用 \(\mathcal{O}(n)\) 查询距离当前点最近的点过于消耗时间,我们可以使用堆优化来直接获得最近的点。
堆优化
如果暴力枚举的话,时间复杂度为 \(\mathcal{O}(V^2)\)。
如果考虑使用一个 set 来维护点的集合,这样时间复杂度就优化到了\(\mathcal{O}((V+E)\log V)\)。
示例代码
set<pair<int, int> > min_heap;
min_heap.insert(make_pair(0, s));
while (min_heap.size()) {
int mind = min_heap.begin()->first;
int v = min_heap.begin()->second;
min_heap.erase(min_heap.begin());
for (int i = 0;i < g[v].size();i++) {
if (d[g[v][i].v] > d[v] + g[v][i].w) {
min_heap.erase(make_pair(d[g[v][i].v], g[v][i].v));
d[g[v][i].v] = d[v] + g[v][i].w;
min_heap.insert(make_pair(d[g[v][i].v], g[v][i].v));
}
}
}
代码实现
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
#include <set>
using namespace std;
const int N = 100001;
const int inf = 0x3f3f3f3f;
struct node {
int v, w;
node() {
}
node(int vv, int ww) {
v = vv;
w = ww;
}
};
vector<node> g[N];
int n, m, s;
int d[N];
set<pair<int, int> > min_heap;
int main() {
cin >> n >> m >> s;
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
g[u].push_back(node(v, w));
g[v].push_back(node(u, w));
}
memset(d, 0x3f, sizeof(d));
d[s] = 0;
min_heap.insert(make_pair(0, s));
while (min_heap.size()) {
int mind = min_heap.begin() -> first;
int v = min_heap.begin() -> second;
min_heap.erase(min_heap.begin());
for (int i = 0;i < g[v].size();i++) {
if (d[g[v][i].v] > d[v] + g[v][i].w) {
min_heap.erase(make_pair(d[g[v][i].v], g[v][i].v));
d[g[v][i].v] = d[v] + g[v][i].w;
min_heap.insert(make_pair(d[g[v][i].v], g[v][i].v));
}
}
}
for (int i = 1; i <= n; i++) {
cout << d[i] << " ";
}
return 0;
}
例题:旅行
题目描述
一个国家中有 \(n\) 个城市,\(m\) 个道路。小明位于第 \(s\) 个城市,他想知道其他城市距离自己所在城市的最短距离是多少。
输入格式
第一行输入一个整数 \(n(1\le n\le 1\times 10^5),m(0\le m\le 1\times 10^6),s(1\le s\le n)\),分别表示城市个数、道路数量以及起点城市。
接下来 \(m\) 行,每行三个不同的正整数 \(u,v,w(1\le u,v\le n,1\le w\le 1000)\),表示 \(u\) 城市到 \(v\) 城市之间有一条长度为 \(w\) 的道路。
输出格式
输出一行,包含 \(n\) 个数字,表示以 \(s\) 为起点到第 \(i\) 个城市的最短距离。如果不可到达输出 \(-1\)。
解析
可以直接使用堆优化迪杰斯特拉来解决。
参考代码
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
#include <set>
using namespace std;
const int N = 100001;
const int inf = 0x3f3f3f3f;
struct node {
int v, w;
node() {
}
node(int vv, int ww) {
v = vv;
w = ww;
}
};
vector<node> g[N];
int n, m, s;
int d[N];
set<pair<int, int> > min_heap;
bool in_queue[N];
int main() {
cin >> n >> m >> s;
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
g[u].push_back(node(v, w));
}
memset(d, 0x3f, sizeof(d));
d[s] = 0;
min_heap.insert(make_pair(0, s));
while (!min_heap.empty()) {
int mind = min_heap.begin() -> first;
int v = min_heap.begin() -> second;
min_heap.erase(min_heap.begin());
for (int i = 0;i < g[v].size();i++) {
if (d[g[v][i].v] > d[v] + g[v][i].w) {
min_heap.erase(make_pair(d[g[v][i].v], g[v][i].v));
d[g[v][i].v] = d[v] + g[v][i].w;
min_heap.insert(make_pair(d[g[v][i].v], g[v][i].v));
}
}
}
