Redis
一、redis简介
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
二、redis安装(基于centos7)
待完善:后面加docker配置,和yum直接安装
参考redis中文官网——http://www.redis.cn/download.html
-
安装wget(若未安装)
yum -y install wget -
下载redis压缩包(本文演示下载位置为/usr/local/mydownload,安装位置为/usr/local/mysoftware/redis,配置文件存放目录为/usr/local/mysoftware/redis/config)
wget http://download.redis.io/releases/redis-6.0.6.tar.gz -
解压到指定目录
tar xzf redis-6.0.6.tar.gz -C ../mysoftware/redis -
切换到解压后目录
cd ../mysoftware/redis/redis-6.0.6/ -
准备编译,注意,编译前需安装gcc且版本高于5
查看gcc版本
gcc -v若未安装或版本低
sudo yum install centos-release-scl sudo yum install devtoolset-7-gcc* scl enable devtoolset-7 bash -
编译
make -
安装
make install -
可能出现的错误
-
如果在排查gcc问题之前就执行了make,那么在解决了gcc问题之后重新执行make会报这个错误,这个时候将之前使用make编译的错误文件删除即可
如果gcc无问题则不会出现此错误
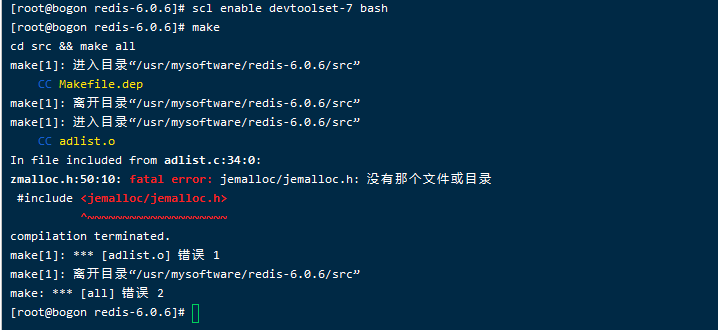
执行命令
make distclean之后再次执行make命令
-
make test时tcl错误——若没有问题或解决了之前的问题顺利make之后,最后会提示Hint: It's a good idea to run 'make test' 😉,顾名思义装完之后建议跑一下测试,但是跑这个需要安装tcl,这个命令可以不执行,若想执行,则可能会报tcl未安装

安装tcl后再执行即可
yum install -y tcl
-
至此,redis安装完毕
三、redis配置
将redis配置文件复制到其他文件夹并修改
cp redis.conf ../config/
若未安装vim则先安装vim
yum -y install vim
使用vim打开配置文件,将redis修改为守护进程,使其可以后台运行,其他设置暂不修改
cd ../config/
vim redis.conf
修改完毕后使用我们的配置文件启动
cd /usr/local/bin/
redis-server /usr/local/mysoftware/config/redis.conf
使用cli简单做个测试
redis-cli -p 6379
ping
set testkey testvalue
get testkey
四、redis可视化管理工具
这里推荐使用免费的Another Redis DeskTop Manager,下载地址https://github.com/qishibo/AnotherRedisDesktopManager/releases
下载安装好了打开,后点击新建连接
使用ssh连接,输入ip、用户名、密码、点击确定
此时就能看到我们的redis信息了,里面的基本操作很简单,根据提示操作即可,这里不再介绍
五、redis数据类型及常用命令
全部命令参考redis命令列表:http://www.redis.cn/commands.html,这里只摘取其中常用的命令
根据redis数据类型的不同,其命令也会不同,例如设置一个string类型的键值对使用set命令,而设置一个list类型的键值对则需要使用lpush或rpush
因此这些常用命令要根据数据类型进行分类。
当然,对库和键的操作与数据类型无关,这些操作都是通用的
(一)、库操作
redis安装完成后默认有16个库,下标为0~15,默认为0号库
select__切换库
根据下标切换不同的库
格式:select index
select 0
flushdb__清空当前库
清空当前库数据
flushdb
flushall__清空所有库
清空所有库的数据,慎用
flushall
dbsize__查看总键数
用来查看当前库有多少个键
dbsize
(二)、键操作
上面测试时我们存入了一个string类型的键值对,接下来我们就用string来简单进行下键的基本操作
先清空当前库
flushdb
设置几个string类型的键值对
set k1 v1
set k2 v2
set k3 v3
set key4 value4
set key5 value5
keys__正则取key
根据正则表达式查找key
格式:keys pattern
例如查看数据库中所有的key
keys *
结果:
1) "k3"
2) "key4"
3) "k2"
4) "key5"
5) "k1"
查看所有以key开头的键
keys key*
结果:
1) "key4"
2) "key5"
查看k后接数字的键
keys k[0-9]
结果
1) "k3"
2) "k2"
3) "k1"
del__删除key
删除指定的一个或多个键
格式:del key[key ...]
例如:删除k1和key4
del k1 key4
结果
(integer) 2
返回值即为被删除的key的数量,这里删除了两个,返回值就是2
exists__是否存在
判断某个或某些键是否存在,返回值为1则存在,为0则不存在
格式:exists key [key ...]
例如,判断名为k1的键是否存在
exists k1
结果
(integer) 0
需要注意的是,可以写多个key,只要有一个存在,返回值即为1
exists k1 key4 k2
结果
(integer) 1
rename__重命名
将key重命名,若新名字已存在,则覆盖它的值
格式:rename key newkey
例如:将k2重命名为key2
rename k2 key2
renamenx__重命名且未存在
将key重命名,但新名字必须未存在
格式:renamenx key newkey
例如:将k3重命名为key2,key2已存在,修改失败,返回值为0
renamenx k3 key2
结果
(integer) 0
move__移动到其他库
将一个key移动到另一个数据库,当前数据库中必须有要被移动的key,且目标数据库中不能有同名的key
成功返回1,失败返回0
格式:move key db
例如:将key5移动到1号库
move key5 1
type__获取类型
返回key的类型
格式:type key
type k3
结果
string
randomkey__获取随机key
随机返回一个key,若当前数据库没有key,则返回nil
randomkey
expire__设置过期时间
为key设置过期时间,超过时间后直接删除该key
格式:expire key seconds
例如:将k3设置为60秒后过期
expire k3 60
注意,如果在过期之前使用set修改了k3的值,那么设置的过期时间将会被清除
如果在过期之前使用rename将k3修改为key3,那么无论key3是否被设置了超时时间,都会被k3所替代
如:key3的过期时间为100秒(或未设置过期时间),k3的过期时间为50秒。当我们执行rename k3 key3命令时,key3的剩余时间为90秒(或未设置过期时间),k3的剩余时间为36秒,那么执行完rename命令后,key3的过期时间将会是36秒
persist__移除过期时间
移除key的过期时间,若key不存在或没有设置过期时间返回0
格式:persist key
例如:移除k3的过期时间
persist k3
ttl__查看剩余过期时间
查看key的过期时间,若key不存在返回-2,若key存在且没有设置过期时间,返回 -1 。
格式:ttl key
例如:查看k3的过期时间
ttl k3
(三)、String类型
string 是 redis 最基本的类型,一个对应一个 value。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
常用命令:
set__设置值
设置一个key的value值,若值不存在返回nil,类型不是string会报错
格式:set key value
例如,设置用户名为admin
set username admin
set命令的扩展:
如果要设置一个值的同时为它设置过期时间,那么可以使用setex命令
setex key seconds value
例如:为k1赋值并同时设置10秒后过期
setex k1 10 v1
同理,要设置一个值,只有key不存在时才设置,存在则不作修改,官方提供了setnx命令,SETNX是”SET if Not eXists”的简写。
设置成功返回1,为未被设置返回0
setnx k2 v2
(integer) 1
setnx k2 v123
(integer) 0
从2.6.12版本开始,redis为SET命令增加了一系列选项:
EXseconds – 设置键key的过期时间,单位时秒PXmilliseconds – 设置键key的过期时间,单位时毫秒NX– 只有键key不存在的时候才会设置key的值XX– 只有键key存在的时候才会设置key的值
因此,我们可以使用set加可选项的方式替代单独的命令
上面的两个命令可以使用下面这种方式实现同样的效果,也可以组合使用,更加方便
set k1 v1 ex 10
set k2 v2 nx
set k3 v4 ex 10 nx
get__取值
根据key获取value值
格式:get key
get username
mset__批量设置值
批量设置键值对
格式:mset key value [key value ...]
例如:
mset k1 v1 k2 v2 k3 v3
mget__批量取值
批量获取,若其中有键不存在,则返回nil
格式:mget key [key ...]
例如:k4不存在
mget k1 k2 k3 k4
1) "v1"
2) "v2"
3) "v3"
4) (nil)
msetnx__批量设置,需不存在
不同于set可以加选项,mset不可以使用后加nx的方式实现不存在才设置,因此需要使用单独的msetnx命令
使用时,添加的多个key value中只要有一个key已存在,那么本次msetnx一个操作都不会执行,是原子性的。要么都成功,要么都失败,不会出现部分成功部分失败的情况
格式:msetnx key value [key value ...]
