


javaweb中的乱码问题
0.为什么需要编码,解码,
无论是图片,文档,声音,在网络IO,磁盘io中都是以字节流的方式存在及传递的,但是我们拿到字节流怎么解析呢?这句话就涉及了编码,解码两个过程,从字符数据转化为字节数据就是编码,从字节数据转化为字符数据是解码,可能有人疑问,一个字符不是一个字节,两个字节吗?一堆字符不就是一堆字节吗,需要转什么?好,刚才所说 的以及涉及到编码了,有的编码是一个字节一个字符,就像ASCII码,但是汉字以及其他语言文字太多,很明显一个字节不能表示所有字符,所以才会引申出如 此多的编码,现在主要讨论ISO-8859-1,utf-8,gbk ,其中iso-8859编码是无法对中文进行编码的
String ISO =
"ISO-8859-1";
String UTF = "UTF-8";
String GBK = "GBK";
String string = "很开心分享经验";
byte[] bytes = string.getBytes(ISO);
System.out.println("结果:"+new
String(bytes,ISO));
for(byte b:bytes){
System.out.print(b+" ");
}

ISO只要遇到不认识的字符,都会将其用63表示,显示出来,也就是 ? 所有的都变成了问号 这里可以看到六个中文对应6个 ?
顺便说一下,英文不会涉及iso,utf-8,gbk,编码问题,因为英文可以用ASCII码表示,这几种编码对ASCII码兼容
String string = "很开心分享经验 happy the world";

32代表 空格
utf-8编解码
String ISO = "ISO-8859-1";
String UTF = "UTF-8";
String GBK = "GBK";
String string = "很开心分享经验";
byte[] bytes = string.getBytes(UTF);
System.out.println("结果:"+new String(bytes,UTF));
for(byte b:bytes){
System.out.print(b+" ");
}

可以看到 编码没有问题,而且每个汉字占用三个字节 ,一共21个(UTF-16一共占用16个)
GBK编码
代码省略了

编解码还是没有问题, 但是每个汉字占用 两个字节,一共14个
我们知道了,只要遇到一大堆??????这样的乱码,一般可以确认,有一个地方用到了iso的编码,这是中文不能使用的编码除此之外,我们还会看到很多种其他的乱码例如:
- 1. 寰堝紑蹇冨垎浜粡楠�
2. 2. �ܿ��ķ��?��
3. ºÜ¿ªÐÄ·ÖÏí¾Ñé
4. 很开心分享ç»éª
这四种乱码,好像都不一样哦,各有各的风采,然而并看不懂。
1. 寰堝紑蹇冨垎浜粡楠� UTF-GBK
2. �ܿ��ķ��?�� GBK-UTF
3. ºÜ¿ªÐÄ·ÖÏí¾Ñé GBK-ISO
4. 很开心分享ç»éª UTF-ISO
(5 裥벀菥袆ꯧ뮏� utf-8 ---utf-16
)
这四种分别对应,不同的编码-解码 例如第一个 很开心分享经验 用utf-8编码后,gbk解码后 就变成了这坨 寰堝紑蹇冨垎浜粡楠� ,剩下三坨不多说
现在总结下(一次编解码):
1. 只要是iso对中文字符编码就一定是一大堆?????,为什么呢,因为我们说了iso把不认识的都转成63 63是什么在ASCII码中是? 而这些编码基本都兼容ASCII,所以
只要是一大坨???????就一定有一个地方采用的是iso编码,而后面还会说道iso编码是很多地方的默认编码(默认的为什么不是utf-8,,郁闷!!!)
2 当我们看到乱码之后,不要慌,第一步先不要想在哪里出现编码问题,先考虑 可能是哪一种编解码 错误。而这种错误是有章可循的。上边内四个基本差不多,(如果还有发现别的,我会再加上)
那么如果出现其他好多次编解码呢? 那这个问题就复杂的多了
1 .String ISO = "ISO-8859-1";
String UTF = "UTF-8";
String GBK = "GBK";
String string = "很开心分享经验";
byte[] bytes = string.getBytes(UTF);
String string2 = new String(bytes,ISO);
byte[] bytes2 = string2.getBytes(ISO);
String string3 = new String(bytes2,UTF);
System.out.println("结果:"+string3);

