深度学习基础
1 线性回归(linear regression)
线性回归问题可以使用最小二乘法进行拟合,该方法可以求得优化方程的一个全局最优解,但当数据量很大时需要很大计算量。
梯度下降法不对方程进行约束,通过迭代方式对参数进行优化,该优化解可能是一个局部最优解。
虽然梯度下降法可能得到一个局部最优解, 但对于深度学习训练来说,我们可以通过改进初始化参数并观察测试集效果选择一个合理的最优解即可实现目标。
1)样本(sample)
对于一组观测数据集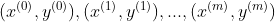 ,其中,
,其中,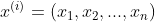 为输入特征,
为输入特征,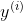 为对应输入特征下的真实输出值。
为对应输入特征下的真实输出值。
2)假设函数(hypothesis function)
对于以上样本数据,首先需要定义一个假设函数,该函数描述了样本输入特征值与输出变量之间的函数关系,只是参数未知,如下:
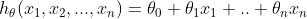 ,
,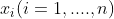 为单个样本的多维特征值,
为单个样本的多维特征值,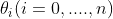 为该假设模型的参数。
为该假设模型的参数。
3)损失函数(loss function)
基于样本数据和假设函数可以定义一个损失函数 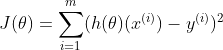 ,当预测结果与真实结果越接近时,该函数的值越接近0。
,当预测结果与真实结果越接近时,该函数的值越接近0。
该函数中的未知量仅有,因此问题转化为求解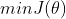 下的。
下的。
4)梯度下降法
要求得损失函数的最小值对应的参数,可以使用梯度下降法求得:
首先对未知量都初始化为0,并设定一个迭代步长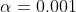 ,
,
然后对所有未知量执行一次迭代 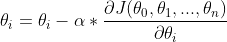 ,迭代后
,迭代后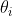 会逐渐靠近最优解,
会逐渐靠近最优解,
在迭代一定次数后,损失函数不再下降,此时即找到了一个最优解。
以上算法中有一些注意事项如下:
.当存在多个局部最优解时,初始化值的可能需要进行不同的尝试,此处的优化过程其实可以设置任意初始化值,因为这是一个凸函数;
.迭代步长不能过大或者过小,过大会出现损失函数的震荡,过小会导致收敛速度很慢;
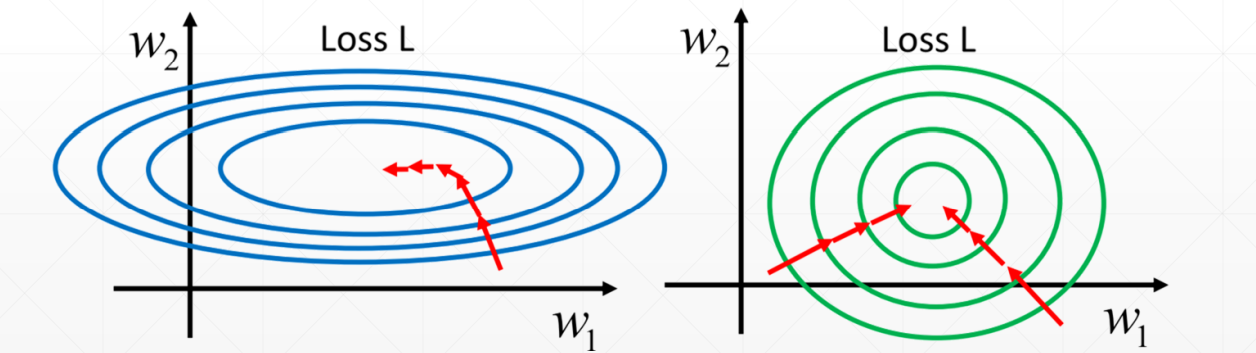
.对样本特征值归一化可以避免学习过程收敛速度过慢问题,使用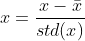 使得归一化后特征值期望为0,方差为1。下图给出了一个直观的解释:
使得归一化后特征值期望为0,方差为1。下图给出了一个直观的解释:
5)应用梯度下降拟合直线
利用以上方案给出一个直线拟合算法,给定平面上的一些点(x,y)构成一个特征集,拟合一条最佳直线,方案如下:
.假设函数为 y = wx + b,损失函数为 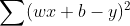 ;
