浅谈Class Activation Mapping(CAM)
第一次接触Class Activation Mapping这个概念是在论文《Learning Deep Features for Discriminative Localization 》(2016CVPR)中。
简单来说,这篇文章主要介绍了两个核心技术:
GAP(Global Average Pooling Layer) 和 CAM(Class Activation Mapping)
- GAP(全局平均池化层)
在说全局平均池化之前,我想先谈一谈池化层。我们都知道,池化层的作用是正则化。比如说,这是一个VGG-16的模型。
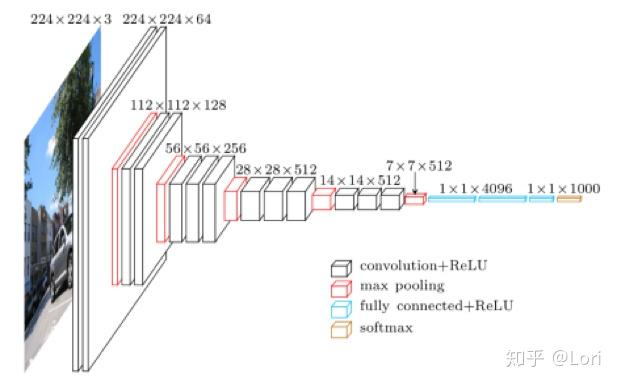
我们可以直观的看到,从卷积层到池化层,深度不变,尺寸变小了。我们使用更小尺寸的特征图来表示输入,虽然会丢失一些信息,但是池化层可以防止过拟合,降低维度,保留主要特征的同时减少计算量,减少了参数数量。
全局平均池化也一样,可以用来正则化。让我们来看一个容易的例子,我想这个相信可以帮助我们理解全局平均池化。
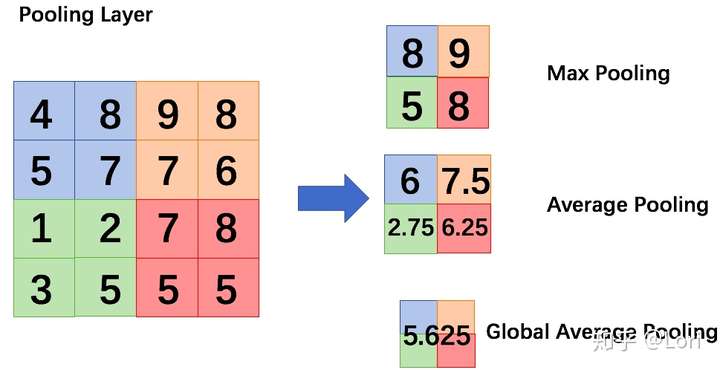
首先是Max pooling(最大池化)。如图所示,最大池化是选择每个子区域的最大值,然后使用子区域的最大值表示该子区域。
Average pooling(平均池化)是指计算出子区域的平均值,用一个平均值来分别表示子区域子区域。
与平均池化类似,Global Average Pooling(全局平均池化)是指计算整个区域的平均值,仅用一个值来表示整个区域。通过下面这个图,我想我们可以更直观的理解GAP。
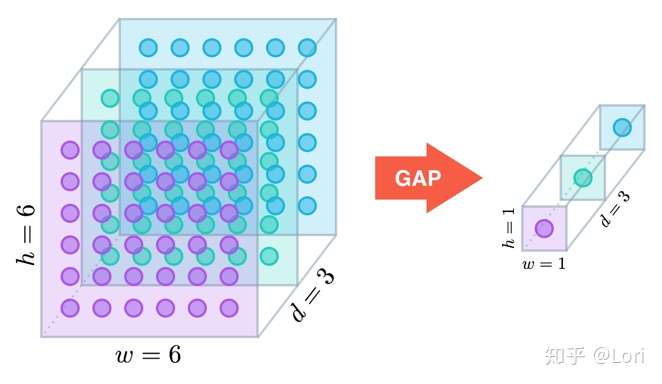
左边是一个特征图。高度为6,宽度为6,深度为3。当它经过GAP,我们把每一层的参数用一个值表示,这个特征图就变成一个1*1*3的特征向量。
第一个提出GAP这个想法的,是一篇叫做《Network in Network》的论文。这篇论文发现用GAP代替全连接层,不仅可以降低维度,防止过拟合,减少大量参数,网络的性能也很不错。
GAP怎么代替全连接层呢?让我们回到一开始的例子。
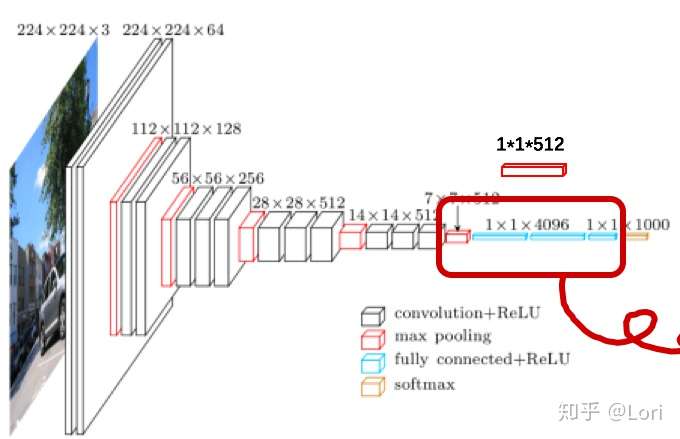
如果我们使用GAP,我们必须改变网络的结构。首先我们把最大池化层和全连接层扔掉,只需要将其换成一个尺寸为1*1*512的GAP,之后和原网络一样接一个softmax层就可以了。当然这只是我从理论出发举的一个小小的例子,性能是否改变还没有做过实验。