UTF编码,iso解码,ios解码,utf-8解码 中间经历了曲折,但是,最终由变成了 中文,好艰难
但是我们应该为此庆幸吗? 我觉得不能,你最好也这么觉得,所有的编解码,要统一
统一之前,我们也应该明白,我们总会有疏漏的地方,万一一不留神呢,,所以再看看其他的混合编解码
2.String string = "很开心分享经验";
byte[] bytes = string.getBytes(UTF);
String string2 = new String(bytes,ISO);
byte[] bytes2 = string2.getBytes(UTF);
String string3 = new String(bytes2,ISO);
System.out.println("结果:"+string3);
这一次我们 进行了两次 utf编码,ios解码, 但是结果什么样子呢

翻翻前面的,基本差不多,只不过小写变大写,最重要的是长度增加了一倍
3.
byte[] bytes =
string.getBytes(UTF);
String string2 = new String(bytes,GBK);
byte[] bytes2 = string2.getBytes(UTF);
String string3 = new String(bytes2,GBK);
System.out.println("结果:"+bytes2.length+string3);
这一次我们进行了 一个utf-8,编码,gbk解码,utf-8编码,gbk解码,依然是乱码,长度又增加了 二分之一(utf-8表示一个中文三个字节,gbk是两个字节)

4.byte[] bytes =
string.getBytes(UTF);
String string2 = new String(bytes,GBK);
byte[] bytes2 = string2.getBytes(GBK);
String string3 = new String(bytes2,UTF);
System.out.println("结果:"+string3);
这次是utf-8编码,gbk解码,gbk编码,utf-8解码。最终的结果好玩

一部分中文被正确显示,另外一些汉字惨遭抛弃。。。
5.byte[] bytes = string.getBytes(GBK);
String string2 = new String(bytes,UTF);
byte[] bytes2 = string2.getBytes(UTF);
String string3 = new String(bytes2,GBK);
System.out.println("结果:"+string3);
这一次是GBK编码,utf-8解码,utf-8编码,gbk解码

6、
byte[] bytes = string.getBytes(GBK);
String string2 = new String(bytes,UTF);
byte[] bytes2 = string2.getBytes(GBK);
String string3 = new String(bytes2,GBK);
System.out.println("结果:"+string3);
这次我们gbk编码,utf-8解码,gbk编码,gbk解码,
得到的结果感人::