;
.使用梯度下降法更新w和b,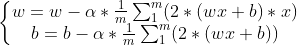 ,m为样本点数量,
,m为样本点数量,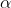 为学习率,代码如下:
为学习率,代码如下:
# b_current, w_current为一次迭代前的参数值,第一次迭代时使用程序给定的初始化值,如0,0等 # points为样本集 # learningRate控制迭代速度,要避免设置过大数值导致迭代过程无法收敛 # 返回值为一次迭代后新的参数值 def step_gradient(b_current, w_current, points, learningRate): b_gradient = 0 w_gradient = 0 N = float(len(points)) for i in range(0, len(points)): x = points[i, 0] y = points[i, 1] b_gradient += -(2/N) * (y - ((w_current * x) + b_current)) w_gradient += -(2/N) * x * (y - ((w_current * x) + b_current)) new_b = b_current - (learningRate * b_gradient) new_w = w_current - (learningRate * w_gradient) return [new_b, new_w]
2 全连接网络
在第1节线性回归中,使用的线性模型为, 为单个样本的多维特征值,为该假设模型的参数。
为了提升模型的表达能力,可使用更多的连接层以增强表达能力,可表达为: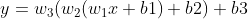 ,
,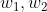 为矩阵,
为矩阵,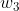 为行向量,其尺寸与输入输出参数关联。
为行向量,其尺寸与输入输出参数关联。
根据人眼特性(感受自然界图像会忽略掉部分响应较小数据),可在每一层网络中添加一个非线性函数以增强表达能力。
一般情况下,可使用ReLU函数,其图像如下:
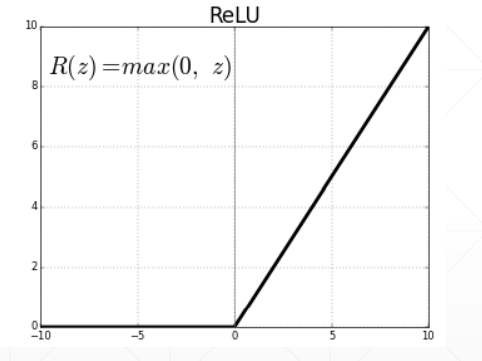
以上就构成了一个全连接网络,该网络使得线性回归具有更好的表达能力,其关键代码如下:
# 输入特征维度为784,输出特征维度为1 nn.Linear(784, 200), nn.ReLU(inplace=True), nn.Linear(200, 200), nn.ReLU(inplace=True), nn.Linear(200, 1), nn.ReLU(inplace=True),
3 逻辑回归(logistic regression)
到目前为止,我们了解了线性回归,并应用全连接层使其具有更强的表达能力。
对于分类问题(如10分类),一个可能的方案是将类别定义为1到10的整数,将分类问题转化为线性回归问题。
但以上方案存在一个明显的缺陷,即多个分类之间被人为的赋予了序列关系,这与分类之间的真实相似性并没有关联。
举例来说,对于0到9手写数字识别问题,7可能看起来更像1而不是更像6。
当转化为线性回归问题后,假设程序预测图像分类为6.5,最终计算结果只能为6或者7,这显然与概率常识不一致!