例如:k3是已经存在的,k4和k5不存在,那么返回值为0,即一个都没有成功,如果只设置k4和k5会设置成功,返回值为1,表示都成功了
msetnx k3 v3 k4 v4 k5 v5
(integer) 0
msetnx k4 v4 k5 v5
(integer) 1
getset__设置新值,返回旧值
为key设置一个新值,并返回它的旧值。如果旧值不存在,返回nil,同时不会创建这个key
例如:当k8不存在时,使用getset并不会创建k8为其赋值,只有当k8存在时才会修改它的值,并返回旧值
get k8
(nil)
getset k8 v8
(nil)
get v8
(nil)
set k8 v8
OK
getset k8 nv8
"v8"
get k8
"nv8"
append__末尾添加
将新值添加到原值之后,若key不存在,该操作等同于set
返回值为添加后value的总长度
格式:append key value
例如:为邮箱添加后缀
set k1 123
OK
append k1 @qq.com
(integer) 10
get k1
"123@qq.com"
strlen__获取长度
根据key获取value的长度,若key不存在返回0,value不是string类型报错
格式:strlen key
例如:获取k1的长度
strlen k1
(integer) 10
incr__加一
对存储在指定key的数值执行原子的加1操作
若key不存在,则会先设置一个为0的值再加1,即结果为1
若value不是string类型,或不是一个整数,则报错
返回值为加1后的值
格式:incr key
例如:将键名为keyincr的value值加1,此时数据库中没有这个值,那么会创建这个键值对,且值默认为0,再加1
再次执行此操作,加1后值为2,返回值即为2
incr keyincr
(integer) 1
incr keyincr
(integer) 2
get keyincr
"2"
decr__减一
对存储在指定key的数值执行原子的减1操作
同incr,只是将加一换为减一
incrby__加整数
将key对应的value值加一个整数
格式:incrby key increment
同incr,key不存在会先创建再操作
例如,将键名为keyincr的value值加3
INCRBY keyincr 3
(integer) 5
get keyincr
"5"
decrby__减整数
将key对应的value值减一个整数,基本操作同incrby
setrange__覆盖部分值
从offset处开始,覆盖value长度个值,返回值为覆盖后的长度
注意,下标从0开始
格式:setrange key offset value
例如:修改邮箱后缀
set email 123@qq.com
OK
setrange email 4 163.com
(integer) 11
get email
"123@163.com"
这里要修改的是@符号之后的内容,下标从0开始,即第一个q下标为4,从4开始覆盖,由于163比qq多了一位,因此必须写全,不能只写163,否则结果会是123@163com,com前的点会被覆盖掉
如果key不存在,则会创建一个空字符串,并从指定位置插入,0到offset之间会补0
如果offset的值大于value的长度,那么会从字符串的最后一位开始到offset之间同样会补0
例如:
setrange testkey 2 v1
(integer) 4
get testkey
"\x00\x00v1"
setrange testkey 6 v2
(integer) 8
get testkey
"\x00\x00v1\x00\x00v2"
getrange__获取部分值
获取某个范围内的字符串,同样下标从0开始,开始结束的下标都可以是负数(setrange中的offset不可以是负数),-1表示倒数第一位,-2表示倒数第二位……
格式:getrange key start end
例如:
set k1 12345
OK
getrange k1 1 3
"234"
getrange k1 0 -1
"12345"
(四)、list类型
Redis lists基于Linked Lists实现,优点是添加快,缺点是根据索引查询慢
lpush__左插入
将所有指定的值插入到存于 key 的列表的头部。如果 key 不存在,那么在进行 push 操作前会创建一个空列表。 如果 key 对应的值不是一个 list 的话,那么会返回一个错误。插入成功返回list的长度
格式:lpush key value [value ...]
lpush list1 v1 v2 v3
(integer) 3
lrange list1 0 -1
1) "v3"
2) "v2"
3) "v1"
可以发现顺序是反的,下面rpush会对比说明
lrange__左查询
从list左侧查询从start到stop个元素
返回存储在 key 的列表里指定范围内的元素。 start 和 stop偏移量都是基于0的下标,即list的第一个元素下标是0(list的表头),第二个元素下标是1,以此类推。
偏移量也可以是负数,表示偏移量是从list尾部开始计数。 例如, -1 表示列表的最后一个元素,-2 是倒数第二个,以此类推。
上面lpush例子中两个下标是0和-1,即从头到尾的所有元素
格式:lrange key start stop
例如:查0到2之间的元素,是包含0和2本身的,即0、1、2三个元素
lrange list1 0 2
1) "v3"
2) "v2"
3) "v1"
如果下标大于list本身的长度,那么会返回一个空列表
lrange list1 4 2
(empty array)
如果stop大于list的长度,则会默认为最后一个元素的下标
lrange list1 0 100
1) "v3"
2) "v2"
3) "v1"
rpush__右插入
向存于 key 的列表的尾部插入所有指定的值。
格式:rpush key value [value ...]
rpush list2 v1 v2 v3
(integer) 3
lrange list2 0 -1
1) "v1"
2) "v2"
3) "v3"
可以看到和lpush不同,它是顺序输出的,那么区别就在于lpush是从左侧,也就是表头插入;rpush是从右侧,也就是表尾插入
我们输入的顺序是v1、v2、v3
如果使用lpush从表头插,那么就是v1先进,然后v2,最后v3
此时,list中的数据顺序(从左到右)为v3、v2、v1
而lrange是从左开始取的,自然取出来的顺序也是如此
如果使用rpush从表尾插同样是v1先进,然后v2,最后v3
此时,list中的数据顺序(从左到右)为v1、v2、v3
使用lrange从左向右取就是顺序的(redis里面是没有rrange的)
lpop__左删除
移除并且返回 key 对应的 list 的第一个元素,key不存在返回nil
格式:lpop key
例如:
rpush list1 v1 v2 v3
(integer) 3
lpop list1
"v1"
lrange list1 0 -1
1) "v2"
2) "v3"
rpop__右删除
移除并返回存于 key 的 list 的最后一个元素。
格式:rpop key
例如:
rpush list2 v1 v2 v3
(integer) 3
rpop list2
"v3"
lrange list2 0 -1
1) "v1"
2) "v2"
lindex__根据下标取值
根据索引(下标)取值,类似于数组的取值操作,下标从0开始,可以是负数,-1表示最后一位,-2表示倒数第二位……
下标越界返回nil
格式:lindex key index
例如:
rpush list3 v1 v2 v3
(integer) 3
lindex list3 1
"v2"
lindex list3 -1
"v3"
lindex list3 5
(nil)
llen__获取list长度
返回存储在 key 里的list的长度。 如果 key 不存在,那么就被看作是空list,并且返回长度为 0。 当存储在 key 里的值不是一个list的话,会返回error。
格式:lien key
例如:
llen list3
(integer) 3
lrem__删除指定个value值
从存于 key 的列表里移除前 count 次出现的值为 value 的元素。 这个 count 参数通过下面几种方式影响这个操作:
count > 0: 从头往尾移除值为 value 的元素。
count < 0: 从尾往头移除值为 value 的元素。
count = 0: 移除所有值为 value 的元素。
格式:lrem key count value
例如:当count参数为2时,删除的是前两个v1,当count参数为-2时,删除的是后两个v1
rpush list4 v1 v2 v1 v3 v1
(integer) 5
lrem list4 2 v1
(integer) 2
lrange list4 0 -1
1) "v2"
2) "v3"
3) "v1"
del list4
(integer) 1
rpush list4 v1 v2 v1 v3 v1
(integer) 5
lrem list4 -2 v1
(integer) 2
lrange list4 0 -1
1) "v1"
2) "v2"
3) "v3"
ltrim__截取值
根据下标截取中间的值并将其重新赋予该值,下标从0开始
start 和 end 也可以用负数来表示与表尾的偏移量,比如 -1 表示列表里的最后一个元素, -2 表示倒数第二个,等等。
超过范围的下标并不会产生错误:如果 start 超过列表尾部,或者 start > end,结果会是列表变成空表(即该 key 会被移除)。 如果 end 超过列表尾部,Redis 会将其当作列表的最后一个元素。
格式:ltrim key start stop
例如:
rpush list5 v1 v2 v3 v4 v5
(integer) 5
ltrim list5 1 3
OK
lrange list5 0 -1
1) "v2"
2) "v3"
3) "v4"
lset__修改指定下标的值
根据下标修改值
格式:lset key index value
例如:
rpush list6 v1 v2 v3 v4 v5
(integer) 5
lset list6 2 v333
OK
lrange list6 0 -1
1) "v1"
2) "v2"
3) "v333"
4) "v4"
5) "v5"
linsert__某值前后插入
在给定的某个值之前或之后插入新的值
格式:linsert key before|after pivot value
例如:
rpush list7 v1 v2 v3
(integer) 3
linsert list7 before v2 v1.5
(integer) 4
linsert list7 after v2 v2.5
(integer) 5
lrange list7 0 -1
1) "v1"
2) "v1.5"
3) "v2"
4) "v2.5"
5) "v3"
(五)、set类型
sadd__添加值
添加一个或多个值到集合中,若key不存在则创建并添加,若要添加的值已存在,则不会重复添加
如果key 的类型不是集合则返回错误
格式:sadd key member [member ...]
例如:
sadd set1 v1 v2 v3
(integer) 3
smembers set1
1) "v3"
2) "v1"
3) "v2"
sadd set1 v1
(integer) 0
smembers__获取所有值
返回key集合所有的元素
例如:
smembers set1
1) "v3"
2) "v1"
3) "v2"
sismember__判断值是否存在
判断给定的值是否已经存在于set中,存在返回1,不存在返回0
格式:sismember key member
例如:
sismember set1 v1
(integer) 1
sismember set1 v5
(integer) 0
scard__获取总个数
返回集合中元素的个数,key不存在返回0
格式:scard key
scard set1
(integer) 3
srem__移除一个或多个元素
从集合中移除一个或多个指定元素,集合不存在返回0,被移除的元素不存在则忽略,返回值为被移除的个数,不包括不存在的
格式:srem key member [member...]
例如:
smembers set1
1) "v3"
2) "v1"
3) "v2"
srem set1 v1 v2
(integer) 2
smembers set1
1) "v3"
spop__随机删除并返回
从存储在key的集合中移除并返回一个或多个随机元素。返回值为被移除的元素
count参数将在更高版本中提供,但是在2.6、2.8、3.0中不可用。
spop key [count]
例如:
sadd set2 v1 v2 v3 v4 v5
(integer) 5
spop set2
"v1"
spop set2 2
1) "v3"
2) "v2"
smembers set2
1) "v4"
2) "v5"
srandmember__随机返回一个或多个元素
仅提供key参数,那么随机返回key集合中的一个元素
Redis 2.6开始,可以接受 count 参数,如果count是整数且小于元素的个数,返回含有 count 个不同的元素的数组,如果count是个整数且大于集合中元素的个数时,仅返回整个集合的所有元素,当count是负数,则会返回一个包含count的绝对值的个数元素的数组,如果count的绝对值大于元素的个数,则返回的结果集里会出现一个元素出现多次的情况
仅提供key参数时,该命令作用类似于SPOP命令,不同的是SPOP命令会将被选择的随机元素从集合中移除,而SRANDMEMBER仅仅是返回该随记元素,而不做任何操作
不使用count 参数的情况下该命令返回随机的元素,如果key不存在则返回nil
使用count参数,则返回一个随机的元素数组,如果key不存在则返回一个空的数组
格式:srandmember key [count]
例如:
sadd set3 v1 v2 v3 v4 v5
(integer) 5
srandmember set3
"v1"
srandmember set3 2
1) "v2"
2) "v5"
srandmember set3 10
1) "v4"
2) "v1"
3) "v3"
4) "v2"
5) "v5"
srandmember set3 -10
1) "v5"
2) "v5"
3) "v1"
4) "v5"
5) "v1"
6) "v5"
7) "v1"
8) "v2"
9) "v2"
10) "v4"
smove__两个key之间移动值
将member从source集合移动到destination集合中
如果source 集合不存在或者不包含指定的元素,这smove命令不执行任何操作并且返回0.否则对象将会从source集合中移除,并添加到destination集合中去
如果destination集合已经存在该元素,则smove命令仅将该元素从source集合中移除.