一大坨 ??? 刚才我说的都是一大坨 ???编码肯定是iso,但是得有前提,长度相同
到这里,不能在总结了,意思很明确,经过一次两次编码,结果可能已经面目全非,但是仔细分析,每一种情况的具体结果还是不同的,对于我们很多人来说,要想记住这些所有的乱码情况,是不可能的,但是如果我们真的遇到了一些多次编解码,多种编码方式,出现的乱码时,有过这方面的试验经验,或许可以解决的更快一些。
下面从请求处理的流程,以及具体流程的某个阶段可能出现的乱码问题
1.http请求的编码
提交表单(一般设置为method = POST ,一下说的表单默认是post),或者在地址栏直接输入url地址(get请求)
首先先说get方式,也就是输入地址栏 的url
1.http://localhost:8080/TestCharSet/test?charset=中文
红色部分为pathinfo,也就是路径部分,绿色部分是QueryInfo部分,也就是查询字符串,在后台我们一般这样获取
String charset = request.getParameter(“charset”);
以上我在地址栏中输入的,当我从 地址栏复制到word中时,他转成了这个
http://localhost:8080/TestCharSet/test?charset=%E4%B8%AD%E6%96%87
后面的%加上数字字母都是URL编码 加上%是因为16进制表示,所以在前面加个%
URL编码的过程很简单,如下:
- 将待编码字符原先的存储编码看成一个16进制流【将原2进制流按 字节拆分,每个字节都用2位16进制数表示】;
- 在每两位16进制数(即一个完整的字节)前加一个%,得到最终编码结果;
对于汉字来说,首先要看其本身存储时所使用的编码是UTF-8还是GB2312。同样的汉字,存储编码不同,经URL编码后的结果自然也不同。例如“川”,使用UTF-8编码存储时为 e5b79d ,经URL编码后则为 %e5%b7%9d ;使用GB2312编码存储时为 b4a8 ,经URL编码后则为 %b4%a8 。
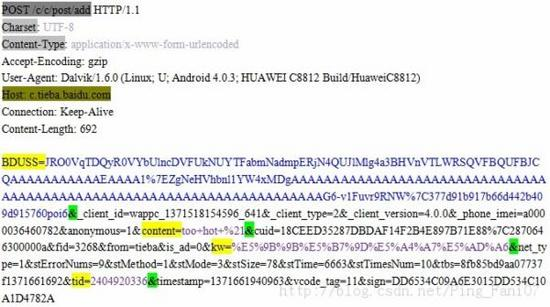
解码的时候也很简单,将编码里的%号去掉,得到一个16进制流,这个16进制流转回2进制流,得到的就是原字符的存储编码。剩下的一个重要问题是怎么理解这个还原出来的存储编码(即原字符使用的存储编码方式)?分三种情况:
- 对于HTTP请求正文中的URL编码,我们可以查看请求头部中 Charset 头域的值,它指定了请求报文所使用的字符集(即存储编码方式)。如图1,因为 Charset 的值为UTF-8,所以我们对解码后的结果就应当按UTF-8编码理解了;
- 因为使用UTF-8编码时,一个汉字的本身存储占三个字节;而使用GB2312编码,一个汉字的本身存储占两个字节。因此如果我们能确定被编码的是纯汉字流的话,我们可以根据解码后的结果占用的字节数是3或者2的倍数来大致推断其存储编码方式;
- 上述方法都不行的话,就只能在译码的时候都试一下了
具体的url编码请查看链接 http://www.tuicool.com/articles/3mUNFz 这里写的很好
前面说到了 浏览器把一个具体编码的字符序列按照url编码 为16进制,同样服务器端,按照url解码,将url进行解码 得到了具体的字符序列,那么服务器拿到了这个字符序列怎么办呢,就可以读取了吗,不能,我们还需要知道这个字符序列是什么编码方式,否则我们根本正常读取不了(否则就会乱码)
2)post方式的编码
例如表单POST请求,会将提交的参数放到请求主体部分
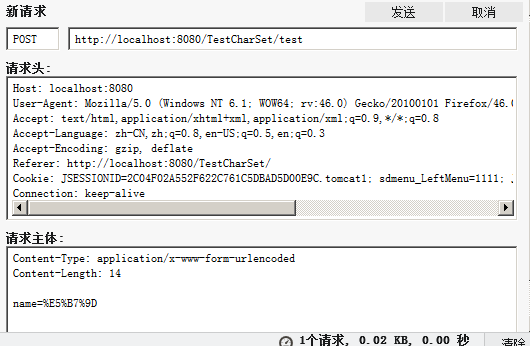
例如name就被放在主体部分,同样,它也是浏览器通过url编码(16进制编码)把数据传送到服务器端,具体的服务器拿到这个16进制解码的结果,也就是这个字符序列,如何处理,是按照什么方式解析呢,同样是 制定的charset值,但是一般表单提交后,服务器端需要我们指定具体的charset进行解码,具体的方式
大家都用过:request.setCharacterEncoding(charset);
3、应用服务器如何解析参数
我们知道url也就是get请求的路径部分,需要解码,解码的方式是charset指定的方式,但是具体的,可能头文件中并没有指定charset,这时 应用服务器会采用默认的编码方式
具体到tomcat中
<Connector URIEncoding="UTF-8" port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
这个uriencoding属性可以设置tomcat的解析的uri的编码
如果不设置,默认是IOS-8859-1,uri中存在中文字符,即使设置了request.setCharaeterEncoding(“utf-8”)在request中也解析不出来的。
如下
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
System.out.println("GET请求处理");
req.setCharacterEncoding("utf-8");//在这里设置了utf-8
String string = req.getParameter("charset");
if(string!=null){
System.out.println(string);
}else {
System.out.println("没有获取到变量");
}
PrintWriter pw = resp.getWriter();
pw.println(req.getRequestURI()+"请求成功");
pw.close();
}
请求路径中包含中文
http://localhost:8080/TestCharSet/test?charset=中文

如果设置了URIEncoding="UTF-8"之后,即使没有设置reqest.setCharaeterEncoding,也可以获取到参数,但是对于post请求,无法获取到name


