

启动hiveserver2:
hiveserver2 --hiveconf hive.execution.engine=spark spark.master=yarn
使用beeline连接hiveserver2:
beeline -u jdbc:hive2://hadoop000:10000 -n spark
注意:每个beeline对应一个SparkContext,而在Spark thriftserver中,多个beeline共享一个SparkContext
可以通过YARN监控页面观察到:分别执行了两个beeline
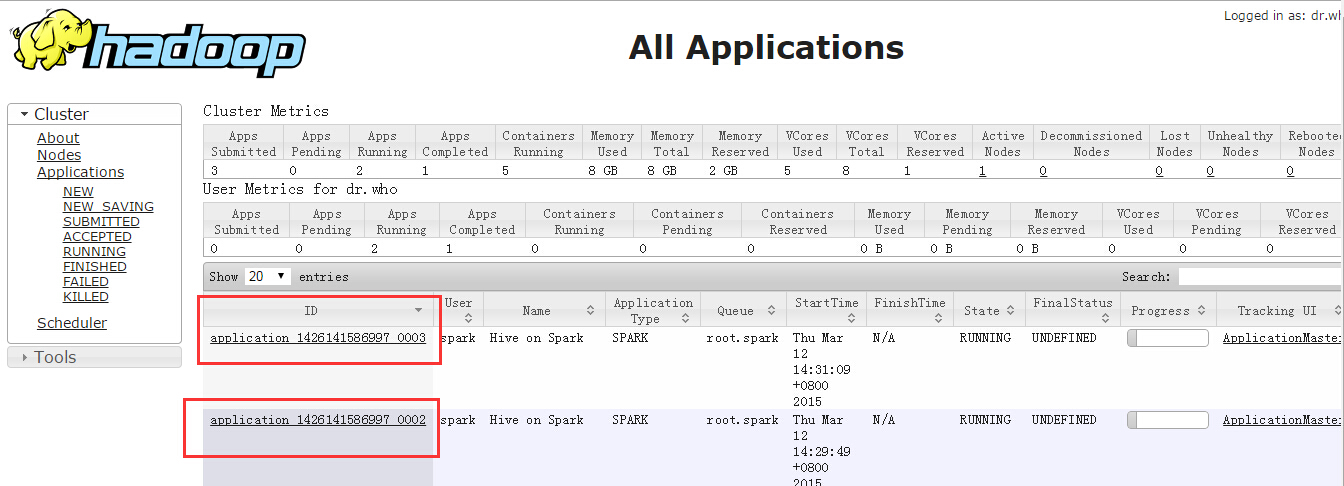
在刚启动hive时,执行第一个sql语句会比较慢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号