如果我们使用GAP来代替FC,优点是最小化参数数量的同时保持高性能,结构变得简单,也避免了过拟合。但是缺点是和FC相比,GAP收敛速度较慢。
虽然这个GAP不是新的技术,但是在论文《Learning Deep Features for Discriminative Localization 》中,他们发现了GAP的一个作用,能保留空间信息并且定位(localization)
尽管在图像级标签上进行了训练,它仍能够区分判别图像区域。 并且在许多任务中它都可以定位判别图像区域,尽管只是训练基于解决分类任务。
- CAM(类激活映射)
那么什么是类激活映射呢?CAM是一个帮助我们可视化CNN的工具。使用CAM,我们可以清楚的观察到,网络关注图片的哪块区域。比如,我们的网络识别出这两幅图片,一个是在刷牙,一个是在砍树。通过CAM这个工具,我们可以清楚的看到网络关注图片的哪一部分,根据哪一部分得到的这个结果。

The class activation map is simply a weighted linear sum of the presence of these visual patterns at different spatial locations.
By simply upsamplingthe class activation map to the size of the input image, we can identify the image regions most relevant to the particular category.
使用论文中的话来说,类激活图仅仅是在不同空间位置处存在这些视觉图案的加权线性和。 通过简单地将类激活映射上采样到输入图像的大小,我们可以识别与特定类别最相关的图像区域。如果把这段话翻译成数学语言,就是如下的公式。

但是我想这样理解起来是很困难的,所以我想通过图片来解释它。
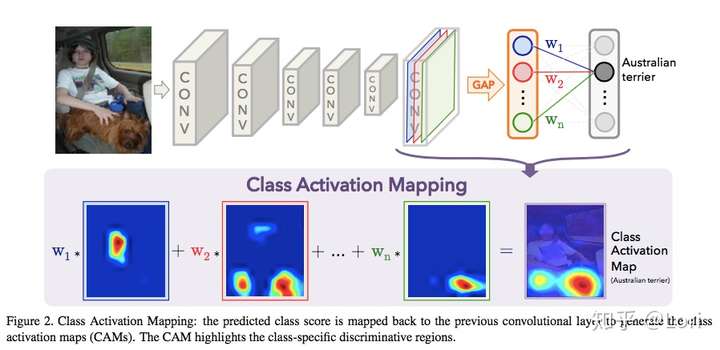
这是一个基于分类训练的CNN网络,最左边是输入,中间是很多卷积层,在最后一层卷积层之后接的是全局平均池化层(GAP),最后接一层softmax,得到输出。我们刚刚说过,GAP就是把特征图转换成特征向量,每一层特征图用一个值表示,所以如果这个特征图的深度是512,那么这个特征向量的长度就是512。我们的输出是Australian terrier,澳大利亚梗。我们用Australian terrier这个类对应的权重乘上特征图对应的层,用热力图归一化,即下面一排热力图:W1*蓝色层+W2*红色层+…+Wn*绿色层=类激活映射(CAM),所以说CAM是一个加权线性和。通常来说,最后一层卷积层的大小是不会等于输入大小的,所以我们需要把这个类激活映射上采样到原图大小,再叠加在原图上,就可以观察到网络得到这个输出是关注图片的哪个区域了。这也就是说可以是任意输入图片的大小和卷积层的深度。