如果source 和destination不是集合类型,则返回错误.
移除成功返回1,source中不存在返回0
格式:smove source destination member
例如:
sadd setsou v1 v2 v3
(integer) 3
sadd setdes v3 v4 v5
(integer) 3
smove setsou setdes v1
(integer) 1
smove setsou setdes v3
(integer) 1
smove setsou setdes v6
(integer) 0
smembers setsou
1) "v2"
smembers setdes
1) "v4"
2) "v1"
3) "v3"
4) "v5"
sdiff__求差集
返回一个集合与给定集合的差集的元素
格式:sdiff key [key ...]
例如:
sadd set4 v1 v2 v3
(integer) 3
sadd set5 v3 v4 v5
(integer) 3
sdiff set4 set5
1) "v1"
2) "v2"
sinter__求交集
返回指定所有的集合的成员的交集
格式:sinter key [key ...]
例如:
sinter set4 set5
1) "v3"
sunion__求并集
返回给定的多个集合的并集中的所有成员,多个集合中重复的值不会多次出现
格式:sunion key [key ...]
例如:
sunion set4 set5
1) "v1"
2) "v3"
3) "v2"
4) "v4"
5) "v5"
(六)、hash类型
和上面的三种类型做对比
string是一个key对应一个值
如:key:value
list和set是一个key对应多个值
如:key:value1 value2 value3
而hash则是一个key对应多个键值对
如:key:key1:value1 key2:value2
hset__设置单个字段值
设置 key 指定的哈希集中指定字段的值。
key不存在被创建,已存在被覆写。
key不存在新建返回1,key存在被覆写返回0
格式:hset key field value
例如:
hset user name tom
(integer) 1
hget user name
"tom"
hset user name jerry
(integer) 0
hget user name
"jerry"
hget__获取单个字段值
获取指定key中指定字段的值,key或字段不存在时返回nil
格式:hget key field
例如:
hget user name
"jerry"
hmset__设置多个值
为key批量设置对个键值对,同hset,不存在创建,存在则覆写
格式:hmset key field value [field value ...]
例如:
hmset user1 name tom age 18
OK
hget user1 name
"tom"
hget user1 age
"18"
hmget__获取多个值
根据多个字段名获取多个值,key或key中的字段不存在返回空
格式:hmget key field [field ...]
例如:
127.0.0.1:6379> hmget user1 name age address email
1) "tom"
2) "18"
3) (nil)
4) (nil)
hgetall__获取所有值
获取key中所有的键值对,键和值都输出,key不存在返回一个空列表
格式:hgetall key
例如:
hgetall user1
1) "name"
2) "tom"
3) "age"
4) "18"
hsetnx__字段不存在设置值
只有字段不存在才设置值,若字段已存在,不会进行任何操作,设置成功返回1,已存在不操作返回0
格式:hsetnx key field value
hset hash2 f1 v1
(integer) 1
hsetnx hash2 f1 nv1
(integer) 0
hsetnx hash2 f2 v2
(integer) 1
hgetall hash2
1) "f1"
2) "v1"
3) "f2"
4) "v2"
hdel__删除一个或多个字段
删除指定key中一个或多个指定字段,不存在的字段会被自动忽略,返回值为删除成功的数量,不包括不存在的字段
格式:hdel key field [field ...]
例如:
hdel user1 name address email
(integer) 1
hgetall user1
1) "age"
2) "18"
hlen__获取字段数
获取指定key中的字段数量
格式:hlen key
例如:
hmset user2 f1 v1 f2 v2 f3 v3
OK
hlen user2
(integer) 3
hexists__判断字段是否存在
判断指定key中的某个字段是否存在,存在返回1,key或key中的字段不存在返回0
格式:hexists key field
例如:
hexists user2 f1
(integer) 1
hexists user2 f5
(integer) 0
hkeys__获取所有字段名
获取key中所有的字段名,key不存在返回空列表
格式:hkeys key
例如:
hkeys user2
1) "f1"
2) "f2"
3) "f3"
hvals__获取所有字段值
获取key中所有的字段值,key不存在返回空列表
格式:hvals key
例如:
hvals user2
1) "v1"
2) "v2"
3) "v3"
hincrby__字段值加整数
为指定key的字段值加指定的整数,字段值必须是整数,若字段不存在则默认为0再进行加法操作,整数值可以是负数,返回值为操作之后的结果
格式:hincrby key field increment
例如:
hset hash1 f1 1
(integer) 1
hincrby hash1 f1 -6
(integer) -5
hget hash1 f1
"-5"
hincrbyfloat__字段值加小数
为指定key的字段值加指定的小数,字段值可以是整数,若字段不存在则默认为0再进行加法操作,小数值可以是负数,返回值为操作之后的结果
格式:hincrbyfloat key field increment
例如:
hset hash1 f1 1
(integer) 1
hincrby hash1 f1 -6
(integer) -5
hget hash1 f1
"-5"
(七)、zset(sorted set)类型
zset,也叫sorted set,即有序集合。和无序的set不同,每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
zadd__添加值
将所有指定成员添加到键为key有序集合(sorted set)里面。 添加时可以指定多个分数/成员(score/member)对。 如果指定添加的成员已经是有序集合里面的成员,则会更新改成员的分数(scrore)并更新到正确的排序位置。
如果key不存在,将会创建一个新的有序集合(sorted set)并将分数/成员(score/member)对添加到有序集合,就像原来存在一个空的有序集合一样。如果key存在,但是类型不是有序集合,将会返回一个错误应答。
分数值是一个双精度的浮点型数字字符串。+inf和-inf都是有效值。
zadd后可以跟参数来进行一些扩展操作,redis版本需大于3.0.2
ZADD 命令在key后面分数/成员(score/member)对前面支持一些参数,他们是:
- XX: 仅仅更新存在的成员,不添加新成员。
- NX: 不更新存在的成员。只添加新成员。
- CH: 修改返回值为发生变化的成员总数,原始是返回新添加成员的总数 (CH 是 changed 的意思)。更改的元素是新添加的成员,已经存在的成员更新分数。 所以在命令中指定的成员有相同的分数将不被计算在内。注:在通常情况下,
ZADD返回值只计算新添加成员的数量。 - INCR: 当
ZADD指定这个选项时,成员的操作就等同incrby命令,对成员的分数进行递增操作。
格式:zadd key [NX|XX] [CH] [INCR] score member [score member ...]
格式:zadd key [NX|XX] [CH] [INCR] score member [score member ...]
例如:输入的时候我们并没有排序,但zset会根据value前的score进行自动排序
zadd zset1 1 v1 3 v3 2 v2 4 v4
(integer) 4
zrange zset1 0 -1
1) "v1"
2) "v2"
3) "v3"
4) "v4"
参数xx举例:这里将v1的score改为5,并添加score为5的值v5,v1修改成功,v5插入失败
zadd zset1 xx 5 v1 5 v5
(integer) 0
zrange zset1 0 -1
1) "v2"
2) "v3"
3) "v4"
4) "v1"
参数nx举例:将v1的分数值修改回1,同时添加v5,v1修改失败,v5添加成功
zadd zset1 nx 1 v1 5 v5
(integer) 1
zrange zset1 0 -1
1) "v2"
2) "v3"
3) "v4"
4) "v1"
5) "v5"
参数ch举例:将v1的分数修改为1,v5的分数修改为2,v3的分数修改为3,返回值为2(v1,v5发生了改变,v3未变)
zadd zset1 ch 1 v1 2 v5 3 v3
(integer) 2
zrange zset1 0 -1
1) "v1"
2) "v2"
3) "v5"
4) "v3"
5) "v4"
参数incr:将v1的score加2,返回值为进行完加法运算后的结果值,这个参数后面只能跟一个分数和值
zadd zset1 incr 2 v1
"3"
zrange__获取指定范围值
查询从start到stop个元素,包含start和stop, 返回的元素默认从低到高排列。 如果得分相同,将按字典排序。
和list中的lrange类似, start 和 stop 偏移量都是基于0的下标,即list的第一个元素下标是0(list的表头),第二个元素下标是1,以此类推。
偏移量也可以是负数,表示偏移量是从zset的尾部开始计数。 例如, -1 表示列表的最后一个元素,-2 是倒数第二个,以此类推。
不加参数默认只返回值,如果想连分数一起返回可以在后面加上withscores
格式:zrange key start stop [withscores]
zadd zset2 1 v1 2 v2 3 v3 4 v4 5 v5
(integer) 5
zrange zset2 0 1
1) "v1"
2) "v2"
127.0.0.1:6379> zrange zset2 -2 -1
1) "v4"
2) "v5"
zrange zset2 0 10
1) "v1"
2) "v2"
3) "v3"
4) "v4"
5) "v5"
zrange zset2 0 -1 withscores
1) "v1"
2) "1"
3) "v2"
4) "2"
5) "v3"
6) "3"
7) "v4"
8) "4"
9) "v5"
10) "5"
zrevrange__根据范围取值,倒序排列
和zrange一样是根据指定的范围取值,不同的是返回值是倒序排列的
格式:zrevrange key start stop [withscores]
例如:
zrevrange zset2 0 -1
1) "v5"
2) "v4"
3) "v3"
4) "v2"
5) "v1"
zrangebyscore__根据分数范围取值
获取分数在某个范围内的所有值,可选参数withscores连同分数一起返回,limit可以取结果的一部分,从下标offset开始(包括它本身),取count个值
格式:zrangebyscore key min max [withscores] [limit offset count]
例如:
zrangebyscore zset2 2 5
1) "v2"
2) "v3"
3) "v4"
4) "v5"
zrangebyscore zset2 2 5 withscores limit 1 2
1) "v3"
2) "3"
3) "v4"
4) "4"
zrevrangebyscore__根据分数范围取值,倒序排列
和zrangebyscore类似,不同的是它的结果是从高到低排列的,参数和zrangebyscore相反,最大值在前,最小值在后,注意区分
格式:zrevrangebyscore key max min [withscores] [limit offset count]
例如:
127.0.0.1:6379> zrevrangebyscore zset2 5 2
1) "v5"
2) "v4"
3) "v3"
4) "v2"
zrem__删除一个或多个元素
删除key中一个或多个value值
格式:zrem key member [member...]