当设置了reqest.setCharaeterEncoding(utf-8)后,post请求可以获取到

我们可以总结一下,也就是说url中的编码必须统一uriEncoding设置,可以不设置reqest.setCharaeterEncoding(utf-8)
但是如果遇到post请求,参数信息在请求主体中,那我们必须设置
reqest.setCharaeterEncoding(utf-8)这样才能保证获取到正确的参数信息。
这里多提一点,tomcat在对请求头文件解析的时候,默认是先不解析请求主体字符串,因为字符串操作非常耗费性能,tomcat把解析工作延迟到第一次调用 req.getParameter中进行,之后便将所有的参数全部注入到tomcat中的一个ParameterMap数据结构中,在解析之后,你即使通过req.setCharaeter也没有用了。
(在由byte[]流转化为Java中的String时,需要指定编码,这个编码就是通过request设置的)
Tomcat还有一个参数useBodyEncodingForURI,这个参数是什么意思呢,当它为false时,对url中的编码采用tomcat默认的或者uriEncoding设置的编码方式。当为true时,get请求中的查询字符串按照http请求主体中的编码方式解码,而请求主体的解码方式,我们通过
request.setCharaeterEncoding设置,而浏览器发送请求主体的编码方式是发送post,get请求的本界面的charset进行编码。后面会具体谈到浏览器发送http请求的编码
不光request,response也需要字符转化,看个例子
这时处理get请求的servlet代码,像屏幕打印输出请求链接,以及“请求成功”
PrintWriter pw = resp.getWriter();
pw.println(req.getRequestURI()+"请求成功");
pw.close();

可以看到请求成功是乱码,因为response将”请求成功“转化为 byte[]流时,默认采用的
ISO-8859-1,所以打印的都是????
基于此reponse也要设置字符编码,response.setCharaeterEncoding(“utf-8”)
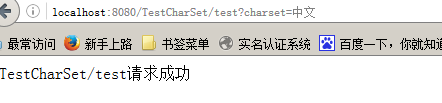
这时显示正常了
但是可能有的小伙伴显示的结果可能是这个

还是乱码,往上面找我们总结的四种情况,最接近第一种,也就是说用utf-8编码,gbk解码的情况,事实也是如此,浏览器接收到byte[]流后,按照的是GBK解码,我用的是火狐浏览器,在文字编码设置中,将简体中文改成Unicode后,即正常显示。
或者我们采用一种更加优雅的方式
pw.println("<meta http-equiv=\"Content-Type\" content=\"text/html;charset=UTF-8\">");
打印meta标签,这样即使我们手动指定文字编码为gbk(简体中文),浏览器接收到这个标签后,会默认按照这个标签中指定的编码,进行解码显示。同样,meta标签指定的编码也要和response.setXXX方法设置的一样,否则也会乱码
再继续深入一下,这是通过response打印输出,如果直接跳转到jsp页面呢?首先我们先不设置 response的编码集也就是默认的转到Charser.jsp界面该界面如下
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<base href="<%=basePath%>">
<title></title>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<meta http-equiv="pragma" content="no-cache">
<meta http-equiv="cache-control" content="no-cache">
<meta http-equiv="expires" content="0">
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="This is my page">
<!--
<link rel="stylesheet" type="text/css" href="styles.css">
-->
</head>
<body>
<h1>copyright @ 青铜器工作室 </h1>
</body>
</html>
在这个界面里,有一段中文,看看这个界面能不能正常显示
req.getRequestDispatcher("/Charset.jsp").forward(req, resp);
这个将请求转发到Charset.jsp这个界面