for (int i = 1;i <= n;i++) {
if (d[i] < inf) cout << d[i] << ' ';
else cout << -1 << ' ';
}
cout << endl;
return 0;
}
SPFA 算法
算法内容
在该算法中,需要使用一个队列来保存即将拓展的顶点列表,并使用 \(\text{in\_queue}_i\) 来表示顶点 \(i\) 是否在队列中。
- 初始队列仅有源点,且 \(d_s=0\)。
- 取出队顶元素 \(u\),扫描从 \(u\) 出发的每一条边,设每条边的另一端为 \(v\),边 \(u,v\) 的权值为 \(w\),若 \(d_u+w<d_v\),则
- 将 \(d_v\) 修改为 \(d_u+w\)。
- 若 \(v\) 不在队列中,则将 \(v\) 入队。
- 重复 2 直到队列为空。
算法效率
空间复杂度很显然为 \(\mathcal{O}(V)\)。如果平均入队次数为 \(k\),则 SPFA 的时间复杂度为 \(\mathcal{O}(kE)\)。
对于一般随机稀疏图,\(k\) 不超过 \(4\)。
示例代码
bool in_queue[maxn];
int d[maxn];
queue<int> q;
void spfa(int s) {
memset(in_queue, 0, sizeof(in_queue));
memset(d, 0x3f, sizeof(d));
d[s] = 0;
in_queue[s] = true;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
in_queue[v] = false;
for (int i = 0;i < g[v].size();i++) {
if (d[g[v][i].v] > d[v] + g[v][i].w) {
d[g[v][i].v] = d[v] + g[v][i].w;
if (!in_queue[g[v][i].v]) {
q.push(g[v][i].v);
in_queue[g[v][i].v] = true;
}
}
}
}
}
代码实现
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 100001;
const int inf = 0x3f3f3f3f;
struct node {
int v, w;
node() {
}
node(int vv, int ww) {
v = vv;
w = ww;
}
};
vector<node> g[N];
int n, m, s;
int d[N];
bool in_queue[N];
queue<int> q;
int main() {
cin >> n >> m >> s;
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
g[u].push_back(node(v, w));
g[v].push_back(node(u, w));
}
memset(d, 0x3f, sizeof(d));
d[s] = 0;
in_queue[s] = true;
q.push(s);
while (!q.empty()) {
int v = q.front();
q.pop();
in_queue[v] = false;
for (int i = 0;i < g[v].size();i++) {
int x = g[v][i].v;
if (d[x] > d[v] + g[v][i].w) {
d[x] = d[v] + g[v][i].w;
if (!in_queue[x]) {
q.push(x);
in_queue[x] = true;
}
}
}
}
for (int i = 1; i <= n; i++) {
cout << d[i] << " ";
}
return 0;
}
SPFA 判负环
我们可以在入队时,记录每个顶点入队次数 \(\text{cnt}_i\)。如果一个顶点入队次数大于 \(n\),那么就出现了负环。
代码实现
#include <iostream>
#include <cstring>
#include <vector>
#include <algorithm>
#include <queue>
using namespace std;
const int N = 100001;
const int inf = 0x3f3f3f3f;
struct node {
int v, w;
node() {
}
node(int vv, int ww) {
v = vv;
w = ww;
}
};
vector<node> g[N];
int n, m, s;
int d[N], cnt[N];
bool in_queue[N];
queue<int> q;
bool spfa(int s) {
memset(d, 0x3f, sizeof(d));
d[s] = 0;
in_queue[s] = true;
q.push(s);
cnt[s] ++;
while (!q.empty()) {
int v = q.front();
q.pop();
in_queue[v] = false;
for (int i = 0; i < g[v].size(); i++) {
int x = g[v][i].v;
if (d[x] > d[v] + g[v][i].w) {
d[x] = d[v] + g[v][i].w;
if (!in_queue[x]) {
q.push(x);
in_queue[x] = true;
cnt[x] ++;
if (cnt[x] > n) {
return true;
}
}
}
}
}
return false;
}
int main() {
cin >> n >> m >> s;
for (int i = 0; i < m; i++) {
int u, v, w;
cin >> u >> v >> w;
g[u].push_back(node(v, w));
}
if (spfa(s)) {
cout << "YES" << endl;
} else {
cout << "NO" << endl;
}
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类