我还想说一点是,因为CAM基于分类,所以被激活的区域是根据分类决定的,即同一个特征图,只更新不同的权重。所以即使我们使用同一张input,就像下面这个例子。
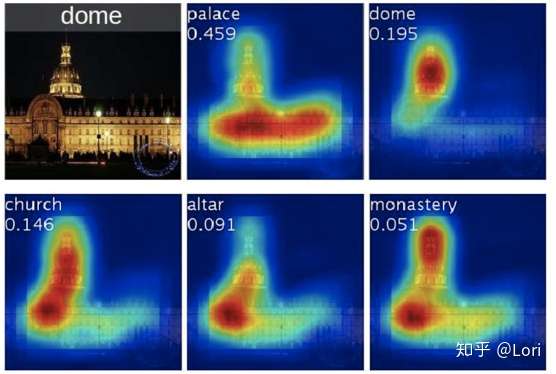
示例图片的地面真值是圆顶。五张类激活映射分别是前五名预测类别和得分。我们可以看到如果输出是宫殿,网络关注的是整块区域的。如果输出是圆顶,网络只是关注宫殿顶部。
- CAM的缺陷
这项技术非常有用但是存在一些缺陷的。首先我们必须改变网络结构,例如把全连接层改成全局平均池化层,这不利于训练。第二是这是基于分类问题的一种可视化技术,用于回归问题可能就没有这么好的效果。
为了解决第一个问题,2017年出现了一种改进的技术叫Grad-CAM,Grad-CAM可以不改变网络结构进行可视化,详见这篇论文《Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization》 (2017 ICCV)。
- CAM的应用
CAM也可以应用到很多方面。比如,它可以发现场景中有用的物体:

在弱标记图像中定位比较抽象的概念:

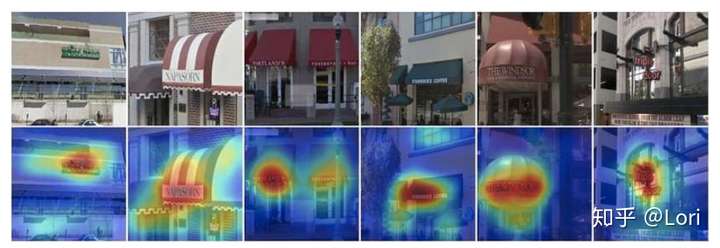
弱监督文字检测,它可以关注文字部分即使网络没有训练过文字或者任何注释框:
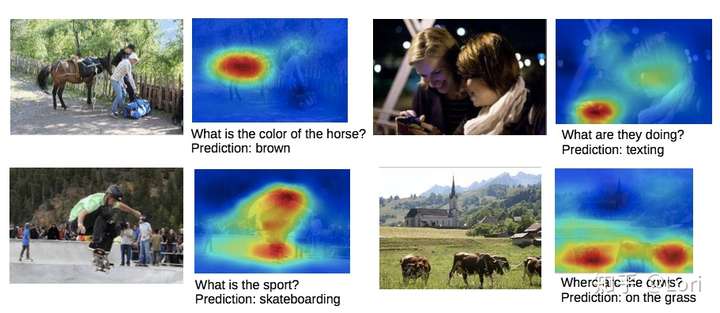
关于视觉问答,我们可以看到网络关注答案区域:
利用CAM的可视化技术,我认为CAM也能帮助我们对比模型,选择一个更合适的结构:
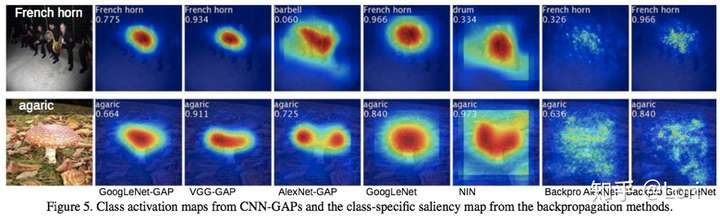
在日常做实验的时候也可以利用CAM帮助我们发现问题,改进结构:
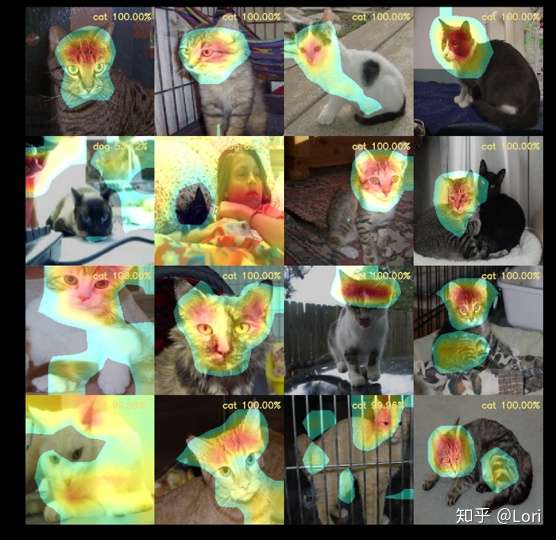
这是一个简单的二分类问题,识别图片是猫还是狗,通过CAM技术,我们可以看到网络关注哪里。在第二排第一第二个结果中,网络错误的将猫识别为狗,使用CAM我们可以很快发现错误原因是对于两张图片网络忽略了猫,而关注了其他区域。所以CAM可视化这可以帮助我们理解网络。
CAM使得弱监督学习发展成为可能,可以慢慢减少对人工标注的依赖,能降低网络训练的成本。通过可视化,就像往黑箱子里打了一个手电筒,让人们可以尝试去理解网络。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号