一文深入理解协同过滤
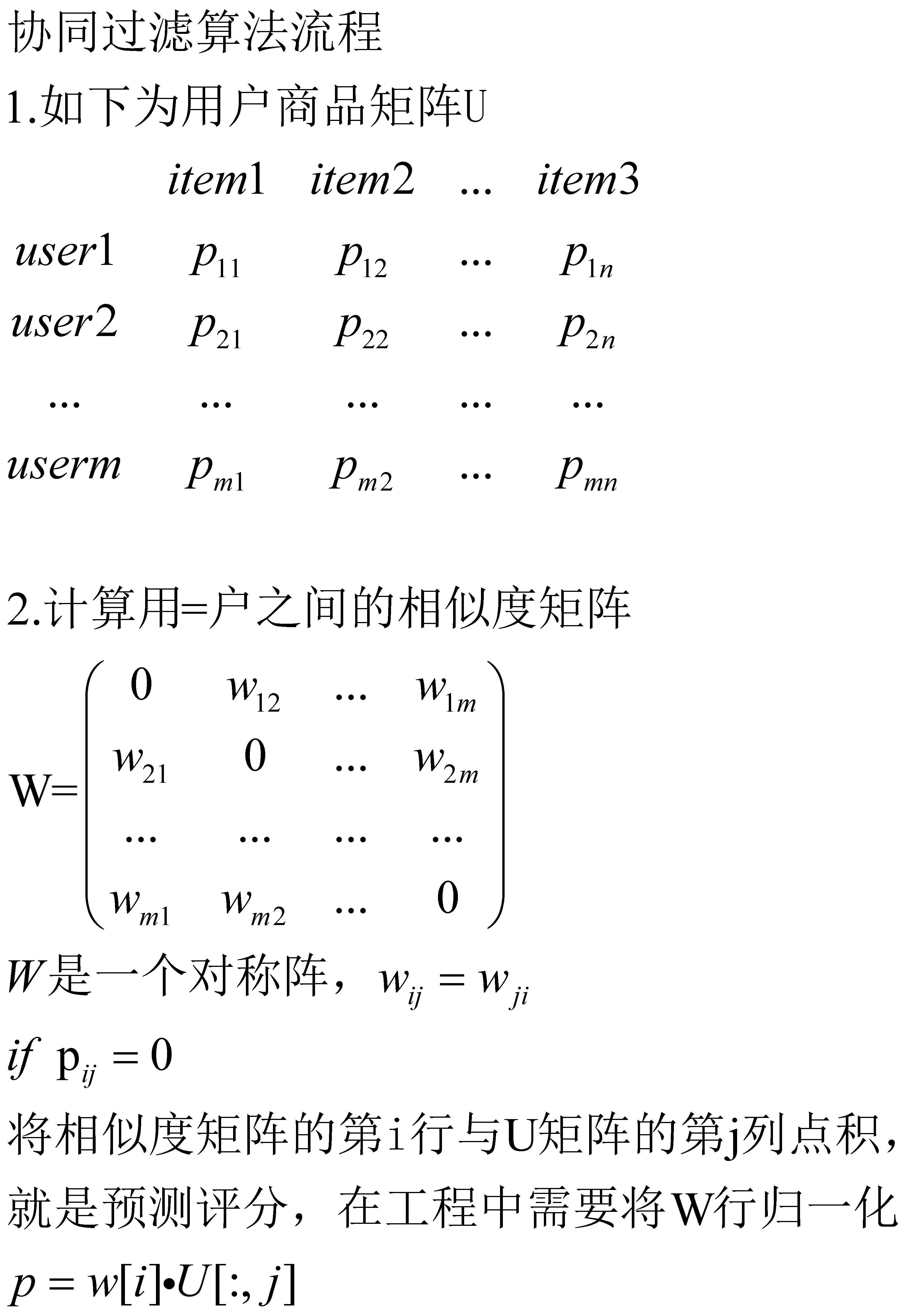
# coding:UTF-8
'''
Date:20180624
@author: luogan
'''
import numpy as np
import pandas
from numpy import mat,eye
from numpy import linalg
def fetch_data():
dat=mat([[4., 3., 0., 5., 0.],
[5., 0., 4., 4., 0.],
[4., 0., 5., 0., 3.],
[2., 3., 0., 1., 0.],
[0., 4., 2., 0., 5.]])