例如:
zrem zset2 v2 v3
(integer) 2
zrange zset2 0 -1 withscores
1) "v1"
2) "1"
3) "v4"
4) "4"
5) "v5"
6) "5"
zcard__获取元素个数
获取给定key中的元素个数
格式:zcard key
zcard zset2
(integer) 3
zcount__获取指定分数范围元素个数
获取指定key中满足分数范围的元素个数
格式:zcount key min max
zadd zset3 1 v1 2 v2 3 v3 4 v4 5 v5
(integer) 5
zcount zset3 2 4
(integer) 3
zrank__返回元素的分数排名
返回给定key中元素的分数在总体中的排名,这个排名是从0开始的
格式:zrank key member
例如:
zrank zset3 v3
(integer) 2
zrevrank__倒序返回元素的分数排名
返回给定key中元素的分数在总体中的排名,与zrank的区别是分数是从大到小排的,排名同样是从0开始的
格式:zrevrank key member
例如:
zrank zset3 v1
(integer) 0
zrevrank zset3 v1
(integer) 4
六、redis持久化机制(RDB和AOF)
redis是基于内存的数据库,这也是它速度非常快的原因,但内存在断电后是会被清空的,而我们的redis在机器重启后却并没有丢失数据,显然它会把数据最终给放到硬盘里,这就要牵涉到它的持久化机制了
(一)、RDB
rdb,即redis database,在指定的时间间隔对数据进行快照(snapshot)存储,保存了某个时间点得数据集。通俗来说,就是redis会每隔一段时间将当前数据保存到一个叫dump.rdb文件的快照中。
保存RDB文件的方式
父进程fork出一个子进程,(fork函数将运行着的程序分成2个(几乎)完全一样的进程,每个进程都启动一个从代码的同一位置开始执行的线程。这两个进程中的线程继续执行,就像是两个用户同时启动了该应用程序的两个副本>。)由这个子进程负责进行持久化,而父进程则不受影响,可以继续进行数据操作。
rdb的配置
rdb的更新策略
并不是每次数据变动都会fork子进程重新生成rdb文件,redis的默认策略为save seconds changes,即多少秒内发生了多少次变动,就更新rdb文件。
如下图,默认的策略有三个,从上到下依次为,900秒(15分钟)改动了1次、00秒(5分钟)改动了10次、60秒(1分钟)改动了一万次。
只要满足其中一条,就会重新生成并覆盖rdb文件,可以根据需求修改。如果不想使用,设置为save “”即可,若想要手动提交,可以使用save命令。
rdb持久化虽然不会影响主线程,但频繁的fork子线程也会消耗资源,因此我们的触发条件一般会不会设置的很简单,那么这就会出现一个问题,以默认配置为例子,假如当前用户访问较少,距离上次修改过了4分钟的时候才修改了5次数据,如果现在机器故障,那么由于没有达到条件,下次重启时,这5次的修改将会丢失,数据的完整性和一致性会受到破坏,这也是rdb的一个无法避免的缺点。
rdb文件配置
rdb是默认开启的,在默认配置下,rdb文件生成目录是./,即当前目录,也就是在我们启动redis服务时的目录下创建dump.rdb文件。而重启redis后,会读取当前目录下的dump.rdb文件中的数据到内存。因此,我们最好在配置文件中指定rdb文件的目录,或者每次都选择同样的目录启动,否则会读不到之前的数据,建议选择前者,方便管理。
这里选择将rdb文件放到 /usr/local/mysoftware/redis/rdbfile/目录下,以后就可以在任意目录下启动redis,不用再跑到专门的目录下启动了。
除了默认文件位置,默认的文件名dump也可以修改,当我们一台服务器上启动了多个redis做主从复制,若要将他们的rdb文件放到同一个文件夹下统一管理,那么就需要修改文件名以区分并避免冲突。
例如下图将主redis服务器的rdb文件命名为dump-master6379.rdb,从机可以命名为dump-slave6380.rdb
其他配置
对性能无特别要求的情况下,以下配置保持默认即可
#后台持久化失败后, 是否停止写操作
stop-writes-on-bgsave-error yes
#是否压缩rdb文件
rdbcompression yes
#保存rdb文件时, 是否校验文件完整性
rdbchecksum yes
#在没有持久性的情况下删除复制中使用的RDB文件,通常情况下保持默认即可。
rdb-del-sync-files no
rdb文件的修复
在进行持久化时,若遇到一些问题导致写入文件的数据错误,可以使用check命令修复
redis-check-rdb --fix 文件名
rdb的备份与恢复
redis在开机时会读取配置文件里dir目录下名为dbfilename的rdb文件,我们可以定期将rdb文件备份到其他地方,当本机的rdb文件损坏或丢失时,只需将备份的rdb文件放到目录下即可
(二)、AOF
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
保存AOF文件的方式
- 保存命令到磁盘
在我们每次执行写操作时,会先将所有的写入命令放到缓冲区中,然后根据相应的更新策略同步到磁盘,将命令追加到aof文件末尾。
- 重写aof文件
由于要记录很多命令,aof文件会比较庞大,因此redis会自动进行文件的重写,对其中的命令进行优化以节省空间。例如,key为“k1“,value值为0,对k1进行100此incr操作,结果为100,此时aof文件中会有100条incr记录,重写时会直接使用一条set k1 100命令替代。
重写的流程:同rdb一样,会先fork一个子进程,子进程开始重写新文件,在此过程中,父进程仍会将新命令放入缓冲区并追加到老文件,防止重写失败丢失数据,待子进程重写完成后,再将缓冲区中的新命令追加到新文件中,最后再将老文件覆盖。
AOF的配置
开启aof
和RDB不同,AOF是默认关闭的,想要使用它,要在配置文件中开启,将其改为yes即可
aof的更新策略
上面说到命令是先被放到缓冲区,然后根据策略再将其同步到磁盘,那么redis提供了三种策略供我们选择
appendfsync always:每次有新命令就同步,最慢也最安全
appendfsync everysec:默认设置,每秒同步一次,也就是最多丢失一秒钟的数据,较快较安全
appendfsync no:由操作系统决定什么时候进行同步,最快也最不安全
建议使用默认设置兼顾速度和安全性,特殊情况下也可以修改为另外两种配置
重写的触发机制
redis会自动帮我们重写aof文件,自然也会有默认的触发条件,在默认配置下,当现有的aof文件大小比上次重写时(如未进行过重写默认为开机时大小)增加了100%,且已经大于64mb,就会触发重写。如数据增长过快不想频繁的触发重写,可以适当调大这两个值
另外默认子进程进行重写时父进程仍会向老文件追加命令,以防止重写失败造成数据丢失,此操作可以在配置文件中关闭,但有可能会损坏数据完整性
混合持久化
aof和rdb同时开启时,重启后只会从aof中恢复数据,速度会慢于从rdb恢复,因此4.0之后,对于aof,redis推出了混合持久化方式,5.0之后默认开启。
开启后,在进行重写时,会将重写前的rdb数据和新的命令组成aof文件,即前面是数据,后面是命令这种形式,重写和恢复速度会更快
其他配置
#aof默认文件名
appendfilename "appendonly.aof"
#指redis在恢复时,会忽略最后一条可能存在问题的指令。默认值yes。即在aof写入时,可能存在指令写错的问题(突然断电,写了一半),这种情况下,yes会log并继续,而no会直接恢复失败
aof-load-truncated yes
aof文件的修复
在进行持久化时,若遇到一些问题导致写入文件的数据错误,可以使用check命令修复
redis-check-aof --fix 文件名
(三)、二者对比
| RDB | AOF | |
|---|---|---|
| 是否默认开启 | 是 | 否 |
| 存储内容 | 数据 | 操作记录(仅写操作) |
| 数据恢复方式 | 读取数据到内存 | 将操作全部执行一遍 |
| 文件体积 | 小 | 大 |
| 故障时数据丢失量 | 多 | 少 |
| 数据恢复速度 | 快 | 慢 |
七、常用配置
以下对配置文件常用选项进行说明,如有错误请指正。
# Redis configuration file example.
# 以指定的redis配置文件启动
#
# ./redis-server /path/to/redis.conf
# 配置单位大小,不区分大小写
#
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
################################## INCLUDES ###################################
# 引入配置文件,在此处引入会被本文件后面的内容覆盖,在本文件最后引入,则会以被引入的文件为主
#
# include /path/to/local.conf
# include /path/to/other.conf
################################## MODULES #####################################
# 启动时加载模块
#
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so
################################## NETWORK #####################################
# 指定监听的ip和端口,redis只会接收来自这些ip端口的请求
#
# 例如:
#
# bind 192.168.1.100 10.0.0.1
# bind 127.0.0.1 ::1
#
# 默认监听本机地址,若设置为空,则接收所有请求
bind 127.0.0.1
# 默认开启保护模式,如果未配置bind绑定其他ip端口,或未设置密码,则reids只会接收本机请求
protected-mode yes
# 默认端口号,单机多开redis做主从复制时需要修改防止冲突
port 6379
# tcp队列中已完成队列的长度
tcp-backlog 511
# 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接。默认值为0,表示不关闭。
timeout 0
# 每隔一段时间向客户端发送请求检测连接是否正常,3.2.1之后默认为300
tcp-keepalive 300
################################# GENERAL #####################################
# 是否以守护进程的形式,即后台启动,默认为no
daemonize no
# 可以通过upstart和systemd管理Redis守护进程
# 选项:
# supervised no - 没有监督互动
# supervised upstart - 通过将Redis置于SIGSTOP模式来启动信号
# supervised systemd - signal systemd将READY = 1写入$ NOTIFY_SOCKET
# supervised auto - 检测upstart或systemd方法基于 UPSTART_JOB或NOTIFY_SOCKET环境变量
supervised no
# 指定pid文件路径,单机多开redis做主从复制时可以修改pid名称以区分
pidfile /var/run/redis_6379.pid
# 设置日志级别,有debug、verbose、notice、warning四个级别,默认为notice
loglevel notice
# log文件日志地址,默认输出到控制台
logfile ""