因此,需要使用其他方案改进分类问题,其关键思想是符合概率表达思维。
引入one-hot编码 0:[1,0,...,0],1:[0,1,...,0],2:[0,0,1,...,0],... ,9:[0,...,0,1]
1)该编码使得每个类之间不存在序列关系,
2)手写数字7被预测为[0,.5,0,0,0,0,0,.5,0,0]是更加合理的,
3)损失函数定义为预测值与编码之间的欧式距离,代码如下:
# 预测输出为:[b, 10] out = net(x) # 将真实值改写为one_hot编码 y_onehot = one_hot(y) # 基于one-hot编码求解预测值与真实值之间的欧式距离 loss = F.mse_loss(out, y_onehot)
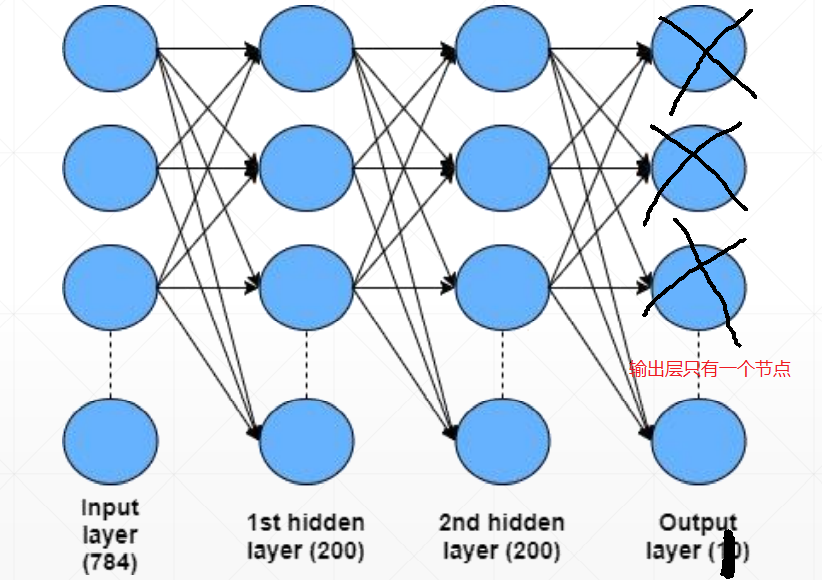
通过改进网络可实现以上目标,如下图:
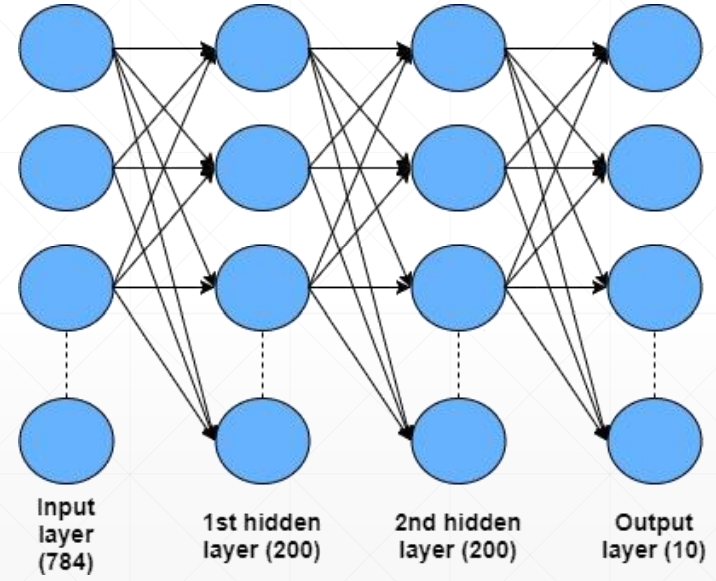
以上实现了一个简单的多分类问题,但仍有一些需要改进的地方:
1)使用softmax函数使得输出层的概率和为1,函数定义为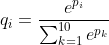 ,
,
softmax函数也使得各个分量间的差异更大,从而突出了最大概率值。
2)使用交叉熵改进损失函数,具体如下:
.熵被定义为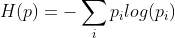 ,熵越大则不确定性越大。
,熵越大则不确定性越大。
.预测值为0到9的真实值的概率可使用交叉熵描述,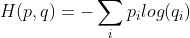 。
。
如果预测值完全等于真实值,则交叉熵为0,表示不确定性最小。
3)交叉熵优于MSE理由为:MSE可能出现梯度消失以及收敛速度较慢等问题。
4 卷积神经网络(CNN)
到目前为止,可以通过构建一个全连接网络实现一个多分类问题,在手写数字minist数据集上应用全连接网络进行训练,其准确率应该可以接近90%(只进行了少量测试,不确定是否可以更高)。
虽然一个简单的全连接网络可以实现较高的识别率,但也存在以下不足:
1)全连接网络将二维数据堆叠成一维数组,忽略了图像之间的邻域关系,这必然降低识别准确率;