return dat
def cos_sim(x, y):
'''余弦相似性
input: x(mat):以行向量的形式存储,可以是用户或者商品
y(mat):以行向量的形式存储,可以是用户或者商品
output: x和y之间的余弦相似度
'''
numerator = x * y.T # x和y之间的额内积
denominator = np.sqrt(x * x.T) * np.sqrt(y * y.T)
return (numerator / denominator)[0, 0]
def similarity(data):
'''计算矩阵中任意两行之间的相似度
input: data(mat):任意矩阵
output: w(mat):任意两行之间的相似度
'''
m = np.shape(data)[0] # 用户的数量
# 初始化相似度矩阵
w = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
if j != i:
# 计算任意两行之间的相似度
w[i, j] = cos_sim(data[i, ], data[j, ])
w[j, i] = w[i, j]
else:
w[i, j] = 0
return w
def user_based_recommend(data, w, user):
'''基于用户相似性为用户user推荐商品
input: data(mat):用户商品矩阵
w(mat):用户之间的相似度
user(int):用户的编号
output: predict(list):推荐列表
'''
m, n = np.shape(data)
interaction = data[user, ] # 用户user与商品信息
# 1、找到用户user没有互动过的商品
not_inter = []
for i in range(n):
if interaction[0, i] == 0: # 没有互动的商品
not_inter.append(i)
# 2、对没有互动过的商品进行预测
#print('not_inter=',not_inter)
predict={}
dd=np.array(data)
ww=np.array(w)
if len(not_inter)>0:
for i in not_inter:
#print('ww[:,user]=',ww[:,user])
#print('dd[:,i].T',dd[:,i].T)
# predict[i]=ww[:,user]@dd[:,i].T
predict[i]=ww[user]@dd[:,i].T
#print(predict)
return predict
def top_k(predict, k):
'''为用户推荐前k个商品
input: predict(list):排好序的商品列表
k(int):推荐的商品个数
output: top_recom(list):top_k个商品
'''
pp=pandas.Series(predict)
pp1=pp.sort_values(ascending=False)
#top_recom = []
len_result = len(predict)
if k>=len_result:
return pp1.iloc[:k]
else:
return pp1
#
#def svd(data):
# u,sigma,vt=linalg.svd(data)
#
# sig3=mat(eye(3)*sigma[:3])
#
# fea_mat=data.T*u[:,:3]*sig3.I
#
# return fea_mat
def normalize(w):
w=np.array(w)
#print(w)
dim=len(w)
ww=[]
for i in range(dim):
d=w[i]
m=[]
for k in range(len(d)):
m.append(abs(d[k]))
ssm=sum(m)
#print('ssm=',ssm)
for j in range(len(m)):
m[j]=d[j]/ssm
ww.append(m)
return mat(ww)
data = fetch_data()
print('仅仅采用协同过滤算法')
print('only use collaborative')
w_initial=similarity(data)
# 3、利用用户之间的相似性进行推荐
#print ("------------ 3. predict ------------" )
predict = user_based_recommend(data, w_initial, 0)
# 4、进行Top-K推荐
#print ("------------ 4. top_k recommendation ------------")
top_recom = top_k(predict, 1)
print ('top_recom=',top_recom)
print('采用协同过滤算法+相似度矩阵的归一化')
print(' use collaborative and normalize')
w_initial=similarity(data)
w_initial_normal=normalize(w_initial)
predict = user_based_recommend(data, w_initial_normal, 0)
top_recom = top_k(predict, 1)
print ('top_recom=',top_recom)
当我们仅仅采用协同过滤,不对结果采用任何处理时,第一个用户的第三的商品的推荐,结果是5.1,对比其他三种算法,可以看出这个结果是有问题的,其他三种算法的推荐值都在2左右.
结论:
在用协同过滤做推荐时,必须采用归一化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号