# 是否把日志输出到系统日志(syslog)中
# syslog-enabled no
# 指定系统日志标识
# syslog-ident redis
# 指定系统日志设备,值必须是USER或者LOCAL0-LOCAL7之间
# syslog-facility local0
# 数据库数量,下标从0开始,默认使用0号库
databases 16
# 启动时展示redis的logo
always-show-logo yes
################################ SNAPSHOTTING ################################
#
# 快照(rdb)更新策略,多少秒内发生了多少次变动,就更新rdb文件。
# 默认的策略有三个,从上到下依次为,900秒(15分钟)改动了1次、00秒(5分钟)改动了10次、60秒(1分钟)改动了一万次。
# 只要满足其中一条,就会重新生成并覆盖rdb文件,可以根据需求修改。如果不想使用,设置为save"",即可
save 900 1
save 300 10
save 60 10000
# 后台持久化失败后, 是否停止写操作
stop-writes-on-bgsave-error yes
# 是否压缩rdb文件
rdbcompression yes
# 保存rdb文件时, 是否校验文件完整性
rdbchecksum yes
# rdb文件名
dbfilename dump.rdb
# 在没有持久性的情况下删除复制中使用的RDB文件,通常情况下保持默认即可。
rdb-del-sync-files no
# rdb文件存放的目录
dir ./
################################# REPLICATION #################################
# 主机ip和端口号,如 replicaof 127.0.0.1 6379
#
# replicaof <masterip> <masterport>
# 如果主机设置了密码,则从机在这里设置
#
# masterauth <master-password>
#
# redis6之后有了acl的新特性,根据用户身份鉴权,此处配置主机中拥有复制权限的用户名
#
# masteruser <username>
# 从机和主机失去连接或正在进行复制时,是否继续响应客户端请求
#
replica-serve-stale-data yes
# 作为从库,是否只读不可写
replica-read-only yes
# 是否使用socket方式复制数据。
# 目前redis复制提供两种方式,disk和socket。
# 如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。
# 有2种方式:
# disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。
# socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。
# disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。
# socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式。
repl-diskless-sync no
# 默认复制等待时间,单位为秒,目的是当有从机连接时,不立刻进行传输,而是等一段时间,若有其他从机连接,则一起复制
repl-diskless-sync-delay 5
# 是否使用无磁盘加载,有三项:
# isabled:不要使用无磁盘加载,先将rdb文件存储到磁盘
# on-empty-db:只有在完全安全的情况下才使用无磁盘加载
# swapdb:解析时在RAM中保留当前db内容的副本,直接从套接字获取数据。
repl-diskless-load disabled
# 从机每隔多久向主机发送ping请求,单位为秒
#
# repl-ping-replica-period 10
# 复制连接的超时时间,单位为秒
#
# repl-timeout 60
# 设置复制缓冲区大小
#
# repl-backlog-size 1mb
# 当主机没有从机时,每隔多长时间释放缓冲区,单位为秒
#
# A value of 0 means to never release the backlog.
#
# repl-backlog-ttl 3600
# 主机挂掉后,根据从机的优先级选出一个从机作为主机,优先级值小的会被选择,默认为100,
replica-priority 100
# 当健康的从机个数小于min-replicas-to-write的值时,主机禁止写入,为0则关闭
#
# min-replicas-to-write 3
# 延迟小于min-slaves-max-lag秒的slave才被认为是健康的slave。
# min-replicas-max-lag 10
################################## SECURITY ###################################
# 设置redis的访问密码
# requirepass foobared
# 修改命令名称,格式为rename-command 命令名 新命令名,若新命令名为空,则表示禁止该命令,如下方示例表示禁用config命令
# rename-command CONFIG ""
################################### CLIENTS ####################################
# redis的最大客户端连接数量,默认为10000
# maxclients 10000
############################## MEMORY MANAGEMENT ################################
# 设置redis的最大内存,为0则无限制,内存满了之后会根据下方maxmemory-policy配置的策略进行删除
# maxmemory <bytes>
# redis的删除策略
# volatile-lru:利用LRU算法移除设置过过期时间的key。
# volatile-random:随机移除设置过过期时间的key。
# volatile-ttl:移除即将过期的key,根据最近过期时间来删除(辅以TTL)
# allkeys-lru:利用LRU算法移除任何key。
# allkeys-random:随机移除任何key。
# noeviction:不移除任何key,只是返回一个写错误。
# 上面的这些驱逐策略,如果redis没有合适的key驱逐,对于写命令,还是会返回错误。
# 默认为noeviction
# maxmemory-policy noeviction
# 使用LRU,LFU或TTL算法时选取的样本数,越多越准确但消耗越大,默认为5
# maxmemory-samples 5
############################## APPEND ONLY MODE ###############################
# 是否开启aof,默认为no
appendonly no
# aof文件名
appendfilename "appendonly.aof"
# aof的更新策略:
# appendfsync always:每次有新命令就同步,最慢也最安全
# appendfsync everysec:默认设置,每秒同步一次,也就是最多丢失一秒钟的数据,较快较安全
# appendfsync no:由操作系统决定什么时候进行同步,最快也最不安全
# appendfsync always
appendfsync everysec
# appendfsync no
# 子进程进行重写时父进程仍会向老文件追加命令,以防止重写失败造成数据丢失,默认为no,即开启
no-appendfsync-on-rewrite no
# aof的重写触发条件,当现有的aof文件大小比上次重写时(如未进行过重写默认为开机时大小)增加了100%,且已经大于64mb,就会触发重写。
# 如数据增长过快不想频繁的触发重写,可以适当调大这两个值
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
#指redis在恢复时,会忽略最后一条可能存在问题的指令。默认值yes。
aof-load-truncated yes
# 是否开启混合持久化,开启后,在进行重写时,会将重写前的rdb数据和新的命令组成aof文件,
# 即前面是数据,后面是命令这种形式,重写和恢复速度会更快
aof-use-rdb-preamble yes
################################ REDIS CLUSTER ###############################
# 是否将该redis服务器作为集群节点使用
# cluster-enabled yes
# 集群节点的配置文件,可以跟路径
# cluster-config-file nodes-6379.conf
# 集群节点的超时时限
# cluster-node-timeout 15000
#master的slave数量大于该值,slave才能迁移到其他孤立master上,
#如这个参数若被设为2,那么只有当一个主节点拥有2 个可工作的从节点时,它的一个从节点才能迁移
# cluster-migration-barrier 1
# 默认为yse吗,集群中有一个节点故障,整个集群停止工作。设置为no可以使一个节点挂了后,其他节点正常使用
# cluster-require-full-coverage yes
# 此选项设置为yes时,可防止主机故障时,从机进行故障转移,但仍可以手动进行故障转移
# cluster-replica-no-failover no
# 是否允许集群在宕机时读取
# cluster-allow-reads-when-down no
八、事务
redis的事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。(注:正常情况下)
简单来说,redis的事务就是将多个命令放到一个队列里面一起执行。
事务相关的命令
| 命令 | 说明 |
|---|---|
| multi | 标记一个事务块的开始。 随后的指令将进入队列等候并在执行exec时作为一个原子执行 |
| exec | 执行事务中所有在排队等待的指令。当使用watch时,只有当被监视的键没有被修改,且允许检查设定机制时,exec会被执行 |
| discard | 取消事务,放弃中所有在排队等待的指令。如果已使用watch,将释放所有被watch的key |
| watch | 标记所有指定的key 被监视起来,在事务中有条件的执行(乐观锁) |
| unwatch | 刷新一个事务中已被监视的所有key。如果执行了exec或discard,则不需要手动执行unwatch |
事务的使用
multi/exec/discard
我们使用先multi命令开启事务,放入k1和k2两个值,查询所有key,然后使用exec命令执行事务。返回值是每条命令相应的值
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> keys *
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) 1) "k2"
2) "k1"
若取消事务,使用discard命令,则队列里面的命令都不执行
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> get k3
(nil)
如果命令入队时,出现了语法错误,那么会直接报错,且所有的命令都不会被执行
这里没有给k4设置值,报了语法错误,k3也没有存入成功
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> set k4
(error) ERR wrong number of arguments for 'set' command
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k3
(nil)
至此,操作都很正常,也符合原子性,然而如果命令语法没错,但执行的时候出错,那么redis就不会把命令全部取消了,这一点跟关系型数据库不同
下面这个例子中,设置完一个字符串类型的k3后,又为其设置list的值,这显然是不合法的,但命令语法上并没有错,因此不会被检测到。然而在执行时,redis虽然返回了这个错误,但之前set k3和之后set k4的操作并没有被取消,而是正常的执行了。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set k3 v3
QUEUED
127.0.0.1:6379> lpush k3 l1 l2 l3
QUEUED
127.0.0.1:6379> set k4 v4
QUEUED
127.0.0.1:6379> exec
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) OK
127.0.0.1:6379> mget k3 k4
1) "v3"
2) "v4"
我们知道,在关系型数据库里,如果事务出错就会回滚,但redis并不会这样,那么官网所说的保证原子性是不是就不正确呢?对于这个问题,官方也给了回答
为什么 Redis 不支持回滚(roll back)
如果你有使用关系式数据库的经验, 那么 “Redis 在事务失败时不进行回滚,而是继续执行余下的命令”这种做法可能会让你觉得有点奇怪。
以下是这种做法的优点:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题。 举个例子, 如果你本来想通过 INCR 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。
根据官方的意思,redis是支持原子性的,因为执行前会检查语法错误,但如果是执行时的错误,那说明是代码的问题,在开发时就应该避免,而不应该让redis去解决。但严格来说,由于错误不回滚机制,它并没有完全的原子性,因此也可以说redis对事务是部分支持的。
watch/unwatch
对于一些高并发的场景来说,我们在将set命令写入事务后到执行前这段时间,其他用户是有可能来修改我们的值的,为了避免冲突,redis提供了基于乐观锁的watch命令来给一个或多个key上锁,防止事务提交前数据被篡改。
使用举例:转账时,user1转账给user2一百元,如果不加锁,转账操作进入事务但还没有执行时,user1将余额全部取出,此时转账事务执行,user1的余额将变成-100,这显然是错误的。那么我们只需要在转账前对user1加锁,若事务执行时发现user1的账户发生了变动,就会取消这次事务,我们可以再次执行直到成功。
127.0.0.1:6379> set user1 1000
OK
127.0.0.1:6379> set user2 1000
OK
127.0.0.1:6379> watch user1