结果如图,response在没有设置编码情况下,还是将jsp中的中文按照iso进行编码,变成了???
有什么方式可以避免这种情况发生呢
事实上我们可以看到
即使加上<meta http-equiv="Content-Type" content="text/html;charset=utf-8" />
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>
如果不用response设置默认编码,同样会乱码 因为response设置的编码是用来编码的,就是讲字符转化为字节数组,而meta设置的utf-8是用来解码的,也就是说告诉,浏览器,你应该如何显示
但是我发现,
当设置了response的编码
设置了<meta http-equiv="Content-Type" content="text/html;charset=gbk" />
时客户端没有显示乱码,预测结果是客户端显示界面时应该按gbk解码 用utf-8编码后的字符。
关键在于 charset.jsp这个界面我是通过request转发过去的,在处理中response设置的utf-8已经指定了http响应头的编码
req.getRequestDispatcher("/Charset.jsp").forward(req, resp);
事实上response设置的utf-8已经设置了jsp编码的方式,同时在响应头中指定了charset,这样jsp设置的charset,没有作用。
那么jsp中的
<meta http-equiv="Content-Type" content="text/html;charset=gbk" />
以及在
<%@ page language="java" contentType="text/html;charset=GBK" import="java.util.*" pageEncoding="UTF-8"%>中设置的ContentType在哪里其作用呢?pageEncoding又是什么呢?
以下引用
http://www.cnblogs.com/loulijun/archive/2012/03/28/2421568.html下内容
pageEncoding是jsp文件本身的编码
contentType的charset是指服务器发送给客户端时的内容编码
JSP要经过两次的“编码”,第一阶段会用pageEncoding,第二阶段会用utf-8至utf-8,第三阶段就是由Tomcat出来的网页, 用的是contentType。
第一阶段是jsp编译成.java,它会根据pageEncoding的设定读取jsp,结果是由指定的编码方案翻译成统一的UTF-8 JAVA源码(即.java),如果pageEncoding设定错了,或没有设定,出来的就是中文乱码。
第二阶段是由JAVAC的JAVA源码至java byteCode的编译,不论JSP编写时候用的是什么编码方案,经过这个阶段的结果全部是UTF-8的encoding的java源码。
JAVAC用UTF-8的encoding读取java源码,编译成UTF-8 encoding的二进制码(即.class),这是JVM对常数字串在二进制码(java encoding)内表达的规范。
第三阶段是Tomcat(或其的application container)载入和执行阶段二的来的JAVA二进制码,输出的结果,也就是在客户端见到的,这时隐藏在阶段一和阶段二的参数contentType就发挥了功效
contentType的设定.
pageEncoding 和contentType的预设都是 ISO8859-1. 而随便设定了其中一个, 另一个就跟着一样了(TOMCAT4.1.27是如此). 但这不是绝对的, 这要看各自JSPC的处理方式. 而pageEncoding不等于contentType, 更有利亚洲区的文字 CJKV系JSP网页的开发和展示, (例pageEncoding=GB2312 不等于 contentType=utf-8)。
jsp文件不像.java,.java在被编译器读入的时候默认采用的是操作系统所设定的locale所对应的编码,比如中国大陆就是GBK, 台湾就是BIG5或者MS950。而一般我们不管是在记事本还是在ue中写代码,如果没有经过特别转码的话,写出来的都是本地编码格式的内容。所以编译器 采用的方法刚好可以让虚拟机得到正确的资料。
但是jsp文件不是这样,它没有这个默认转码过程,但是指定了pageEncoding就可以实现正确转码了。
1、pageEncoding="UTF-8"的作用是设置JSP编译成Servlet时使用的编码。
众所周知,JSP在服务 器上是要先被编译成Servlet的。pageEncoding="UTF-8"的作用就是告诉JSP编译器在将JSP文件编译成Servlet时使用的 编码。通常,在JSP内部定义的字符串(直接在JSP中定义,而不是从浏览器提交的数据)出现乱码时,很多都是由于该参数设置错误引起的。例如,你的 JSP文件是以GBK为编码保存的,而在JSP中却指定pageEncoding="UTF-8",就会引起JSP内部定义的字符串为乱码。
另外,该参数还有一个功能,就是在JSP中不指定contentType参数,也不使用response.setCharacterEncoding方法时,指定对服务器响应进行重新编码的编码。
2、contentType="text/html;charset=UTF-8"的作用是指定对服务器响应进行重新编码的编码。
在不使用response.setCharacterEncoding方法时,用该参数指定对服务器响应进行重新编码的编码。
