Python基础【day03】:字典进阶(二)
本节内容
- 深浅拷贝
- 循环方式
- 字典常用方法总结
一、深浅拷贝
列表、元组、字典(以及其他)
对于列表、元组和字典而言,进行赋值(=)、浅拷贝(copy)、深拷贝(deepcopy)而言,其内存地址是变化不通的。
赋值(=)
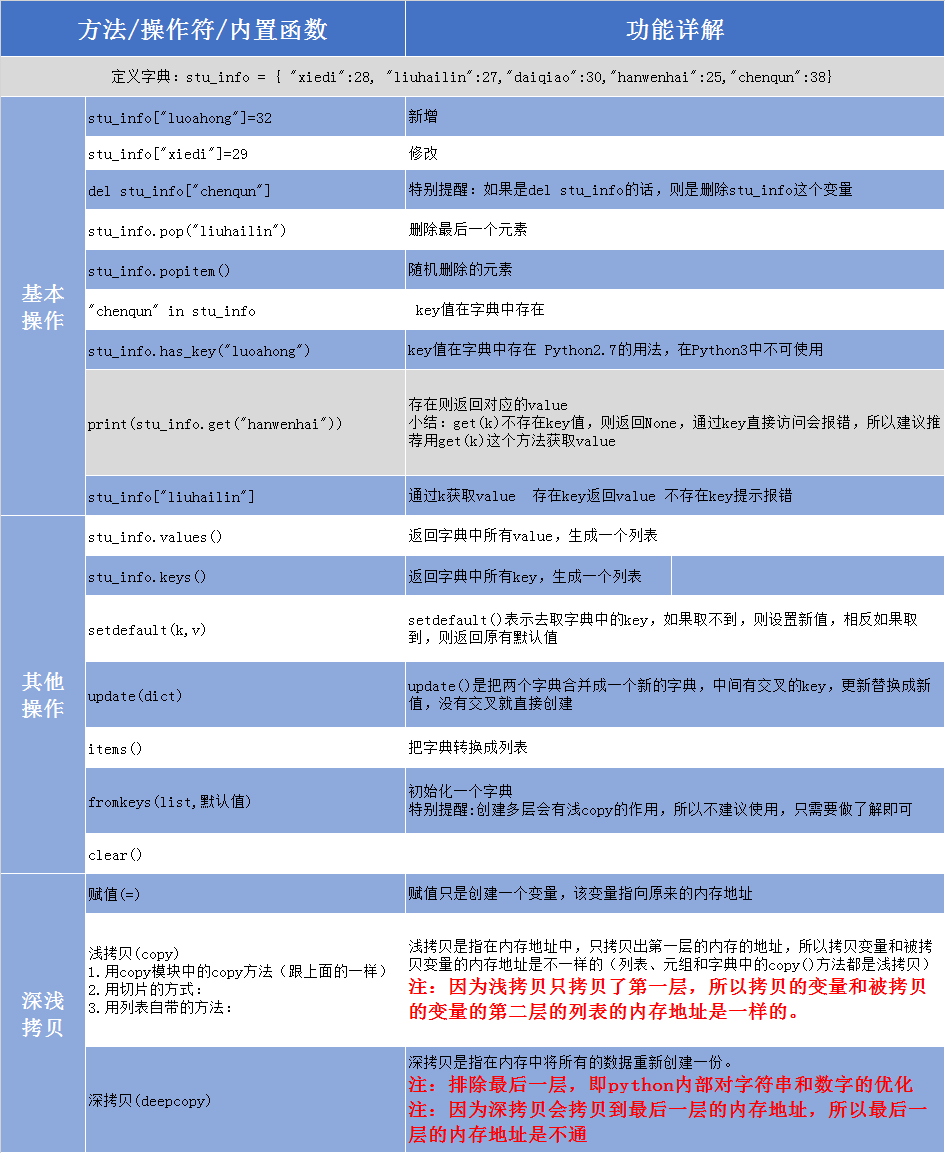
赋值只是创建一个变量,该变量指向原来的内存地址
|
1
2
3
4
5
|
>>> name1 = ['a','b',['m','n'],'c']>>> name2 = name1#输出结果,两个内存地址是一样的>>> print(id(name1),',',id(name2))50077256 , 50077256 |
如图所示:

浅拷贝(copy)
浅拷贝是指在内存地址中,只拷贝出第一层的内存的地址,所以拷贝变量和被拷贝变量的内存地址是不一样的(列表、元组和字典中的copy()方法都是浅拷贝)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
>>> import copy>>> name1 = ['a','b',['m','n'],'c']#浅copy>>> name2 = copy.copy(name1)>>> print(name1,',',id(name1))['a', 'b', ['m', 'n'], 'c'] , 50228296>>> print(name2,',',id(name2))['a', 'b', ['m', 'n'], 'c'] , 50920008#修改列表中的元素>>> name1[0] = 'h'>>> name1[2][0] = 'M'>>> print(name1,',',id(name1))['h', 'b', ['M', 'n'], 'c'] , 50228296>>> print(name2,',',id(name2))['a', 'b', ['M', 'n'], 'c'] , 50920008 |
如图所示:

注:因为浅拷贝只拷贝了第一层,所以拷贝的变量和被拷贝的变量的第二层的列表的内存地址是一样的。
|
1
2
3
4
5
6
7
8
9
10
|
>>> import copy>>> name1 = ['a','b',['m','n'],'c']>>> name2 = copy.copy(name1)>>> name1[0] = 'h'>>> name1[2][0] = 'M'#name1[2][0]的内存地址和name2[2][0]内存地址是一样的>>> print(name1,id(name1),id(name1[2][0]))['h', 'b', ['M', 'n'], 'c'] 50209800 13820904>>> print(name2,id(name2),id(name2[2][0]))['a', 'b', ['M', 'n'], 'c'] 50891144 13820904 |
浅拷贝的三种表现形式:
1.用copy模块中的copy方法(跟上面的一样)
2.用切片的方式:
|
1
2
|
>>> name1 = ['a','b',['m','n'],'c']>>> name2 = name1[:] |
3.用列表自带的方法:
|
1
2
|
>>> name1 = ['a','b',['m','n'],'c']>>> name2 = name1.copy() |
深拷贝(deepcopy)
深拷贝是指在内存中将所有的数据重新创建一份。
注:排除最后一层,即python内部对字符串和数字的优化
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
>>> import copy>>> name1 = ['a','b',['m','n'],'c']#深拷贝>>> name2 = copy.deepcopy(name1)>>> print(name1,',',id(name1))['a', 'b', ['m', 'n'], 'c'] , 50142472>>> print(name2,',',id(name2))['a', 'b', ['m', 'n'], 'c'] , 50942280>>> name1[0] = 'h'>>> name1[2][0] = 'M'>>> print(name1,id(name1),id(name1[2][0]))['h', 'b', ['M', 'n'], 'c'] 50142472 10937320>>> print(name2,id(name2),id(name2[2][0]))['a', 'b', ['m', 'n'], 'c'] 50942280 4896280 |
如图所示:

注:因为深拷贝会拷贝到最后一层的内存地址,所以最后一层的内存地址是不通
二、循环方式
方法1、
|
1
2
|
for key in info: print(key,info[key]) |
方法2、
|
1
2
3
|
#方法2for k,v in info.items(): #会先把dict转成list,数据量大时莫用 print(k,v) |
小结:
①方法1的效率比方法2的效率高很多
②方法1是直接通过key取value
③方法2是先把字典转换成一个列表,再去取值
④当数据量比较大的时候,用第二种方法时,字典转换成列表的这个过程需要花大量的时间老转换,当然数据量不大,没有关系,效率差不多
七、字典常用方法
作者:罗阿红
出处:http://www.cnblogs.com/luoahong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
分类:
1.Python基础


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构