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> decrby user1 100
QUEUED
127.0.0.1:6379> incrby user2 100
QUEUED
127.0.0.1:6379> exec
1) (integer) 900
2) (integer) 1100
exec命令或discard命令执行后,watch会自动解除,如果我们想手动解除,可以使用unwatch命令取消所有的监控
九、主从复制
出于政治正确,master-slave 架构的描述现在改为了master-replica,包括配置文件在内某些地方的关键字也进行了修改(slave修改为了replica)
基本概念
主从复制,即一台主服务器,一台或多台从服务器,对主服务器的写操作将同步到所有从服务器上。有了主从复制后,数据备份更加方便,而且可以进行读写分离,提高负载。当某一台服务器挂了之后,其他服务器也可以快速接替。
配置示例
-
配置主从服务器
本文演示中,是在一台虚拟机上配置1台主机,2台从机,目录如下
#在redis-6.0.6目录下复制配置文件到config目录,6379是主机,6380和6381为从机 [root@192 redis-6.0.6]# cp redis.conf ../config/redis-6379.conf [root@192 redis-6.0.6]# cp redis.conf ../config/redis-6380.conf [root@192 redis-6.0.6]# cp redis.conf ../config/redis-6381.conf #编辑配置文件,以主机配置文件为例 [root@192 redis-6.0.6]# vim ../config/redis-6379.conf主从配置文件中都需要修改的部分(如果是多台机器,每台机器上一个redis,可以不用全部配置):
-
后台启动
daemonize yes -
pid文件名。主机为redis_6379.pid,从机依次改为redis_6380.pid、redis_6381.pid
pidfile /var/run/redis_6379.pid -
端口号。主服务器使用默认6379,从服务器修改为6380和6381
port 6379 -
log文件位置和名称。位置都相同,从机改为redis-6380.log和redis-6381.log
logfile "/usr/local/mysoftware/redis/log/redis-6379.log" -
rdb文件名和位置。两个从机修改为dump-6380.rdb和dump-6381.rdb,位置都相同
dbfilename dump-6379.rdb dir /usr/local/mysoftware/redis/rdbfile/
配置完成后,三台redis服务器并没有关联,因此我们还需要告诉从机主机是谁
从机配置文件中需要单独修改的内容
-
要主机的端口号和ip
replicaof 127.0.0.1 6379
配置完成,接下来我们测试一下
-
-
测试主从服务器
分别启动三台服务器,在主服务器设置k1的值,在从服务器中取
[root@192 config]# redis-server /usr/local/mysoftware/redis/config/redis-6379.conf [root@192 config]# redis-server /usr/local/mysoftware/redis/config/redis-6380.conf [root@192 config]# redis-server /usr/local/mysoftware/redis/config/redis-6381.conf [root@192 config]# redis-cli -p 6379 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> shutdown not connected> exit [root@192 config]# redis-cli -p 6380 127.0.0.1:6380> get k1 "v1" 127.0.0.1:6380> SHUTDOWN not connected> exit [root@192 config]# redis-cli -p 6381 127.0.0.1:6381> get k1 "v1"
配置主从关系除了可以在配置文件中配置,还可以使用replicaof或slaveof命令手动配置,使用info replication命令查看主从配置信息
127.0.0.1:6380> replicaof 127.0.0.1 6379
OK Already connected to specified master
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:364
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:8d8f72fa68a09f071cccf5eb6af7d89fd15e664c
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:364
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:364
使用replicaof no one或slaveof no one命令可以取消与主机的连接
同步机制
当从机连接上主机时,会复制主机的全部数据
当主机故障时,从机仍会保持主从关系,主机恢复时自动连接(默认)
当从机故障,恢复后,如果是使用命令配置的主从关系会失效,配置文件配置的仍会生效
从机也可以有从机,此时它的角色还是从机,仍不可读,从主机复制的数据会向从机传递
- 当一个 master 实例和一个 slave 实例连接正常时, master 会发送一连串的命令流来保持对 slave 的更新,以便于将自身数据集的改变复制给 slave , 包括客户端的写入、key 的过期或被逐出等等。
- 当 master 和 slave 之间的连接断开之后,因为网络问题、或者是主从意识到连接超时, slave 重新连接上 master 并会尝试进行部分重同步:这意味着它会尝试只获取在断开连接期间内丢失的命令流。
- 当无法进行部分重同步时, slave 会请求进行全量重同步。这会涉及到一个更复杂的过程,例如 master 需要创建所有数据的快照,将之发送给 slave ,之后在数据集更改时持续发送命令流到 slave 。
注意:即使使用了主从复制,也应该开启主从机的持久化。如果主机持久化未开启,那么假如发生了故障,数据被清空,重启后从机会同步空的主机数据,导致从机的数据也全部变成空
复制原理
Redis 复制功能是如何工作的
每一个 Redis master 都有一个 replication ID :这是一个较大的伪随机字符串,标记了一个给定的数据集。每个 master 也持有一个偏移量,master 将自己产生的复制流发送给 slave 时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新 slave 的状态。复制偏移量即使在没有一个 slave 连接到 master 时,也会自增,所以基本上每一对给定的Replication ID, offset都会标识一个 master 数据集的确切版本。当 slave 连接到 master 时,它们使用 PSYNC 命令来发送它们记录的旧的 master replication ID 和它们至今为止处理的偏移量。通过这种方式, master 能够仅发送 slave 所需的增量部分。但是如果 master 的缓冲区中没有足够的命令积压缓冲记录,或者如果 slave 引用了不再知道的历史记录(replication ID),则会转而进行一个全量重同步:在这种情况下, slave 会得到一个完整的数据集副本,从头开始。
下面是一个全量同步的工作细节:
master 开启一个后台保存进程,以便于生产一个 RDB 文件。同时它开始缓冲所有从客户端接收到的新的写入命令。当后台保存完成时, master 将数据集文件传输给 slave, slave将之保存在磁盘上,然后加载文件到内存。再然后 master 会发送所有缓冲的命令发给 slave。这个过程以指令流的形式完成并且和 Redis 协议本身的格式相同。
你可以用 telnet 自己进行尝试。在服务器正在做一些工作的同时连接到 Redis 端口并发出 SYNC 命令。你将会看到一个批量传输,并且之后每一个 master 接收到的命令都将在 telnet 回话中被重新发出。事实上 SYNC 是一个旧协议,在新的 Redis 实例中已经不再被使用,但是其仍然向后兼容:但它不允许部分重同步,所以现在 PSYNC 被用来替代 SYNC。
之前说过,当主从之间的连接因为一些原因崩溃之后, slave 能够自动重连。如果 master 收到了多个 slave 要求同步的请求,它会执行一个单独的后台保存,以便于为多个 slave 服务。
哨兵模式
简介
前面已经配置了主从关系,多台机器可以保证主机故障后从机能替代,大大提高容错性,然而这个操作需要手动指定新的主服务器并重新配置主从关系,我们并不能保证随时有人处理,好在redis提供了哨兵模式来进行这个自动化操作。
哨兵模式的作用:开启哨兵服务会在后台开启一个进程,它会自动进行以下操作
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
演示
下面演示下哨兵模式的实际效果
首先启动上面做主从复制的三台服务器
[root@192 config]# redis-server /usr/local/mysoftware/redis/config/redis-6379.conf
[root@192 config]# redis-server /usr/local/mysoftware/redis/config/redis-6380.conf
[root@192 config]# redis-server /usr/local/mysoftware/redis/config/redis-6381.conf
在config下新建sentinel文件夹,并在sentinel文件夹下新建sentinel.conf配置文件(这是个公共配置文件,前面配置三台主从服务器也可以用这种方式)
[root@192 sentinel]# vim sentinel.conf
写入以下内容
# 设置后台启动
daemonize yes
# 设置被监控的主机,其中mymaster是自定义主机的名称,之后是主机的ip和端口号,最后的2表示至少需要两个哨兵同意才能判断为当前主机故障,然后进行故障迁移
sentinel monitor mymaster 127.0.0.1 6379 2
# 设置多少毫秒内主机无响应或回复错误,会标记为主观下线
sentinel down-after-milliseconds mymaster 60000
# 执行故障转移的最大等待时间
sentinel failover-timeout mymaster 180000
# 在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。
# 如果所有的从机都进行故障转移,那么在这个时间段内将没有从机响应读操作
sentinel parallel-syncs mymaster 1
然后创建三个哨兵的单独配置文件,分别为sentinel-26379.conf、sentinel-26380.conf、sentinel-26381.conf,以下以sentinel-26379.conf为例
vim sentinel-26379.conf
配置以下内容,后面两个依次将26379替换为为26380和23681
# 引入公共配置文件
include /usr/local/mysoftware/redis/config/sentinel/sentinel.conf
# 端口号
port 26379
# 进程id
pidfile /var/run/redis-sentinel_26379.pid
# 日志位置和内容
logfile "/usr/local/mysoftware/redis/log/sentinel_26379.log"
最后启动三个哨兵。可以使用redis-sentinel /path/to/sentinel.conf或redis-server /path/to/sentinel.conf --sentinel的方式启动。
[root@192 sentinel]# redis-sentinel /usr/local/mysoftware/redis/config/sentinel/sentinel-26379.conf
[root@192 sentinel]# redis-sentinel /usr/local/mysoftware/redis/config/sentinel/sentinel-26380.conf
[root@192 sentinel]# redis-sentinel /usr/local/mysoftware/redis/config/sentinel/sentinel-26381.conf
查看进程看是否启动成功
[root@192 sentinel]# ps -ef|grep sentinel
root 4510 1 0 20:26 ? 00:00:00 redis-sentinel *:26379 [sentinel]
root 4603 1 0 20:26 ? 00:00:00 redis-sentinel *:26380 [sentinel]
root 4699 1 0 20:26 ? 00:00:00 redis-sentinel *:26381 [sentinel]
root 5282 122918 0 20:26 pts/0 00:00:00 grep --color=auto sentinel
接下来我们把主机6379用shutdown关掉,模拟故障场景
[root@192 sentinel]# redis-cli -p 6379
127.0.0.1:6379> shutdown
not connected> exit
在没配置哨兵之前,两台从服务器会一直等待主机重新上线,现在我们进入从机6380的控制台,看它是否已经被哨兵选为了新主机
[root@192 sentinel]# redis-cli -p 6380
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=133613,lag=0
可以看到现在6380的角色已经变为了master,并且6381也将主机更换为了他,现在我们重新启动6379。
[root@192 sentinel]# redis-server /usr/local/mysoftware/redis/config/redis-6379.conf
[root@192 sentinel]# redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6380
可以看到新上线的6379并没有按照我们的配置文件再次成为主机,而是成为了新的被推选出来的主机6380的从机
哨兵模式的简单演示完成了,我们很清楚的看到了它的效果,那么它是怎么做到全程自动化的呢?
