

package org.apache.spark.sql.sources import org.apache.spark.SparkContext import java.sql.{ResultSet, DriverManager} import org.apache.spark.rdd.JdbcRDD /** * @author luogankun * Created by spark on 14-12-25. */ object JdbcTest extends App{ val sc = new SparkContext("local[2]", "demo") def getConnection() = { Class.forName("com.mysql.jdbc.Driver").newInstance() DriverManager.getConnection("jdbc:mysql://hadoop000:3306/hive", "root", "root") } def flatValue(result: ResultSet) = { (result.getInt("TBL_ID"), result.getString("TBL_NAME")) } //select * from TBLS WHERE TBL_ID>=1 AND TBL_ID<=10 val data = new JdbcRDD( sc, getConnection, "select * from TBLS where TBL_ID >= ? and TBL_ID <= ?", 1, 10, 2, flatValue ) println(data.collect().toList) sc.stop }
执行报错:

查看JdbcRDD代码发现,sql语句一定要带上2个条件:
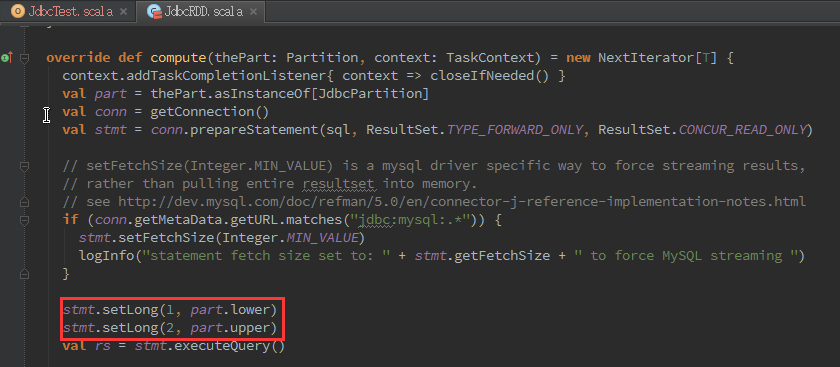
这个使用起来不太方便,最近需要找时间将JdbcRDD优化下,以便后续更方便的在jdbc external data source中能使用JdbcRDD。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号