刚才我们就是在设置response.setCharacterEncoding(utf-8)后,设置contentType为gbk,但是客户端依然按照response的设置,所以response对contentType的优先级高
3、request.setCharacterEncoding("UTF-8")的作用是设置对客户端请求进行重新编码的编码。
该方法用来指定对浏览器发送来的数据进行重新编码(或者称为解码)时,使用的编码。
4、response.setCharacterEncoding("UTF-8")的作用是指定对服务器响应进行重新编码的编码。
服务器在将数据发送到浏览器前,对数据进行重新编码时,使用的就是该编码。
当我们直接通过访问jsp的方式,转到jsp界面时,发现 在page标签中contentType起作用了,我们设置的是gbk
然后我们发现通过meta设置的编码为utf-8时,也并没有出现乱码,可见,浏览器显示时,并没有按照meta标签中指定的编码,而是优先使用page标签中的contentType中设置的值。这时即使设置了字符过滤器,字符过滤器中response中的设置也不会启用,也即是说,
当直接访问jsp时,只会看
<%@ page language="java" contentType="text/html;charset=gbk" import="java.util.*" pageEncoding="UTF-8"%>
的设置,(过滤器什么的都不会起作用)
当采用servlet中请求转发方式时,过滤器或servlet中的response的设置会起作用
当在html页面中,使用meta标签会起作用,当没有meta标签中会默认按照utf-8编码(并不推荐默认)
下面我们在分析一下,已开始讨论的浏览器端的处理
默认的情况下,如果jsp中出现这个超级链接应该如何处理呢。
<a href="http://localhost:8080/TestCharSet/test?charset=中文">点击这里</a>
浏览器解析这个本界面时按照response的设置,或者page标签中的contentType设置(也就是响应头中的charset)进行解析,所以这个链接中的中文自然是按照响应中的设置进行编码,而这是一个get请求,我们知道get请求浏览器需要将url进行url编码(16进制编码),我们需要知道url本身的编码是utf-8,还是gbk,这样服务器获取到字符序列才能进行重新编码,
当我们的url是通过超级链接跳转的,编码方式按照本界面response的字符编码设定。
当我们直接通过地址栏输入中文url,这时url会按照浏览器自己默认的编码方式编码,火狐是utf-8,360也是utf-8,至于其他的浏览器是不是utf-8不确定。
那么post方式,浏览器是采用什么编码的呢?
和上面所说的一样,浏览器会解析response设置的响应头的charset,然后确定post请求的主体采用什么编码
如果响应头中charset是utf-8时,那么下次它发送http请求,主体部分会是utf-8.
引用这个链接中的一段话http://www.cnblogs.com/loulijun/archive/2012/03/28/2421568.html
response.setCharacterEncoding("UTF- 8")的作用是指定对服务器响应进行重新编码的编码。同时,浏览器也是根据这个参数来对其接收到的数据进行重新编码(或者称为解码)。所以在无论你在 JSP中设置response.setCharacterEncoding("UTF-8")或者 response.setCharacterEncoding("GBK"),浏览器均能正确显示中文(前提是你发送到浏览器的数据编码是正确的,比如正
确设置了pageEncoding参数等)。读者可以做个实验,在JSP中设置 response.setCharacterEncoding("UTF- 8"),在IE中显示该页面时,在IE的菜单中选择"查看(V)"à"编码(D)"中可以查看到是" Unicode(UTF-8)",而在在JSP中设置response.setCharacterEncoding("GBK"),在IE中显示该页面 时,在IE的菜单中选择"查看(V)"à"编码(D)"中可以查看到是"简体中文(GB2312)"。
浏览器在发送数据时,对URL和参数会 进行URL编码,对参数中的中文,浏览器也是使response.setCharacterEncoding参数来进行URL编码的。以百度和 GOOGLE为例,如果你在百度中搜索"汉字",百度会将其编码为"%BA%BA%D7%D6"。而在GOOGLE中搜索"汉字",GOOGLE会将其编
码为"%E6%B1%89%E5%AD%97",这是因为百度的response.setCharacterEncoding参数为GBK,而 GOOGLE的的response.setCharacterEncoding参数为UTF-8。
浏览器在接收服务器数据和发送数据到服务器 时所使用的编码是相同的,默认情况下均为JSP页面的response.setCharacterEncoding参数(或者contentType和 pageEncoding参 数),我们称其为浏览器编码。当然,在IE中可以修改浏览器编码(在IE的菜单中选择"查看(V)"à"编码(D)"中修 改),但通常情况下,修改该参数会使原本正确的页面中出现乱码。一个有趣的例子是,在IE中浏览GOOGLE的主页时,将浏览器编码修改为"简体中文 (GB2312)",此时,页面上的中文会变成乱码,不理它,在文本框中输入"汉字",提交,GOOGLE会将其编码为"%BA%BA%D7%D6",可 见,浏览器在对中文进行URL编码时,使用的就是浏览器编码。