原理
监视
简单概括:
当我们启动了哨兵服务后,每个哨兵(Sentinel )会通过配置文件得知需要监控的主服务器,之后会询问主服务器得到它下面的从服务器,同时哨兵之间会自动发现彼此。即每个哨兵都会监视所有的主从服务器,然后通过哨兵间的自动发现进行交流(如主机故障认定和新主机的选举)
官网详细说明:
一个 Sentinel 可以与其他多个 Sentinel 进行连接, 各个 Sentinel 之间可以互相检查对方的可用性, 并进行信息交换。
你无须为运行的每个 Sentinel 分别设置其他 Sentinel 的地址, 因为 Sentinel 可以通过发布与订阅功能来自动发现正在监视相同主服务器的其他 Sentinel , 这一功能是通过向频道 sentinel:hello 发送信息来实现的。
与此类似, 你也不必手动列出主服务器属下的所有从服务器, 因为 Sentinel 可以通过询问主服务器来获得所有从服务器的信息。
- 每个 Sentinel 会以每两秒一次的频率, 通过发布与订阅功能, 向被它监视的所有主服务器和从服务器的 sentinel:hello 频道发送一条信息, 信息中包含了 Sentinel 的 IP 地址、端口号和运行 ID (runid)。
- 每个 Sentinel 都订阅了被它监视的所有主服务器和从服务器的 sentinel:hello 频道, 查找之前未出现过的 sentinel (looking for unknown sentinels)。 当一个 Sentinel 发现一个新的 Sentinel 时, 它会将新的 Sentinel 添加到一个列表中, 这个列表保存了 Sentinel 已知的, 监视同一个主服务器的所有其他 Sentinel 。
- Sentinel 发送的信息中还包括完整的主服务器当前配置(configuration)。 如果一个 Sentinel 包含的主服务器配置比另一个 Sentinel 发送的配置要旧, 那么这个 Sentinel 会立即升级到新配置上。
- 在将一个新 Sentinel 添加到监视主服务器的列表上面之前, Sentinel 会先检查列表中是否已经包含了和要添加的 Sentinel 拥有相同运行 ID 或者相同地址(包括 IP 地址和端口号)的 Sentinel , 如果是的话, Sentinel 会先移除列表中已有的那些拥有相同运行 ID 或者相同地址的 Sentinel , 然后再添加新 Sentinel 。
故障恢复
-
判断主机下线
简单概括:
每个哨兵都会定期向主从服务器和其他哨兵发送ping命令,如果超时未回复,则此哨兵主观认为该服务器已下线(主观下线),如果多个哨兵(我们在上面配置文件中配置的数量为2)都观察到该服务器下线,那么该服务器的状态将变为客观下线,之后将会进行故障转移,选举出新的主服务器
官网详细说明:
- 每个 Sentinel 以每秒钟一次的频率向它所知的主服务器、从服务器以及其他 Sentinel 实例发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被 Sentinel 标记为主观下线。 一个有效回复可以是: +PONG 、 -LOADING 或者 -MASTERDOWN 。
- 如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态。
- 如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令。 当一个主服务器被 Sentinel 标记为客观下线时, Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。 当主服务器重新向 Sentinel 的 PING 命令返回有效回复时, 主服务器的主观下线状态就会被移除。
前面说过, Redis 的 Sentinel 中关于下线(down)有两个不同的概念:
- 主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
- 客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内, 对向它发送 PING 命令的 Sentinel 返回一个有效回复(valid reply), 那么 Sentinel 就会将这个服务器标记为主观下线。
服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
- 返回 +PONG 。
- 返回 -LOADING 错误。
- 返回 -MASTERDOWN 错误。
如果服务器返回除以上三种回复之外的其他回复, 又或者在指定时间内没有回复 PING 命令, 那么 Sentinel 认为服务器返回的回复无效(non-valid)。
注意, 一个服务器必须在 master-down-after-milliseconds 毫秒内, 一直返回无效回复才会被 Sentinel 标记为主观下线。
举个例子, 如果 master-down-after-milliseconds 选项的值为 30000 毫秒(30 秒), 那么只要服务器能在每 29 秒之内返回至少一次有效回复, 这个服务器就仍然会被认为是处于正常状态的。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议: 如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。 如果之后其他 Sentinel 不再报告主服务器已下线, 那么客观下线状态就会被移除。
客观下线条件只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
只要一个 Sentinel 发现某个主服务器进入了客观下线状态, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对失效的主服务器执行自动故障迁移操作。
-
投票选出新的主服务器
简单概括:
主机故障后,哨兵之间要先选出一个领头哨兵,让其进行故障转移操作。
选出后,领头哨兵要根据条件选举出新的主机,而条件有三个,优先级从大到小依次为
- 从机配置文件中的优先级。即配置文件REPLICATION项中的replica-priority 100,默认都是一百,数值小的优先
- 偏移量。如果从机的优先级都是默认100,那么会使用偏移量进行判断。指的是主节点向从节点同步数据的偏移量,越大表示该从机同步的数据越多
- runid。如果偏移量也一样,则会使用每个redis实例启动时生成的runid进行判断,数值小越小说明启动的越早,优先级越高
新主机被推选出后,领头哨兵会向其他从机发出命令,使他们跟随新的主机,若故障的主机重新上线,同样让它跟随新的主机,此外还会通知其他哨兵更新配置。
需要注意的是,以上操作是持久化的,这些操作将会被写入到各个主从服务器和哨兵的配置文件末尾,将初始设置覆盖,即使重启,也会是进行了故障恢复后的关系,而不是我们最开始的配置
我们可以打开哨兵的配置文件验证一下
# 引入公共配置文件 include /usr/local/mysoftware/redis/config/sentinel/sentinel.conf # 端口号 port 26379 # 进程id pidfile "/var/run/redis-sentinel_26379.pid" # 日志位置和内容 logfile "/usr/local/mysoftware/redis/log/sentinel_26379.log" # 以下是后来自动添加的内容 # Generated by CONFIG REWRITE daemonize yes protected-mode no user default on nopass ~* +@all dir "/usr/local/mysoftware/redis/config/sentinel" sentinel myid 538650a37e9f80202306f881a2b835240d8bf077 sentinel deny-scripts-reconfig yes sentinel monitor mymaster 127.0.0.1 6380 2 sentinel down-after-milliseconds mymaster 60000 sentinel config-epoch mymaster 1可以看到倒数第三行重新配置了6380为主机,而我们一开始在公共配置文件里面配置的是6379。那么重启时,将会覆盖之前的配置
打开端口号为6379服务器的配置文件,最开始我们设置它为主机,翻到最后,会发现添加了一行使其成为了6380的从机
replicaof 127.0.0.1 6380如果打开6380的配置文件,则会发现之前配置的replicaof 127.0.0.1 6379这行已经被删掉了。
官网详细说明:
故障转移
一次故障转移操作由以下步骤组成:
- 发现主服务器已经进入客观下线状态。
- 对我们的当前纪元进行自增(详情请参考 Raft leader election ), 并尝试在这个纪元中当选。
- 如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。 如果当选成功, 那么执行以下步骤。
- 选出一个从服务器,并将它升级为主服务器。
- 向被选中的从服务器发送
SLAVEOF NO ONE命令,让它转变为主服务器。 - 通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
- 向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
- 当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。
Sentinel 使用以下规则来选择新的主服务器:
- 在失效主服务器属下的从服务器当中, 那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被淘汰。
- 在失效主服务器属下的从服务器当中, 那些与失效主服务器连接断开的时长超过 down-after 选项指定的时长十倍的从服务器都会被淘汰。
- 在经历了以上两轮淘汰之后剩下来的从服务器中, 我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器; 如果复制偏移量不可用, 或者从服务器的复制偏移量相同, 那么带有最小运行 ID 的那个从服务器成为新的主服务器。
Sentinel 自动故障迁移的一致性特质
Sentinel 自动故障迁移使用 Raft 算法来选举领头(leader) Sentinel , 从而确保在一个给定的纪元(epoch)里, 只有一个领头产生。
这表示在同一个纪元中, 不会有两个 Sentinel 同时被选中为领头, 并且各个 Sentinel 在同一个纪元中只会对一个领头进行投票。
更高的配置纪元总是优于较低的纪元, 因此每个 Sentinel 都会主动使用更新的纪元来代替自己的配置。
简单来说, 我们可以将 Sentinel 配置看作是一个带有版本号的状态。 一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他 Sentinel 。
举个例子, 当出现网络分割(network partitions)时, 一个 Sentinel 可能会包含了较旧的配置, 而当这个 Sentinel 接到其他 Sentinel 发来的版本更新的配置时, Sentinel 就会对自己的配置进行更新。
如果要在网络分割出现的情况下仍然保持一致性, 那么应该使用 min-slaves-to-write 选项, 让主服务器在连接的从实例少于给定数量时停止执行写操作, 与此同时, 应该在每个运行 Redis 主服务器或从服务器的机器上运行 Redis Sentinel 进程。
Sentinel 状态的持久化
Sentinel 的状态会被持久化在 Sentinel 配置文件里面。
每当 Sentinel 接收到一个新的配置, 或者当领头 Sentinel 为主服务器创建一个新的配置时, 这个配置会与配置纪元一起被保存到磁盘里面。
这意味着停止和重启 Sentinel 进程都是安全的。
十、集群
在我们配置完主从服务器外加哨兵模式后,redis已经具备了读写分离、故障自动恢复的功能。一般来说,数据库的压力大部分来自于读操作,因此我们可以增加从机来应对(垂直扩容),然而,当数据量很大时,写操作的压力也不容忽视,在只有一个master的情况下,可能会出现瓶颈,那么我们是否可以像多个从机一样,配置多个主机(水平扩容)来应对呢?答案是肯定的,redis提供了集群来解决这个问题。
基本概念
首先集群是要基于主从复制和哨兵模式的,在主从复制中,是一主机多从机的模式,而集群则是在此基础上,添加了多个主机,组成了多主机多从机的模式。例如,我们可以在一个集群中配置三台主机,每台主机又各有一台从机,而数据则分布的存储于三台主机和它们的从机上。其中,每台主机和它的从机被称之为集群中的一个节点(node)。需要注意的是,和主从复制不同,从机仅仅是主机的备份,不支持读操作。
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。它可以自动分割数据到不同的节点上,使得整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
简单来说就是一个集群中有多个节点,每个节点负责存储一部分内容,整个集群才是一个完整的数据库。
配置示例
接下来我们使用六台redis服务器来组成一个三主三从的集群(一个redis集群至少要包含三个主节点)
在redis目录下创建cluster-test文件夹,创建7000到7005六个文件夹用于存放六台redis服务器的数据,复制redis自带的默认配置文件到cluster-test目录下,一会让它成为所有服务器的公共配置文件。开始配置redis服务器,以7000为例,在7000目录下创建并编辑redis-7000.conf
[root@192 redis]# mkdir cluster-test
[root@192 redis]# cd cluster-test
[root@192 cluster-test]# mkdir 7000 7001 7002 7003 7004 7005
[root@192 cluster-test]# cp ../redis-6.0.6/redis.conf ./
[root@192 cluster-test]# cd 7000
[root@192 7000]# vim redis-7000.conf
写入以下内容,其他五台同理,只需要修改目录和端口号、文件名即可
# 引入公共配置文件
include /usr/local/mysoftware/redis/cluster-test/redis.conf
# 端口号
port 7000
# 后台启动
daemonize yes
# pid名称
pidfile "/var/run/redis-7000.pid"
# log文件位置、名称
logfile "/usr/local/mysoftware/redis/cluster-test/7000/redis-7000.log"
# rdb文件名
dbfilename dump-7000.rdb
# rdb文件位置
dir /usr/local/mysoftware/redis/cluster-test/7000/
################################ 集群配置 ################################
# 开启集群模式
cluster-enabled yes
# 保存节点配置文件的路径
cluster-config-file /usr/local/mysoftware/redis/cluster-test/7000/nodes-7000.conf
# 集群节点的超时时限
cluster-node-timeout 15000
# 开启aof
appendonly yes
将所有的配置文件修改好了后启动这六台服务器,由于我们在上面的配置文件中已经制定了运行时会生成的配置文件的位置,因此启动目录可以随意。
[root@192 cluster-test]# redis-server ./7000/redis-7000.conf
[root@192 cluster-test]# redis-server ./7001/redis-7001.conf
[root@192 cluster-test]# redis-server ./7002/redis-7002.conf
[root@192 cluster-test]# redis-server ./7003/redis-7003.conf
[root@192 cluster-test]# redis-server ./7004/redis-7004.conf
[root@192 cluster-test]# redis-server ./7005/redis-7005.conf
接下来我们要让现在相互独立的redis服务器组成一个集群,注意,坑来了,按照中文官网文档
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
这个命令是ruby脚本,理所当然需要安装ruby环境,装完之后再次执行,会提示以下信息
WARNING: redis-trib.rb is not longer available!