2)全连接网络将原始图像作为特征向量,更好的特征向量应该是基于图像上进行一些不同尺度的提取;
3)全连接网络参数量巨大,使得更大网络难以训练;
通过引入卷积层可以解决以上问题,基本思想如下:
1)卷积从信号处理中引入,这里的卷积核与传统图像处理中思想一致;
2)与传统图像处理不同,深度学习训练中无需自己定义卷积核的内容,卷积核也是训练参数中的一部分;
3)卷积核一般尺寸为 1*1, 3*3, 5*5, 7*7,不同尺寸决定了卷积感受视野;
4)经常使用3*3卷积核,同时搭配下采样来感受不同视野;
5)1*1卷积核对于传统图像处理来说是无用的,但对于深度学习来说却是有用操作,理由是卷积操作对多个通道卷积再求和,从而减少了通道数量;
6)下采样操作可以是隔行采样,更有效的方式是使用池化操作,理由是:
对于经过卷积运算后的特征图像,往往表示某种特征(如边缘),其响应值较弱的部分可能是噪声信息,所以池化操作可以避免噪声,提升算法鲁棒性;
综上,我们引入了卷积层,进一步增强了网络的表达能力,一个经典的网络(LeNet-5)如下图所示:
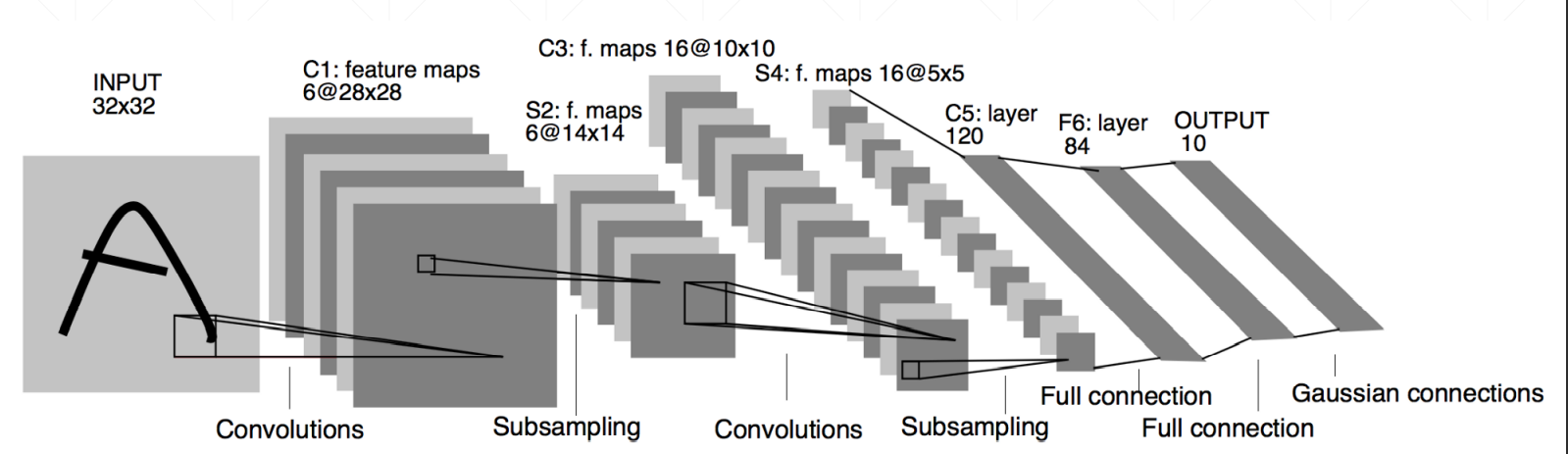
这是一个5层(不包括下采样)的神经网络,基于minist数据集进行训练,其流程如下:
1)输入数据维度为 [b,1,32,32],b表示神经网络每次需要处理的一个batch,所有的训练与测试均以batch为单位;
2)第一个卷积层维度为[b,6, 28,28],因为没有使用padding操作,卷积后图像尺寸会变小,这里卷积核尺寸为5*5;
3)对卷积层下采样后得到维度为[b,6,14,14],这里下采样可以使用池化操作取代;
4)第二个卷积层维度为[b, 16, 10, 10],因为没有使用padding操作,卷积后图像尺寸会变小,这里卷积核尺寸为5*5;
5)对卷积层下采样后得到维度为[b,16, 5, 5],这里下采样可以使用池化操作取代;
6)将二维特征图像堆叠为一维特征,其维度为[b, 400];
7)对一维特征经过第一个线性层得到维度为[b, 120];
8)经过第二个线性层得到维度为[b, 84];
9)经过第三个线性层得到输出层维度为[b, 10],这里不用使用高斯层!