所以至此整个浏览器发送http请求,服务器获取数据,发送数据,浏览器接受数据中涉及的编码基本上都已经说了,那项目中还有哪些编码问题呢,或者哪些编码问题隐藏比较深呢?
1.数据库的编码,数据库一般不会出现编码问题前提是我们创建数据库时需要指定编码
CREATE TABLE `t_image` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`fkey` varchar(50) DEFAULT NULL,
`src` varchar(500) NOT NULL,
`des1` varchar(500) DEFAULT NULL,
`des2` varchar(500) DEFAULT NULL,
`des3` varchar(500) DEFAULT NULL,
`des4` varchar(500) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
同时连接数据库时也要制定编码
jdbc:mysql://localhost:3306/psych?Unicode=true&characterEncoding=utf-8
这种情况下基本上不会出现数据库编码问题,在这种情况下,如果出现乱码问题,最后考虑数据库,因为有可能存进去的时候就是乱码
什么意思呢,例如你将一个 string转化为byte[]使用gbk编码,然后存进数据库,这时你如果读取后,将byte[]按照utf-8进行解码,本身就是错的,后面我会说到我的一个经历,这个经历很久了,但bug隐藏的很深,以至于 写博客之前,我才恍然大悟为什么出现问题。
2.tomcat的默认编码问题。
为什么要说tomcat的默认编码?刚才不已经说了嘛,通过uriEncoding设置。此处说的默认编码设置是tomcat本身作为一个javaweb应用服务器,它本身就是一个进程,而一个进程实例就是一个虚拟机,我们在java里很少说进程,取而代之的是虚拟机,实际上,tomcat也是从main函数开始,中间有线程监听请求,监听到交给处理器线程处理,处理器针对http请求流进行解析,将其封装为request,response,其中response中封装了outputStream,也是即将发送给客户端的输出流,然后映射器(tomcat5以后没了,但道理一样)找到我们定义的servlet,将其加载,包装成tomcat中的类进行业务处理。以上我们讨论的都是每层每个阶段之间交换数据出现的编码问题。
而这里谈到的默认编码是指tomcat进程(虚拟机)本身采用的字符编码,可以通过
System.out.println(java.nio.charset.Charset.defaultCharset());
查看在windows下默认是gbk,linux下默认是utf-8
一般情况下,我们即使在windows下面,一个java进程采用的编码是utf-8
但是tomcat进程不同,它是gbk。
那这个默认字符编码作用是什么呢?
String string = "很开心分享经验";
byte[] bytes = string.getBytes(UTF);
String string2 = new String(bytes);
这段代码执行结果是什么呢那要看具体的环境了在windows下的tomcat,绝对是乱码
在linux下的tomcat,就不乱,如果是默认的进程(你自己写个main,然后这三代码,不加任何虚拟机初始参数)那不是乱码。
一开始我并没有发现windows下的tomcat默认编码是gbk,我在测试数据库时,采用的是本地测试,把字符串转化为byte[]时,采用的是默认的,这时默认的应该是utf,然后tomcat在显示时依然采用默认的进行解码(gbk)这时,就出现了乱码。然而我当时百思不得其解,误以为是数据库的错。浪费了不少时间依然没有解决。还在怀疑是不是web请求处理中出现乱码。这就是知识面不全,存在疏漏之处的后果。有时候我们很有必要建立全面深刻的知识体系,不能一知半解,即使是小知识点也要好好解决掉,否则出现了bug这些不足都会以时间成本来报复你。
那默认编码如何解决呢,答案是这样的,我找了很多初始参数但是都不对,于是想个邪招
Field field = Charset.class.getDeclaredField("defaultCharset");
field.setAccessible(true);
try {
field.set(Charset.class,Charset.forName("GBK"));
} catch (IllegalArgumentException e) {
//
e.printStackTrace();
} catch (IllegalAccessException e) {
//
e.printStackTrace();
}
通过反射获取静态类的私有字段,然后修改,这时
String string = "很开心分享经验";
byte[] bytes = string.getBytes(UTF);
String string2 = new String(bytes);
我们通过getBytes,以及new String().默认的都是我们设置的gbk,或者utf-8了。
转载自:http://blog.csdn.net/yuhaiqiang_123/article/details/51811419