You should use redis-cli instead.
All commands and features belonging to redis-trib.rb have been moved
to redis-cli.
In order to use them you should call redis-cli with the --cluster
option followed by the subcommand name, arguments and options.
Use the following syntax:
redis-cli --cluster SUBCOMMAND [ARGUMENTS] [OPTIONS]
Example:
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
To get help about all subcommands, type:
redis-cli --cluster help
大意是使用ruby脚本启动集群的这种方式现在已经改了(从redis5开始改的,redis3、4版本还是这种方式),被挪到了redis-cli里面,所以我们可以使用下面这个命令来启动集群。(英文官网里有关于这个说明,中文官网没有更新......)
# --cluster-replicas 1表示为每一个主机分配一个从机
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
启动成功后,会出现以下信息
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7004 to 127.0.0.1:7000
Adding replica 127.0.0.1:7005 to 127.0.0.1:7001
Adding replica 127.0.0.1:7003 to 127.0.0.1:7002
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: e0253ee292c3340352b9db3823d69b5767c1d167 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
M: ccb17cc4a01b33d8f220f737f3a709d3bb4dd0d4 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
M: dd27258adb7ccb2a0e00a25d9f0ba6e8255ee55c 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
S: 36147ef6659afc61b34cafb749268a212b0ff8d6 127.0.0.1:7003
replicates ccb17cc4a01b33d8f220f737f3a709d3bb4dd0d4
S: a0f4df3a7281a48dae7ac1fb8c1d704cfc5a4efb 127.0.0.1:7004
replicates dd27258adb7ccb2a0e00a25d9f0ba6e8255ee55c
S: 0c29e3261bcd309bab7811d9bf8765d9d531fa52 127.0.0.1:7005
replicates e0253ee292c3340352b9db3823d69b5767c1d167
Can I set the above configuration? (type 'yes' to accept): yes
可以看到自动完成的了主从机关系的配置,7000到7001被设置成了主机,后面的slots意为插槽,是存放数据的依据,后面会说到。7003到7005为从机,replicates 后面的一长串字符串和上面的主机id对应
最后问我们是否同意以上的配置,输入yes表示同意,会按照以上配置启动集群,如果输入了yes以外的字符,则会退出,重新执行创建集群命令,主从配置的关系可能会发生变化。
输入yes集群启动成功
使用ps命令查看redis进程,六台服务器都在运行
[root@192 src]# ps -ef|grep redis
root 12347 1 0 18:18 ? 00:00:08 redis-server 127.0.0.1:7000 [cluster]
root 13151 1 0 18:19 ? 00:00:08 redis-server 127.0.0.1:7001 [cluster]
root 13334 1 0 18:19 ? 00:00:09 redis-server 127.0.0.1:7002 [cluster]
root 13458 1 0 18:19 ? 00:00:09 redis-server 127.0.0.1:7003 [cluster]
root 13596 1 0 18:19 ? 00:00:08 redis-server 127.0.0.1:7004 [cluster]
root 13706 1 0 18:19 ? 00:00:08 redis-server 127.0.0.1:7005 [cluster]
root 15507 1553 0 20:14 pts/0 00:00:00 grep --color=auto redis
使用redis-cli命令进入控制台进行存取测试
# -c表示使用集群方式进入
[root@192 src]# redis-cli -c -p 7000
# 我们进入的是7000的控制台,存入了一个数据
127.0.0.1:7000> set k1 v1
# 这里根据插槽重定向到了7002,回头看我们启动时的信息,7002被分配的插槽范围是10923-16383
# M: dd27258adb7ccb2a0e00a25d9f0ba6e8255ee55c 127.0.0.1:7002 slots:[10923-16383] (5461 slots) master
# k1的插槽值为12706,因此被存到了7002
-> Redirected to slot [12706] located at 127.0.0.1:7002
OK
# 由于是以集群方式启动的,控制台同样被切换到了7002
127.0.0.1:7002> set k2 v2
-> Redirected to slot [449] located at 127.0.0.1:7000
OK
127.0.0.1:7000> set k3 v3
OK
127.0.0.1:7000> set k4 v4
-> Redirected to slot [8455] located at 127.0.0.1:7001
OK
127.0.0.1:7001> set k5 v5
-> Redirected to slot [12582] located at 127.0.0.1:7002
OK
127.0.0.1:7002> get k1
# 此时k1是位于7002内的,因此没有发生切换
"v1"
127.0.0.1:7002> get k2
# k2的值被存储在7000中,因此取值的请求同样被重定向到7000
-> Redirected to slot [449] located at 127.0.0.1:7000
"v2"
127.0.0.1:7000>
可以使用cluster nodes命令查看集群的节点信息。包含主从关系和节点分配情况
127.0.0.1:7000> cluster nodes
36147ef6659afc61b34cafb749268a212b0ff8d6 127.0.0.1:7003@17003 slave ccb17cc4a01b33d8f220f737f3a709d3bb4dd0d4 0 1612528109292 2 connected
0c29e3261bcd309bab7811d9bf8765d9d531fa52 127.0.0.1:7005@17005 slave e0253ee292c3340352b9db3823d69b5767c1d167 0 1612528108000 1 connected
a0f4df3a7281a48dae7ac1fb8c1d704cfc5a4efb 127.0.0.1:7004@17004 slave dd27258adb7ccb2a0e00a25d9f0ba6e8255ee55c 0 1612528108273 3 connected
dd27258adb7ccb2a0e00a25d9f0ba6e8255ee55c 127.0.0.1:7002@17002 master - 0 1612528108000 3 connected 10923-16383
e0253ee292c3340352b9db3823d69b5767c1d167 127.0.0.1:7000@17000 myself,master - 0 1612528107000 1 connected 0-5460
ccb17cc4a01b33d8f220f737f3a709d3bb4dd0d4 127.0.0.1:7001@17001 master - 0 1612528108782 2 connected 5461-10922
运行机制
由此我们可以看出redis集群的工作方式:
一个redis集群中一共有16384个插槽(为什么是这个数字?参见https://www.cnblogs.com/rjzheng/p/11430592.html,注意,这里并不是说集群中只能放16384个键,一个插槽可以对应多个键,并不是一对一的关系),每个节点负责其中的一部分,在我们上面的演示中,7000被分配的是0-5460号插槽,7001是5461到10922,7002是10923到16383。若有n个节点,那么每个节点将负责n/1个插槽
当我们存入数据时,集群会使用CRC16(key)%16384计算出当前key属于哪个插槽,并根据插槽值将其存入对应的节点主机,取值同样根据这种方式得出需要到哪个节点主机处取
需要注意的是,使用类似mset,mget这种多值操作时,由于要存(取)的值不一定在一个插槽内,因此会报错。存值时,可以通过在key后加{组名}的方式保证一个组里的key存在同一个地方,其实就是将这些key都对应一个插槽
# 多数据不在同一个主机内会报错
127.0.0.1:7002> mget k1 k2
(error) CROSSSLOT Keys in request don't hash to the same slot
127.0.0.1:7002> set groupkey1{test} v1
-> Redirected to slot [6918] located at 127.0.0.1:7001
OK
# 使用设置组的方式会放在同一个主机内,因为同一个组中的数据对应的插槽是一样的
127.0.0.1:7001> set groupkey2{test} v2
OK
127.0.0.1:7001> set groupkey3{test} v3
OK
下面是关于插槽数据的三个命令
# cluster keyslot <key> 计算key的插槽
127.0.0.1:7001> cluster keyslot k1
(integer) 12706
# cluster countkeysinslot <插槽值> 查询该插槽下有几个key
127.0.0.1:7001> cluster countkeysinslot 6918
(integer) 3
# cluster getkeysinslot <插槽值> <要查询的数量> 查询该插槽值下一个或多个值
127.0.0.1:7001> cluster getkeysinslot 6918 3
1) "groupkey1{test}"
2) "groupkey2{test}"
3) "groupkey3{test}"
虽然集群是有多个节点的,但只要有一个节点挂了,就会有一部分插槽无法使用,redis默认只有在插槽完整的情况下才能正常使用,因此就算只挂了一个节点(节点主机挂了之后从机会上位,该节点下的主从机全都挂了整个节点才算挂掉),整个集群也会无法运行,可以在配置文件中修改,使的剩余节点可以继续工作
# 默认为yse,设置为no可以使一个节点挂了后,其他节点正常使用
cluster-require-full-coverage yes
节点操作
集群运行后,我们仍可以对节点进行操作
增加节点
和上面配置的六个redis服务器相同,再配置一台服务器并启动,使用cluster meet命令将新服务器添加到集群中来,被添加进来的服务器默认为master,但是不会再被分配插槽
cluster meet ip port
修改节点身份
将一个redis服务器指定为id为node-id的主机的从机,node-id就是开启集群时为所有服务器分配的一长串字符串,如主机7000的id就是e0253ee292c3340352b9db3823d69b5767c1d167
M: e0253ee292c3340352b9db3823d69b5767c1d167 127.0.0.1:7000
slots:[0-5460] (5461 slots) master
如果需要被设置为从机的服务器是主机,那么要满足以下条件才可以
- 该节点不保存任何hash槽
- 该节点是空的,key空间中不存储任何键
cluster replicate node-id
移除节点
将id为node-id的节点移除,被删除的节点无法被再次添加进来
cluster forget node-id
查看节点信息
cluster info查看集群的参数信息
cluster nodes查看集群的节点信息
cluster info
cluster nodes