10)在输出层上应用softmax函数并计算交叉熵可得到损失函数;
11)优化损失函数即完成训练;
5 pytorch实现
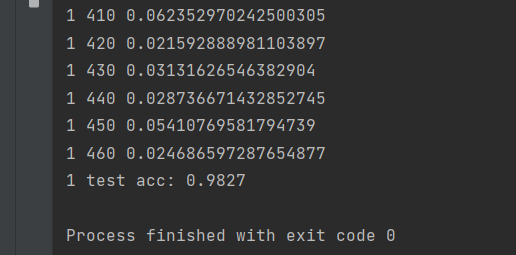
使用pytorch库基于minist数据集实现一个LeNet-5网络,其中,lenet5.py包含了LeNet-5网络的具体实现,main.py调用lenet5类实现训练与测试,经过简单训练其成功率达到了98%。
#lenet5.py #引入pytorch相关库 import torch from torch import nn from torch.nn import functional as F #定义Lenet网络类,自定义类必须继承自nn.Module class Lenet5(nn.Module): #定义初始化函数 def __init__(self): super(Lenet5, self).__init__() #定义卷积序列 self.conv_unit = nn.Sequential( # x: [b, 1, 32, 32] => [b, 16, ] nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=0), nn.MaxPool2d(kernel_size=2, stride=2, padding=0), #[b, 16, ] => [b, 32, ] nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=0), nn.MaxPool2d(kernel_size=2, stride=2, padding=0), # ) #定义全连接序列 self.fc_unit = nn.Sequential( nn.Linear(32*5*5, 32), nn.ReLU(), # nn.Linear(120, 84), # nn.ReLU(), nn.Linear(32, 10) ) #定义前向函数 def forward(self, x):
batchsz = x.size(0) # [b, 1, 32, 32] => [b, 16, 5, 5] x = self.conv_unit(x) # [b, 16, 5, 5] => [b, 16*5*5] x = x.view(batchsz, 32*5*5) # [b, 16*5*5] => [b, 10] logits = self.fc_unit(x) return logits #main.py #引入pytorch相关库 import torch import torchvision from torch.utils.data import DataLoader from torchvision import datasets from torchvision import transforms from torch import nn, optim # 引入lenet5网络类,实现文件为lenet5.py from lenet5 import Lenet5 def main(): #一次梯度下降法使用图像数量 batchsz = 128 #加载训练集 minist_train = torch.utils.data.DataLoader( torchvision.datasets.MNIST('mnist_data', train=True, download=True, transform=torchvision.transforms.Compose([ transforms.Resize((32, 32)), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( (0.1307,), (0.3081,)) ])), batch_size=batchsz, shuffle=True) # 加载测试集 minist_test = torch.utils.data.DataLoader( torchvision.datasets.MNIST('mnist_data/', train=False, download=True, transform=torchvision.transforms.Compose([ transforms.Resize((32, 32)), torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( (0.1307,), (0.3081,)) ])), batch_size=batchsz, shuffle=False) #实例化Lenet对象,这里在CPU上运行 #device = torch.device('cuda') model = Lenet5()#.to(device) print(model) #使用交叉熵进行优化 criteon = nn.CrossEntropyLoss()#.to(device) optimizer = optim.Adam(model.parameters(), lr=1e-3) for epoch in range(2): model.train() #切换到训练模式,通过切换训练/测试模式以避免测试数据更新梯度 for batchidx, (x, label) in enumerate(minist_train): #x, label = x.to(device), label.to(device) #forward方法 logits = model(x) #使用交叉熵建立损失函数 loss = criteon(logits, label) #反向传播 optimizer.zero_grad() loss.backward() optimizer.step() #经过10个batch后打印训练结果 if batchidx % 10 == 0: print(epoch, batchidx, loss.item()) #切换到测试模式,明确指定以下内容不需要梯度信息 model.eval() with torch.no_grad(): # 遍历测试集,统计准确率 total_correct = 0 total_num = 0 for x, label in minist_test: #x, label = x.to(device), label.to(device) #应用前向方法预测分类 logits = model(x) #求最大概率对应分类序列号 pred = logits.argmax(dim=1) #比较预测值与实际值 correct = torch.eq(pred, label).float().sum().item() total_correct += correct total_num += x.size(0) acc = total_correct / total_num print(epoch, 'test acc:', acc) if __name__ == '__main__': main()
训练结果如下:
参考资料:深度学习与pytorch入门实战 龙曲良

 浙公网安备 33010602011771号
浙公网安备 33010602011771号